

容器相关随记
0.查找容器中的网卡与宿主机的veth网卡之间的对应关系:
cat /sys/class/net/eth0/iflink 1. 为什么说容器是单进程模型:对于应用容器化,一个典型错误用法就是将容器当成虚拟机来使用,将一堆进程启动在一个容器内。但是容器和虚拟机对进程的管理能力是有着巨大差异的。不管在容器中还是虚拟机中都有一个一号进程,虚拟机中是 systemd 进程,容器中是 entrypoint 启动进程,然后所有的其他线程都是一号进程的子进程,或者子进程的子进程,递归下去。这里的主要差异就体现在 systemd 进程对僵尸进程回收的能力。
关于僵尸进程。对于正常的使用情况,子进程的创建一般需要父进程通过系统调用 wait() 或者 waitpid() 来等待子进程结束,从而回收子进程的资源。除了这种方式外,还可以通过异步的方式来进行回收,这种方式的基础是子进程结束之后会向父进程发送 SIGCHLD 信号,基于此父进程注册一个 SIGCHLD 信号的处理函数来进行子进程的资源回收就可以了。
Kubernetes 中可以将多个容器编排到一个 Pod 里面,共享同一个 Linux NameSpace。这项技术的本质是使用 Kubernetes 提供一个 pause 镜像,展开来说就是先用 pause 镜像实例化出 NameSpace,然后其他容器加入这个 NameSpace 从而实现 NameSpace 共享。
2.Linux中共七种NAMESPCE,作用如下
推荐阅读的文章:https://coolshell.cn/articles/17010.html
| namespace | 引入的相关内核版本 | 被隔离的全局系统资源 | 在容器语境下的隔离效果 |
|---|---|---|---|
| Mount namespaces | Linux 2.4.19 | 文件系统挂接点 | 每个容器能看到不同的文件系统层次结构 |
| UTS namespaces | Linux 2.6.19 | nodename 和 domainname | 每个容器可以有自己的 hostname 和 domainame |
| IPC namespaces | Linux 2.6.19 | 特定的进程间通信资源,包括System V IPC 和 POSIX message queues | 每个容器有其自己的 System V IPC 和 POSIX 消息队列文件系统,因此,只有在同一个 IPC namespace 的进程之间才能互相通信 |
| PID namespaces | Linux 2.6.24 | 进程 ID 数字空间 (process ID number space) | 每个 PID namespace 中的进程可以有其独立的 PID; 每个容器可以有其 PID 为 1 的root 进程;也使得容器可以在不同的 host 之间迁移,因为 namespace 中的进程 ID 和 host 无关了。这也使得容器中的每个进程有两个PID:容器中的 PID 和 host 上的 PID。 |
| Network namespaces | 始于Linux 2.6.24 完成于 Linux 2.6.29 | 网络相关的系统资源 | 每个容器用有其独立的网络设备,IP 地址,IP 路由表,/proc/net 目录,端口号等等。这也使得一个 host 上多个容器内的同一个应用都绑定到各自容器的 80 端口上。 |
| User namespaces | 始于 Linux 2.6.23 完成于 Linux 3.8) | 用户和组 ID 空间 | 在 user namespace 中的进程的用户和组 ID 可以和在 host 上不同; 每个 container 可以有不同的 user 和 group id;一个 host 上的非特权用户可以成为 user namespace 中的特权用户; |
还有一个CGROUP namespace:容器中看到的 cgroup 视图是以根的形式来呈现的,这样的话就和宿主机上面进程看到的 cgroup namespace 的一个视图方式是相同的;另外一个好处是让容器内部使用 cgroup 会变得更安全。
可以使用unshare命令来创建namespace
参考自:http://crosbymichael.com/ https://www.cnblogs.com/sammyliu/p/5878973.html
3.docker架构演化:
OCI:Established in June 2015 by Docker and other leaders in the container industry, the OCI currently contains two specifications: the Runtime Specification (runtime-spec) and the Image Specification (image-spec). The Runtime Specification outlines how to run a “filesystem bundle” that is unpacked on disk. At a high-level an OCI implementation would download an OCI Image then unpack that image into an OCI Runtime filesystem bundle. At this point the OCI Runtime Bundle would be run by an OCI Runtime.
参考自:https://www.jianshu.com/p/1ac4e1fa7c11?clicktime=1570842577&enterid=1570842577
4. docker使用dm存储驱动时,如果某个容器exit了,那么df -h将无法看到该容器相关的dm设备的挂载信息,此时可以将dm设备手动挂出来,再取里面的数据:https://www.cnblogs.com/xuxinkun/p/10643840.html
5. 在 Linux 内核中,有很多资源和对象是不能被 Namespace 化的,最典型的例子就是:时间
6. 直接利用linux cgroup的例子:限制某个进程cpu的使用量
当前linux环境支持cgroup限制的资源,即子系统
在cpu子系统下创建测试目录mytest,在mytest目录下会自动创建相关文件

执行程序如下shell脚本,可见bash进程几乎吃光了cpu
while : ; do : ; done &

cfs_period 和 cfs_quota这两个参数需要组合使用,可以用来限制进程在长度为 cfs_period 的一段时间内,只能被分配到总量为 cfs_quota 的 CPU 时间
cpu.cfs_period_us值为100000,即100ms
cpu.cfs_quota_us值为-1,即无限制

通过echo 50000 > cpu.cfs_quota_us 修改文件,同时追加上述bash进程的pid至tasks文件中,再通过top可以发现bash进程cpu使用量低于50

7. docker在使用诸如devicemapper、overlay等存储驱动时,往往会存在一些init层,以devicemapper为例,在/var/lib/docker/devicemapper/metadata目录下
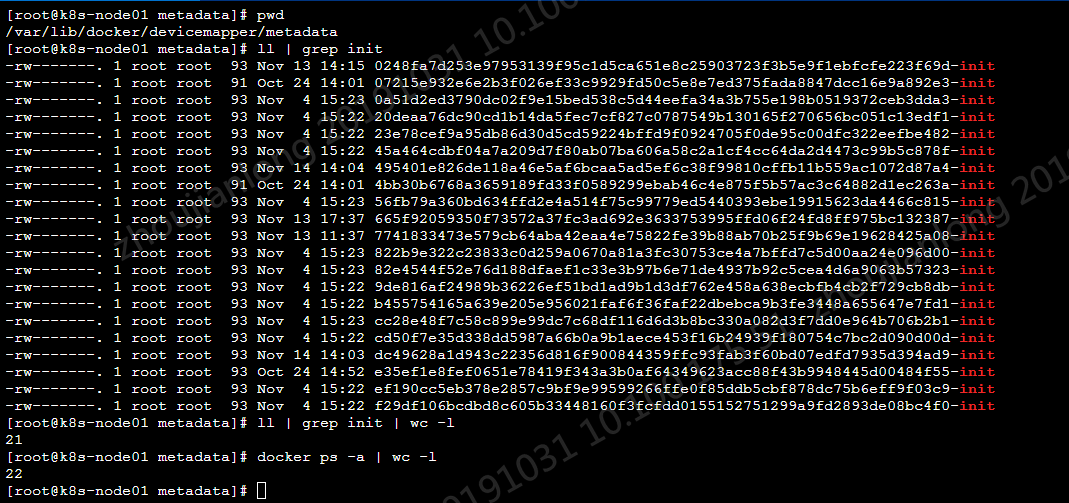
由上图可知metadata目录下的init层数量与节点上的容器数量是一致的
我们知道有镜像层(只读)和容器层(读写),那这个init层得作用是什么呢?
“init”结尾的层,夹在只读层和读写层之间。Init 层是 Docker 项目单独生成的一个内部层,专门用来存放 /etc/hosts、/etc/resolv.conf 等信息。需要这样一层的原因是,用户往往需要在启动容器时写入一些指定的值比如在/etc/hosts中写入hostname,所以就需要在可读写层对它们进行修改。可是,这些修改往往只对当前的容器有效,我们并不希望执行 docker commit 时,把这些信息连同可读写层一起提交掉。所以,Docker 做法是,在修改了这些文件之后,以一个单独的层挂载了出来。而用户执行 docker commit 只会提交可读写层,所以是不包含这些内容的。
8. 如果使用的存储驱动是overlay,可以这样理解/var/lib/docker/overlay/{layer}目录结构
lower-id:指向上一个镜像层;
upper Dir:指向容器层,在容器中创建文件后,文件出现在此目录;
merged Dir:容器层和镜像层联合之后的挂载点 ,lowerdir和upperdir整合起来提供统一的视图给容器,作为根文件系统;
work Dir:用于实现copy_up操作。
9.比如通过docker run -it -v /home:/test myimage bash,即将宿主机的/home目录挂载到容器的/test目录,假设/home目录下有一个a文件,容器/test目录下有一个b文件,那么容器启动后/test目录下是只有a文件的,即b文件不可见,这是因为:
上述操作使用到了Linux 的绑定挂载(bind mount)机制。它的主要作用就是,允许你将一个目录或者文件,而不是整个设备,挂载到一个指定的目录上。并且,这时你在该挂载点上进行的任何操作,只是发生在被挂载的目录或者文件上,而原挂载点的内容则会被隐藏起来且不受影响,也就是容器原/test目录下的b文件被隐藏了。
绑定挂载实际上是一个 inode 替换的过程。在 Linux 操作系统中,inode 可以理解为存放文件内容的“对象”,而 dentry,也叫目录项,就是访问这个 inode 所使用的“指针”。

mount --bind /home /test,会将 /home 挂载到 /test 上。其实相当于将 /test 的 dentry,重定向到了 /home 的 inode。这样当我们修改 /test 目录时,实际修改的是 /home 目录的 inode。这也就是为何,一旦执行 umount 命令,/test 目录原先的内容就会恢复:因为修改真正发生在的,是 /home 目录里。
同样的,在docker commit时,并不会将宿主机/home中的内容commit出来,因为commit的只是容器层,mount进去的内容并没有真实的在容器层另外的创建出来,当然挂载点/test目录不存在时,这个目录会被真实的创建在容器层。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号