


1. JMM规定CPU执行的(线程执行的)一些交互操作(应该并不是指令名称,只是抽象动作概念):
每条指令都是原子的(指令内部的操作们粘在一起的,不可分开的,要么都执行要么都不执行)
(JMM规定每条指令都是原子的,但是对double和long的操作除外)
lock:作用于主内存的变量, 将该变量被唯一的线程独占。对于一个变量而言,会变成单核CPU。
unlock:作用于主内存的变量,与lock相反。
read:作用于主内存的变量,将变量的值拿在手里。
load:作用于工作内存的变量,将read操作拿着的变量的值,放入工作内存的变量的拷贝空间中。
store:作用于工作内存的变量,将变量的值拿在手里。
write:作用于主内存的变量。将store操作操作拿着的变量的值,放入主内存中。
use:作用于工作内存的变量,将变量提供给CPU。
assign:作用于工作内存的变量,接收CPU的指令,将一个值赋值给变量。
JMM对以上指令的规定:
1. read-load和store-write,必须成对出现,且每对内部按顺序执行。(但是可以不连续执行)
2. 如果一个线程执行了assign,则后面必须store-write。即 assign+(store-write)
3. 如果一个线程没执行assign,则不允许store-write。即 no assign,no(store-write)
4. 一个线程使用变量(执行use或者store-write)之前,这个变量必须load,(如果load之后变量为null的话还需要assign初始化)
5. 一个变量只能被同一个线程lock,但是可以lock多次。记得unlock时也要unlock那么多次。
6. 一个线程执行lock变量,会清空这个变量的在工作内存的值,所以需要lock之后执行load和assign。
7. 一个线程只能unlock当前线程已经lock了的变量。
8. 一个线程执行unlock,之前必须store-write同步会主内存。unlock ‘before = (store-write)
JMM允许对double和long的操作可以不需要满足原子性:
因为double和long是64位,又因为32位CPU的缓存行是32位,所以有时不可能实现原子性。
所以JMM允许double和long的操作可以不需要满足原子性。
但是现在的商用JVM都已经把double和long的操作实现为原子了。
2. Volatile
2.1 Volatile语义1:(可见性语义)
Volatile变量改变时会直接写入主内存。但是只保证可见性,并不保证原子性。
意思是,只保证数据显示的值是最新的,但是不保证我用这条数据的时候别人不用,如果大家都用,可能会造成某些人的操作被覆盖而看不出来。
例子:以下场景不适合用Volatile:
新建20个线程,对同一个Volatile变量1万次++,但是结果小于20万。
解决方式:加锁 或者 CAS的AtomInterger
2.2 Volatile语义1的推论:
满足以下两个条件时,适合用Volatile。如果不满足的话还是用Synchronized或者JUC吧:
1. 运算结果并不依赖变量的当前值,或者能够确保只有单一的线程修改变量的值。(场景比如:不并发进行++)
2. 变量不需要与其他的状态变量共同参与不变约束。(场景比如:用Volatile变量作为开关(且只用这一个Volatile变量),控制某个方法是否执行)
2.3 Volatile语义2:(有序性语义)
禁止指令重排序。
例子:以下场景适合用Volatile:
Volatile+DCL单例模式。
2.4 Volatile的实现方式为LOCK指令,相当于内存屏障:
当变量为Volatile,在改变Volatile变量的值以后,比普通变量时多出一条汇编代码 ,注意是汇编代码而不是字节码。
lock addl $0x0,(%esp)
这句话的关键是lock,
加入了lock前缀之后就变成了如下操作:
1. 对CPU总线加锁(不过后来的处理器都采用锁缓存替代锁总线,因为锁总线的开销比较大)
2. 这时其他CPU的读写请求都会被阻塞,直到锁释放。
3. 当前CPU改变当前高速缓存中的Volatile变量的值,强制做了一次store+write操作,写入主内存。
4. 锁释放,同时清空其他CPU的相应的缓存行(也有人说是设置为无效Invalid)。
5. 当其他CPU读取那个Volatile变量时,发现空行或者无效,那怎么办呢?根据MESI,会从主存获取。
使语义1生效的原因:
即操作12345
使语义2生效的原因:
即操作12345,其实整个操作相当于在写Volatile变量加了全屏障。
ps.
Volatile只可以修饰成员变量(静态不静态都可以)但是不可以修饰局部变量(idea不允许)。因为局部变量只存活于方法栈中(工作内存中)所以不存在主存可见性的问题。
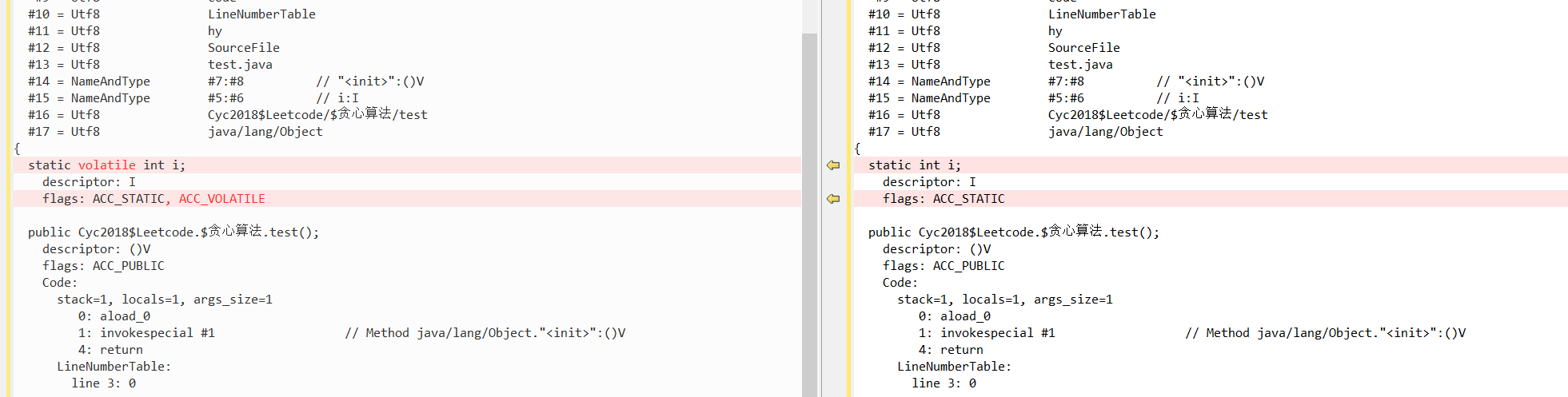
加了Volatile的成员变量的字节码的区别是:变量多了一个ACC_VOLATILE的flag而已。
public class test { static int i; // static Volatile int i; void hy () { i = 20; } }
3. 内存屏障
作用:
1. 保证数据的可见性
2. 防止指令之间的重排序
x86的内存屏障分为三类及其作用:
内存屏障其实是Intel提供的硬件指令:sfence (Store Barrier)、lfence(Load Barrier)、mfence (Full Barrier)
Intel还提供了一个lock指令前缀,这个前缀是专门用于加在指令(比如add)之前的,表示当前指令操作的内存只能由当前CPU使用,而且自带Full Barrior效果;(就是Volatile的实现)
1. 读屏障Load Barrier(lfence + 内存地址):先使缓存行失效,然后触发强制从主存获取数据的动作。
保证的是,Load Barrier之前的load和之后的load不会被重排序。
2. 写屏障Store Barrier(sfence + 内存地址):触发强制写入主存的动作,对其他CPU可见。
保证的是,Store Barrier之前的store和之后的store不会被重排序。
3. 全屏障 Full Barrier(mfence + 内存地址):强制从主存读取以及强制向主存写。
保证的是,Full Barrier上面的不能下去,同时,Full Barrier下面的不能上去。
(全屏障是一个原子效果,并不是等于写屏障+读屏障,因为写屏障+读屏障这个组合也可能出现重排(因为x86允许Store-Load 重排序))
X86下仅支持一种指令重排:Store-Load ,
即读操作可能会重排到写操作前面,同时不同线程的写操作并没有保证全局可见,例子见《Intel® 64 and IA-32 Architectures Software Developer’s Manual》手册8.6.1、8.2.3.7节。
要注意的是这个问题只能用mfence(或者是Lock前缀)解决,不能靠组合sfence和lfence解决。
(用sfence+lfence组合仅可以解决重排问题,但不能解决全局可见性问题,简单理解不如视为sfence和lfence本身也能乱序重拍)
JMM的内存屏障分为四类:
Java编译器会在适当位置插入以下内存屏障来禁止重排序
1. LoadLoad Barrier:相当于x86的 Load Barrier
2. LoadStore Barrier:相当于x86的读屏障+写屏障的原子组合。
3. StoreLoad Barrier:相当于x86的 Full Barrier(即写屏障+读屏障的原子组合)
4. StoreStore Barrier:相当于x86的 Store Barrier

4. Final
如果final修饰一个基本数据类型,表示该基本数据类型的值一旦在初始化后便不能发生变化;
如果final修饰一个引用类型,则在对其初始化之后便不能再让其指向其他对象了,但该引用所指向的对象的内容是可以发生变化的。
(其实本质上是一回事,因为引用的值是一个地址,final要求值,即地址的值不发生变化。)
final修饰的属性必须要初始化后才能返回这个类的实例对象,如果不初始化赋值会编译失败。可以在变量声明的时候初始化 + 也可以在构造函数中对这个变量赋初值。
Final的实现内存屏障:
1. 对某个类的final域的初始化后,加入一个Store-load屏障,然后才能使用这个对象。(如果不加屏障就可能会重排序了,就会可能拿到的对象的final域是没有初始化的)(盲猜也是Lock前缀,全屏障)
2. (没明白,可以不用说)初次读这个对象的final域之前,加入一个load-Store屏障。(如果不加屏障就可能会重排序了,就会可能拿到的对象的final域是没有初始化的)
题外话,需要注意Final的使用方法:
Final的成员变量的注意事项:
1.
该成员变量必须在创建对象之前进行赋值,否则编译失败。
即定义成员变量的时候手动赋值 或者 利用构造器对成员变量进行赋值
2.
final变量是属于对象的,意思是同一个类的两个对象的各自final变量可以是不相同的。
5. 硬件层面需要解决两个问题之一:缓存一致性问题:(CPU之间横向层面,多核操作同一变量的问题)
问题产生原因:CPU1缓存与CPU2缓存之间数据不同步的问题。
解决方式1(不推荐):通过在总线加LOCK#锁的方式(因为会变成单核CPU,不推荐)
解决方式2(采用):MESI(缓存一致性协议)+Store Buffer(缓冲区)+Invalidate Queue
MESI协议:
Store Buffer & Invalidate Queue为MESI 提供了异步解决方案,强调的是异步。
Store Buffer:读写时的更高级缓存
Invalidate Queue:而当一个CPU核收到Invalid消息时,会把消息写入自身的Invalidate Queue中,随后异步将其设为Invalid状态(具体什么时候未知)。
Invalid状态:非法
Share状态 :正在被共享
Exclusive状态:正在被独占
Modified状态:缓存行已被修改,但是还未写入主存。
CPU向缓存写数据时,
先写入Store-Buffer,
如果该缓存行是Invalid,则从主存中获取并刷新缓存先,再把自己缓存行设置为Share。
如果该缓存行是Share ,就把其他CPU的这条缓存行都设置为Invalid,然后自己缓存行变为Exclusive。
如果该缓存行是Exclusive,就把该缓存行设置为Modified,写入缓存行,然后异步写入主存(具体什么时候未知),然后把自己缓存行设置为Exclusive。
如果该缓存行是Modified,就先等待异步写入主存后(具体什么时候未知),再变为Exclusive先。
CPU从缓存读数据时,
先扫描Store-Buffer,如果没找到就去找缓存,
如果该缓存行是Invalid,则从主存中获取并刷新缓存,变为Share 。
如果该缓存行是Share ,则直接读。
如果该缓存行是Exclusive ,则直接读。
如果该缓存行是Modified,需要等待变成Exclusive才可以读。
缺点1:当一个CPU核收到Invalid消息时,会把消息写入自身的Invalidate Queue中,随后异步将其设为Invalid状态(具体什么时候未知)。这个期间可能就会发生读取数据的操作,而此时的数据是脏数据。
缺点2:当CPU向缓存写数据时,在Modified之后&Exclusive之前,异步写入主存(具体什么时候未知),而此时别人可能从主存读取了脏数据。
6. 硬件层面需要解决两个问题之二: 指令重排问题:(时间纵向层面,多核操作同一变量的问题)
问题原因之编译器重排:
由于编译器只需要满足JMM的as-if-serial规则,
即,在单线程下不能改变结果。
所以默认允许了指令重排序。
但是会导致多线程下出现问题。
问题原因之处理器重排:
为了优化CPU运算效率,CPU在保证运算结果不变的情况下,允许指令重排。
X86默认只允许Store-Load形式的指令重排。不允许Load-Load,Load-Store,Store-Load形式的指令重排。
但是仍会导致多线程下出现问题。
解决方式1:Volatile语义2,即内存屏障。(见上文)
应用举例:Volatile+DCL
解决方式2:Final语义。(见上文)
解决方式3:Synchronized(lock同理)
但是有局限性。
synchronized(lock同理)只是把多线程执行一个块(lock的trycatch块)变为对于单线程执行一个块(lock的trycatch块)。
synchronized(lock同理)保证的是线程1块对线程2的同一个块(lock的trycatch块)不重排,但是块内部的逻辑就不能保证不重排了。
解决方式4:java自带的happenbefore原则
7. 硬件层面需要解决两个问题之总结:
MESI(CPU之间横向层面,多核操作同一变量的问题,解决多核操作同一变量的问题)+内存屏障(时间纵向层面,解决多核操作同一变量的问题)组成了x86的解决方式。
其中MESI是必然发生的,而内存屏障是可以我们手动加上的(Volatile)。
Synchronized和Lock是JVM的解决方式
8. JMM层面要求代码需要满足三个特性之一:原子性
解决方式1:Synchronized修饰(lock同理)
每一个synchronized块(lock的trycatch块),都是一整个原子操作。
解决方式2:CAS
cmpxchg一个指令完成了比较和交换两个操作。
解决方式3:AQS(内部使用了Volatile+CAS维护State的改变+同步队列的节点状态、节点前后、头尾节点等)
9. JMM层面要求代码需要满足三个特性之二:可见性
解决方式1:Volatile
Volatile语义1.(见上文)
解决方式2:Synchronized(lock同理)
但是有局限性。
synchronized(lock同理)只是把多线程执行一个块(lock的trycatch块)变为对于单线程执行一个块(lock的trycatch块)
synchronized(lock同理)保证的是线程1块对线程2的同一个块可见。不能保证块内的第一行对第二行可见。
解决方式3:final
final语义(见上文)
解决方式4:AQS(内部使用了Volatile+CAS维护State的改变+同步队列的节点状态、节点前后、头尾节点等)
10. JMM层面要求代码需要满足三个特性之三:有序性
解决方式1:Volatile语义2,即内存屏障。(见上文)
应用举例:Volatile+DCL
解决方式2:Final语义。(见上文)
解决方式3:Synchronized(lock同理)
但是有局限性。
synchronized(lock同理)只是把多线程执行一个块(lock的trycatch块)变为对于单线程执行一个块(lock的trycatch块)。
synchronized(lock同理)保证的是线程1块对线程2的同一个块(lock的trycatch块)不重排,但是块内部的逻辑就不能保证不重排了。
解决方式4:java自带的happens-before原则
解决方式5:AQS(内部使用了Volatile+CAS维护State的改变+同步队列的节点状态、节点前后、头尾节点等)
11. Happens-Before规则:
为了实现有序性,我们可以使用Volatile或Synchronized或final,但是这样对程序员不友好,因为代码会很烦琐。为了辅助Volatile或Synchronized或final,所以Java语言自带了Happens-Before规则:。
Happens-Before规则的意思是,java天生自带了某些情况下的两个操作的前后可见,
即假如A happens- before B,则A对于B是可见的。但是并不表示A必须在B之前执行。
意思是,可以重排,但是不能影响我们两者的有序性,所以其实也一定程度地约束了不允许重排。
至于Java是怎么保证AB有序性的(或者叫A对于B的可见性),盲猜是使用了JMM的四种内存屏障吧。
程序顺序规则:在一个线程内,
前:前面的操作,后:后面的操作。
Synchronize规则:对于一个monitor锁,
前:unlock,后:lock。
Volatile规则:对于一个 volatile变量,
前:写,后:读。
线程启动规则:对于一个Thread对象,
前:Thread.start,后:Thread的内部方法被调用。
线程中断规则:对于一个Thread对象,
前:Thread.interrupt,后:interrupt被检测到
线程终止规则:对于一个Thread对象t1,还有一个线程t2在t1内部运行t2.join,
前:t2的所有操作,后:t2.join结束后,t1恢复
对象终结原则:对于一个对象,
前:对象初始化,后:对象执行finalize
传递性:对于操作A先于操作B,并且,操作B先于操作C,则操作A先于操作C


 浙公网安备 33010602011771号
浙公网安备 33010602011771号