Map2DFusion 论文阅读
| 英文题目 | Map2DFusion: Real-time Incremental UAV Image Mosaicing based on Monocular SLAM |
|---|---|
| 中文名称 | Map2DFusion: 基于单目 SLAM 的实时增量无人机图像拼接 |
| 发表时间 | 2016年10月09-14日 |
| 平台 | IROS 2016 |
| 作者 | Shuhui Bu ; Yong Zhao |
| 邮箱 | zd5945@126.com |
| 来源 | 西北工业大学 |
| 关键词 | 实时增量无人机图像拼接 |
| paper && code && video | paper code video |
Abstract-In this paper we present a real-time approach to stitch large-scale aerial images incrementally. A monocular SLAM system is used to estimate camera position and attitude, and meanwhile 3D point cloud map is generated. When GPS information is available, the estimated trajectory is transformed to WGS84 coordinates after time synchronized automatically. Therefore, the output orthoimage retains global coordinates without ground control points. The final image is fused and visualized instantaneously with a proposed adaptive weighted multiband algorithm. To evaluate the effectiveness of the proposed method, we create a publicly available aerial image dataset with sequences of different environments. The experimental results demonstrate that our system is able to achieve high efficiency and quality compared to state-of-the-art methods. In addition, we share the code on the website with detailed introduction and results.
摘要-在本文中,我们提出了一种实时方法,用于增量拼接大规模航拍图像。
- 使用 单目 SLAM 系统 来估计相机的位置和姿态,同时生成 3D 点云地图。
- 当 GPS 信息可用时,估计的轨迹在自动时间同步后转换为 WGS84 坐标。因此,输出的正射影像保留了 global 坐标,而无需地面控制点。
- 最终图像通过提出的自适应加权多波段算法即时融合和可视化。
- 为了评估所提方法的有效性,我们创建了一个公开可用的航拍图像数据集,包含不同环境的序列。
实验结果表明,与最先进的方法相比,我们的系统能够实现高效率和高质量。此外,我们在网站上分享了代码,并提供了详细的介绍和结果。
Index Terms-UAVs, real-time, SLAM, stitching, adaptive weighted multiband
关键词-无人机、实时、SLAM、拼接、自适应加权多波段
Image mosaic: https://en.wikipedia.org/wiki/Image_mosaic
当 GPS 信息可用时,估计的轨迹会在时间同步后自动转换为 WGS84 坐标系中的坐标。
参考: slam 估计的轨迹转为 WGS84?
1 Shuhui Bu, Yong Zhao, and Zhenbao Liu are with Northwestern Polytechnical University, 710072 Xi'an, China bushuhui@nwpu.edu.cn, zd5945@126.com
1 Shuhui Bu、Yong Zhao 和 Zhenbao Liu 供职于西北工业大学,710072 西安,中国 bushuhui@nwpu.edu.cn,zd5945@126.com
\({}^{2}\) Gang Wan is with Information Engineering University, Zhengzhou, China
\({}^{2}\) Gang Wan 供职于信息工程大学,郑州,中国
\({}^{1}\) http://www.orthovista.com/
I. 引言
In recent years, Unmanned Aerial Vehicles (UAVs) have been more and more popular because they are able to accomplish aeronautic tasks at a low price. They are now used for coordinated urban surveillance [1], forest fire localization during monitoring [2], [3], object-based change detection [4], [5], and so on. A real-time global orthoimage can help missions such as fire monitoring and urban surveillance where both efficiency and accuracy are required.
近年来,无人机(UAV)越来越受欢迎,因为它们能够以低成本完成航空任务。它们现在被用于协调城市监视 [1]、监测期间的森林火灾定位 [2]、[3]、基于目标的变化检测 [4]、[5] 等等。实时 global 正射影像可以帮助执行诸如火灾监测和城市监视等任务,这些任务需要效率和准确性。
A mature choice for quick orthoimage generation is Structure from Motion (SfM), which is able to explore the most information from the multi-view images. There are lots of implementations of SfM algorithm such as open-source projects OpenMVG [6], openDroneMap, and commercial software Pix4DMapper [7], Photoscan [8]. They share almost the same pipeline: feature detection and matching, image alignment and sparse point cloud generation with bundle algorithm [9], dense point-cloud and mesh generation, texture and orthoimage mosaicing. While SfM methods always take hours to generate the final orthoimage and all images need to be prepared before computation, they are not suitable for real-time and incremental usage.
快速正射影像生成的成熟选择是 Structure from Motion (SfM),它能够从多视角图像中探索出最多的信息。SfM 算法有很多实现,例如开源项目 OpenMVG [6]、openDroneMap 和商业软件 Pix4DMapper [7]、Photoscan [8]。
- 它们几乎共享相同的流程: 特征检测与匹配、图像对齐和稀疏点云生成与束(bundle)算法 [9]、密集点云和网格生成、纹理和正射影像拼接。
- 然而 SfM 方法通常需要数小时Structure from Motion (SfM)来生成最终的正射影像,并且所有图像在计算之前都需要准备,它们不适合实时和增量使用 。
Since the expensive computation cost of SfM, several 2D methods are proposed in the past years for orthoimage. Niethammer et al. [5] show a straightforward approach for landslide surface displacements evaluation where images are warped onto the plane by matching the ground control points (GCPs) and the final result is blended with software OrthoVista \({}^{1}\) . Hirokawa et al. [10] use GCPs to calibrate the position and attitude of the UAV, while pictures are compensated to a spatial temporal GIS with UAV attitude information later. Homography transformation based on feature matching is also used for image registration [11], [12], where images are warped to the reference frame instead of the GCPs plane. GCPs methods seem tedious for quick response circumstances and 2D homography methods are hard to meet large-scale mosaicing requirements.
由于 SfM 的高计算成本,过去几年提出了几种 2D 方法用于正射影像。
- Niethammer 等 [5] 展示了一种直接的方法来评估滑坡表面位移,其中图像通过匹配地面控制点(GCPs)被扭曲到平面上,最终结果与软件 OrthoVista \({}^{1}\) 混合。
- Hirokawa 等 [10] 使用 GCPs 来校准无人机的位置和姿态,而图像随后被补偿到具有无人机姿态信息的时空 GIS 中。
- 基于特征匹配的单应性变换也用于图像配准 [11]、[12],其中图像被扭曲到参考帧而不是 GCPs 平面。
- GCPs 方法在快速响应情况下似乎显得繁琐,而 2D 单应性方法难以满足大规模拼接的要求。

Fig. 1. We integrate Map2DFusion into the self-developed ground control station, where the orthoimage is generated and visualized online during the flight. The figure shows that the orthoimage is well aligned to Bing satellite map automatically after GPS trajectory fitted.
图 1. 我们将 Map2DFusion 集成到自主开发的地面控制站中,其中在飞行过程中在线生成和可视化正射影像。该图显示,在 GPS 轨迹拟合后,正射影像与 Bing 卫星地图自动对齐良好。
Simultaneous localization and mapping (SLAM), one of the hot researches in robotics and computer vision community, is considered to be the key technique for automatic navigation in unknown environments. The SLAM approach has the advantage of real-time performance due to the well designed processing flow. Some researches are conducted to utilize SLAM for real-time spherical mosaic [13] and underwater sonar image stitching [14]. Since [13] is limited to pure rotation situation and [14] lacks a proper blending algorithm which leads to poor visualization, they both do not meet the demand of aerial images stitching. In this work, a visual SLAM and an adaptive weighted multiband algorithm are designed to stitch the captured images online in real-time as demonstrated in Fig. 1. Because the proposed method has merits of real-time and fully automatic properties, it has a good prospect on applications such as real-time surveillance, GPS denied environment navigation for UAV or drone cluster, forest fire localization during monitoring, and so on. In brief, the main contributions are concluded as follows:
同时定位与地图构建(SLAM)是机器人和计算机视觉领域的热门研究之一,被认为是自动导航未知环境的关键技术。SLAM 方法由于设计良好的处理流程,具有实时性能的优势。一些研究致力于利用 SLAM 进行实时球形拼接 [13] 和水下声纳图像拼接 [14]。由于 [13] 限于纯旋转情况,而 [14] 缺乏合适的混合算法,导致可视化效果差,它们都无法满足航空图像拼接的需求。在这项工作中,设计了一种视觉 SLAM 和自适应加权多波段算法,以实时在线拼接捕获的图像,如图 1 所示。由于所提出的方法具有实时和完全自动化的优点,因此在实时监控、无人机或无人机集群的 GPS 拒绝环境导航、监测期间的森林火灾定位等应用中具有良好的前景。简而言之,主要贡献总结如下:
| 序号 | EN | ZH |
|---|---|---|
| 1) | Automatic GPS and video synchronization: As most video streams are not synchronized with GPS, a graph based optimization is proposed to synchronize video time with GPS time from coarse to fine. Consequently, our method is able to obtain WGS84 coordinates and conquer accumulated drift by fusing GPS information into SLAM processing without GCPs required. | 自动 GPS 和视频同步:由于大多数视频流与 GPS 不同步,提出了一种基于图的优化方法,将视频时间与 GPS 时间从粗到细进行同步。因此,我们的方法能够获得 WGS84 坐标,并通过将 GPS 信息融合到 SLAM 处理过程中来克服累积漂移,而无需 GCP。 |
| 2) | Real-time orthoimage blender: We propose an adaptive weighted multi-band method to blend and visualize images incrementally in real-time. Compared to SfM methods, the approach obtains higher efficiency and satisfactory results without holes and twists caused by limited viewing angles. | 实时正射影像混合器:我们提出了一种自适应加权多波段方法,以实时增量方式混合和可视化图像。与 SfM 方法相比,该方法在有限视角造成的孔洞和扭曲的情况下,获得了更高的效率和令人满意的结果。 |
| 3) | A public aerial image dataset: We create an aerial image dataset with several different sequences for visual SLAM, orthoimage, and 3D reconstruction evaluation. | 一个公共航空图像数据集:我们创建了一个包含多个不同序列的航空图像数据集,用于视觉 SLAM、正射影像和 3D 重建评估。 |
For better understanding of our work, not only the source code and dataset, but also introduction video, detailed results, and evaluations are publicly available on the project \({\text{website}}^{2}\) .
为了更好地理解我们的工作,源代码和数据集,以及介绍视频、详细结果和评估都在项目 \({\text{website}}^{2}\) 上公开可用。
II. 相关工作
Many works have been conducted to generate orthoimage from aerial images in recent years [5], [10], [12]. Most methods can not output acceptable results at real-time speed, while the proposed approach is able to generate high-quality orthoimage incrementally from aerial images. The two related key techniques of our work are monocular SLAM and image stitching, which are summarized in below.
近年来,许多研究致力于从航空图像生成正射影像 [5]、[10]、[12]。大多数方法无法以实时速度输出可接受的结果,而所提出的方法能够逐步从航空图像生成高质量的正射影像。我们工作的两个相关关键技术是单目 SLAM 和图像拼接,下面对此进行总结。
SLAM is regarded as the core to realize navigation and environment sensing for fully autonomous robotics. Parallel Tracking and Mapping (PTAM) [15] is one of the most famous monocular SLAM implementations which shows high efficiency but is limited to small workspaces. As most methods detect keypoint features for matching, Newcombe et al. propose a direct approach named DTAM [16] where camera motion is computed by minimizing a global spatially regularized energy function on GPU. To reduce the intensively computational demand of DTAM, Forster et al. propose a semi-direct monocular visual odometry (SVO) [17] which only processes strong gradient pixels and brings high frame-rates. While all these methods only locally track camera motion and do not have loop-closures, Engel et al. show a well-known large-scale direct monocular SLAM (LSD-SLAM) [18]. The approach utilizes FabMap [19] for loop detection and a similarity transform pose graph for optimization, which allows to build consistent, large-scale maps of the environment. It is extended for omni-directional and stereo cameras [20], [21]. The direct methods rely on small baselines and seem lack robustness when frame-rate is not high enough. Mur-Artal et al. propose a novel ORB feature based monocular SLAM algorithm (ORB-SLAM) [22], which is able to handle large baselines robustly with high precision. It is also further explored for semi-dense reconstruction and gets even better results than direct methods [23]. In order to improve the tracking accuracy, Bu et al. [24] propose a semi-direct tracking and mapping (SDTAM) method for RGB-D device, which inherits the advantages of both direct and feature based methods. The place recognition is a crucial technique for SLAM to perform loop closure and lost recover. To boost performance for image similarity measure, \(\mathrm{{Li}}\) et al. [25] propose an image similarity measurement method based on deep learning and similarity matrix analyzing.
SLAM 被视为实现完全自主机器人导航和环境感知的核心。
- 并行跟踪与地图构建 (PTAM) [15] 是最著名的单目 SLAM 实现之一,显示出高效率,但仅限于小工作空间。
- 由于大多数方法检测关键点特征进行匹配,Newcombe 等人提出了一种名为 DTAM [16] 的直接方法,通过在 GPU 上最小化全局空间正则化能量函数来计算相机运动。
- 为了减少 DTAM 的高计算需求,Forster 等人提出了一种半直接单目视觉里程计 (SVO) [17],仅处理强梯度像素并带来高帧率。
- 虽然所有这些方法仅局部跟踪相机运动且没有回环闭合,Engel 等人展示了一种著名的大规模直接单目 SLAM (LSD-SLAM) [18]。该方法利用 FabMap [19] 进行回环检测,并使用相似性变换姿态图进行优化,从而能够构建一致的大规模环境地图。该方法已扩展至全向和立体相机 [20]、[21]。直接方法依赖于小基线,当帧率不足时似乎缺乏鲁棒性。
- Mur-Artal 等人提出了一种新颖的基于 ORB 特征的单目 SLAM 算法 (ORB-SLAM) [22],能够以高精度稳健地处理大基线。该方法还进一步探索了半稠密重建,并获得了比直接方法更好的结果 [23]。
- 为了提高跟踪精度,Bu 等人 [24] 提出了一种针对 RGB-D 设备的半直接跟踪与地图构建 (SDTAM) 方法,继承了直接方法和基于特征方法的优点。
- 位置识别是 SLAM 执行回环闭合和丢失恢复的关键技术。为了提高图像相似性度量的性能,\(\mathrm{{Li}}\) 等人 [25] 提出了一种基于深度学习和相似性矩阵分析的图像相似性度量方法。
Another critical part of our work is image stitching, which has reached a stage of maturity where there are now an abundance of tools especially for panoramic image stitching, including OpenCV functions, the well-known software Pho-toshop, web-based photo organization tools like Microsoft Photosynth, smartphone apps like Autostitch [26], as well as the built-in image stitching functionality on off-the-shelf digital cameras. Many efforts are conducted to obtain better alignment and blending. Zaragoza et al. [27] improve the image alignment stage with Moving Direct Linear Transformation (DLT) which produces better alignment when the scene is not planar and camera has both rotation and translation. However, perfect alignment is still difficult to be obtained for real world situations, so that some seam cutting methods [28] and blending algorithms [29] are used to minimize the visible seams.
我们工作的另一个关键部分是图像拼接,已经达到了一种成熟阶段,
- 现在有大量工具,尤其是用于全景图像拼接,包括 OpenCV 函数、著名软件 Photoshop、基于网络的照片组织工具如 Microsoft Photosynth、智能手机应用如 Autostitch [26],以及现成数码相机上的内置图像拼接功能。
- 许多努力致力于获得更好的对齐和混合。Zaragoza 等人 [27] 使用移动直接线性变换 (DLT) 改进图像对齐阶段,当场景不是平面且相机具有旋转和位移时,能够产生更好的对齐。
- 然而,在现实世界情况下,完美对齐仍然很难获得,因此使用了一些接缝切割(seam cutting)方法 [28] 和混合算法 [29] 来最小化可见接缝。
In this paper, we present a novel approach which generates high quality orthoimage incrementally with real-time speed. Different from traditional image stitching methods which just compute homograph transformation, in the proposed method, the camera position and attitude are estimated through well designed SLAM system, therefore, a more reasonable plane and precise camera poses are obtained. In order to handle large-scale scenes, GPS information is fused in our SLAM system to obtain WGS84 coordinates and reduce tracking drift. The loop closure technique is also used to further minimize the drift especially when GPS information is absented. Most image stitching methods perform blending after all images are prepared, which reduces the overall efficiency. To achieve real-time speed, an incremental adaptive weighted multi-band is proposed to blend SLAM keyframes efficiently. In the blending, Laplacian pyramids are stored in grids which brings high performance and reduces the memory consumption. Thereby, resulting orthoimage can be stitched incrementally and visualized immediately.
在本文中,我们提出了一种新颖的方法,能够以实时速度逐步生成高质量的正射影像。
- 与传统的仅计算单应性变换的图像拼接方法不同,在所提出的方法中,相机的位置和姿态通过精心设计的>不同,在所提出的方法中,相机的位置和姿态通过精心设计的 SLAM 系统进行估计,因此获得了更合理的平面和精确的相机姿态。
- 为了处理大规模场景,我们的 SLAM 系统融合了 GPS 信息,以获取 WGS84 坐标并减少跟踪漂移。
- 回环闭合技术也被用来进一步最小化漂移,特别是在 GPS 信息缺失时。
- 大多数图像拼接方法在所有图像准备好后进行混合,这降低了整体效率。为了实现实时速度,提出了一种增量自适应加权多带混合方法,以高效地混合 SLAM 关键帧。
- 在混合过程中,拉普拉斯金字塔存储在网格中,这带来了高性能并减少了内存消耗。因此,生成的正射影像可以逐步拼接并立即可视化。
III. REAL-TIME INCREMENTAL UAV IMAGE MOSAICING 实时增量无人机图像拼接
The overview of our system is depicted in Fig. 2 which contains five main parts running in separated threads: video preparation, tracking, mapping, map optimization, and map fusion. The outline of each part is briefly introduced as follows:
**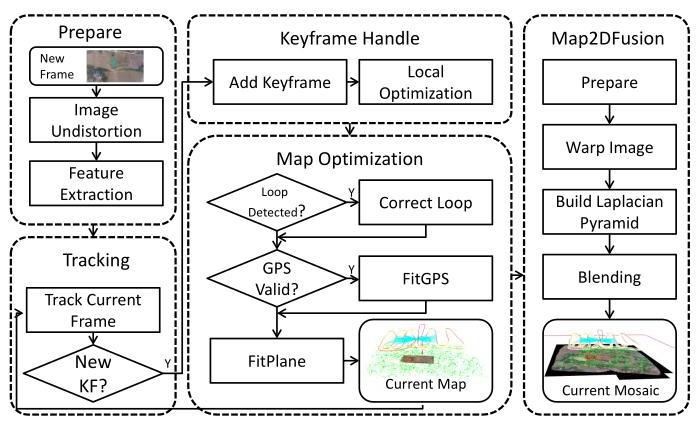
Fig. 2. The framework overview of our system.
图 2. 我们系统的框架概述。**
我们的系统概述如图 2 所示,包含五个主要部分在独立线程中运行:视频准备、跟踪、地图构建、地图优化和地图融合。每个部分的概要简要介绍如下:
| 序号 | EN | ZH |
|---|---|---|
| 1 | The images are undistorted to an ideal pinhole model, and keypoints with features are extracted for tracking usage. | 图像去畸变转换为理想的针孔模型,并提取具有特征的关键点以用于跟踪。 |
| 2 | The initial motion of current frame is tracked against the last frame and then aligned with the local sub-map precisely. | 当前帧的初始运动与上一帧进行跟踪,然后与局部子图精确对齐。 |
| 3 | New keyframe will be added to the global map when the distance between current frame and the last keyframe exceeds a certain threshold, and then a local bundle is performed to optimize the local map-points and keyframe poses. | 当当前帧与最后一个关键帧之间的距离超过某个阈值时,将新关键帧添加到全局地图中,然后执行局部束调整以优化局部地图点和关键帧姿态。 |
| 4 | The global optimization is taken to detect and close loops so that a consistent map can be obtained. An online calibration of time difference between video and GPS timestamp is performed from coarse to fine with a \(\operatorname{SIM}\left( 3\right)\) pose graph, and the final similarity transformation is applied to the estimated trajectory and map-points. After that, GPS constraints are also considered in the local bundle optimization of mapping thread and the mosaic plane is fitted with sampled map-points. | 进行全局优化以检测和闭合循环,从而获得一致的地图。通过一个 \(\operatorname{SIM}\left( 3\right)\) 姿态图,从粗到细地进行视频与 GPS 时间戳之间的时间差在线校准,并将最终的相似性变换应用于估计的轨迹和地图点。之后,GPS 约束也会在映射线程的局部束优化中考虑,并且马赛克平面与采样的地图点进行拟合。 |
| 5 | The map fusion unit blends keyframes into the mosaic plane incrementally. | 地图融合单元逐步将关键帧融合到马赛克平面中。 |
In this section, a brief notation of transformation and projection is firstly given, and then we will introduce the implementation details of our system.
在本节中,首先给出变换和投影的简要符号,然后介绍我们系统的实现细节。
A. Notations 符号
In order to make reader easily understand the representation of transformation and projection, the notations are briefly introduced here. The camera pose is represented with a twist coordinate representation \(\xi\) , which is given as a member of the Lie group \({se}\left( 3\right)\) [30]:
为了使读者能够轻松理解变换和投影的表示,这里简要介绍符号。相机姿态用扭转坐标表示 \(\xi\),它作为李群的一个成员给出 \({se}\left( 3\right)\) [30]:
where \({v}_{1},{v}_{2},{v}_{3}\) represent translation and \({q}_{1},{q}_{2},{q}_{3}\) are the angular positions corresponding to rotation matrix \(\mathbf{R} \in {SO}\left( 3\right)\) . The quarternion representation \({rx},{ry},{rz}, w\) or matrix representation \(\mathbf{R}\) of rotation are calculated from \({q}_{1},{q}_{2},{q}_{3}\) using the exponential function according to Lie algebra [30]. A left-multiplication is defined to transform a point \(\mathbf{P} = {\left( X, Y, Z\right) }^{T}\) in the world coordinate to the camera coordinates:
其中 \({v}_{1},{v}_{2},{v}_{3}\) 表示平移,\({q}_{1},{q}_{2},{q}_{3}\) 是与旋转矩阵 \(\mathbf{R} \in {SO}\left( 3\right)\) 对应的角位置。四元数表示 \({rx},{ry},{rz}, w\) 或矩阵表示 \(\mathbf{R}\) 的旋转是根据李代数 [30] 使用指数函数从 \({q}_{1},{q}_{2},{q}_{3}\) 计算得出的。定义左乘法将世界坐标中的一个点 \(\mathbf{P} = {\left( X, Y, Z\right) }^{T}\) 转换为相机坐标:
A standard pinhole camera model is used to represent the projection:
使用标准针孔相机模型来表示投影:
Here \({f}_{x},{f}_{y}\) are the focal lengths and \({x}_{0},{y}_{0}\) are the coordinates of the camera center in the standard pinhole camera model.
这里 \({f}_{x},{f}_{y}\) 是焦距,\({x}_{0},{y}_{0}\) 是标准针孔相机模型中相机中心的坐标。
On the contrary, the inverse project function \({\mathrm{{Proj}}}^{-1}\) is used to compute corresponding position of \({\mathbf{P}}_{C}\) in the \({Z}_{C} = 1\) plane:
相反,逆投影函数 \({\mathrm{{Proj}}}^{-1}\) 用于计算 \({\mathbf{P}}_{C}\) 在 \({Z}_{C} = 1\) 平面中的对应位置:
B. VideoFrame Preparation and Tracking 视频帧准备与跟踪
To ease the heavy burdens of tracking thread, preparation works like image undistortion and feature extraction are performed in a separated thread. The oriented FAST and rotated BRIEF (ORB) [31] detector and descriptor are selected due to the satisfactory performance.
为了减轻跟踪线程的重负,图像去畸变和特征提取等准备工作在单独的线程中进行。选择了定向 FAST 和旋转 BRIEF (ORB) [31] 检测器和描述符,因为其性能令人满意。
A map constructed with several keyframes \(\mathbf{K}\) and map-points \(\mathbf{P}\) is initialized automatically with the first two keyframes \({K}_{1},{K}_{2}\) . After the map is initialized, the pose \(\mu\) of the current image is obtained from several pairs of 3D map-points \(\mathbf{P}\) and \(2\mathrm{D}\) keypoints \(\mathbf{p}\) , which is called the perspective- \(\mathrm{n}\) -point \(\left( \mathrm{{PnP}}\right)\) problem. The corrospondences between map-points and keypoints are found with a similar strategy of the ORB-SLAM [22]. A window searching between current frame and the last keyframe \({K}_{i - 1}\) is applied to collect tens matches followed with a coarse pose determination. All keyframes observing these map-points are collected to construct the local sub-map, and more matches are found by projecting all local map-points with the coarse pose.
使用几个关键帧 \(\mathbf{K}\) 和地图点 \(\mathbf{P}\) 构建的地图会自动用前两个关键帧 \({K}_{1},{K}_{2}\) 初始化。地图初始化后,当前图像的姿态 \(\mu\) 是通过几个 3D 地图点 \(\mathbf{P}\) 和 \(2\mathrm{D}\) 关键点 \(\mathbf{p}\) 的配对获得的,这被称为透视 \(\mathrm{n}\) -点 \(\left( \mathrm{{PnP}}\right)\) 问题。地图点和关键点之间的对应关系是通过与 ORB-SLAM [22] 类似的策略找到的。应用在当前帧和最后一个关键帧 \({K}_{i - 1}\) 之间的窗口搜索来收集数十个匹配,随后进行粗略姿态确定。所有观察到这些地图点的关键帧被收集以构建局部子地图,并通过使用粗略姿态投影所有局部地图点来找到更多匹配。
Given a set of matches between 3D map-points \(\mathbf{P}\) and current keypoints \(\mathbf{p}\) , the camera pose \(\mu\) can be estimated by minimizing the weighted squared residual function:
给定 3D 地图点 \(\mathbf{P}\) 和当前关键点 \(\mathbf{p}\) 之间的一组匹配,可以通过最小化加权平方残差函数来估计相机姿态 \(\mu\):
The weight \({w}_{i}\) is determined by the pyramid level of the keypoint.
权重 \({w}_{i}\) 由关键点的金字塔层级决定。
The error \({\mathbf{e}}_{i}\) is defined as the difference between measurements \({\mathbf{p}}_{i} = {\left( {x}_{i},{y}_{i}\right) }^{T}\) and predicted \({\mathbf{p}}_{i}^{\prime }\) of a map-point \({\mathbf{P}}_{i}\) :
误差 \({\mathbf{e}}_{i}\) 定义为测量值 \({\mathbf{p}}_{i} = {\left( {x}_{i},{y}_{i}\right) }^{T}\) 与地图点 \({\mathbf{P}}_{i}\) 的预测值 \({\mathbf{p}}_{i}^{\prime }\) 之间的差异:
The weight \({w}_{i}\) is given to reduce influence of large residuals with a robust weighted function and information matrix \({\sum }_{i}^{-1}\) is associated with the pyramid level of \({\mathbf{p}}_{i}\) .
权重 \({w}_{i}\) 被赋予以减少大残差的影响,采用稳健的加权函数,信息矩阵 \({\sum }_{i}^{-1}\) 与 \({\mathbf{p}}_{i}\) 的金字塔层级相关联。
The relative distance between two frames is measured by a weighted combination of translation and rotation described in LSD-SLAM [18]:
两个帧之间的相对距离通过在 LSD-SLAM [18] 中描述的平移和旋转的加权组合来测量:
here \(\mathbf{W}\) is a diagonal matrix with different weights for each parameter in \({\mu }_{ji}\) , and the translation weights are scaled according to the mean inverse depth. Once the distance between current frame and the last keyframe \({K}_{i - 1}\) exceeds the fixed threshold, a new keyframe \({K}_{i}\) will be created to ensure enough overlaps between keyframes.
这里 \(\mathbf{W}\) 是一个对角矩阵,为 \({\mu }_{ji}\) 中的每个参数赋予不同的权重,平移权重根据平均逆深度进行缩放。一旦当前帧与最后一个关键帧 \({K}_{i - 1}\) 之间的距离超过固定阈值,将创建一个新的关键帧 \({K}_{i}\) 以确保关键帧之间有足够的重叠。
C. Keyframe Handle and Local Optimization 关键帧处理与局部优化
When a keyframe \({K}_{i}\) is inserted, new map-points need to be added to the map as soon as possible so that enough correspondences are able to be matched for tracking. For all keypoints that are not observed in tracking, we try to find their correspondences in neighbor keyframes along the epipolar line. A bag-of-words (BoW) vector is computed and registered to accelerate the search, and new map-points are triangulated from matches. After new map-points are created, a data association step is performed to add more observations, combine redundancy map-points, and remove bad map-points.
当插入关键帧 \({K}_{i}\) 时,需要尽快将新的地图点添加到地图中,以便能够匹配足够的对应点进行跟踪。对于在跟踪中未观察到的所有关键点,我们尝试在沿着极线的邻近关键帧中找到它们的对应点。计算并注册一个词袋(BoW)向量以加速搜索,并从匹配中三角化新的地图点。在创建新的地图点后,执行数据关联步骤以添加更多观察,合并冗余地图点,并移除不良地图点。
A local bundle is executed to refine the local sub-map consisted with local keyframes \({K}_{L}\) and map-points \({P}_{L}\) seen by \({K}_{L}\) . The keyframes’ poses \(\mu\) and map-points’ positions \(\mathbf{P}\) are optimized by minimizing the weighted residuals from all local observations:
执行局部束调整以优化由局部关键帧 \({K}_{L}\) 和地图点 \({P}_{L}\) 组成的局部子地图。通过最小化所有局部观察的加权残差来优化关键帧的位姿 \(\mu\) 和地图点的位置 \(\mathbf{P}\):
where the second item of above equation denotes the GPS constraint which will be described in section III-E. In our implementation, the optimization is performed by G2O framework [32].
上述方程的第二项表示 GPS 约束,将在 III-E 节中描述。在我们的实现中,优化是通过 G2O 框架 [32] 进行的。
D. Loop Detection and Fusion 闭环检测与融合
For generating high-quality map, it is necessary to obtain high quality trajectory, but tracking drift is inevitable in visual SLAM which may lead to intolerable misalignment error over long journey accumulation. Although the accumulated drift can be jointly optimized by fusing GPS information which will be described in next sub-section, it is preferable to perform loop closure and global optimization to achieve better consistency in large-scale scenes.
为了生成高质量地图,有必要获得高质量轨迹,但在视觉 SLAM 中跟踪漂移是不可避免的,这可能导致在长时间积累中不可容忍的对齐误差。尽管通过融合 GPS 信息可以共同优化累积漂移,这将在下一个子节中描述,但在大规模场景中,执行循环闭合和全局优化以实现更好的一致性是更可取的。
The first step is detecting appropriate keyframe which is closest to the current position. Because the estimated position has large drift, therefore, it is not easy to estimate the cross point of the loop directly. Recently, appearance based SLAM method such as FabMap [19] gives a vision-based solution. In this work, DBoW2 [33] package is adopted for loop detection. All keyframes sharing visual words with current keyframe are collected and the similarity scores are computed. Then the candidates are sorted according to their visual similarities. In order to gain robustness, they are chosen to be loop candidates only if its neighbors are also candidates. For all loop candidates, we find their correspondences with current keyframe and compute a coarse similarity transformation through the RANSAC method. The candidate which performs the best fitting with enough inliers, is accepted as the loop keyframe, and then the relative pose is optimized by minimizing sum of projection error of map-points.
第一步是检测与当前位置最接近的合适关键帧。由于估计的位置存在较大漂移,因此直接估计循环的交叉点并不容易。最近,基于外观的 SLAM 方法如 FabMap [19] 提供了一种基于视觉的解决方案。在这项工作中,采用 DBoW2 [33] 包进行循环检测。收集与当前关键帧共享视觉词的所有关键帧,并计算相似性分数。然后根据视觉相似性对候选者进行排序。为了获得鲁棒性,只有当其邻居也是候选者时,它们才被选择为循环候选者。对于所有循环候选者,我们找到它们与当前关键帧的对应关系,并通过 RANSAC 方法计算粗略的相似性变换。与足够内点拟合最佳的候选者被接受为循环关键帧,然后通过最小化地图点的投影误差之和来优化相对位姿。
After the loop is detected, a data association step is firstly performed to fuse duplicated map-points. Since direct bundle adjust approach takes too much time to do optimization, a pose graph optimization described in [34] is utilized to decrease the drifts of key-frames and refine corresponding map-points. This approach retains preciseness which benefits from local optimization with little computation.
在检测到循环后,首先执行数据关联步骤以融合重复的地图点。由于直接的束调整方法优化所需时间过长,因此采用文献[34]中描述的姿态图优化方法,以减少关键帧的漂移并细化相应的地图点。这种方法保留了精确性,得益于局部优化且计算量较小。
E. GPS and Plane Fitting GPS 和平面拟合
In our experiments, UAVs are equipped with GPS and the trajectory with timestamp is available for most sequences. However, the video is not synchronized with GPS and a constant time difference needs to be calibrated for each sequence. In our system, the time difference \({t}_{vg}\) is used to build correspondences between global positions and camera positions, and a similarity transformation \({S}_{vg}\) is adopted to transform the whole map to WGS84 coordinates. A robust and efficient algorithm is proposed to jointly optimize the time difference \({t}_{vg}\) and the similarity transformation \({S}_{vg}\) from coarse to fine. For keyframe \({K}_{j}\) whose timestamp in the video is \({t}_{j}\) and translation in the map is \({\mathbf{P}}_{{t}_{j}}^{\text{map }}\) , its corresponding timestamp for GPS should be \({t}_{g} = {t}_{j} + {t}_{vg}\) with WGS84 coordinates \({\mathbf{S}}_{vg}{\mathbf{P}}_{{t}_{j}}^{map}\) after transformation. The goal is to find the best \({t}_{vg}\) and \({\mathbf{S}}_{vg}\) by minimizing the following squared sum of residuals for all keyframes \(\mathbf{K}\) :
在我们的实验中,无人机配备了 GPS,大多数序列都有带时间戳的轨迹。然而,视频与 GPS 不同步,需要为每个序列校准一个恒定的时间差。在我们的系统中,时间差 \({t}_{vg}\) 用于建立全局位置与相机位置之间的对应关系,并采用相似变换 \({S}_{vg}\) 将整个地图转换为 WGS84 坐标。提出了一种鲁棒且高效的算法,从粗到细共同优化时间差 \({t}_{vg}\) 和相似变换 \({S}_{vg}\)。对于视频中时间戳为 \({t}_{j}\) 且地图中平移为 \({\mathbf{P}}_{{t}_{j}}^{\text{map }}\) 的关键帧 \({K}_{j}\),其对应的 GPS 时间戳应为 \({t}_{g} = {t}_{j} + {t}_{vg}\),在变换后为 WGS84 坐标 \({\mathbf{S}}_{vg}{\mathbf{P}}_{{t}_{j}}^{map}\)。目标是通过最小化所有关键帧 \(\mathbf{K}\) 的以下残差平方和来找到最佳的 \({t}_{vg}\) 和 \({\mathbf{S}}_{vg}\):
where \({\Lambda }_{j}^{-1}\) controls the weight for each component in global coordinates. To estimate \({t}_{vg}\) and \({\mathbf{S}}_{vg}\) more robustly, a coarse calibration is firstly performed to narrow the time shift range and obtain an initial \({\mathbf{S}}_{vg}\) . Generally the time shift won't be too large and is assumed to be less than 60 seconds. Consequently, the time shift range is divided into several slices, for each \({t}_{vg} \in \left\lbrack {-{60},{60}}\right\rbrack\) is used to compute \({\mathbf{S}}_{vg}\) with a fast \(\operatorname{SIM}\left( 3\right)\) solver [35]. The best \({t}_{vg}^{ * }\) and \({\mathbf{S}}_{vg}^{ * }\) are chosen to be the initial values and precise results are optimized with the G2O framework [32]. After the \({t}_{vg}\) is calibrated, \({\mathbf{S}}_{vg}\) is applied to the map-points and keyframes. GPS constraint used in formula (8) is considered during the local optimization to eliminate tracking drift.
其中 \({\Lambda }_{j}^{-1}\) 控制全局坐标中每个分量的权重。为了更鲁棒地估计 \({t}_{vg}\) 和 \({\mathbf{S}}_{vg}\),首先进行粗略校准以缩小时间偏移范围并获得初始 \({\mathbf{S}}_{vg}\)。通常时间偏移不会太大,假设小于 60 秒。因此,时间偏移范围被划分为几个切片,对于每个 \({t}_{vg} \in \left\lbrack {-{60},{60}}\right\rbrack\),使用快速 \(\operatorname{SIM}\left( 3\right)\) 求解器 [35] 计算 \({\mathbf{S}}_{vg}\)。选择最佳的 \({t}_{vg}^{ * }\) 和 \({\mathbf{S}}_{vg}^{ * }\) 作为初始值,并使用 G2O 框架 [32] 优化精确结果。在校准 \({t}_{vg}\) 后,将 \({\mathbf{S}}_{vg}\) 应用于地图点和关键帧。在局部优化过程中考虑公式 (8) 中使用的 GPS 约束,以消除跟踪漂移。
Since a ground plane is necessary for \(2\mathrm{D}\) map mosaicing and visualization, a plane is fitted from sampled map-points with a RANSAC approach.
由于进行 \(2\mathrm{D}\) 地图拼接和可视化需要一个地面平面,因此使用 RANSAC 方法从采样的地图点中拟合一个平面。
F.Map Fusion 地图融合
In the previous sections, images are correctly aligned and a mosaic plane is fitted, in this section, our goal is to stitch the keyframes together incrementally. Unlike traditional panoramic stitching circumstances, challenges in the instantaneous aerial image mosaicing exist as follows:
在前面的章节中,图像被正确对齐并且拟合了马赛克平面,在本节中,我们的目标是逐步拼接关键帧。与传统的全景拼接情况不同,即时航空图像马赛克存在以下挑战:
-
It must be able to achieve real-time speed.
-
它必须能够实现实时速度。
-
The stitching needs to be incremental for both blending and visualization.
-
拼接需要在混合和可视化方面是增量的。
-
Most scenes are not totally planar and the camera contains not only rotation but also translation, which leads to inevitable misalignments.
-
大多数场景并不是完全平面的,摄像机不仅包含旋转还包含平移,这导致不可避免的错位。
-
The mosaicing result should be as ortho as possible and able to be updated properly.
-
马赛克结果应该尽可能正交,并能够正确更新。
A seam cutting step is generally performed before blending to obtain better mosaic, however, most seam cutting methods [28] are computational expensive for instantaneous applications and they also discard the weights and need masks for all images prepared. In our system, the ortho-mosaic is split up into rectangular patches and a seam is generated naturally during the blending with a proposed weighted multi-band algorithm. For each patch, a Laplacian pyramid and a weight pyramid are stored. With a Laplacian pyramid, the exposure differences and misalignments are minimized, and brightness are mixed to be continuous, while all details are reserved in low levels of the pyramid. The Laplacian pyramid \({L}_{l}\) for level \(l\) can be computed with an expanded operation [29]. To accelerate the operation, a \(k\) level Gaussian pyramid is first computed and each level \({G}_{l}\) is subtracted from the lower level \({G}_{l - 1}\) of the pyramid:
在混合之前通常会执行一个接缝切割步骤以获得更好的马赛克,然而,大多数接缝切割方法 [28] 对于即时应用来说计算开销较大,并且它们还会丢弃权重并需要为所有准备好的图像提供掩码。在我们的系统中,正交马赛克被分割成矩形块,并且在使用提出的加权多带算法进行混合时自然生成接缝。对于每个块,存储一个拉普拉斯金字塔和一个权重金字塔。通过拉普拉斯金字塔,曝光差异和错位被最小化,亮度被混合为连续的,同时所有细节在金字塔的低层级中保留。拉普拉斯金字塔 \({L}_{l}\) 的级别 \(l\) 可以通过扩展操作 [29] 计算。为了加速操作,首先计算一个 \(k\) 级别的高斯金字塔,并且每个级别 \({G}_{l}\) 从金字塔的下一级 \({G}_{l - 1}\) 中减去:
Here \({2n} - 1\) is the Laplacian kernel size and the sum of weights \({w}_{{d}_{x},{d}_{y}}\) should be one. The highest level \({L}_{k}\) just equals \({G}_{k}\) since there is no higher level \({G}_{k + 1}\) computed. The default band number \(k\) is 5 and the patch resolution is multiple of \({2}^{k}\) , where a \({256} \times {256}\) resolution is used in our system. The patches not only make the blending incremental, but also ensure the warped images in a proper size.
这里 \({2n} - 1\) 是拉普拉斯核大小,权重的总和 \({w}_{{d}_{x},{d}_{y}}\) 应该为一。最高级别 \({L}_{k}\) 恰好等于 \({G}_{k}\),因为没有计算出更高的级别 \({G}_{k + 1}\)。默认带宽数 \(k\) 为 5,补丁分辨率是 \({2}^{k}\) 的倍数,其中在我们的系统中使用 \({256} \times {256}\) 分辨率。补丁不仅使混合增量化,还确保了变形图像的适当大小。
The pipeline to stitch a frame is concluded as follows:
拼接帧的流程总结如下:
-
The rectangular margins are obtained according to the relative pose and the mosaic area grows when the margins exceed the existed area.
-
根据相对姿态获得矩形边缘,当边缘超过现有区域时,马赛克区域会增长。
-
To make the mosaic as ortho and precise as possible, a weighted image is adaptively computed considering the height, view angle and pixel localization. The homography matrix is computed and applied to warp the color image and weighted image.
-
为了使马赛克尽可能正交和精确,考虑高度、视角和像素定位,自适应计算加权图像。计算并应用单应性矩阵以变形彩色图像和加权图像。
-
A Laplacian pyramid is expanded from the warped image and the corresponding weight pyramid is computed. Instead of the weighted summation, the results are fused to the global mosaic patches with the best weighted value.
-
从变形图像扩展拉普拉斯金字塔,并计算相应的权重金字塔。结果不是加权求和,而是与最佳加权值融合到全局马赛克补丁中。
The original image is recovered with a sum of the Laplacian pyramid \({G}_{0} = \mathop{\sum }\limits_{{l = 0}}^{k}{L}_{l}\) . It should be noted that the neighbor patches need to be considered to achieve better consistency. A brief comparison with the feather and multiband blenders implemented by OpenCV is conducted and the results are illustrated in Fig. 3. Both feather and multi-band fail to handle the misalignments caused by the high buildings which are even unrecognizable since the blurs. On the other hand, the buildings are not smooth when no blender used and all pixels are determined with the highest weight. Our algorithm is able to obtain satisfactory results although no seam cutting methods used.
原始图像通过拉普拉斯金字塔的总和 \({G}_{0} = \mathop{\sum }\limits_{{l = 0}}^{k}{L}_{l}\) 恢复。需要注意的是,邻近补丁需要考虑以实现更好的一致性。与 OpenCV 实现的羽毛和多带混合器进行简要比较,结果如图 3 所示。羽毛和多带都无法处理由于高楼造成的错位,甚至由于模糊而无法识别。另一方面,当不使用混合器时,建筑物并不平滑,所有像素都以最高权重确定。尽管未使用接缝切割方法,我们的算法能够获得令人满意的结果。

Fig. 3. Compositing comparison using different blender. (a) Pixels are overwritten with the maximum weight. (b) The blending result of feather blender. (c) The blending result of multi-band blender. (d) The result using our approach. Both feather and multi-band use the implementation of OpenCV.
图 3. 使用不同混合器的合成比较。(a) 像素被最大权重覆盖。(b) 羽毛混合器的混合结果。(c) 多频带混合器的混合结果。(d) 使用我们的方法的结果。羽毛和多频带都使用 OpenCV 的实现。
IV. 实验
To evaluate our system, the NPU DroneMap Dataset with several sequences is created and all data are available on the website \({}^{3}\) . We demonstrate the results of the proposed approach and compare the orthoimages with two state-of-the-art commercial softwares Photoscan [8] and Pix4DMapper [7]. The results show that our system achieves higher robustness and comparative quality with less computation.
为了评估我们的系统,创建了包含多个序列的 NPU DroneMap 数据集,所有数据均可在网站上获取 \({}^{3}\)。我们展示了所提方法的结果,并将正射影像与两款最先进的商业软件 Photoscan [8] 和 Pix4DMapper [7] 进行比较。结果表明,我们的系统在计算量更少的情况下实现了更高的鲁棒性和相当的质量。
A.NPU DroneMap Dataset
A self-made hexacopter and a DJI Phantom3 (advanced version) are used to record the sequences. The hexacopter is equipped with a GoPro Hero3+ camera and a DJI Light-bridge is used for real-time video transmission. Table I summarizes some basic statistics over all the sequences. The dataset contains sequences captured in different terrains and heights, furthermore, new captured sequences will be added to the dataset and published on the website.
使用自制的六旋翼无人机和 DJI Phantom3(高级版)记录序列。六旋翼无人机配备了 GoPro Hero3+ 相机,并使用 DJI Light-bridge 进行实时视频传输。表 I 总结了所有序列的一些基本统计信息。该数据集包含在不同地形和高度下捕获的序列,此外,新的捕获序列将被添加到数据集中并发布在网站上。
For each sequence, the following contents are supplied:
对于每个序列,提供以下内容:
-
Original data consist of video, flight log, GCPs locations, and camera calibration data. The cameras are calibrated with three different models including ATAN (used in PTAM [15]), OpenCV (used by ROS), and OCamCalib [36]. The flight logs have different formats since two types UAVs are utilized.
-
原始数据包括视频、飞行日志、GCPs 位置和相机校准数据。相机使用三种不同的模型进行校准,包括 ATAN(用于 PTAM [15])、OpenCV(由 ROS 使用)和 OCamCalib [36]。飞行日志有不同的格式,因为使用了两种类型的无人机。
-
We convert the original data to an unified and readable format which is used by our system in the following evaluations. For each sequence, the video is divided into undistorted images and flight log is converted into text file.
-
我们将原始数据转换为统一且可读的格式,该格式在后续评估中由我们的系统使用。对于每个序列,视频被分割为无畸变图像,飞行日志被转换为文本文件。
TABLE I
Summarizes of NPU DroneMap Dataset. 'H-Max' denotes the maximum flight height (above ground) and 'V-Max' represents MAXIMUM FLIGHT SPEED. ‘TRAJ-LENGTH’ REPRESENTS THE LENGTH OF RECORDED FLIGHT TRAJECTORY AND ‘TRAJ-GPS’ INDICATES WHETHER GLOBAL POSITIONS ARE AVAILABLE.
NPU DroneMap 数据集的总结。'H-Max' 表示最大飞行高度(高于地面),'V-Max' 表示最大飞行速度。‘TRAJ-LENGTH’ 表示记录的飞行轨迹长度,‘TRAJ-GPS’ 指示是否提供全球位置。
| Sequence Name | Localization | UAV | H-Max (m) | V-Max (m/s) | Area | Traj-Length | Traj-GPS | GCPs |
| gopro-npu | Xi'an, Shaanxi | Hexacopter | 376.8 | 10.39 | ${2.739}\;k{m}^{2}$ | 5.547 km | yes | 6 |
| gopro-monticules | Xi'an, Shaanxi | Hexacopter | 147.2 | 10.44 | ${0.571}\;k{m}^{2}$ | 4.680 km | yes | 0 |
| gopro-saplings | Xi'an, Shaanxi | Hexacopter | 129.2 | 12.40 | ${0.455}\;k{m}^{2}$ | 4.566 km | yes | 0 |
| phantom3-npu | Xi'an, Shaanxi | Phantom3 | 254.5 | 16.96 | ${1.598}\;k{m}^{2}$ | 6.962 km | yes | 6 |
| phantom3-centralPark | Shenzhen, Guangdong | Phantom3 | 161.8 | 16.61 | ${0.606}\;k{m}^{2}$ | 4.536 km | yes | 0 |
| phantom3-grass | Shenzhen, Guangdong | Phantom3 | 78.6 | 10.81 | ${3559.2}{m}^{2}$ | 502.85 m | no | 0 |
| phantom3-village | Hengdong, Hunan | Phantom3 | 196.6 | 17.47 | ${0.932}\;k{m}^{2}$ | 8.323 km | yes | 0 |
| phantom3-hengdong | Hengdong, Hunan | Phantom3 | 358.0 | 16.37 | - | - | no | 0 |
| phantom3-huangqi | Hengdong, Hunan | Phantom3 | 222.3 | 16.57 | ${1.313}\;k{m}^{2}$ | 6.945 km | yes | 0 |
| 序列名称 | 定位 | 无人机 | 最大高度 (米) | 最大速度 (米/秒) | 区域 | 轨迹长度 | 轨迹 GPS | 地面控制点 |
| gopro-npu | 西安,陕西 | 六旋翼无人机 | 376.8 | 10.39 | ${2.739}\;k{m}^{2}$ | 5.547 公里 | 是 | 6 |
| gopro-小丘 | 西安,陕西 | 六旋翼无人机 | 147.2 | 10.44 | ${0.571}\;k{m}^{2}$ | 4.680 公里 | 是 | 0 |
| gopro-幼苗 | 西安,陕西 | 六旋翼无人机 | 129.2 | 12.40 | ${0.455}\;k{m}^{2}$ | 4.566 公里 | 是 | 0 |
| phantom3-npu | 西安,陕西 | Phantom3 | 254.5 | 16.96 | ${1.598}\;k{m}^{2}$ | 6.962 公里 | 是 | 6 |
| phantom3-centralPark | 深圳,广东 | Phantom3 | 161.8 | 16.61 | ${0.606}\;k{m}^{2}$ | 4.536 公里 | 是 | 0 |
| 幻影3-草地 | 深圳,广东 | Phantom3 | 78.6 | 10.81 | ${3559.2}{m}^{2}$ | 502.85 m | 否 | 0 |
| 幻影3-村庄 | 湖南衡东 | Phantom3 | 196.6 | 17.47 | ${0.932}\;k{m}^{2}$ | 8.323 公里 | 是 | 0 |
| 幻影3-衡东 | 湖南衡东 | Phantom3 | 358.0 | 16.37 | - | - | 否 | 0 |
| phantom3-huangqi | 湖南衡东 | Phantom3 | 222.3 | 16.57 | ${1.313}\;k{m}^{2}$ | 6.945 公里 | 是 | 0 |

Fig. 4. The mosaicing results of NPU DroneMap Dataset using Map2DFusion. Our algorithm is able to handle all the sequences successfully and the result shows high robustness and quality in different environments.
图4. 使用 Map2DFusion 的 NPU DroneMap 数据集的拼接结果。我们的算法能够成功处理所有序列,结果在不同环境中显示出高鲁棒性和质量。
-
The keyframe images and trajectories used in SfM methods and our Map2DFusion are offered.
-
提供了在 SfM 方法和我们的 Map2DFusion 中使用的关键帧图像和轨迹。
B. Fusion Results
We evaluate our system on the NPU DroneMap dataset, where thumbnails of the results are shown in Fig. 4 and the full resolution images are available on the website. The result shows that our approach not only achieves satisfactory quality on plain sequences, but also obtains acceptable performances over trees, buildings, and water. Moreover, the proposed method remains high robustness on sequence phantom3-grass, which is very challenging because of the fast motion and repetitive views.
我们在 NPU DroneMap 数据集上评估我们的系统,结果的缩略图如图4所示,完整分辨率的图像可在网站上获取。结果表明,我们的方法不仅在平坦序列上达到了令人满意的质量,而且在树木、建筑物和水面上也获得了可接受的性能。此外,所提出的方法在序列 phantom3-grass 上保持了高鲁棒性,这非常具有挑战性,因为它涉及快速运动和重复视图。
The mapping accuracy is quantitatively evaluate on gopro- \({npu}\) and phantom3-npu, and mean errors are \({3.066}\mathrm{\;m}\) and \({5.710}\mathrm{\;m}\) , respectively. The difference of errors is caused by using different reference points for the two experiments due to the global optimization is not performed in current implementation. The accuracy can be improved by introducing a well designed global fitting and bundle adjustment.
映射精度在 gopro- \({npu}\) 和 phantom3-npu 上进行了定量评估,平均误差分别为 \({3.066}\mathrm{\;m}\) 和 \({5.710}\mathrm{\;m}\)。误差的差异是由于在两个实验中使用了不同的参考点,因为当前实现中没有进行全局优化。通过引入精心设计的全局拟合和束调整,可以提高精度。
C. Comparisons to State-of-the-art Methods
We compare orthoimages generated by our method with two well-known softwares Photoscan [8] and Pix4DMapper [7]. All comparison data including the original images and orthomosaics are publicly available on the project website. For software Photoscan and Pix4DMapper, the parameter for aligning images is set to 'precise level'. The comparisons of some details in sequences phantom3-centralPark and phantom3-village are illustrated in Fig. 5. We notice that our approach obtains better results in some circumstances:
我们将我们的方法生成的正射影像与两个著名软件 Photoscan [8] 和 Pix4DMapper [7] 进行比较。所有比较数据,包括原始图像和正射拼接图,均可在项目网站上公开获取。对于软件 Photoscan 和 Pix4DMapper,图像对齐的参数设置为“精确级别”。在序列 phantom3-centralPark 和 phantom3-village 中一些细节的比较如图 5 所示。我们注意到,在某些情况下,我们的方法获得了更好的结果:
-
Firstly, our approach is able to obtain more nature mo-saicing over vertical structures like trees and buildings. As we can see in part A of Fig. 5(a) and part B of Fig. 5(b), the borders of houses are twisty in Photoscan and rough in Pix4DMapper.
-
首先,我们的方法能够在树木和建筑物等垂直结构上获得更自然的拼接。如图 5(a) 的 A 部分和图 5(b) 的 B 部分所示,Photoscan 中房屋的边缘扭曲,而 Pix4DMapper 中则显得粗糙。
-
Secondly, the results generated by Photoscan contain some misalignments founded not only in part \(\mathrm{B}\) of Fig. 5, but also some other sequences like phantom3- npu. Especially for challenging sequence phantom3- grass, our method shows high robustness while both Photoscan and Pix4DMapper are failed to obtain an acceptable result. The Pix4DMapper obtains better alignment than Photoscan in Fig. 5 but its blending is not smooth enough, while some obvious light spots exist over water area such as part A of Fig. 5(b).
-
其次,Photoscan 生成的结果包含一些不对齐的问题,这不仅出现在图 5 的 \(\mathrm{B}\) 部分,还出现在其他一些序列中,如 phantom3-npu。特别是在具有挑战性的序列 phantom3-grass 中,我们的方法表现出较高的鲁棒性,而 Photoscan 和 Pix4DMapper 都未能获得可接受的结果。虽然 Pix4DMapper 在图 5 中获得了比 Photoscan 更好的对齐,但其融合效果不够平滑,同时在水域上存在一些明显的光斑,如图 5(b) 的 A 部分。

Fig. 5. Comparison on sequences phantom3-centralPark (a) and phantom3-village (b). Left: Map2DFusion (our method), Middle: Photoscan, Right: Pix4DMapper.
图 5. 对序列 phantom3-centralPark (a) 和 phantom3-village (b) 的比较。左:Map2DFusion(我们的方法),中:Photoscan,右:Pix4DMapper。
-
Another important merit is that our algorithm remains high quality over areas with few overlap. This brings better result at margins such as part \(\mathrm{C}\) of Fig. 5(a).
-
另一个重要优点是,我们的算法在重叠较少的区域仍能保持高质量。这在边缘处带来了更好的结果,如图 5(a) 的 \(\mathrm{C}\) 部分所示。
It should be noted that although hours are taken to align the keyframes, both Pix4DMapper and Photoscan failed to output correct results for the sequence phantom3-grass because of fast UAV speed and low altitude. However, the comparison is not completely neutral because our method does not reconstruction the dense 3D map. In addition, our method use GPS coordinates to jointly estimate the camera pose.
需要注意的是,尽管花费了数小时对齐关键帧,但由于 UAV 速度快和飞行高度低,Pix4DMapper 和 Photoscan 都未能为序列 phantom3-grass 输出正确的结果。然而,这一比较并不完全中立,因为我们的方法并未重建密集的 3D 地图。此外,我们的方法使用 GPS 坐标共同估计相机姿态。
D. Computational Performance
All evaluations are performed on a computer equipped Intel i7-4710 CPU, 16 GB RAM, and GTX960 GPU. We run our approach and Photoscan in a 64-bit Linux system, while Pix4DMapper executes on 64-bit Windows 10. The time usage statistics with time unit of minute are illustrated in Table II.
所有评估均在配备 Intel i7-4710 CPU、16 GB RAM 和 GTX960 GPU 的计算机上进行。我们在 64 位 Linux 系统上运行我们的方法和 Photoscan,而 Pix4DMapper 在 64 位 Windows 10 上执行。时间使用统计以分钟为单位如表 II 所示。
Our method tracks all frames, while both Pix4DMapper and Photoscan only process the keyframes to generate the final images. As the keyframe number increases, the processing time of Pix4DMapper and Photoscan increase dramatically. However, the computational complexity of our system is approximately linear, consequently, large-scale scenes can be handled fluently. In the proposed system, the tracking runs at about \({30}\mathrm{\;{Hz}}\) and the stitching runs at about \({10}\mathrm{\;{Hz}}\) for full \({1080}\mathrm{p}\) video. In fact, it is not necessary to process every frame due to the large baseline tracking ability, thus the speed can be further boosted by processing selected frames. Based on the above merits, it is sufficient to use this system on low-cost embedded devices.
我们的方法跟踪所有帧,而 Pix4DMapper 和 Photoscan 仅处理关键帧以生成最终图像。随着关键帧数量的增加,Pix4DMapper 和 Photoscan 的处理时间急剧增加。然而,我们系统的计算复杂度大约是线性的,因此可以流畅处理大规模场景。在所提议的系统中,跟踪大约在 \({30}\mathrm{\;{Hz}}\) 运行,而拼接大约在 \({10}\mathrm{\;{Hz}}\) 运行以处理完整的 \({1080}\mathrm{p}\) 视频。实际上,由于大基线跟踪能力,不必处理每一帧,因此通过处理选定帧可以进一步提高速度。基于上述优点,在低成本嵌入式设备上使用该系统是足够的。
TABLE II
TIME USAGE STATISTICS FOR ORTHOIMAGE GENERATING. THE TIME UNIT IS MINUTE.
正射影像生成的时间使用统计。时间单位为分钟。
| Sequence | Frames | KFs | Ours | Pix4D | Photoscan |
| gopro-npu | 28,493 | 337 | 15.84 | 107.05 | 153.62 |
| gopro-monticules | 18,869 | 395 | 10.49 | 52.62 | 334.73 |
| gopro-saplings | 19,371 | 482 | 16.44 | 83.75 | 683.98 |
| phantom3-npu | 13,983 | 457 | 9.32 | 140.08 | 532.38 |
| phantom3-centralPark | 12,744 | 471 | 8.49 | 127.73 | 563.57 |
| phantom3-grass | 4,585 | 648 | 2.39 | 154.77 | 999.67 |
| phantom3-village | 16,969 | 406 | 11.31 | 132.07 | 360.70 |
| phantom3-hengdong | 16,292 | 221 | 10.86 | 72.13 | 145.52 |
| phantom3-huangqi | 14,776 | 393 | 10.36 | 102.83 | 462.32 |
| 序列 | 帧 | 关键帧 | 我们的 | Pix4D | Photoscan |
| gopro-npu | 28,493 | 337 | 15.84 | 107.05 | 153.62 |
| gopro-小丘 | 18,869 | 395 | 10.49 | 52.62 | 334.73 |
| gopro-幼苗 | 19,371 | 482 | 16.44 | 83.75 | 683.98 |
| phantom3-npu | 13,983 | 457 | 9.32 | 140.08 | 532.38 |
| phantom3-中央公园 | 12,744 | 471 | 8.49 | 127.73 | 563.57 |
| phantom3-草地 | 4,585 | 648 | 2.39 | 154.77 | 999.67 |
| phantom3-村庄 | 16,969 | 406 | 11.31 | 132.07 | 360.70 |
| phantom3-横东 | 16,292 | 221 | 10.86 | 72.13 | 145.52 |
| phantom3-黄旗 | 14,776 | 393 | 10.36 | 102.83 | 462.32 |
V. Conclusions
This paper presents a novel approach to mosaic aerial images incrementally in real-time with high robustness and quality. Most traditional SfM methods need all data prepared and hours for computation, while the proposed method outputs comparative or even better results with real-time speed. Moreover, the results are able to be visualized in the map widget immediately. We publish the detailed results, introduction video, and dataset on the project website, in addition, the code of Map2DFusion is also provided.
本文提出了一种新颖的方法,可以实时增量 mosaic 航空图像,具有高鲁棒性和质量。大多数传统的 SfM 方法需要准备所有数据并耗费数小时进行计算,而所提出的方法能够以实时速度输出相当或更好的结果。此外,结果可以立即在地图小部件中可视化。我们在项目网站上发布了详细的结果、介绍视频和数据集,并提供了 Map2DFusion 的代码。
Although our system outputs high quality mosaics in most circumstances, there are still some improvements that can be made especially for non-planar environments. PhotoScan and Pix4DMapper output dense point cloud and mosaic with better orthogonality. However, our method just computes sparse point cloud and the orthoimages are not totally ortho although great efforts are conducted to make the result as ortho as possible. In addtion, some other image warping functions considering 3D structure should be investigated to minimize the misalignments.
尽管我们的系统在大多数情况下输出高质量的 mosaic,但在非平面环境中仍然可以进行一些改进。
- PhotoScan 和 Pix4DMapper 输出具有更好正射性的稠密点云和 mosaic 。
- 然而,我们的方法仅计算稀疏点云,尽管进行了大量努力使结果尽可能正射,但正射影像并不完全正射。
- 此外,还应研究考虑三维结构的其他图像变形函数,以最小化不对齐。
mosaic 的意思应该就是正射影像拼接
ACKNOWLEDGEMENTS
This work is partly supported by grants from National Natural Science Foundation of China (61573284), and Open Projects Program of National Laboratory of Pattern Recognition (NLPR).
本工作部分得到中国国家自然科学基金(61573284)和国家模式识别实验室(NLPR)开放项目计划的资助。
REFERENCES
参考文献
[1] T. Samad, J. S. Bay, and D. Godbole, "Network-centric systems for military operations in urban terrain: the role of uavs," Proceedings of the IEEE, vol. 95, no. 1, pp. 92-107, 2007.
[1] T. Samad, J. S. Bay, 和 D. Godbole, "面向城市地形军事作战的网络中心系统:无人机的角色," IEEE 会议录, 第 95 卷, 第 1 期, 页 92-107, 2007.
[2] W. Tao, "Multi-view dense match for forest area," ISPRS-International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences, vol. 1, pp. 397-400, 2014.
[2] W. Tao, "森林区域的多视角密集匹配," ISPRS-国际摄影测量、遥感与空间信息科学档案, 第 1 卷, 页 397-400, 2014.
[3] B. H. Wilcox, T. Litwin, J. Biesiadecki, J. Matthews, M. Heverly, J. Morrison, J. Townsend, N. Ahmad, A. Sirota, and B. Cooper, "Athlete: A cargo handling and manipulation robot for the moon," Journal of Field Robotics, vol. 24, no. 5, pp. 421-434, 2007.
[3] B. H. Wilcox, T. Litwin, J. Biesiadecki, J. Matthews, M. Heverly, J. Morrison, J. Townsend, N. Ahmad, A. Sirota, 和 B. Cooper, "Athlete:一种用于月球的货物处理和操作机器人," 现场机器人学杂志, 第 24 卷, 第 5 期, 页 421-434, 2007.
[4] J. Shi, J. Wang, and Y. Xu, "Object-based change detection using georeferenced uav images," Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci, vol. 38, pp. 177-182, 2011.
[4] J. Shi, J. Wang, 和 Y. Xu, "基于对象的变化检测使用地理参考的无人机图像," 国际摄影测量与遥感档案, 第 38 卷, 页 177-182, 2011.
[5] U. Niethammer, M. James, S. Rothmund, J. Travelletti, and M. Joswig, "Uav-based remote sensing of the super-sauze landslide: Evaluation and results," Engineering Geology, vol. 128, pp. 2-11, 2012.
[5] U. Niethammer, M. James, S. Rothmund, J. Travelletti, 和 M. Joswig, "基于无人机的超级索兹滑坡遥感:评估与结果," 工程地质, 第 128 卷, 页 2-11, 2012.
[6] P. Moulon, P. Monasse, R. Marlet, and Others, "Openmvg. an open multiple view geometry library." https://github.com/openMVG/ openMVG.
[6] P. Moulon, P. Monasse, R. Marlet, 等, "Openmvg. 一个开放的多视角几何库." https://github.com/openMVG/openMVG.
[7] J. Vallet, F. Panissod, C. Strecha, and M. Tracol, "Photogrammetric performance of an ultra light weight swinglet uav," in UAV-g, no. EPFL-CONF-169252, 2011.
[7] J. Vallet, F. Panissod, C. Strecha 和 M. Tracol,"超轻量级摆动无人机的摄影测量性能",在 UAV-g,第 EPFL-CONF-169252 号,2011 年。
[8] G. Verhoeven, "Taking computer vision aloft-archaeological three-dimensional reconstructions from aerial photographs with photoscan," Archaeological Prospection, vol. 18, no. 1, pp. 67-73, 2011.
[8] G. Verhoeven,"将计算机视觉带入空中——利用照片扫描从航拍照片中进行考古三维重建",考古勘探,卷 18,第 1 期,页 67-73,2011 年。
[9] B. Triggs, P. F. McLauchlan, R. I. Hartley, and A. W. Fitzgibbon, "Bundle adjustmentla modern synthesis," in Vision algorithms: theory and practice. Springer, 1999, pp. 298-372.
[9] B. Triggs, P. F. McLauchlan, R. I. Hartley 和 A. W. Fitzgibbon,"束调整:现代综合",在视觉算法:理论与实践。施普林格,1999 年,页 298-372。
[10] R. Hirokawa, D. Kubo, S. Suzuki, J.-i. Meguro, and T. Suzuki, "A small uav for immediate hazard map generation," in AIAA Infotech@ Aerospace 2007 Conference and Exhibit, 2007, p. 2725.
[10] R. Hirokawa, D. Kubo, S. Suzuki, J.-i. Meguro 和 T. Suzuki,"用于即时危险地图生成的小型无人机",在 AIAA Infotech@ Aerospace 2007 会议及展览,2007 年,页 2725。
[11] T. Botterill, S. Mills, and R. Green, "Real-time aerial image mosaic-ing," in Image and Vision Computing New Zealand (IVCNZ), 2010 25th International Conference of. IEEE, 2010, pp. 1-8.
[11] T. Botterill, S. Mills 和 R. Green,"实时航拍图像拼接",在新西兰图像与视觉计算(IVCNZ),2010年第 25 届国际会议。IEEE,2010 年,页 1-8。
[12] P. Xiong, X. Liu, C. Gao, Z. Zhou, C. Gao, and Q. Liu, "A real-time stitching algorithm for uav aerial images," in Proceedings of the 2nd International Conference on Computer Science and Electronics Engineering. Atlantis Press, 2013.
[12] P. Xiong, X. Liu, C. Gao, Z. Zhou, C. Gao 和 Q. Liu,"一种用于无人机航拍图像的实时拼接算法",在第二届计算机科学与电子工程国际会议论文集。亚特兰蒂斯出版社,2013 年。
[13] S. Lovegrove and A. J. Davison, "Real-time spherical mosaicing using whole image alignment," in Computer Vision-ECCV 2010. Springer, 2010, pp. 73-86.
[13] S. Lovegrove 和 A. J. Davison, "实时球形拼接使用全图像对齐," 收录于计算机视觉-ECCV 2010. Springer, 2010, 页 73-86.
[14] T. Maki, H. Kondo, T. Ura, and T. Sakamaki, "Photo mosaicing of tagiri shallow vent area by the auv" tri-dog 1" using a slam based navigation scheme," in OCEANS 2006. IEEE, 2006, pp. 1-6.
[14] T. Maki, H. Kondo, T. Ura 和 T. Sakamaki, "通过 AUV 'tri-dog 1' 的 tagiri 浅通气区的照片拼接,使用基于 SLAM 的导航方案," 收录于 OCEANS 2006. IEEE, 2006, 页 1-6.
[15] G. Klein and D. Murray, "Parallel tracking and mapping for small ar workspaces," in Mixed and Augmented Reality, 2007. ISMAR 2007. 6th IEEE and ACM International Symposium on. IEEE, 2007, pp. 225-234.
[15] G. Klein 和 D. Murray, "小型增强现实工作空间的并行跟踪与映射," 收录于混合与增强现实, 2007. ISMAR 2007. 第六届 IEEE 和 ACM 国际研讨会. IEEE, 2007, 页 225-234.
[16] R. A. Newcombe, S. J. Lovegrove, and A. J. Davison, "Dtam: Dense tracking and mapping in real-time," in Computer Vision (ICCV), 2011 IEEE International Conference on. IEEE, 2011, pp. 2320-2327.
[16] R. A. Newcombe, S. J. Lovegrove 和 A. J. Davison, "DTAM: 实时密集跟踪与映射," 收录于计算机视觉 (ICCV), 2011 IEEE 国际会议. IEEE, 2011, 页 2320-2327.
[17] C. Forster, M. Pizzoli, and D. Scaramuzza, "Svo: Fast semi-direct monocular visual odometry," in Robotics and Automation (ICRA), 2014 IEEE International Conference on. IEEE, 2014, pp. 15-22.
[17] C. Forster, M. Pizzoli 和 D. Scaramuzza, "SVO: 快速半直接单目视觉里程计," 收录于机器人与自动化 (ICRA), 2014 IEEE 国际会议. IEEE, 2014, 页 15-22.
[18] J. Engel, T. Schöps, and D. Cremers, "Lsd-slam: Large-scale direct monocular slam," in Computer Vision-ECCV 2014. Springer, 2014, pp. 834-849.
[18] J. Engel, T. Schöps 和 D. Cremers, "LSD-SLAM: 大规模直接单目 SLAM," 收录于计算机视觉-ECCV 2014. Springer, 2014, 页 834-849.
[19] A. Glover, W. Maddern, M. Warren, S. Reid, M. Milford, and G. Wyeth, "Openfabmap: An open source toolbox for appearance-based loop closure detection," in Robotics and Automation (ICRA), 2012 IEEE International Conference on, May 2012, pp. 4730-4735.
[19] A. Glover, W. Maddern, M. Warren, S. Reid, M. Milford, 和 G. Wyeth, "Openfabmap: 一个用于基于外观的闭环检测的开源工具箱," 在2012年IEEE国际会议上,机器人与自动化(ICRA),2012年5月,页4730-4735。
[20] D. Caruso, J. Engel, and D. Cremers, "Large-scale direct slam for omnidirectional cameras," in Intelligent Robots and Systems (IROS), 2015 IEEE/RSJ International Conference on. IEEE, 2015, pp. 141- 148.
[20] D. Caruso, J. Engel, 和 D. Cremers, "用于全向相机的大规模直接SLAM," 在2015年IEEE/RSJ国际会议上,智能机器人与系统(IROS)。IEEE,2015年,页141-148。
[21] J. Engel, J. Stuckler, and D. Cremers, "Large-scale direct slam with stereo cameras," in Intelligent Robots and Systems (IROS), 2015 IEEE/RSJ International Conference on. IEEE, 2015, pp. 1935-1942.
[21] J. Engel, J. Stuckler, 和 D. Cremers, "使用立体相机的大规模直接SLAM," 在2015年IEEE/RSJ国际会议上,智能机器人与系统(IROS)。IEEE,2015年,页1935-1942。
[22] R. Mur-Artal, J. Montiel, and J. D. Tardos, "Orb-slam: a versatile and accurate monocular slam system," arXiv preprint arXiv:1502.00956, 2015.
[22] R. Mur-Artal, J. Montiel, 和 J. D. Tardos, "ORB-SLAM: 一个多功能且准确的单目SLAM系统," arXiv预印本 arXiv:1502.00956, 2015。
[23] R. Mur-Artal and J. D. Tardós, "Probabilistic semi-dense mapping from highly accurate feature-based monocular slam," Proceedings of Robotics: Science and Systems, Rome, Italy, 2015.
[23] R. Mur-Artal 和 J. D. Tardós, "基于特征的单目SLAM的概率半稠密映射," 机器人:科学与系统会议论文集,意大利罗马,2015年。
[24] S. Bu, Y. Zhao, G. Wan, and K. Li, "Semi-direct tracking and mapping with rgb-d camera for mav," Multimedia Tools and Applications, vol. 75, pp. 1-25, 2016.
[24] S. Bu, Y. Zhao, G. Wan, 和 K. Li, "使用RGB-D相机进行的半直接跟踪与映射用于MAV," 多媒体工具与应用,卷75,页1-25,2016年。
[25] Q. Li, K. Li, X. You, S. B. Bu, and Z. Liu, "Place recognition based on deep feature and adaptive weighting of similarity matrix," Neurocomputing, vol. 199, pp. 114-127, 2016.
[25] Q. Li, K. Li, X. You, S. B. Bu, 和 Z. Liu, "基于深度特征和相似性矩阵自适应加权的地点识别," Neurocomputing, vol. 199, pp. 114-127, 2016.
[26] M. Brown and D. G. Lowe, "Automatic panoramic image stitching using invariant features," International journal of computer vision, vol. 74, no. 1, pp. 59-73, 2007.
[26] M. Brown 和 D. G. Lowe, "使用不变特征的自动全景图像拼接," 国际计算机视觉杂志, vol. 74, no. 1, pp. 59-73, 2007.
[27] J. Zaragoza, T.-J. Chin, Q.-H. Tran, M. S. Brown, and D. Suter, "As-projective-as-possible image stitching with moving dlt," Pattern Analysis and Machine Intelligence, IEEE Transactions on, vol. 36, no. 7, pp. 1285-1298, 2014.
[27] J. Zaragoza, T.-J. Chin, Q.-H. Tran, M. S. Brown, 和 D. Suter, "尽可能投影的图像拼接与移动 DLT," 模式分析与机器智能, IEEE 交易, vol. 36, no. 7, pp. 1285-1298, 2014.
[28] V. Kwatra, A. Schödl, I. Essa, G. Turk, and A. Bobick, "Graphcut textures: image and video synthesis using graph cuts," in \({ACM}\) Transactions on Graphics (ToG), vol. 22, no. 3. ACM, 2003, pp. 277-286.
[28] V. Kwatra, A. Schödl, I. Essa, G. Turk, 和 A. Bobick, "图切割纹理:使用图切割的图像和视频合成," 在 \({ACM}\) 图形学交易 (ToG), vol. 22, no. 3. ACM, 2003, pp. 277-286.
[29] P. J. Burt and E. H. Adelson, "A multiresolution spline with application to image mosaics," ACM Transactions on Graphics (TOG), vol. 2, no. 4, pp. 217-236, 1983.
[29] P. J. Burt 和 E. H. Adelson, "一种多分辨率样条及其在图像马赛克中的应用," ACM 图形学交易 (TOG), vol. 2, no. 4, pp. 217-236, 1983.
[30] J. Selig, "Lie groups and lie algebras in robotics," in Computational Noncommutative Algebra and Applications. Springer, 2004, pp. 101- 125.
[30] J. Selig, "机器人中的李群和李代数," 在计算非交换代数及其应用. Springer, 2004, pp. 101-125.
[31] E. Rublee, V. Rabaud, K. Konolige, and G. Bradski, "Orb: an efficient alternative to sift or surf," in Computer Vision (ICCV), 2011 IEEE International Conference on. IEEE, 2011, pp. 2564-2571.
[31] E. Rublee, V. Rabaud, K. Konolige 和 G. Bradski, "Orb: 一种高效的 sift 或 surf 替代方案," 载于计算机视觉 (ICCV), 2011 年 IEEE 国际会议. IEEE, 2011, 第 2564-2571 页。
[32] G. Grisetti, H. Strasdat, K. Konolige, and W. Burgard, "g2o: A general framework for graph optimization," in IEEE International Conference on Robotics and Automation, 2011.
[32] G. Grisetti, H. Strasdat, K. Konolige 和 W. Burgard, "g2o: 一种图优化的通用框架," 载于 2011 年 IEEE 国际机器人与自动化会议。
[33] R. Mur-Artal and J. D. Tardós, "Fast relocalisation and loop closing in keyframe-based slam," in Robotics and Automation (ICRA), 2014 IEEE International Conference on, 2014.
[33] R. Mur-Artal 和 J. D. Tardós, "基于关键帧的快速重定位和闭环检测," 载于机器人与自动化 (ICRA), 2014 年 IEEE 国际会议, 2014。
[34] H. Strasdat, A. J. Davison, J. Montiel, and K. Konolig, "Double window optimisation for constant time visual slam," in Computer Vision (ICCV), 2011 IEEE International Conference on. IEEE, 2011, pp. 2352-2359.
[34] H. Strasdat, A. J. Davison, J. Montiel 和 K. Konolig, "恒定时间视觉 SLAM 的双窗口优化," 载于计算机视觉 (ICCV), 2011 年 IEEE 国际会议. IEEE, 2011, 第 2352-2359 页。
[35] B. K. Horn, "Closed-form solution of absolute orientation using unit quaternions," JOSA A, vol. 4, no. 4, pp. 629-642, 1987.
[35] B. K. Horn, "使用单位四元数的绝对定向闭式解," JOSA A, 第 4 卷, 第 4 期, 第 629-642 页, 1987。
[36] D. Scaramuzza, A. Martinelli, and R. Siegwart, "A flexible technique for accurate omnidirectional camera calibration and structure from motion," in Computer Vision Systems, 2006 ICVS'06. IEEE International Conference on. IEEE, 2006, pp. 45-45.
[36] D. Scaramuzza, A. Martinelli 和 R. Siegwart, "一种灵活的技术用于精确的全向相机标定和运动结构重建," 载于计算机视觉系统, 2006 ICVS'06. IEEE 国际会议. IEEE, 2006, 第 45 页。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号