
python学习第六天 数据类型(集合,内存相关)
day06 数据类型
今日内容
- 集合
- 内存相关 注意是重新fuzhi还是内部修改
- 深浅拷贝
内容补充
-
列表功能
-
reverse 反转
v1 = [1,2,2,4,4,4,5,5] v1.reverse() print(v1) -
sort() 可以根据数字大小排序😂
v1 = [11,22,3111,32,13] print(v1) # v1.sort(reverse=False) # 从小到大(默认) # v1.sort(reverse=True) # 从大到小 # print(v1)
-
-
字典
-
keys/values/items
-
.get
info = {} info.get(k1,111)- pop
info = {'k1':'v1','k2':'v2'} result = info.pop('k2') print(info,result) del info['k1']- update
info = {'k1':'v1','k2':'v2'} # 不存在,则添加/存在,则更新 info.update({'k3':'v3','k4':'v4','k2':666}) print(info)-
判断一个字符传中是否有敏感字符
-
str 字符串
v = "Python全栈21期" if "全栈" in v: print('含敏感字符') -
list/tuple 列表/元祖
v = ['alex','oldboy','张三','李四'] if "张三" in v: print('含敏感') -
dict 字典
v = {'k1':'v1','k2':'v2','k3':'v3'} # 默认按照键判断,即:判断x是否是字典的键。 if 'x' in v: pass # 请判断:k1 是否在其中? if 'k1' in v: pass # 请判断:v2 是否在其中? # 方式一:循环判断 flag = '不存在' for v in v.values(): if v == 'v2': flag = '存在' print(flag) # 方式二: if 'v2' in list(v.values()): # 强制转换成列表 ['v1','v2','v3'] pass # 请判断:k2:v2 是否在其中? value = v.get('k2') if value == 'v2': print('存在') else: print('不存在') -
练习题
# 让用户输入任意字符串,然后判断此字符串是否包含指定的敏感字符。 char_list = ['张三','李四','刘五'] content = input('请输入内容:') # 我叫张三 / 我是李四 / 我要刘五 success = True for v in char_list: if v in content: success = False break if success: print(content) else: print('包含铭感字符') # 示例: # 1. 昨天课上最后一题 # 2. 判断 ‘v2’ 是否在字典的value中 v = {'k1':'v1','k2':'v2','k3':'v3'} 【循环判断】 # 3. 敏感字
-
-
内容详细
1.集合 set
- 无序
- 无重复
v = {1,2,3,4,5,6,99,100}
# 疑问:v = {} """
None
int
v1 = 123
v1 = int() --> 0
bool
v2 = True/False
v2 = bool() -> False
str
v3 = ""
v3 = str()
list
v4 = []
v4 = list()
tuple
v5 = ()
v5 = tuple()
dict
v6 = {}
v6 = dict()
set
v7 = set() """
空字符串写法
-
集合独有功能
- add 添加,不会生成新的变量
- discard 删除,不会生成新的变量
- update 更新,不会生成新的变量
- intersection 交集
- union 并集
- difference 差集
-
公共功能
-
len
v = {1,2,'李邵奇'} print(len(v)) -
for循环
v = {1,2,'李邵奇'} for item in v: print(item) -
索引-无
-
不长-无
-
切片-无
-
删除-无
-
修改-无
-
-
嵌套问题
# 1. 列表/字典/集合 -> 不能放在集合中+不能作为字典的key(unhashable) # info = {1, 2, 3, 4, True, "国风", None, (1, 2, 3)} # print(info) # 2. hash -> 哈希是怎么回事? # 因为在内部会将值进行哈希算法并得到一个数值(对应内存地址),以后用于快速查找。 # 3. 特殊情况 # info = {0, 2, 3, 4, False, "国风", None, (1, 2, 3)} # print(info) # info = { # 1:'alex', # True:'oldboy' #} # print(info)
2.内存相关
-
示例一
v1 = [11,22,33] v2 = [11,22,33] v1 = 666 v2 = 666 v1 = "asdf" v2 = "asdf" # 按理 v1 和 v2 应该是不同的内存地址。特殊: 1. 整型: -5 ~ 256 2. 字符串:"alex",'asfasd asdf asdf d_asdf ' ----"f_*" * 3 - 重新开辟内存。
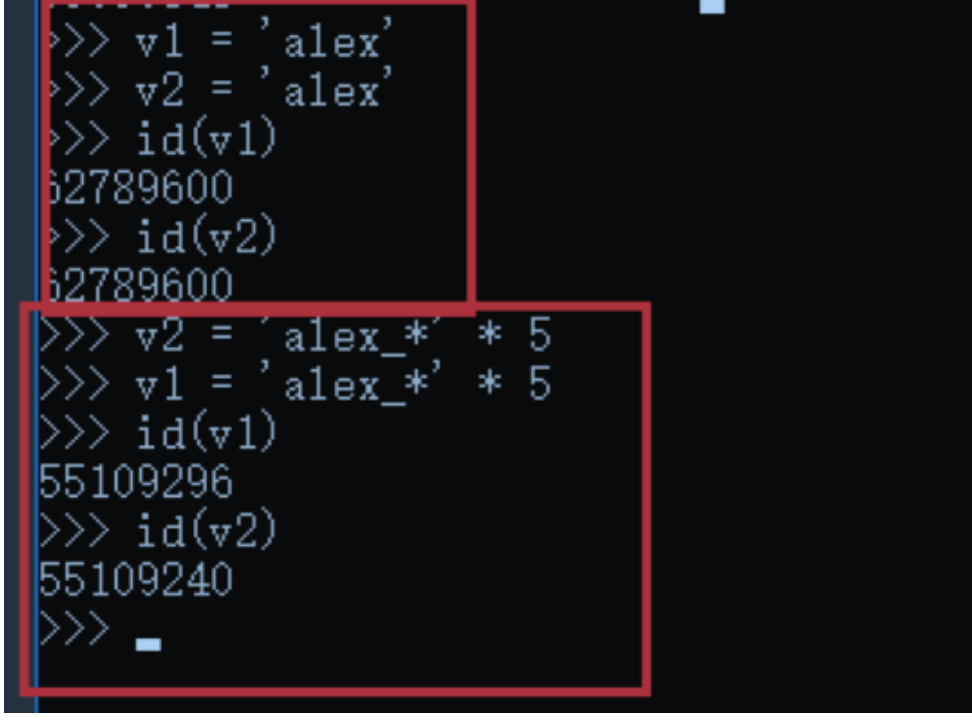
-
示例二
v1 = [11,22,33,44] v1 = [11,22,33] -
示例三
v1 = [11,22,33] v2 = v1 # 练习1 (内部修改) v1 = [11,22,33] v2 = v1 v1.append(666) print(v2) # 含 666 # 练习2:(赋值) v1 = [11,22,33] v2 = v1 v1 = [1,2,3,4] print(v2) # 练习3:(重新赋值) v1 = 'alex' v2 = v1 v1 = 'oldboy' print(v2) -
示例四
v = [1,2,3] values = [11,22,v] # 练习1: """ v.append(9) print(values) # [11,22,[1,2,3,9]] """ # 练习2: """ values[2].append(999) print(v) # [1, 2, 3, 999] """ # 练习3: """ v = 999 print(values) # [11, 22, [1, 2, 3]] """ # 练习4: values[2] = 666 print(v) # [1, 2, 3] -
示例五
v1 = [1,2] v2 = [2,3] v3 = [11,22,v1,v2,v1] -
查看内存地址
""" v1 = [1,2,3] v2 = v1 v1.append(999) print(v1,v2) print(id(v1),id(v2)) """ """ v1 = [1,2,3] v2 = v1 print(id(v1),id(v2)) v1 = 999 print(id(v1),id(v2)) """ -
问题:==跟is有什么区别
- ==用于比较值是否相等
- is用于比较内存地址是否相等
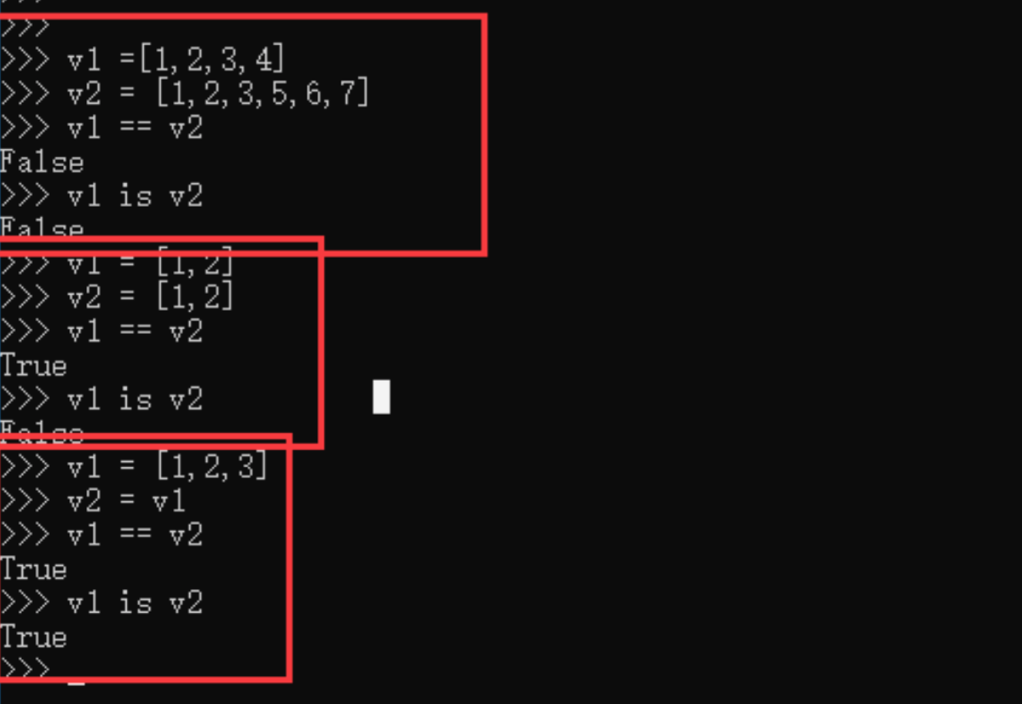
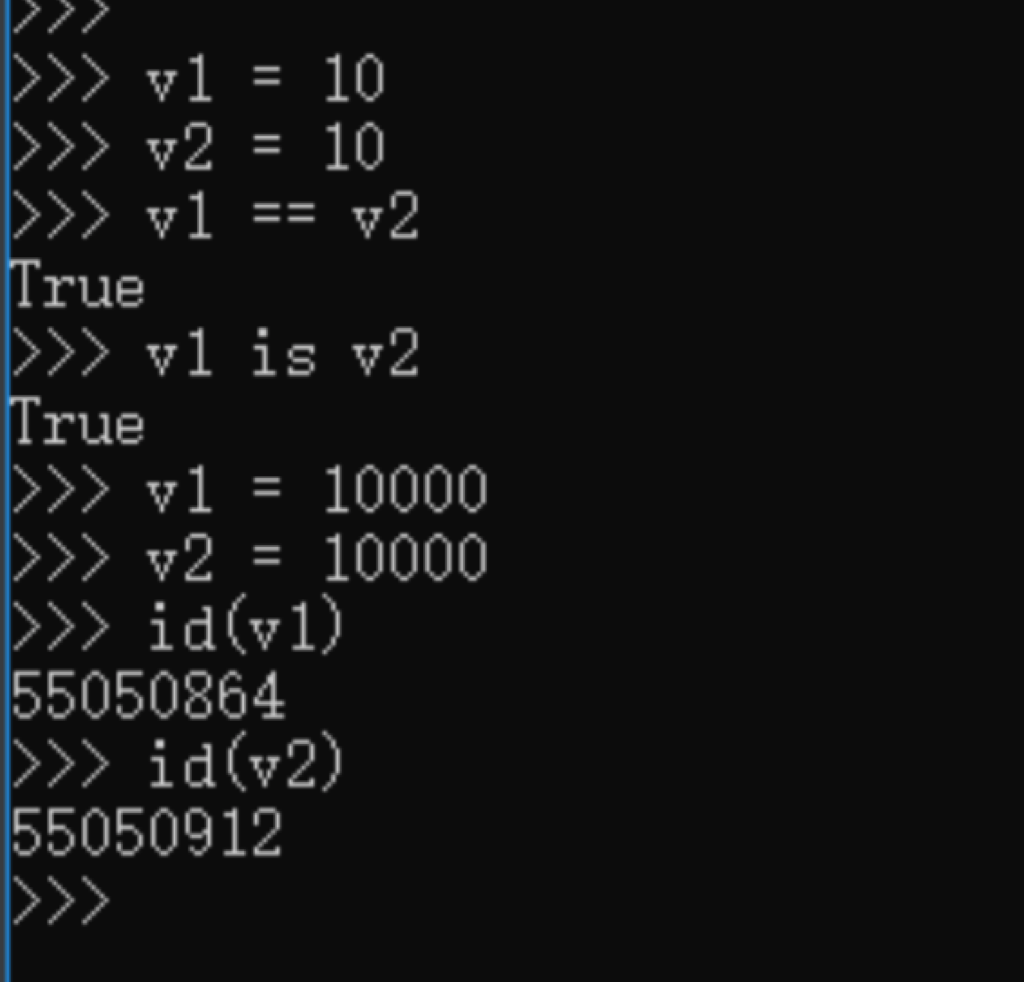
总结
-
列表
- reverse 反转
- sort 根据数字大小排序
-
字典
- get 取值判断是否存在
- pop 删除
- update 不存在,则添加/存在,则更新
-
集合
-
add 添加,不会生成新的变量
-
discard 删除,不会生成新的变量
-
update 更新,不会生成新的变量
-
intersection 交集(*)
-
union 并集
-
difference 差集
-
-
特殊:
- 嵌套:集合/字典的key
- 空:None
- 空集合 set()
-
id 查看内存地址
-
type 查看是什么数据类型
-
嵌套的应用:(*)
- 赋值
- 修改内部元素:列表,字典,集合
-
python数据的小数据池
- -5~~256
- 字符串:"alex",'asfasd asdf asdf d_asdf '
----"f_*" * 3 - 重新开辟内存。
-
None数据类型,改类型表示空(无任何功能,专门用于提供空值)
-
字典补充
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# 索引不存在,报错
# v = ['alex','oldboy']
# print(v[123])
# ################ get
"""
info = {'k1':'v1','k2':'v2'}
# v1 = info['k11111']
# v2 = info.get('k1111') # None就是Python中的空
# v3 = info.get('k1111',666)
# print(v2)
result = info.get('k1111')
if result == None:
print('不存在')
if result:
print('存在')
else:
print('不存再')
"""
# ################ get
# info = {'k1':'v1','k2':'v2'}
# result = info.pop('k2')
# print(info,result)
#
# del info['k1']
# ################ update
info = {'k1':'v1','k2':'v2'}
# 不存在,则添加/存在,则更新
info.update({'k3':'v3','k4':'v4','k2':666})
print(info)
- 集合
#!/usr/bin/env python
# -*- coding:utf-8 -*-
""""""
# 1. 空集合
# v = {} # 空字典
# v1 = set()
# print(type(v1))
"""
None
int
v1 = 123
v1 = int() --> 0
bool
v2 = True/False
v2 = bool() -> False
str
v3 = ""
v3 = str()
list
v4 = []
v4 = list()
tuple
v5 = ()
v5 = tuple()
dict
v6 = {}
v6 = dict()
set
v7 = set()
"""
# 2. 独有功能
# 2.1 add添加
# v = {1,2}
# v.add('Lishaoqi')
# v.add('Lishaoqi')
# print(v)
# 2.2 删除
# v = {1,2,'李邵奇'}
# v.discard('李邵奇')
# print(v)
# 2.3 批量添加
# v = {1,2,'李邵奇'}
# v.update({11,22,33})
# print(v)
# 2.4. 交集
# v = {1,2,'李邵奇'}
# result = v.intersection({1,'李邵奇','小黑'})
# print(result)
# 2.4 并集
# v = {1,2,'李邵奇'}
# result = v.union({1,'李邵奇','小黑'})
# print(result)
# 2.5 差集
# v = {1,2,'李邵奇'}
# result = v.difference({1,'李邵奇','小黑'}) # v中有且{1,'李邵奇','小黑'}没有
# print(result)
#
# v1 = {1,'李邵奇','小黑'}
# result1 = v1.difference({1,2,'李邵奇'})
# print(result1)
# 2.6 对称差集
# v = {1,2,'李邵奇'}
# result = v.symmetric_difference({1,'李邵奇','小黑'})
# print(result)
# 注意:
# v = {1,2,'李邵奇'}
# result = v.intersection([1,'李邵奇','小黑'])
# print(result)
# ##################################################
# 3.1 len
# v = {1,2,'李邵奇'}
# print(len(v))
# 3.2 循环
# v = {1,2,'李邵奇'}
# for item in v:
# print(item)
# ##################################################
# 1. 列表/字典/集合 -> 不能放在集合中+不能作为字典的key(unhashable)
# # info = {1, 2, 3, 4, True, "国风", None, (1, 2, 3)}
# # print(info)
# # 2. hash -> 哈希是怎么回事?
# # 因为在内部会将值进行哈希算法并得到一个数值(对应内存地址),以后用于快速查找。
#
# # 3. 特殊情况
# # info = {0, 2, 3, 4, False, "国风", None, (1, 2, 3)}
# # print(info)
#
# # info = {
# # 1:'alex',
# # True:'oldboy'
# # }
# # print(info)
"""
v1 = [1,2,3]
v2 = v1
v1.append(999)
print(v1,v2)
print(id(v1),id(v2))
"""
"""
v1 = [1,2,3]
v2 = v1
print(id(v1),id(v2))
v1 = 999
print(id(v1),id(v2))
"""

 浙公网安备 33010602011771号
浙公网安备 33010602011771号