

卷积神经网络(三)目标检测
1、目标定位:(以定位汽车为例)
将图像分类:行人、汽车、摩托车、纯背景图,使用softmax函数输出结果. 输出的结果不仅仅是分类,还有四个标记:bx、by、bh、bw. 这四个数据为被检测对象的边界框的参数.
左上角坐标(0,0),右下角坐标(1,1).

输出结果的表示形式:

2、特征点检测:
(1)以人脸特征提取为例:
对于人脸的多个特征点,比如4个眼角、鼻子周围关键点等,假设选取64个特征点,设置为 (l1x,l1y)、(l2x,l2y)、....、(l64x,l64y).
准备一个卷积网络,将人脸图片输入卷积网络,输入0/1判断是否含有人脸,然后再输出128个特征参数,最终输出129个参数.

(2)以姿态检测为例:
定义一些关键特征点,如胸部的中点、左右肩、左右肘等,来识别人物的姿态动作.

3、目标检测:(以汽车识别为例)
(1)问题描述:
由于训练集都是整张照片为汽车,且待识别照片可能含有多辆汽车,因此需要对待识别的照片应用滑动窗口,使得汽车所占图片区域较大.

使用滑动窗口,并逐渐扩大窗口的大小:

但使用滑动窗口的缺陷是:窗口截取的图片数量太多,计算成本太高.
(2)卷积的滑动窗口实现:为了解决上述计算成本的问题.
① 将全连接层转换成卷积层:假设训练集是14*14*3.


② 应用至测试集:
若测试集是16*16*3.
结果集的四个小块,每一小块都可以看成是一个窗口得出的结果.

若测试集是28*28*3.

(3)边界框预测:
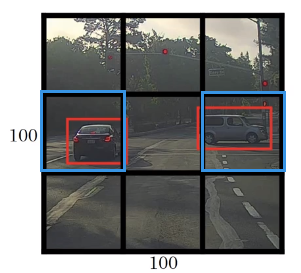
可能出现所有边界框都无法完整框处汽车的情况,如下图.

使用YOLO算法:
① 将图像分为若干格,比如3*3;
② 结合目标定位算法,找到对象的中心点,对象分配给中心点所在格子,找出汽车所在的边界,每一格输出的结果:y = [pc, bx, by, bh, bw, c1, c2, c3]T.(其中bh,bw可以超过边界)
③ 输出的结果:3*3*8(3*3是格子划分,8是每一个格子的结果都是8维).
(4)交并比(IoU):
用于判断对象检测算法运作是否良好,计算方法为:
(下图红色为正确的边界框,紫色为识别的边界框)

IoU = size of Intersection / size of Union
"correct" if IoU ≥ 0.5 (或者其它阈值)
(5)Non-max suppression(非极大值抑制):
解决的问题:在对象检测时,可能会对同一个对象检测多次,非极大值抑制可以确保算法对同一个对象检测一次.
当使用19*19的划分方式时,可能有多个格子包含了同一辆车,可能的识别结果如下图:
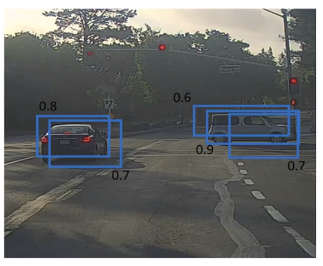
首先分析概率pc最大的边界框,即最可靠的检测,即下图黄色框,对于与其有较高交并比的边界框就会被抑制.

(6)Anchor boxes:
解决的问题:在同一个格子中识别多个对象.
当同一个格子中出现了多个对象的中点,如下图,第同一个格子中出现了人和车的中点:

选择Anchor box:一般通过手动设置5-10个anchor box形状,覆盖所需要检测的对象形状.
每一个对象都被指定到一个格子和一个与对象形状IoU最高的anchor box.
输出的结果格式:

(7) YOLO算法:
在以下用例中,使用了2个Anchor box:

其中第1格的y:![]() ;其中第8格的y:
;其中第8格的y:![]()
分别对不同对象使用极大值抑制,挑选出pc较大的边界框.
4、R-CNN(Regions with convolutional network 带区域的卷积网络):
当采用滑动窗口时,由于图片中有些区域是空的,窗口中并没有行人、汽车、摩托车等所需识别的对象,如下图:

RPN只选用少数的窗口上运行卷积网络分类器,采用的方法是图像分割方法,分割结果如下图. 对不同的色块运行分类器.

改进:
Fast R-CNN:图像分割后,再使用滑动窗口和卷积进行分类.
Faster R-CNN: 使用卷积神经网络获得候选块.
(但这些方法通常比YOLO算法慢)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号