
从零搭建 ES 搜索服务(二)基础搜索
一、前言
上篇介绍了 ES 的基本概念及环境搭建,本篇将结合实际需求介绍整个实现过程及核心代码。
二、安装 ES ik 分析器插件
2.1 ik 分析器简介
GitHub 地址:https://github.com/medcl/elasticsearch-analysis-ik
提供两种分词模式:「 ik_max_word 」及「 ik_smart 」
| 分词模式 | 描述 |
|---|---|
| ik_max_word | 会将文本做最细粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,中华人民,中华,华人,人民共和国,人民,人,民,共和国,共和,和,国国,国歌”,会穷尽各种可能的组合 |
| ik_smart | 会做最粗粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,国歌” |
2.2 安装步骤
① 进入 ES 的 bin 目录
$ cd /usr/local/elasticsearch/bin/
② 通过 elasticsearch-plugin 命令安装 ik 插件
$ ./elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v5.5.3/elasticsearch-analysis-ik-5.5.3.zip
③ 安装成功后会在 plugins 目录出现 analysis-ik 文件夹
三、数据同步
3.1 方案设计
通过 Logstash 实现 MySQL 数据库中的数据同步到 ES 中,第一次全量同步,后续每分钟增量同步一次
3.2 实现步骤
3.2.1 安装 logstash-input-jdbc 插件
① 进入 Logstash 的 bin 目录
$ cd /usr/local/logstash/bin/
② 使用 logstash-plugin 命令安装 logstash-input-jdbc 插件
$ ./logstash-plugin install logstash-input-jdbc
3.2.2 MySQL 同步数据配置
① 首先在 Logstash 安装目录中新建「MySQL 输入数据源」相关目录
/usr/local/logstash/mysql > MySQL 输入数据源目录
/usr/local/logstash/mysql/config > 配置文件目录
/usr/local/logstash/mysql/metadata > 追踪字段记录文件目录
/usr/local/logstash/mysql/statement > SQL 脚本目录
② 其次上传「MySQL JDBC 驱动」至 /usr/local/logstash/mysql 目录中
mysql-connector-java-5.1.40.jar
③ 然后新建「 SQL 脚本文件」,即 /usr/local/logstash/mysql/statement 目录中新建 yb_knowledge.sql 文件,内容如下:
SELECT
id,
create_time AS createTime,
modify_time AS modifyTime,
is_deleted AS isDeleted,
knowledge_title AS knowledgeTitle,
author_name AS authorName,
knowledge_content AS knowledgeContent,
reference_count AS referenceCount
FROM
yb_knowledge
WHERE
modify_time >= :sql_last_value
④ 之后再新建「配置文件」,即 /usr/local/logstash/mysql/config 目录中新建 yb_knowledge.conf 文件,内容如下:
input {
jdbc {
jdbc_connection_string => "jdbc:mysql://192.168.1.192/test"
jdbc_user => "root"
jdbc_password => "123456"
jdbc_driver_library => "/usr/local/logstash/mysql/mysql-connector-java-5.1.40.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_paging_enabled => "true"
jdbc_page_size => "50000"
jdbc_default_timezone => "UTC"
lowercase_column_names => false
# 使用其它字段追踪,而不是用时间
use_column_value => true
# 追踪的字段
tracking_column => "modifyTime"
record_last_run => true
# 上一个sql_last_value值的存放文件路径, 必须要在文件中指定字段的初始值
last_run_metadata_path => "/usr/local/logstash/mysql/metadata/yb_knowledge.txt"
# 执行的sql文件路径+名称
statement_filepath => "/usr/local/logstash/mysql/statement/yb_knowledge.sql"
# 设置监听间隔 各字段含义(由左至右)分、时、天、月、年,全部为*默认含义为每分钟都更新
schedule => "* * * * *"
# 索引类型
type => "knowledge"
}
}
filter {
json {
source => "message"
remove_field => ["message"]
}
}
output {
if [type] == "knowledge" {
elasticsearch {
hosts => ["localhost:9200"]
index => "yb_knowledge"
document_id => "%{id}"
}
}
stdout {
# JSON格式输出
codec => json_lines
}
}
⑤ 进入 Logstash 的 bin 目录启动,启动时既可指定单个要加载的 conf 文件,也可以指定整个 config 目录
$ ./logstash -f ../mysql/config/yb_knowledge.conf
注:启动 Logstash 时,不管有多少个配置文件最后都会编译成一个文件,也就是说无论有多少个 input 或 output ,最终只有一个 pipeline
注:每分钟的 0 秒 Logstash 会自动去同步数据
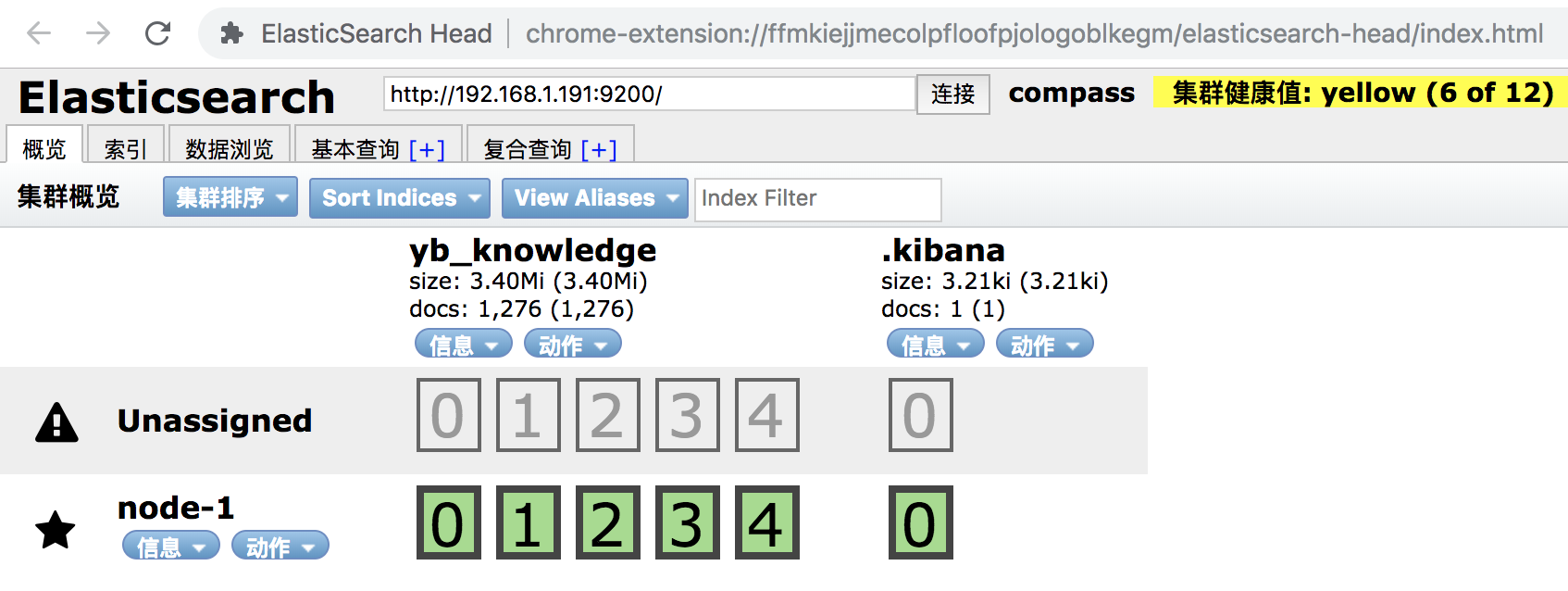
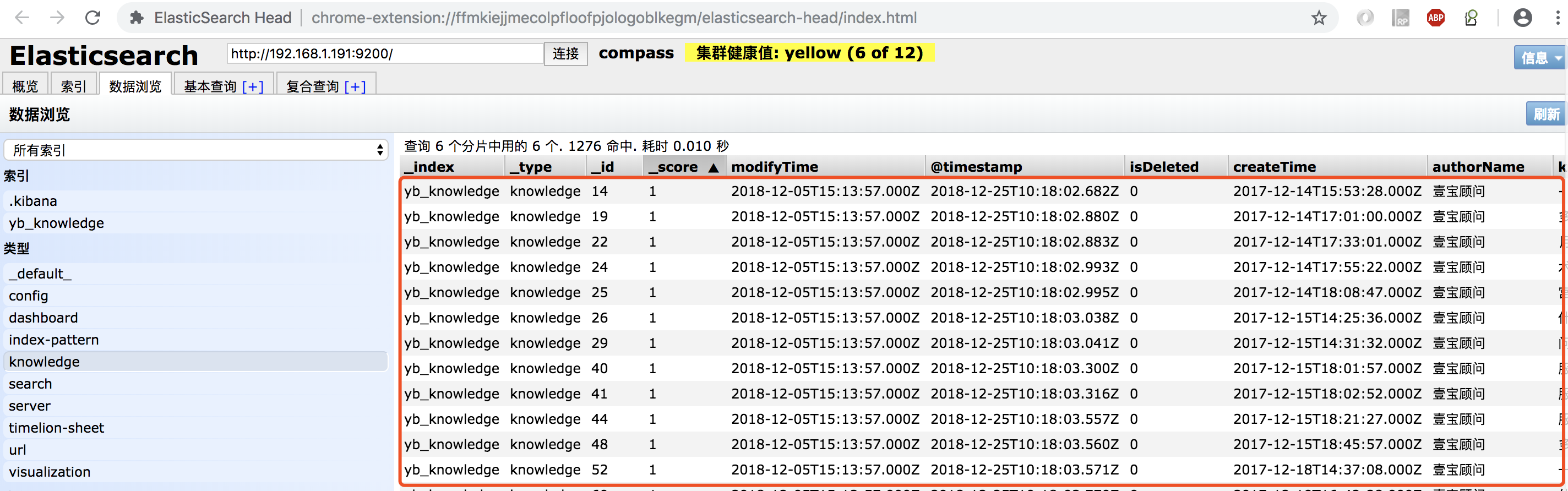
elasticsearch-head 中可看到最终结果如下:
3.2.3 自定义模板配置
此时建立的索引中字符串字段是用的默认分析器 「standard」,会把中文拆分成一个个汉字,这显然不满足我们的需求,所以需要自定义配置以使用 ik 分析器
① 首先在 Logstash 安装目录中新建「自定义模板文件」目录
/usr/local/logstash/template > 自定义模板文件目录
② 其次在该目录中新建 yb_knowledge.json 模板文件,内容如下:
{
"template": "yb_knowledge",
"settings": {
"index.refresh_interval": "5s",
"number_of_shards": "1",
"number_of_replicas": "1"
},
"mappings": {
"knowledge": {
"_all": {
"enabled": false,
"norms": false
},
"properties": {
"@timestamp": {
"type": "date",
"include_in_all": false
},
"@version": {
"type": "keyword",
"include_in_all": false
},
"knowledgeTitle": {
"type": "text",
"analyzer": "ik_max_word"
},
"knowledgeContent": {
"type": "text",
"analyzer": "ik_max_word"
}
}
}
},
"aliases": {
"knowledge": {}
}
}
③ 然后修改 yb_knowledge.conf 文件中的 output 插件,指定要使用的模板文件路径
if [type] == "knowledge" {
elasticsearch {
hosts => ["localhost:9200"]
index => "yb_knowledge"
document_id => "%{id}"
template_overwrite => true
template => "/usr/local/logstash/template/yb_knowledge.json"
template_name => "yb_knowledge"
}
}
④ 之后停止 Logstash 并删除 metadata 目录下 sql_last_value 的存放文件
$ rm -rf /usr/local/logstash/mysql/metadata/yb_knowledge.txt
⑤ 最后删除先前创建的 yb_knowledge 索引并重启 Logstash
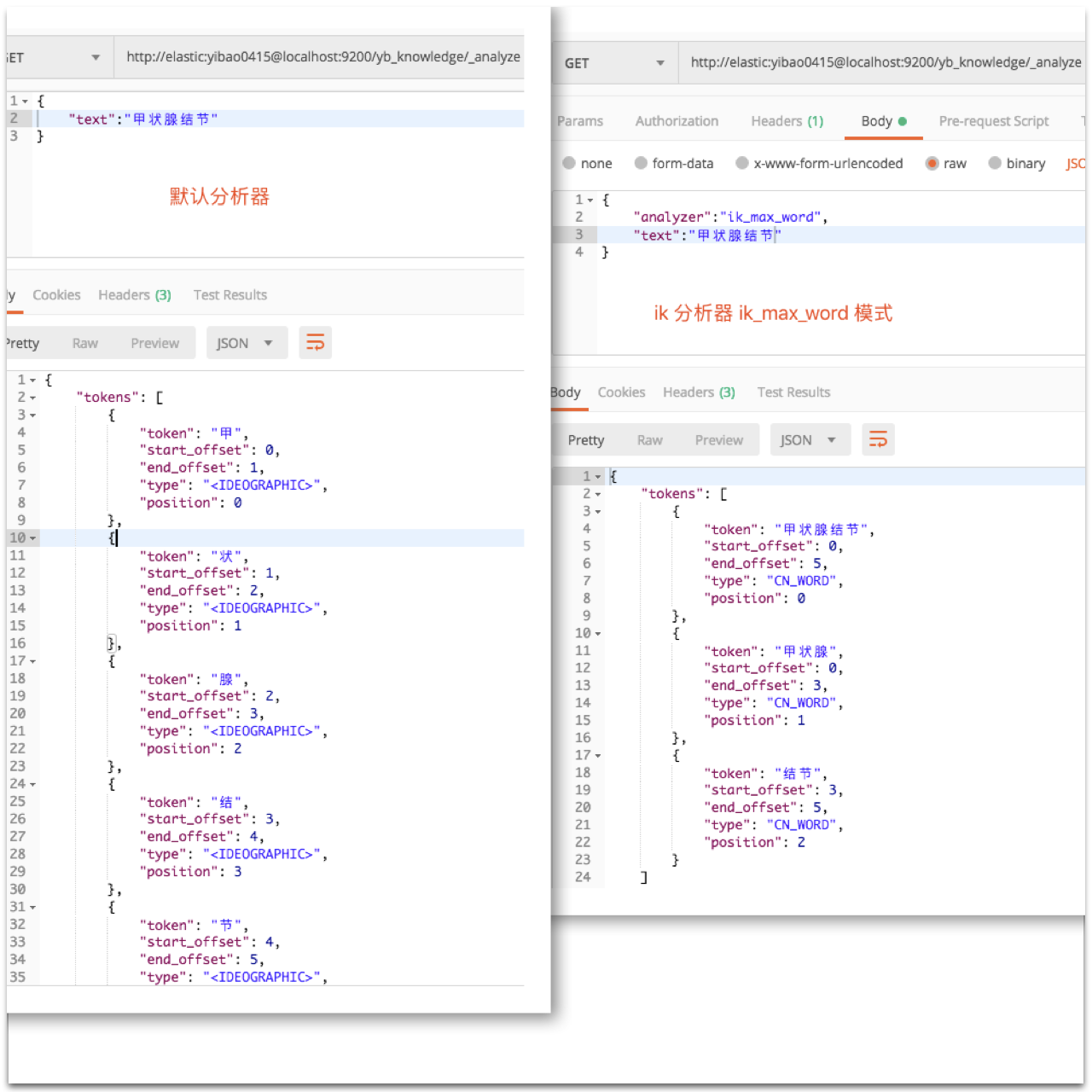
注:重建索引后可以通过「_analyze」测试分词结果
3.2.4 自动重载配置文件
为了可以自动检测配置文件的变动和自动重新加载配置文件,需要在启动的时候使用以下命令
$ ./logstash -f ../mysql/config/ --config.reload.automatic
默认检测配置文件的间隔时间是 3 秒,可以通过以下命令改变
--config.reload.interval <second>
配置文件自动重载工作原理:
- 检测到配置文件变化
- 通过停止所有输入停止当前 pipline (即管道)
- 用新的配置创建一个新的 pipeline
- 检查配置文件语法是否正确
- 检查所有的输入和输出是否可以初始化
- 检查成功使用新的 pipeline 替换当前的 pipeline
- 检查失败,使用旧的继续工作
- 在重载过程中, Logstash 进程没有重启
注:自动重载配置文件不支持 stdin 这种输入类型
四、代码实现
以下代码实现基于 Spring Boot 2.0.4,通过 Spring Data Elasticsearch 提供的 API 操作 ES
4.1 搭建 Spring Boot 项目
4.2 引入核心依赖包
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
4.3 添加 Spring Boot ES 相关配置项
在 application.properties 文件中添加 ES 相关配置项
spring.data.elasticsearch.cluster-name = compass
spring.data.elasticsearch.cluster-nodes = xxx.xxx.xxx.xxx:9300
spring.data.elasticsearch.repositories.enabled = true
4.4 核心代码
Spring Data Elasticsearch 提供了类似数据库操作的 repository 接口,可以使我们像操作数据库一样操作 ES
① 定义实体
@Data
@Document(indexName = "knowledge", type = "knowledge")
public class KnowledgeDO {
@Id
private Integer id;
private Integer isDeleted;
private java.time.LocalDateTime createTime;
private java.time.LocalDateTime modifyTime;
private String knowledgeTitle;
private String authorName;
private String knowledgeContent;
private Integer referenceCount;
}
② 定义 repository 接口
public interface KnowledgeRepository extends ElasticsearchRepository<KnowledgeDO, Integer> {
}
③ 构建查询对象
private SearchQuery getKnowledgeSearchQuery(KnowledgeSearchParam param) {
Pageable pageable = PageRequest.of(param.getStart() / param.getSize(), param.getSize());
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
// 使用 filter 比使用 must query 性能要好
boolQuery.filter(QueryBuilders.termQuery("isDeleted", IsDeletedEnum.NO.getKey()));
// 多字段查询
MultiMatchQueryBuilder multiMatchQuery = QueryBuilders.multiMatchQuery(param.getKeyword(), "knowledgeTitle", "knowledgeContent");
boolQuery.must(multiMatchQuery);
return new NativeSearchQueryBuilder()
.withPageable(pageable)
.withQuery(boolQuery)
.build();
}
注:上述查询类似于 MySQL 中的 select 语句「select * from yb_knowledge where is_deleted = 0 and (knowledge_title like '%keyword%' or knowledge_content like '%keyword%')」
④ 获取返回结果
SearchQuery searchQuery = getKnowledgeSearchQuery(param);
Page<KnowledgeDO> page = knowledgeRepository.search(searchQuery);
注:最终结果默认会按照相关性得分倒序排序,即每个文档跟查询关键词的匹配程度
五、结语
至此一个简易的搜索服务已经实现完毕,后续将继续介绍一些附加功能,如同义词搜索、拼音搜索以及搜索结果高亮等
六、其它
6.1 注意事项
① 在 Logstash 的 config 目录执行启动命令时会触发以下错误,所以请移步 bin 目录执行启动命令
ERROR Unable to locate appender "${sys:ls.log.format}_console" for logger config "root"
② Logstash 中 last_run_metadata_path 文件中保存的 sql_last_value 值是最新一条记录的 tracking_column 值,而不是所有记录中最大的 tracking_column 值
③ 当 MySQL 中字段类型为 tinyint(1) 时,同步到 ES 后该字段会转化成布尔类型,改为 tinyint(4) 可避免该问题
6.2 如何使 ES 中的字段名与 Java 实体字段名保持一致?
Java 实体字段通常是小驼峰形式命名,而我们数据库表字段都是下划线形式的,所以需要将两者建立映射关系,方法如下:
① 修改 statement_filepath 的 SQL 脚本,表字段用 AS 设置成小驼峰式的别名,与 Java 实体字段名保持一致
② Logstash 配置文件中的 jdbc 配置还需要加一个配置项 lowercase_column_names => false ,否则在 ES中字段名默认都是以小写形式存储,不支持驼峰形式
6.3 Logstash 自定义模板详解
① 第一次启动 Logstash 时默认会生成一个名叫 「logstash」 的模板到 ES 里,可以通过以下命令查看
curl -XGET 'http://localhost:9200/_template/logstash'
注:默认模板内容如下:
{
"logstash": {
"order": 0,
"version": 50001,
"template": "logstash-*",
"settings": {
"index": {
"refresh_interval": "5s"
}
},
"mappings": {
"_default_": {
"dynamic_templates": [
{
"message_field": {
"path_match": "message",
"mapping": {
"norms": false,
"type": "text"
},
"match_mapping_type": "string"
}
},
{
"string_fields": {
"mapping": {
"norms": false,
"type": "text",
"fields": {
"keyword": {
"ignore_above": 256,
"type": "keyword"
}
}
},
"match_mapping_type": "string",
"match": "*"
}
}
],
"_all": {
"norms": false,
"enabled": true
},
"properties": {
"@timestamp": {
"include_in_all": false,
"type": "date"
},
"geoip": {
"dynamic": true,
"properties": {
"ip": {
"type": "ip"
},
"latitude": {
"type": "half_float"
},
"location": {
"type": "geo_point"
},
"longitude": {
"type": "half_float"
}
}
},
"@version": {
"include_in_all": false,
"type": "keyword"
}
}
}
},
"aliases": {}
}
}
② 使用默认模板,适合刚入门时快速验证使用,但不满足实际需求场景,此时可以在 Logstash 「配置文件」中「 output 」插件中指定自定义模板 覆盖默认模板
output {
if [type] == "knowledge" {
elasticsearch {
hosts => ["localhost:9200"]
index => "yb_knowledge"
document_id => "%{id}"
template_overwrite => true
template => "/usr/local/logstash/template/yb_knowledge.json"
template_name => "yb_knowledge"
}
}
stdout {
# JSON格式输出
codec => json_lines
}
}
| 配置项 | 说明 |
|---|---|
| template_overwrite | 是否覆盖默认模板 |
| template | 自定义模板文件路径 |
| template_name | 自定义模板名 |
| 注意事项: |
-
如果不指定「 template_name 」则会永久覆盖默认的「 logstash 」模板,后续即使删除了自定义模板文件,在使用默认模板的情况下创建的索引还是使用先前自定义模板的配置。所以使用自定义模板时建议指定「 template_name 」防止出现一些难以察觉的问题。
-
如果不小心覆盖了默认模板,需要重置默认模板则执行以下命令后重启 Logstash。
curl -XDELETE 'http://localhost:9200/_template/logstash' -
ES 会按照一定的规则来尝试自动 merge 多个都匹配上了的模板规则,最终运用到索引上。所以如果某些自定义模板不再使用记得使用上述命令及时删除,避免新旧版本的模板规则同时作用在索引上引发问题。
例:「 t1 」为旧模板,「 t2 」为新模板,它们的匹配规则一致,唯一的区别是「 t2 」删除了其中一个字段的规则,此时如果「 t1 」模板不删除则新建的索引还是会应用已删除的那条规则。
-
模板是可以设置 order 参数的,默认的 order 值就是 0。order 值越大,在 merge 模板规则的时候优先级越高。这也是解决新旧版本同一条模板规则冲突的一个解决办法。
③ 自定义模板中设置索引别名,增加「 aliases 」配置项,如 yb_knowledge => knowledge
"template": "yb_knowledge",
...省略中间部分...
"aliases": {
"knowledge": {}
}
6.4 Logstash 多个配置文件里的 input 、filter 、 output 是否相互独立?
不独立;Logstash 读取多个配置文件只是简单的将所有配置文件整合到了一起。如果要彼此独立,可以通过 type 或 tags 区分,然后在 output 配置中用 if 语句判断一下
6.5 如何不停机重建索引?
① 首先新建新索引 v2
② 其次将源索引 v1 的数据导入新索引 v2 中
③ 然后设置索引别名(删除源索引 v1 别名,添加新索引 v2 别名)
④ 之后修改 Logstash 配置文件中 output 的 index 值为 v2
注:前提是 Logstash 启动时指定
config.reload.automatic设置项开启配置文件自动重载
⑤ 再次执行步骤二增量同步源索引 v1 中已修改但没同步到新索引 v2 中的数据
⑥ 最后删除源索引 v1

 浙公网安备 33010602011771号
浙公网安备 33010602011771号