
第3次作业:卷积神经网络(代码练习)
卷积神经网络(CNN)
导入相关的库并加载数据 (MNIST)
显示数据集中的部分图像
创建网络

定义训练和测试函数
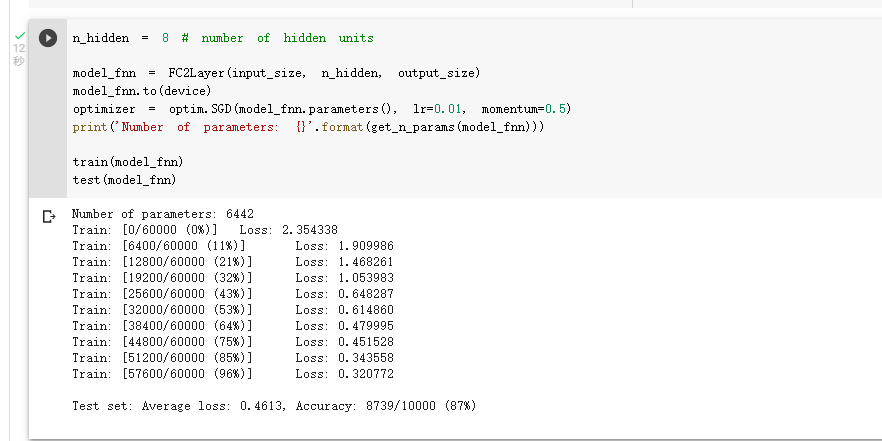
全连接网络训练:准确率0.87
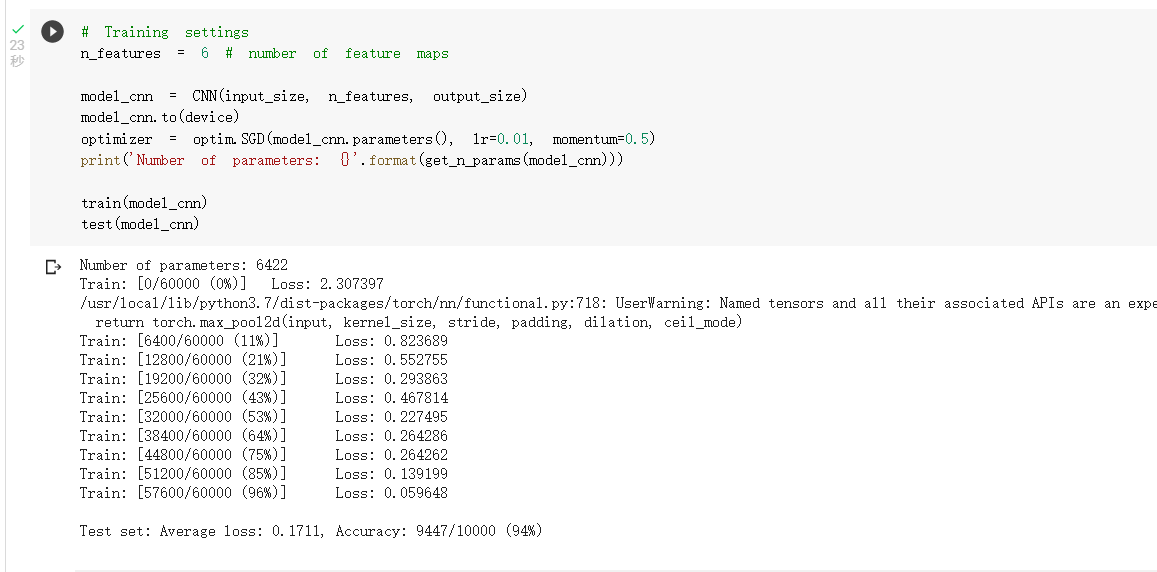
卷积神经网络上训练(和上面的模型参数相同,但准确率达到了0.94)
通过上面的测试结果,可以发现,含有相同参数的 CNN 效果要明显优于 简单的全连接网络,是因为 CNN 能够更好的挖掘图像中的信息,主要通过两个手段:
- 卷积:Locality and stationarity in images
- 池化:Builds in some translation invariance
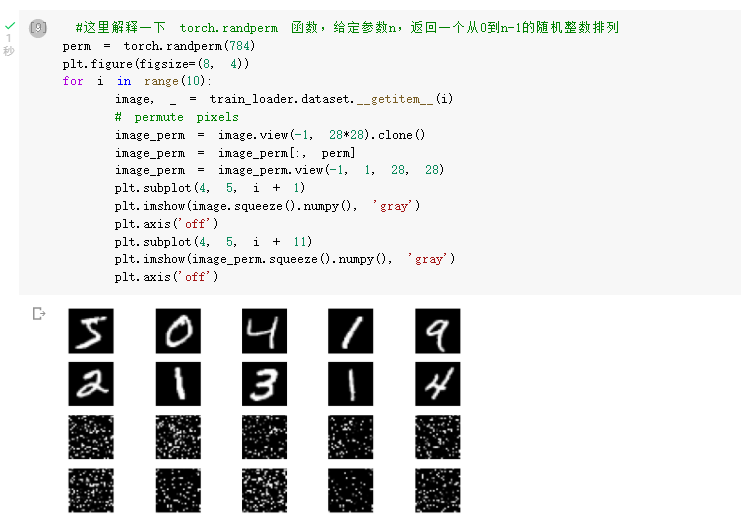
考虑到CNN在卷积与池化上的优良特性,如果我们把图像中的像素打乱顺序,这样 卷积 和 池化 就难以发挥作用了,为了验证这个想法,我们把图像中的像素打乱顺序再试试。
首先下面代码展示随机打乱像素顺序后,图像的形态:
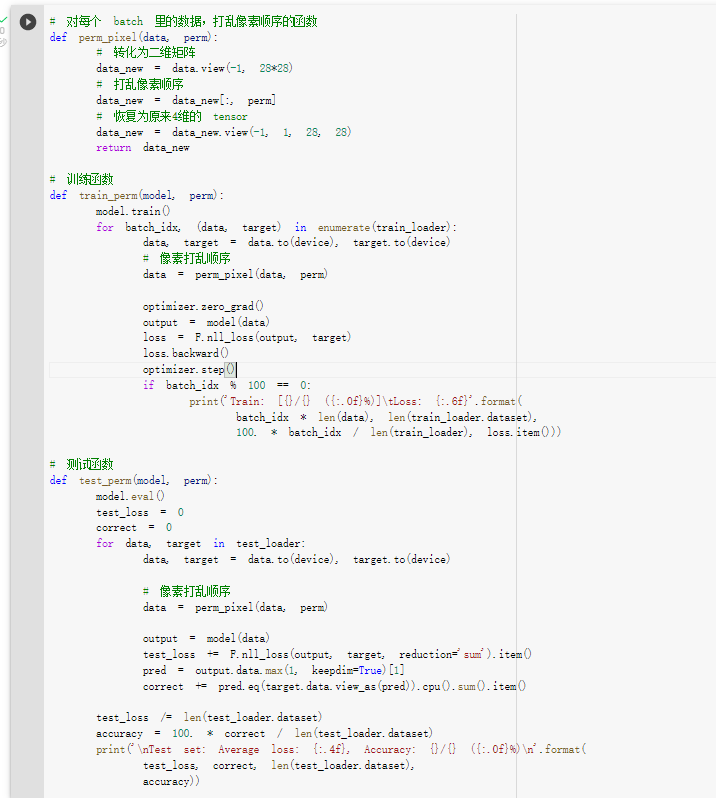
重新定义训练与测试函数,我们写了两个函数 train_perm 和 test_perm,分别对应着加入像素打乱顺序的训练函数与测试函数。
与之前的训练与测试函数基本上完全相同,只是对 data 加入了打乱顺序操作。
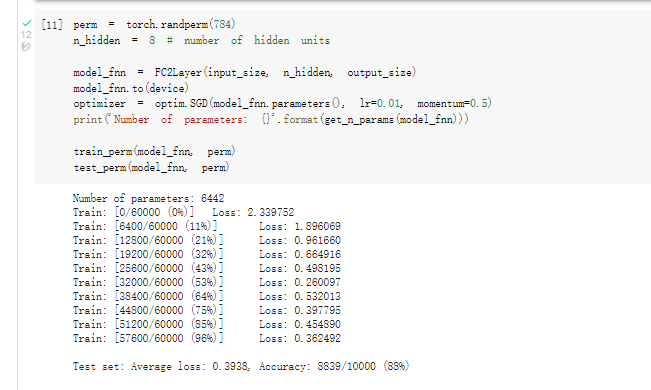
在全连接网络上训练与测试:
在卷积神经网络上训练与测试:
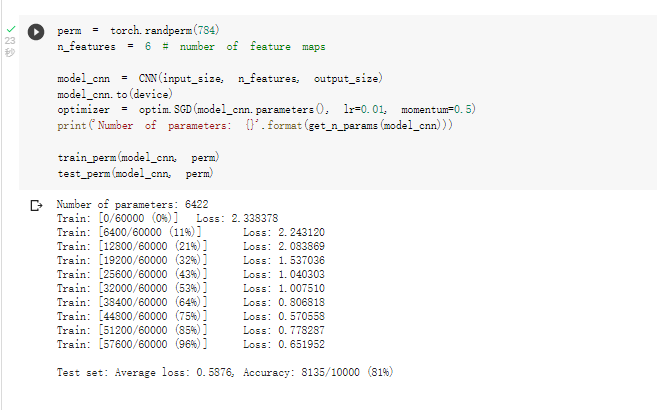
从打乱像素顺序的实验结果来看,全连接网络的性能基本上没有发生变化,但是 卷积神经网络的性能明显下降。
这是因为对于卷积神经网络,会利用像素的局部关系,但是打乱顺序以后,这些像素间的关系将无法得到利用。
CIFAR10数据集
CIFAR10数据集,它包含十个类别:‘airplane’, ‘automobile’, ‘bird’, ‘cat’, ‘deer’, ‘dog’, ‘frog’, ‘horse’, ‘ship’, ‘truck’。CIFAR-10 中的图像尺寸为3x32x32,也就是RGB的3层颜色通道,每层通道内的尺寸为32*32。
###导入库

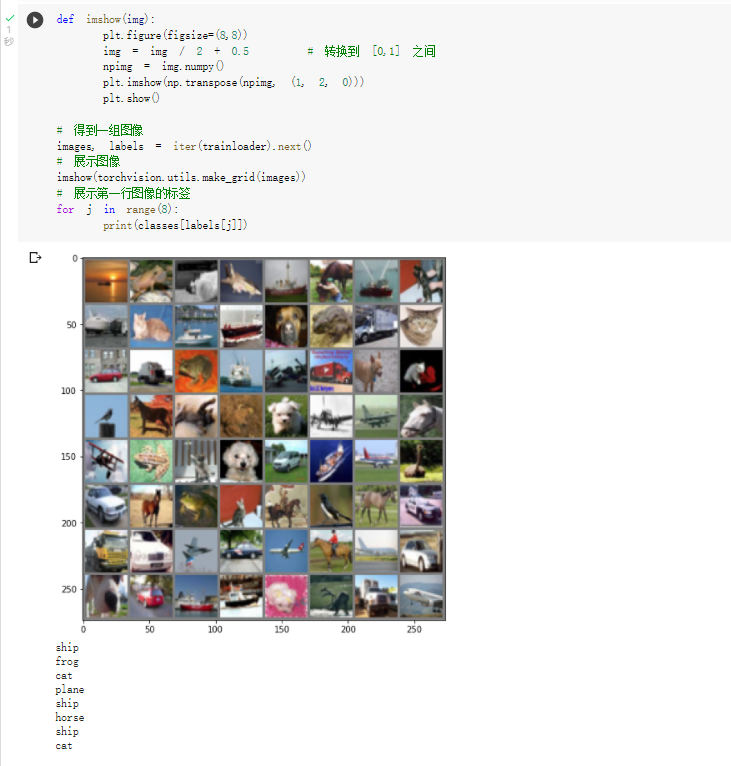
展示 CIFAR10 里面的一些图片:
接下来定义网络,损失函数和优化器:

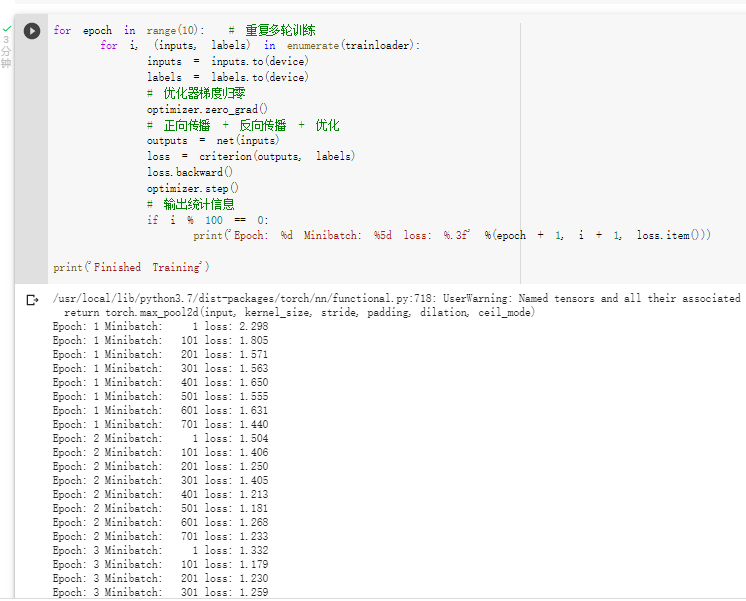
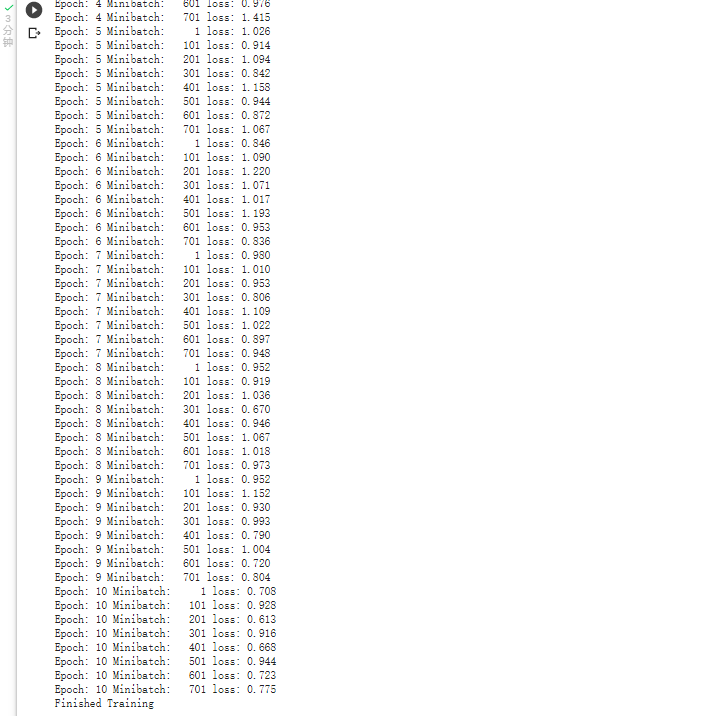
训练网络:
现在我们从测试集中取出8张图片:
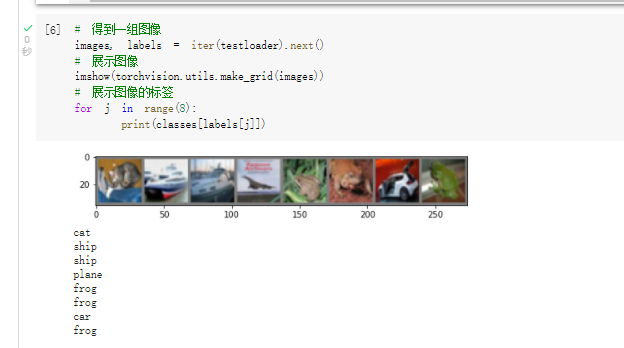
把图片输入模型,看看CNN把这些图片识别成什么:
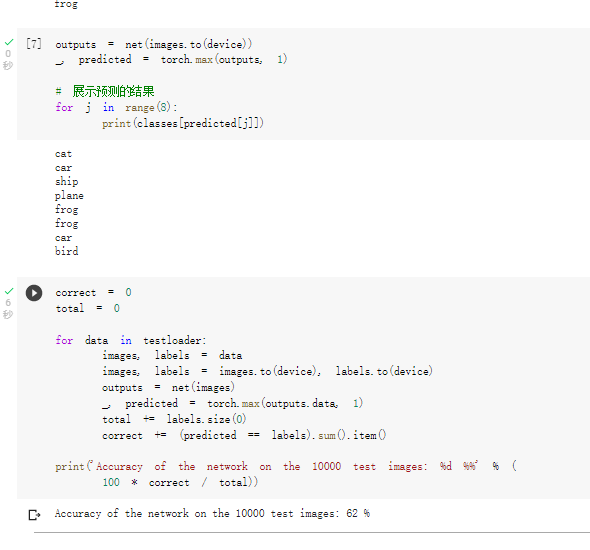
准确率达到了0.62,感觉也不是太靠谱。
VGG16 对 CIFAR10 分类
定义 dataloader

VGG网络定义,下面是模型的实现代码:
圈起来的是运行时报错,之后改了一下。

初始化网络,根据实际需要,修改分类层。因为 tiny-imagenet 是对200类图像分类,这里把输出修改为200。

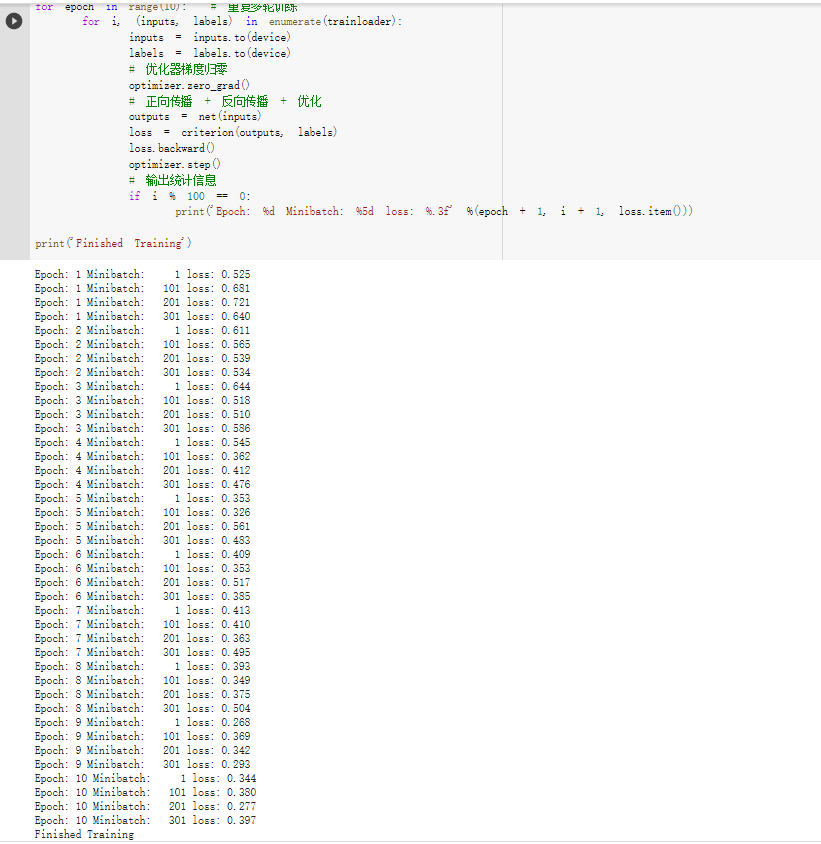
网络训练:
测试验证准确率
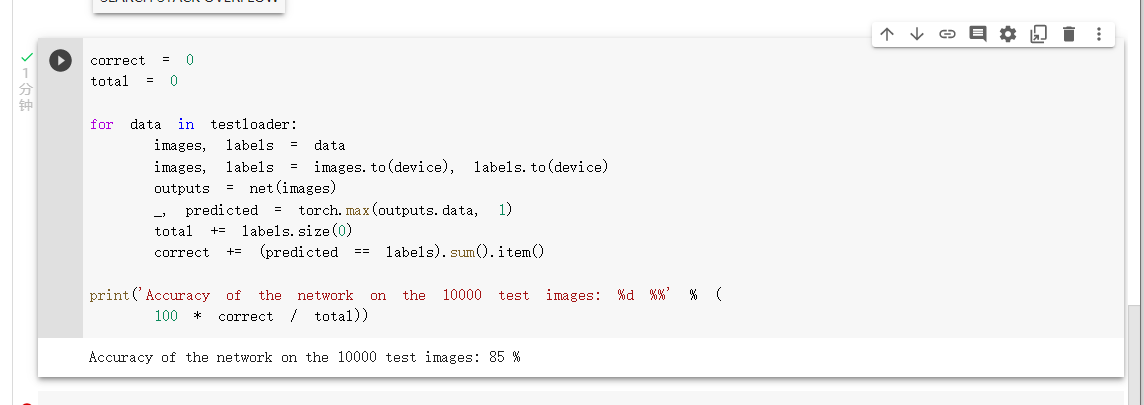
可以看到,使用一个简化版的 VGG 网络,就能够显著地将准确率由 62%,提升到 85%

 浙公网安备 33010602011771号
浙公网安备 33010602011771号