spark(三)-spark算子
• RDD(Resilient Distributed Dataset )• 五大特性:
– A list of partitions
– A function for computing each partition
– A list of dependencies on other RDDs
– Optionally, a Partitioner for key-value RDDs• shuffle的时
– Optionally, a list of preferred locations to compute each split on• task计算的数据本地化

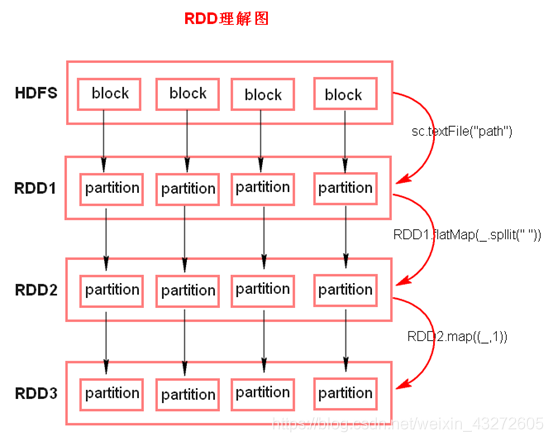
RDD里截图:
注意:
- textFile方法底层封装的是读取MR读取文件的方式,读取文件之前先split,默认split大小是一个block大小。
- RDD实际上不存储数据,这里方便理解,暂时理解为存储数据。
- 什么是K,V格式的RDD?
如果RDD里面存储的数据都是二元组对象,那么这个RDD我们就叫做K,V格式的RDD。 - 哪里体现RDD的弹性(容错)?
- partition数量,大小没有限制,体现了RDD的弹性。
- RDD之间依赖关系,可以基于上一个RDD重新计算出RDD。
- 哪里体现RDD的分布式?
- RDD是由Partition组成,partition是分布在不同节点上的。
- RDD提供计算最佳位置,体现了数据本地化。体现了大数据中“计算移动数据不移动”的理念。
Transformations转换算子
Transformations类算子是一类算子(函数)叫做转换算子,如map,flatMap,reduceByKey等。Transformations算子是延迟执行,也叫懒加载执行。
filter
过滤符合条件的记录数,true保留,false过滤掉。
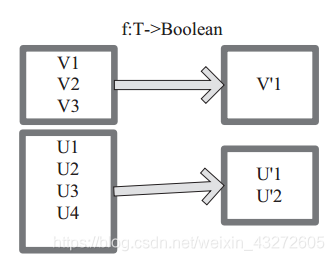
filter 函数功能是对元素进行过滤,对每个 元 素 应 用 f 函 数, 返 回 值 为 true 的 元 素 在RDD
中保留,返回值为 false 的元素将被过滤掉。
内 部 实 现 相 当 于 生 成 FilteredRDD(this,sc.clean(f))。
下面代码为函数的本质实现: deffilter(f:T=>Boolean):RDD[T]=newFilteredRDD(this,sc.clean(f))
上图中每个方框代表一个 RDD 分区, T 可以是任意的类型。通过用户自定义的过滤函数 f,对每个数据项操作,将满足条件、返回结果为 true 的数据项保留。例如,过滤掉 V2 和 V3 保留了 V1,为区分命名为 V’1。
比如下面这个例子。
map
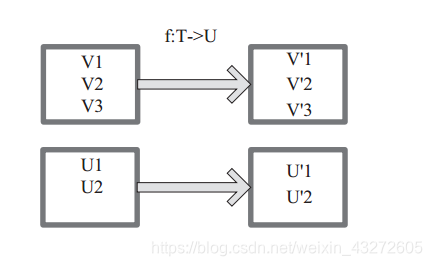
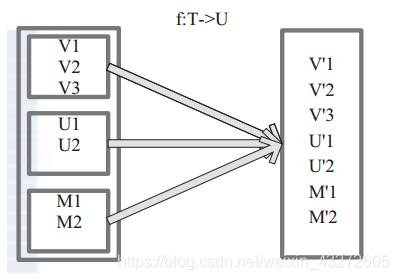
将一个RDD中的每个数据项,通过map中的函数映射变为一个新的元素。 特点:输入一条,输出一条数据。
图 中每个方框表示一个 RDD 分区,左侧的分区经过用户自定义函数 f:T->U 映射为右侧的新 RDD 分区。但是,实际只有等到 Action算子触发后,这个 f 函数才会和其他函数在一个stage 中对数据进行运算。在图 1 中的第一个分区,数据记录 V1 输入 f,通过 f 转换输出为转换后的分区中的数据记录 V’1。
flatMap
先map后flat。与map类似,每个输入项可以映射为0到多个输出项。
将原来 RDD 中的每个元素通过函数 f 转换为新的元素,并将生成的 RDD 的每个集合中的元素合并为一个集合,内部创建 FlatMappedRDD(this,sc.clean(f))。
图中表 示 RDD 的 一 个 分 区 ,进 行 flatMap函 数 操 作, flatMap 中 传 入 的 函 数 为 f:T->U, T和 U 可以是任意的数据类型。将分区中的数据通过用户自定义函数 f 转换为新的数据。外部大方框可以认为是一个 RDD 分区,小方框代表一个集合。 V1、 V2、 V3 在一个集合作为 RDD 的一个数据项,可能存储为数组或其他容器,转换为V’1、 V’2、 V’3 后,将原来的数组或容器结合拆散,拆散的数据形成为 RDD 中的数据项。
上面这个例子,就是对于lines中一共有三个分区:
第一个分区:“ak gh” “hh rr”
第二个分区:“tt rtwer”,“mm gsfg”,“qq dlee”,
第三个分区:“dfsa pp”,“ade qjid”,“sdf laow”
三个分区是一个RDD,当对它使用flatmap时,就是对RDD的每一个分区作用,将某一个分区的不同部分操作,然后组成一个集合,比如对第一个分区,将每个字符串用空格分离,然后组成一个字符串集合。
每一个分区都组成了一个集合。
sample
sample 将 RDD
这个集合内的元素进行采样,获取所有元素的子集。用户可以设定是否有放回的抽样、百分比、随机种子,进而决定采样方式。
内部实现是生成
SampledRDD(withReplacement, fraction, seed)。
函数参数设置:
withReplacement=true,表示有放回的抽样。
withReplacement=false,表示无放回的抽样。
fraction:用来抽取百分之多少的数据,0-1之间
seed:如果针对同一批数据源,则对于同样的参数,抽取的数据永远一样,只要所有参数一样。这主要针对一个公司有一个公共数据集,每个人写的算法从中抽取相同数据来比较谁的好。
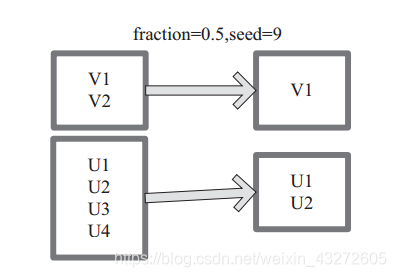
图 中 的 每 个 方 框 是 一 个 RDD 分 区。 通 过 sample 函 数, 采 样 50% 的 数 据。V1、 V2、
U1、 U2、U3、U4 采样出数据 V1 和 U1、 U2 形成新的 RDD。
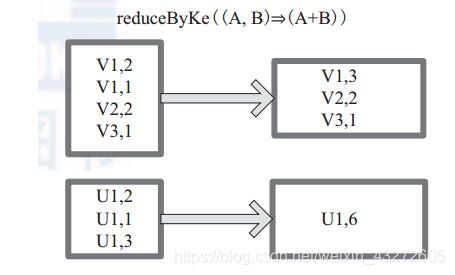
reduceByKey
reduceByKey 是比 combineByKey 更简单的一种情况,只是两个值合并成一个值
( Int, Int V)to (Int, Int C)
比如叠加。所以 createCombiner reduceBykey 很简单,就是直接返回 v,而 mergeValue和 mergeCombiners 逻辑是相同的,没有区别。
图中的方框代表 RDD 分区。通过用户自定义函数 (A,B) => (A + B) 函数,将相同 key 的数据 (V1,2) 和 (V1,1) 的 value 相加运算,结果为( V1,3)。
reducebykey可以将所有分区里面key值相同的聚集到一块,然后将它进行用户定义的聚合操作,这种聚合操作((v1,v2)=>{v1+v2})就是针对每一个key值,轮回迭代,v1+v2的结果作为下一轮回的v1,v2在取下一个相同key的value,知道一个key中的所有value用完。然后再取下一个key进行相同的运算。
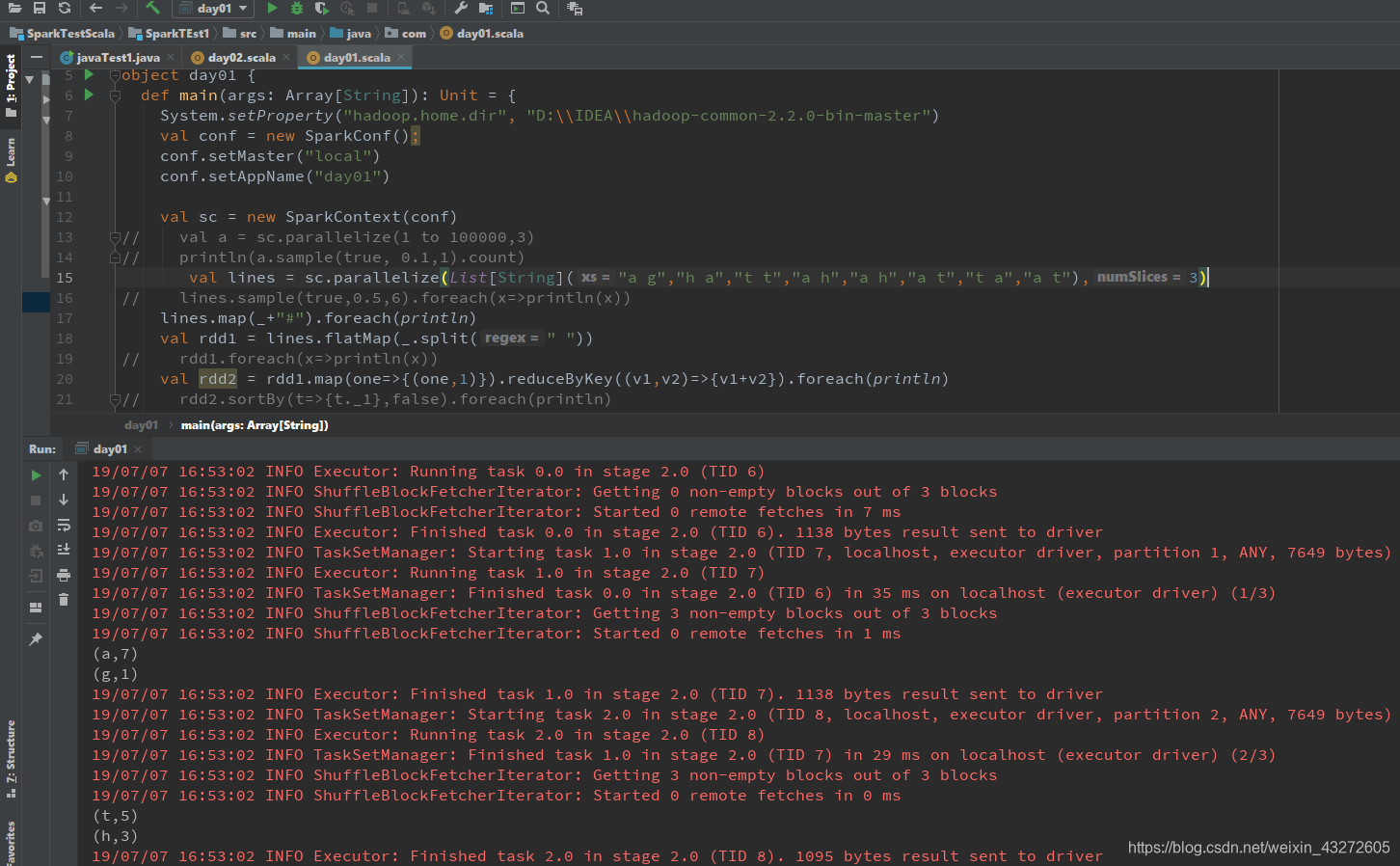
sortByKey/sortBy
sortBy就是根据传递的参数进行排序:
就像下面这个例子,将rdd中的第二个元素,就是单词个数进行排序。
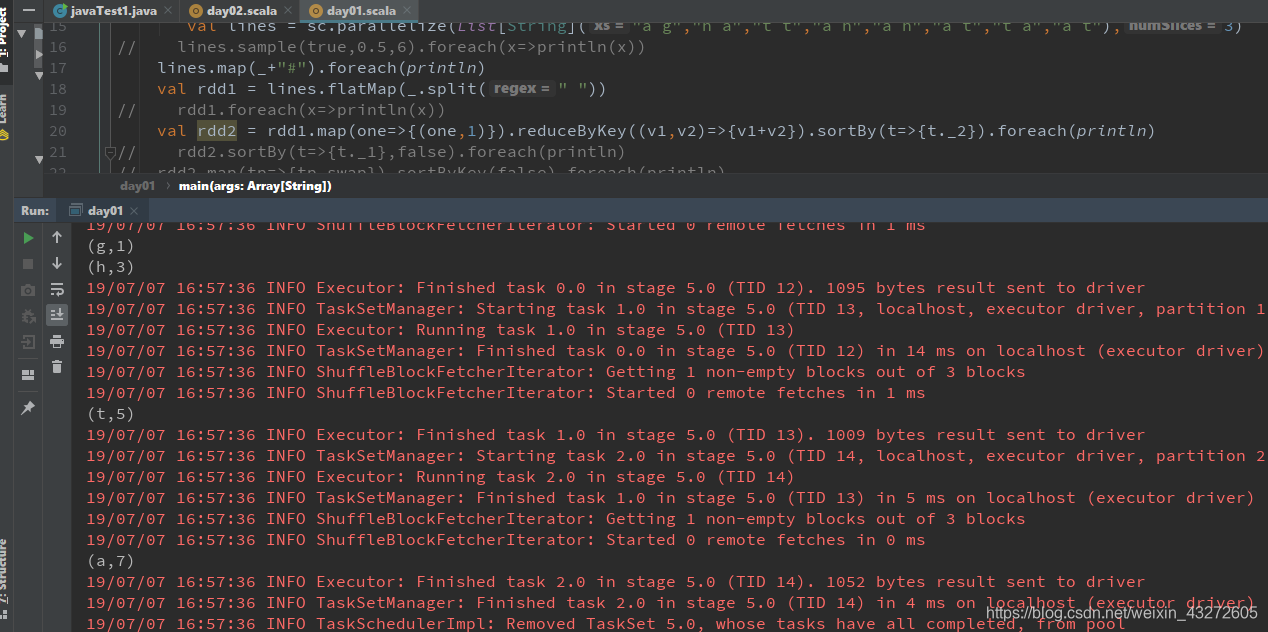
sortBykey就是根据key去排序了。
Action算子
Action类算子也是一类算子(函数)叫做行动算子,如foreach,collect,count等。Transformations类算子是延迟执行,Action类算子是触发执行。一个application应用程序中有几个Action类算子执行,就有几个job运行。
count
返回数据集中的元素数。会在结果计算完成后回收到Driver端
take
返回一个包含数据集前n个元素的集合。
first
first=take(1),返回数据集中的第一个元素。
foreach
循环遍历数据集中的每个元素,运行相应的逻辑
collect
将计算结果回收到Driver端。
持久化算子
控制算子有三种,cache,persist,checkpoint,以上算子都可以将RDD持久化,持久化的单位是partition。cache和persist都是懒执行的。必须有一个action类算子触发执行。checkpoint算子不仅能将RDD持久化到磁盘,还能切断RDD之间的依赖关系。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号