
Flume使用
Flume的安装
首先去官网下载,选择适合自己的版本进行下载。
我下的是1.9.0的
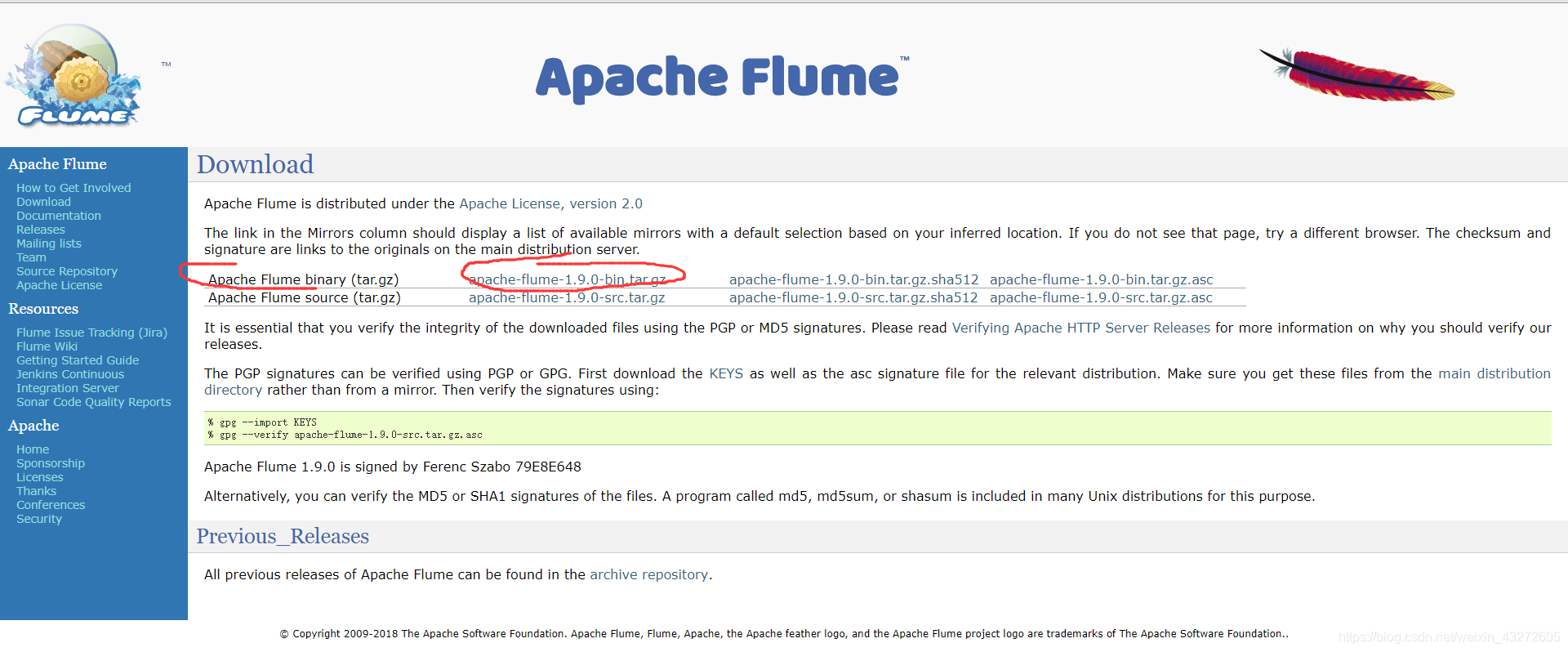
选择二进制版本
然后将其弄到自己的Linux某一文件夹下
将其解压,然后进入到conf目录下面,复制flume-env.sh这个文件的模板,然后编辑它

将其中的javaHOME换成自己的jdk
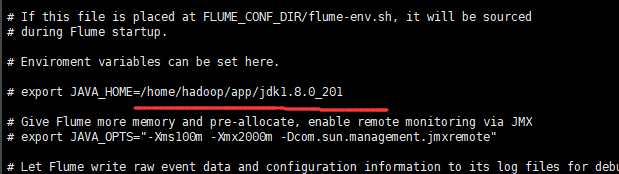
然后安装基本到这里就可以了
Flume的简单使用
我是在flume文件夹下创建了一个dirflume,用于存储配置文件
编辑文件option1
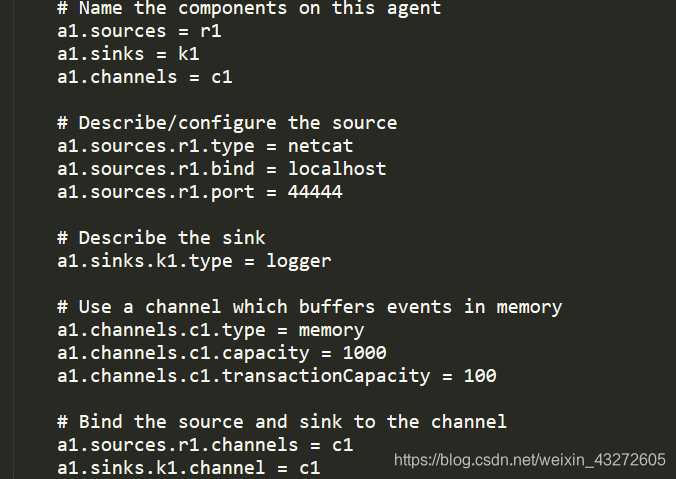
这个配置内容等会儿解释,来测试测试内容,这里监听的是本地的44444端口,然后向本地44444号端口发送消息
bin/flume-ng agent --conf conf/ --name a1 --conf-file dirflume/option1 -Dflume.root.logger==INFO,console
开始监听端口
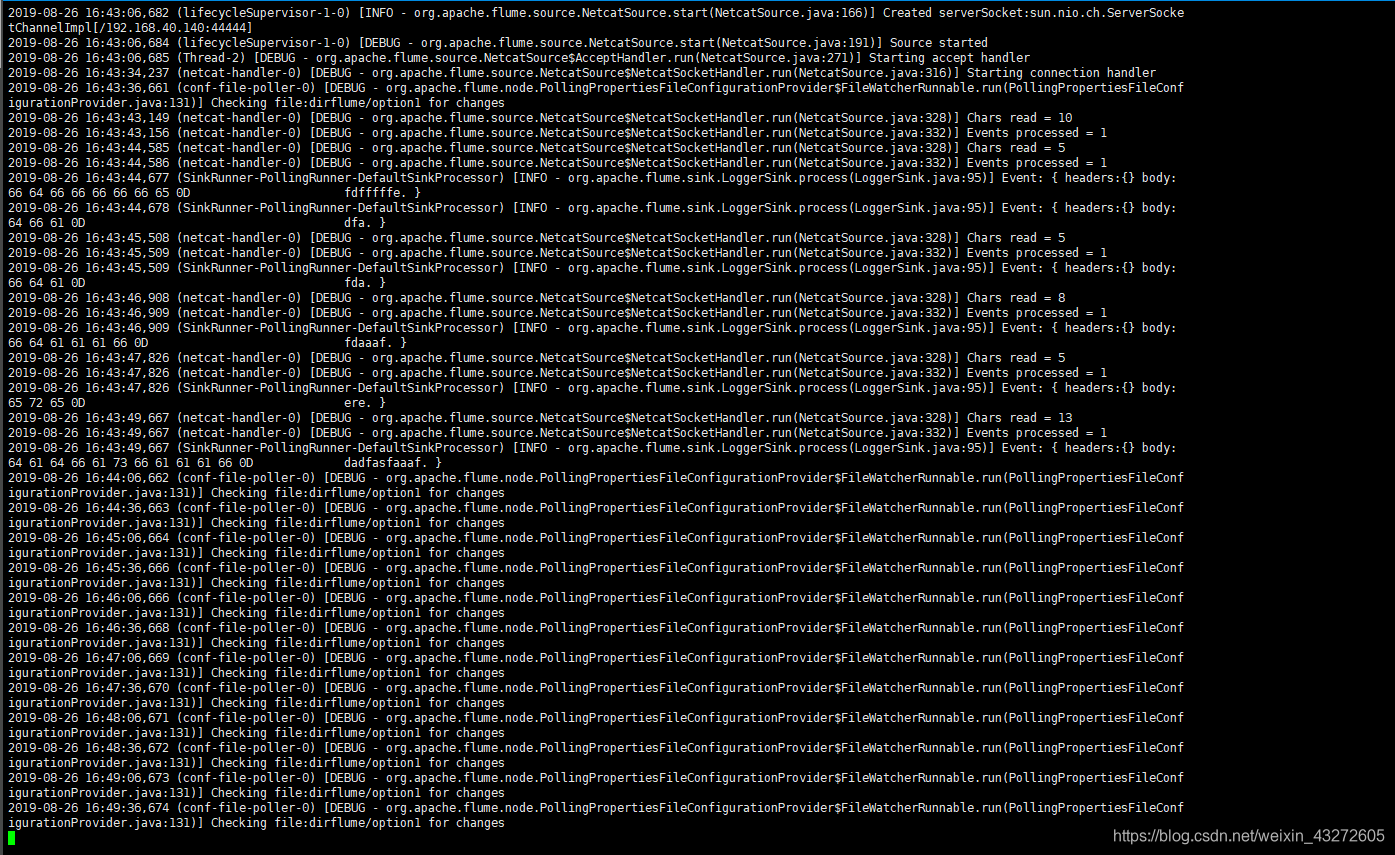
telnet localhost 44444
向44444端口发送消息
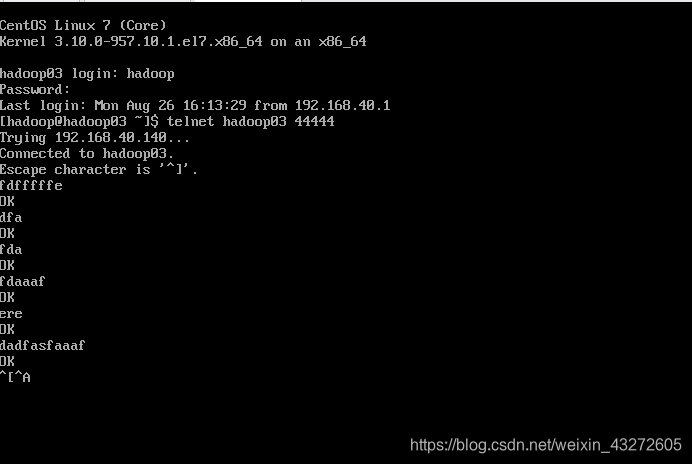
测试成功!!!!
Flume原理
这是flume的数据模型
先来理清楚几个概念
Source:一个数据源
Channel:数据通道
Sink:数据槽
Agent:一个JVM进程,相当于一个从数据源到数据操的过程。
当然一个Agent的Source可以从其他的Agent的Sink接受消息,也可以从其他服务器接受消息。
然后一个Agent的Sink可以将数据写到存储文件里面,比如hdfs,或者写到下一个Agent的Source。
可靠性
flume提供的是可靠的运输。它的数据传输是事务性的,而且只有数据全部到了Sink的时候,Channel才会把它的数据删除
可恢复性
flume支持持久化的Channel,借由本地文件系统。也可以放在内存通道,但是不可以恢复。
我们还是来看看测试案例
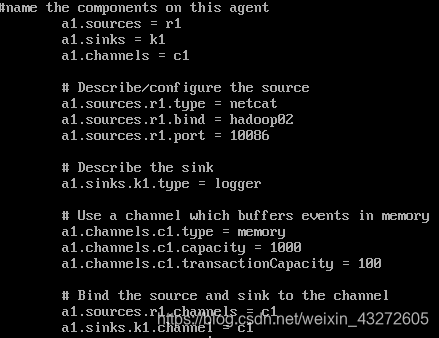
解释一些配置文件的意思
前三行命名+定义
a1就是我们给Agent取得名字,而Agent有三个Component(Source,Channel,Sink)
分别给他们指向r1,k1,c1
而我们接下来配置
Source的数据接受类型,来源(IP,端口号)
Sink的输出数据类型等等
Channel的存储方式,容量等等。
再将Source和Sink通过Channel联系起来。
测试:
bin/flume-ng agent --conf conf/ --name a1 --conf-file dirflume/option -Dflume.root.logger=INFO,console这样flume的这个Agent就不断监听hadoop02的10086端口,等待数据写过来。
假设我们用hadoop03通过telnet向hadoop02的10086端口些信息,那么看看是否能够接受到。
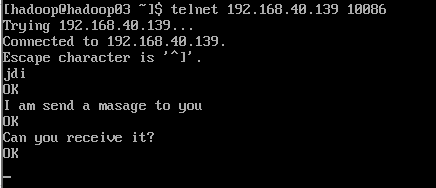
下面就是通过hadoop02的控制台打印的日志信息。能够将每一条消息打印,并且还给了你17进制的编码。多好!!!!

注意我们的参数命令:
--conf是flume的配置,有log4j-properties还有flume-env.sh运行脚本
而--conf-file是一个Agent的配置信息了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号