Flink Do It!!
官网:flink.apache.org

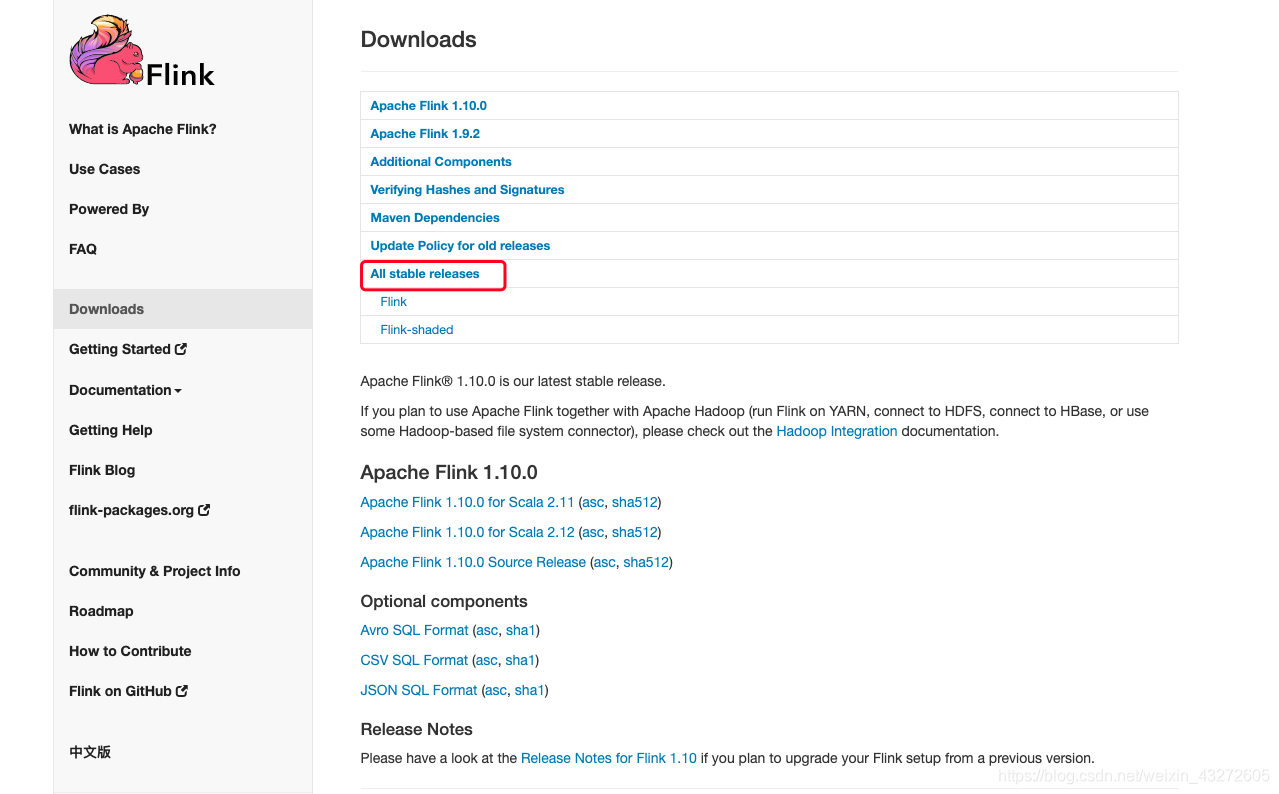
选择你自己想要的版本
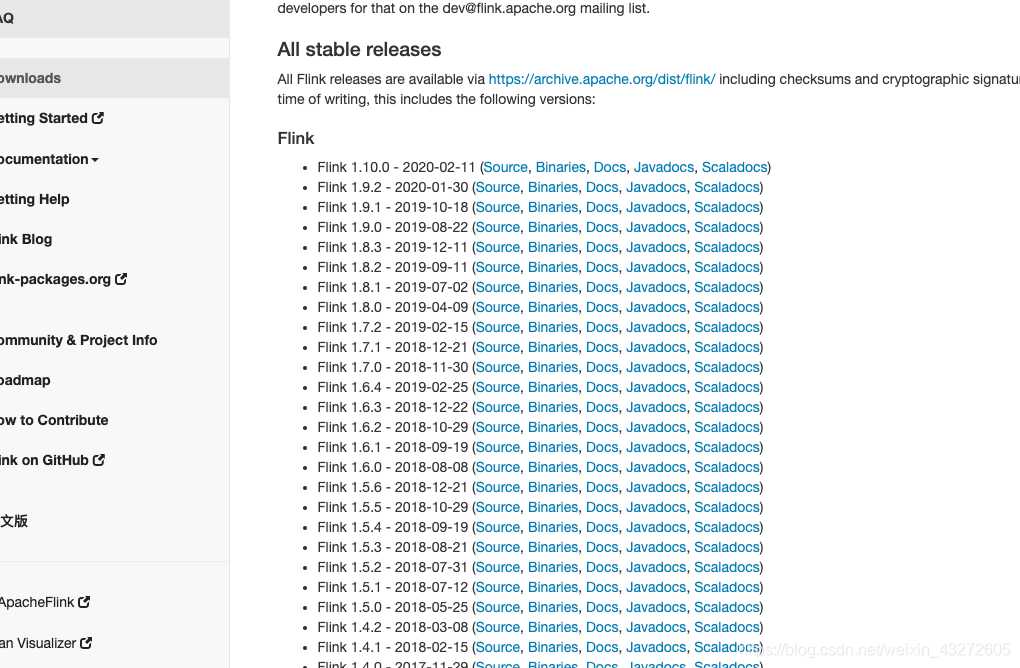
下载之后,就解压
执行命令
./start-cluster
看到这两个进程,说明单节点运行没问题,也就是伪分布咯。
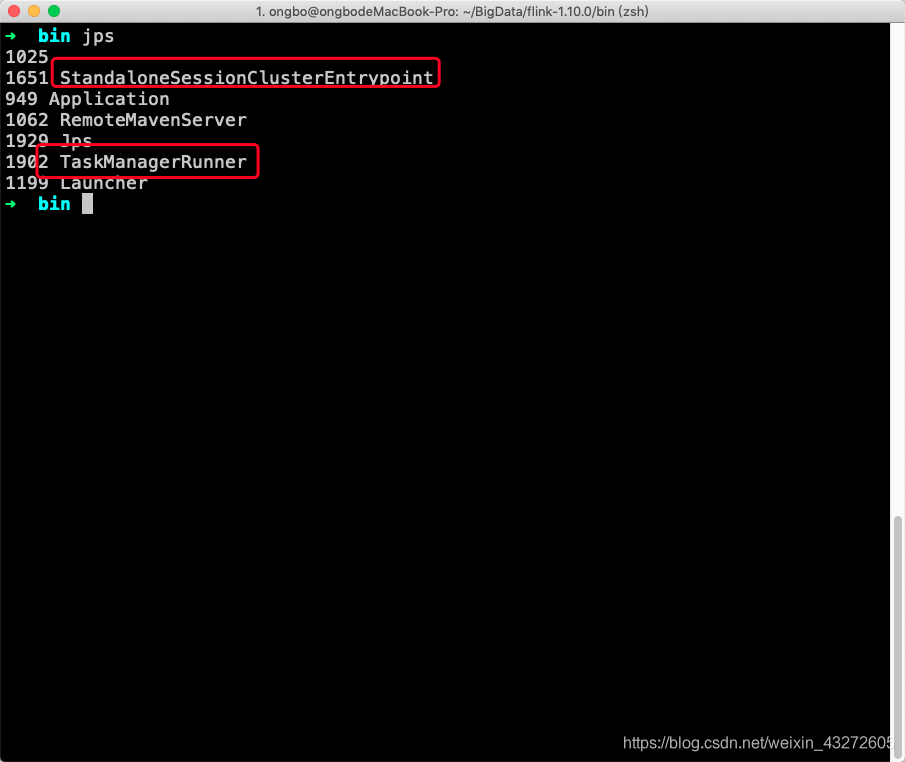
访问IP:8081(默认端口是8081)
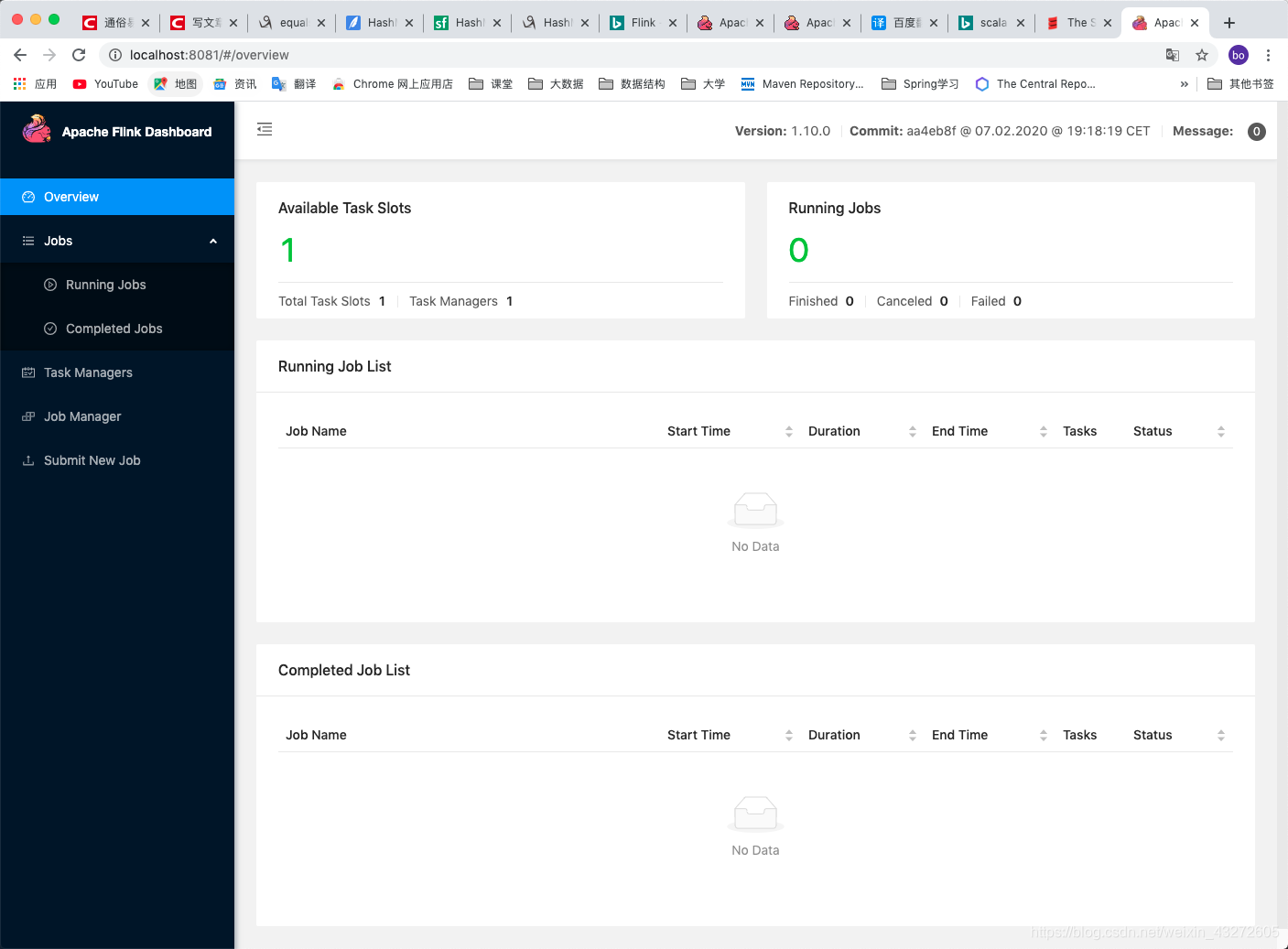
在集群执行程序
先上代码:用的IDEA,而且是Maven项目
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>FlinkDemo</groupId>
<artifactId>FlinkDemo</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>1.10.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.10.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.11</artifactId>
<version>1.10.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.11</artifactId>
<version>1.10.0</version>
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.6.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.1.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<mainClass>flinkjava.flinkWord</mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
代码如下
package flinkjava;
/*
* 滑动窗口计算
*
* 通过socket模拟产生数据
* flink对数据进行统计计算
*
* 实现每隔一秒统计前两秒的的数据进行汇总运算
* */
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
public class flinkWord {
public static void main(String[] args) {
//获取需要的端口号
int port = 0;
try {
ParameterTool parameterTool = ParameterTool.fromArgs(args);
port = parameterTool.getInt("port");
}catch (Exception e){
System.out.println("#########################################");
System.out.println("##No port set,user default port 9000!!!##");
System.out.println("#########################################");
port = 9000;
}
//获取Flink流运行环境
StreamExecutionEnvironment streamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
//添加源Source
String hostname = "localhost";
String delimiter = "\n";
//获取监控socket输出入的数据
DataStreamSource<String> text = streamExecutionEnvironment.socketTextStream(hostname, port, delimiter);
//这个返回值的数据类型是DataStream
SingleOutputStreamOperator<WordWithCount> sum = text.flatMap(new FlatMapFunction<String, WordWithCount>() {
public void flatMap(String s, Collector<WordWithCount> collector) throws Exception {
String[] splits = s.split("\\s");
for (String word : splits) {
collector.collect(new WordWithCount(word, 1));
}
}
}).keyBy("word")
.timeWindow(Time.seconds(2), Time.seconds(1))//间隔一秒,窗口是2秒
.sum("count");//在这里使用sum或者reduce都可以
// .reduce(new ReduceFunction<WordWithCount>() {
// public WordWithCount reduce(WordWithCount wordWithCount, WordWithCount t1) throws Exception {
// return new WordWithCount(wordWithCount.word,wordWithCount.count+t1.count);
// }
// });
//把数据打印到控制台,并且设置并行度。
sum.print().setParallelism(1);
try {
//触发执行,延迟计算。
streamExecutionEnvironment.execute("socket_Window count");
} catch (Exception e) {
e.printStackTrace();
}
}
public static class WordWithCount{
public String word;
public Integer count;
public WordWithCount(String word, Integer count){
this.word = word;
this.count = count;
}
public WordWithCount(){
}
@Override
public String toString() {
return "WordWithCount{" +
"word='" + word + '\'' +
", count=" + count +
'}';
}
}
}
这时候,将我们之前的代码来打包弄到集群去运行
打jar包就不多介绍了。直接上命令

在Web端看看:
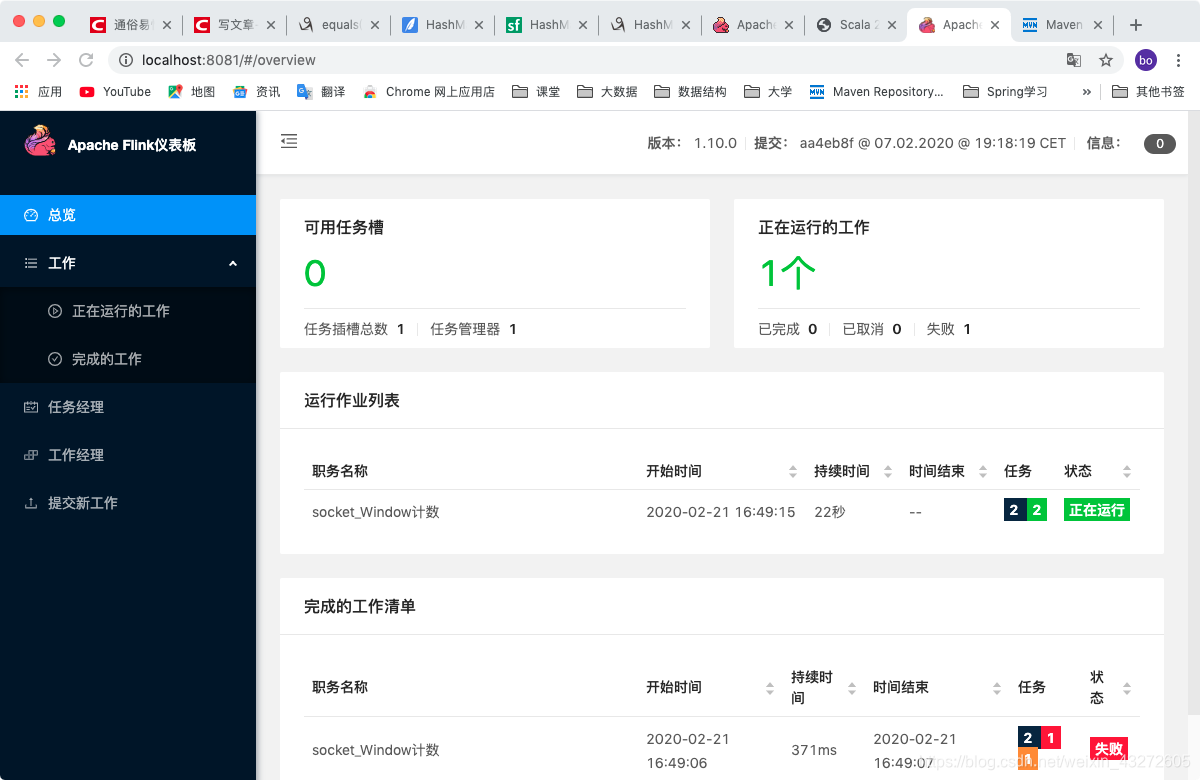
窗口还是挺好看的,各种界面相对比spark和hadoop要好看。这时候,我们在IDEA里面写的代码虽然是pring可以输出到控制台,但是在命令行是看不到的,这时候在Web界面可以看到
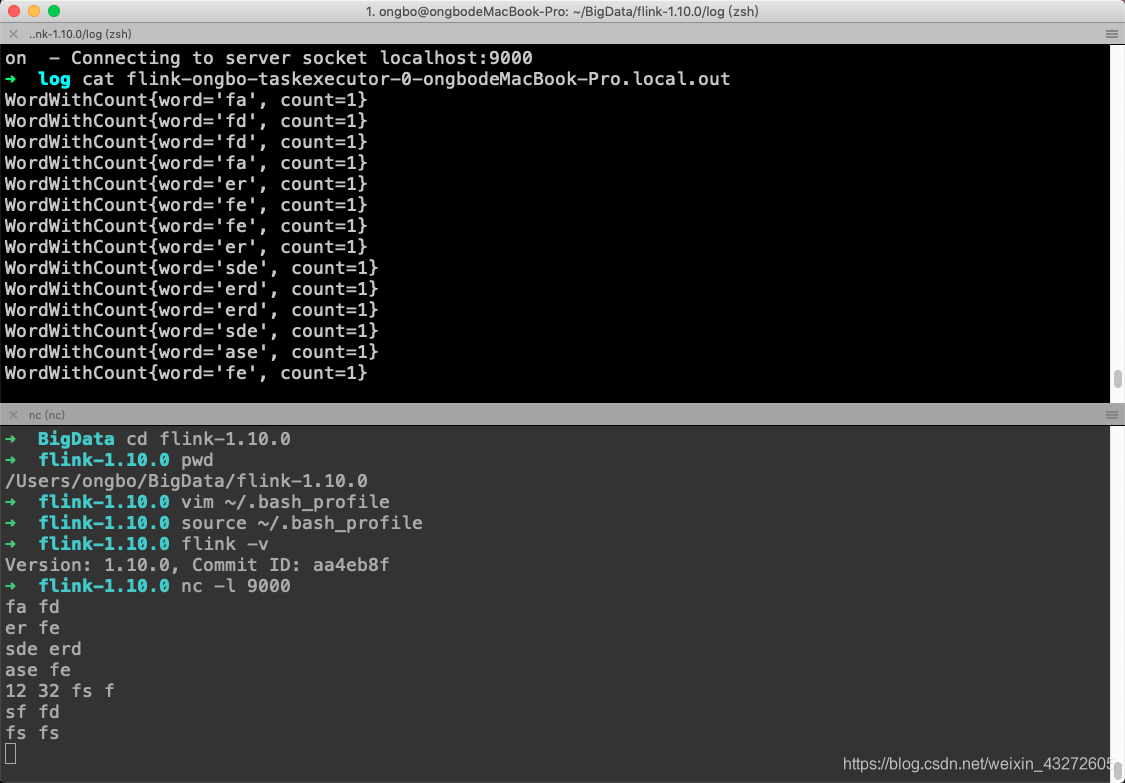
在TaskManager的Stdout下。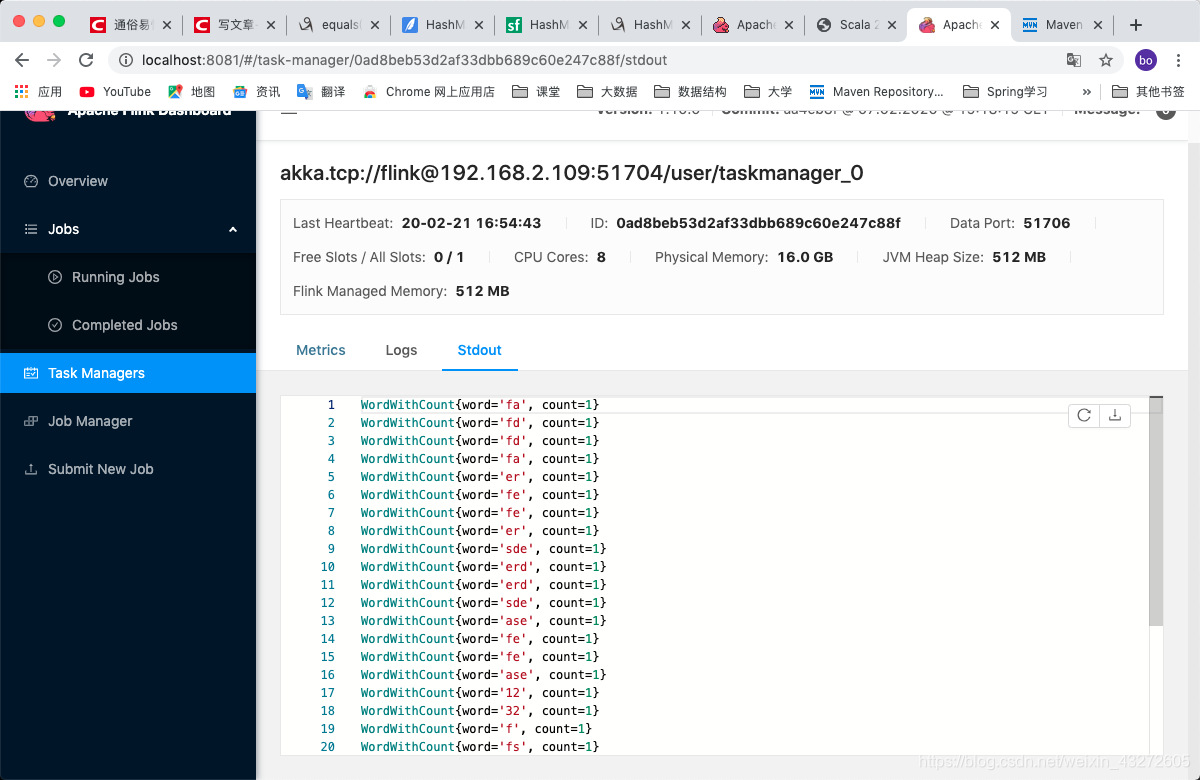
或者在flink日志文件中查看也可以的。
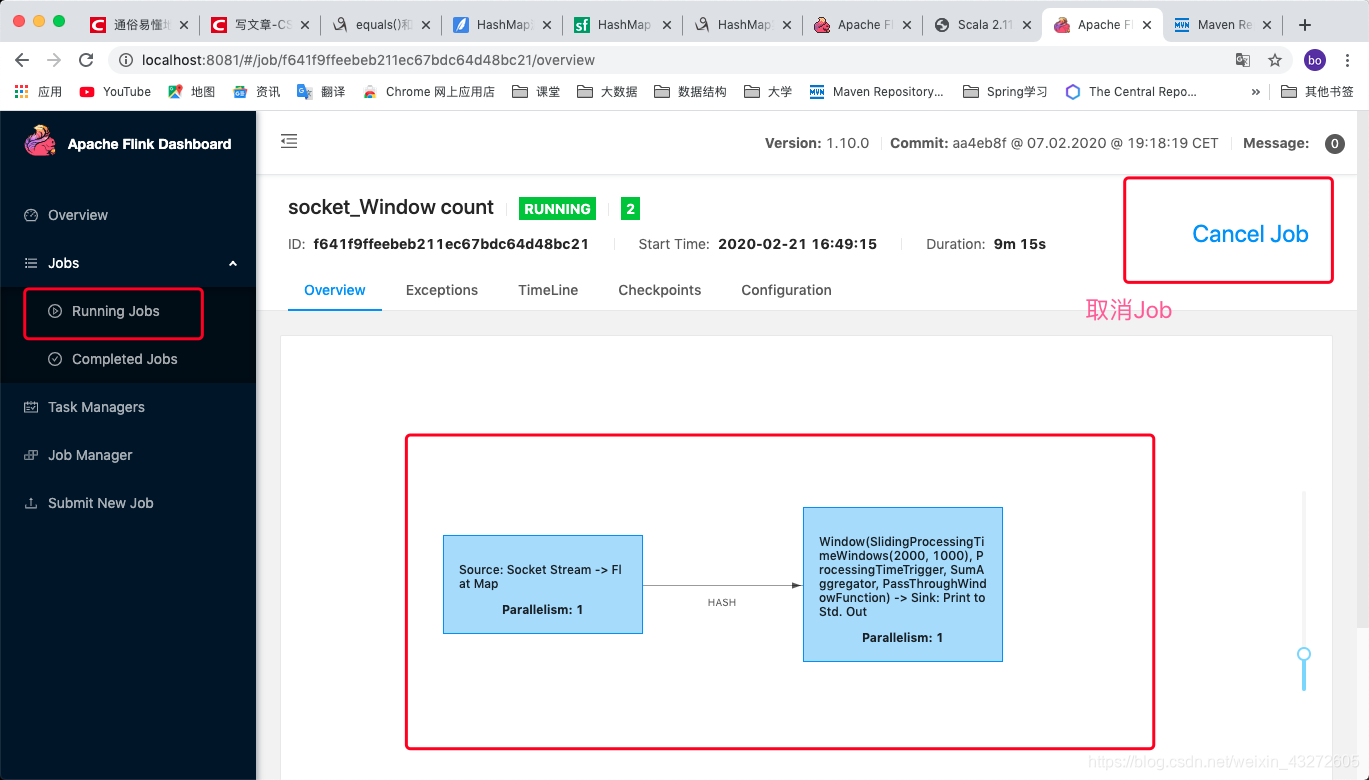
在Running Job里面,可以Cancel Job。还可以看执行图
Flink环境搭建
之前的小实验不过是一个Stanlone的环境方式,只有一个节点,做做测试可以 用,下面看看Flink的集群。
Flink的环境有Standlone,cluster,cloud
现在重点看看cluster,cluster有普通集群,还有基于yarn

 浙公网安备 33010602011771号
浙公网安备 33010602011771号