


神经网络数学基础+卷积神经网络+部分实战训练
神经网络的数学基础:
1.矩阵线性变换(起到尺度和旋转上的变化,W·x与升降维、放大缩小相关,b与平移相关,与弯曲相关)
2.矩阵的秩(秩越低,数据分布越容易被捕捉,相关性大)
奇异值、低秩近似(保留决定数据分布最主要的模式/方向)
3.概率
概率分布、似然函数、对数似然函数、最大对数似然
4.策略设计:机器学习的目的是获得最小泛化误差
无免费午餐定理、奥卡姆剃刀定理
5.欠拟合:提高模型复杂度
过拟合:降低模型复杂度
6.频率学派:可独立重复的随机实验中单个事件发生频率(统计机器学习)
贝叶斯学派:关注随机事件可信程度(概率图模型)
7.Beyond深度学习
因果推断、群体智能
总结:
感觉自己数学知识还有一定欠缺,需要恶补。
卷积神经网络
深度学习三步:
搭建神经网络结构(提取特征)->找到一个合适损失函数(评估差异)->
找到一个合适的优化函数,更新参数
一:搭建神经网络结构
1.损失函数:用来衡量输出和真实标签之间的差异,可以通过调整参数/权重来进行调整
常用分类损失:交叉熵损失
常用回归损失:均方误差、平均绝对值误差
2.卷积神经网络
局部关联(卷积核)、参数共享
基本组成结构:
(1)卷积:是对两个实变函数(以实数为变量)的一种数学操作
二维卷积:
Kernel/filter:卷积核、滤波器
Receptive field:感受野(进行一次卷积时所对应输入的区域)
Activation map/featuer map:特征图(经过一次卷积所输出结果)
Channel:深度
输出特征图大小:(N+2*padding-F)/stride+1
过拟合:权重矩阵参数太多(过度拟合训练集)
(2)池化:(Pooling)
保留主要特征的同时减少参数和计算量,防止过拟合,提高模型泛化能力。
一般处于卷积层和卷积层之间,全连接层和全连接层之间。
常用方法:
最大值池化、平均值池化
(3)全连接:
全连接层一般放在卷积神经网络尾部
3.典型神经网络结构:
(1)AlexNet
采用ReLU函数
DropOut(随机失活):训练时随机关闭部分神经元(防止过拟合)
数据增强(data augmentation)平移翻转对称等
过程:第一次卷积:卷积---ReLU---池化
第二次卷积:卷积---ReLU---池化
第三次卷积:卷积---池化
。。。。。。。
第六层:全连接---ReLU---Dropout
(2)ZFNet
(3)VGG:是一个更深的网络
(4)GoogleNet
包含22个但参数层,没有FC层
多卷积核增加特征多样性,利用padding在深度上进行串联
Inception v2:插入1*1卷积核进行降维、v3用小卷积核替代大卷积核
(5)ResNet
残差学习网络、深度有152层
残差:去掉相同的主体部分,从而突出微小变化。
MNIST数据集分类
1.下载导入MNIST:
2.创建网络
(1)定义网络时需要继承nn.Module,并实现其forward方法。
forword函数是用来定义网络结构
(2)定义训练和测试函数:
batch确定一个样本单位数量
test用来计算损失
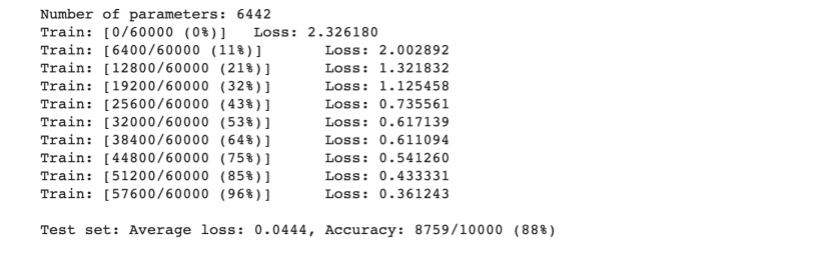
3.在小型全连接网络(FC2Layer)上训练

4.在卷积神经网络上进行训练

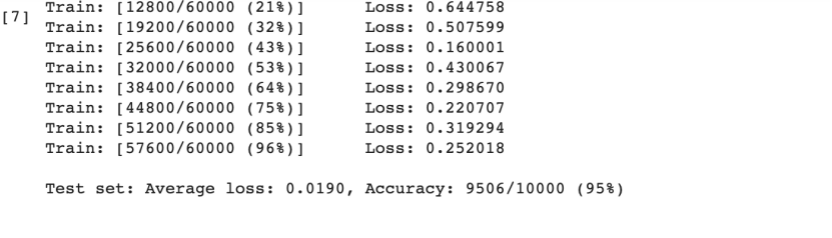
可以显著看出CNN的准确率明显优于全连接网络,原因在于CNN采用了卷积和池化方法。
5.打乱图像顺序再次进行训练
采用torch.randperm( )函数将图像像素打乱,让卷积和池化无法发挥作用
打乱:

小型:
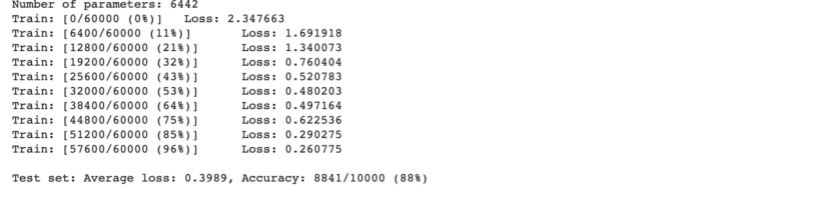
卷积神经网络
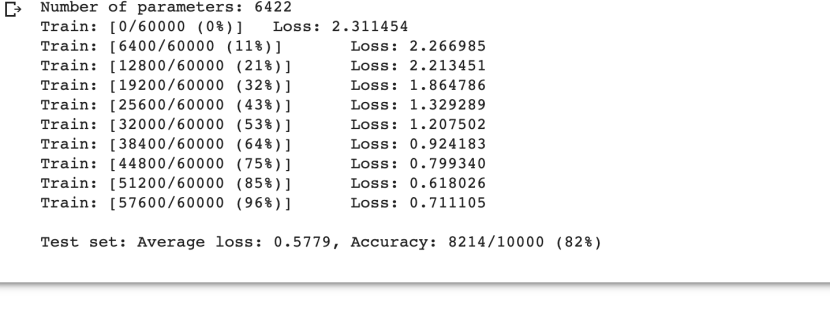
可以明显看出,在不能利用原有的图像局部关系后,CNN网络失去了原有的准确率。
CIFAR10数据分类:
其中图像尺寸为3*32*32(RGB的三色通道)
1.导入数据集

2.定义网络
(1)损失函数和优化器
(2)训练网络
正向传播+反向传播+优化
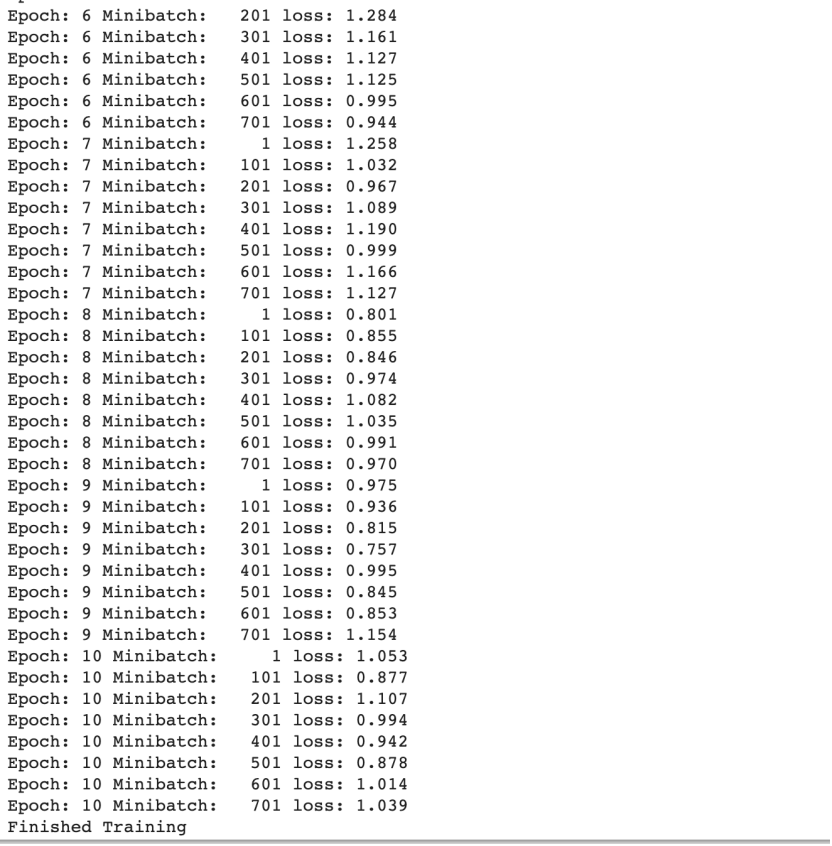
(3)从测试集取8张图片,进行模型测试

测试结果:

发现有3个图片识别错误
(4)对整个数据集进行测试:
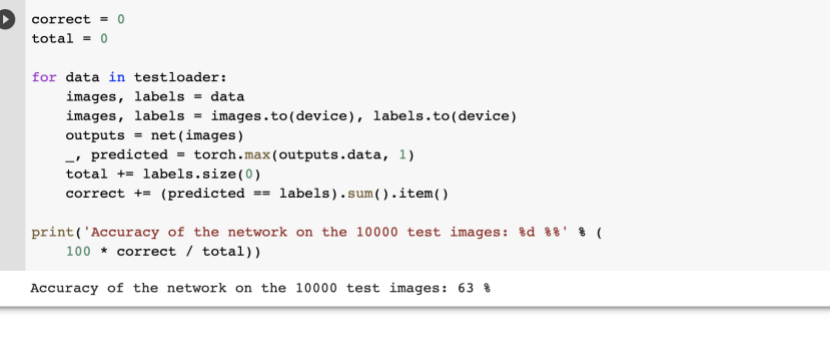
发现成功率在63%左右。
使用 VGG16 对 CIFAR10 分类
1.定义dataloader(将img,label加载到模型中):
发现batch_size相对于第一个扩大到2倍
2.定义VGG网络,并将网络放到GPU

发现原本代码报错,提示cfg不存在,将cfg设置为外部变量后解决;之后又提示错误大小不匹配,因此将nn.Linear(1024,10)按提示更改为(512,10),程序成功运行,但对原理比较模糊。
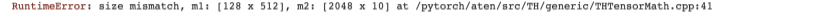
结果运行:

跑的比较慢。
总结:
通过本次的三个实验,对训练过程有了更深刻的了解,但在许多细节处的原理仍未理解透彻,需要在以后的学习中慢慢精进。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号