yolov8 模型架构研究
1. 模型研究
通过导出的 onnx,我们就可以研究下模型结构。
首先看下模型概览:

值得注意的是: 输出的维度变为:[1, 84, 8400], 至于 为什么是 84 和 8400 后面有答案。
1. yolov5 和 yolov8 对比( 通过 yaml )
对照 yolov8.yaml 文件 和 yolov5s-7.0.yaml ,使用 netron , 分析下模型架构。
输出位置:
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# YOLOv5 和 v8 都是默认的 P3、P4、P5 输出
参数:
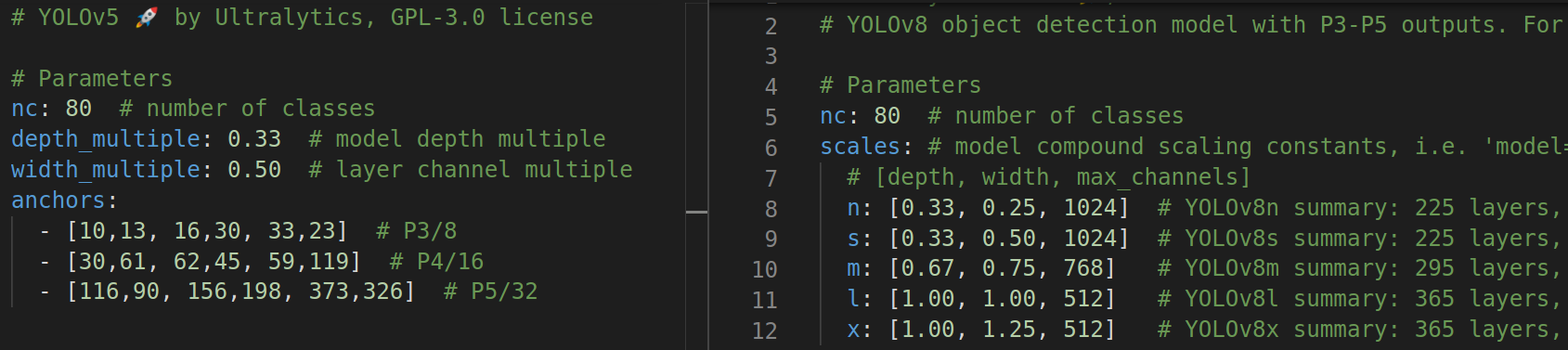
YOLOv8 变成 anchor free,参数配置把 n,s,m,l,x 多个模型整合到了 一个 yaml 文件。
- depth: 是用来控制 c2f 模块的 Bottleneck 有几个的;
- width 是用来控制 每层的输出通道数(就是下面的 args[0], 如 64 等);
- max_channels 也是用来控制每层的输出的通道数的,不过如果配置中 写的输出通道个数(比如 1024)> max_channels,那么 1024 不起作用,使用的是 max_channels*width,感觉就是用来让大的模型不要太大。
宽度变化 和 分辨率大小变化表
| 0:Conv | 1:Conv | 2:C2f+ | 3:Conv | 4:C2f+ | 5:Conv | 6:C2f+ | 7:Conv | 8:C2f+ | 9:SPPF | 10:Up | 11:Cat(6+10) | 12:C2f | 13:Up | 14:Cat(4+13) | 15:C2f | 16:Conv | 17:Cat(12+16) | 18:C2f | 19:Conv | 20:Cat(9+19) | 21:C2f | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| n*0.25 | 16 | 32 | 32 | 64 | 64 | 128 | 128 | 256 | 256 | 256 | 256 | 384 | 128 | 128 | 192 | 64 | 64 | 192 | 128 | 128 | 384 | 256 |
| s*0.5 | 32 | 64 | 64 | 128 | 128 | 256 | 256 | 512 | 512 | 512 | 512 | 768 | 256 | 256 | 384 | 128 | 128 | 384 | 256 | 256 | 768 | 512 |
| m(768)*0.75 | 48 | 96 | 96 | 192 | 192 | 384 | 384 | 576 | 576 | 576 | 576 | 960 | 384 | 384 | 576 | 192 | 192 | 576 | 384 | 384 | 960 | 576 |
| l(512)*1 | 64 | 128 | 128 | 256 | 256 | 512 | 512 | 512 | 512 | 512 | 512 | 1024 | 512 | 512 | 768 | 256 | 256 | 768 | 512 | 512 | 1024 | 512 |
| x(512)*1.25 | 80 | 160 | 160 | 320 | 320 | 640 | 640 | 640 | 640 | 640 | 640 | 1280 | 640 | 640 | 960 | 320 | 320 | 960 | 640 | 640 | 1280 | 640 |
| w/h | /2 | /4 | /8 | /16 | /32 | /16 | /8 | /16 | /32 |
backbone:
- from: 表示该模块的上一个模块在哪里, -1 表示就是上面那个模块连过来,[-1, 6] 类似的主要在 Concat 操作,表示把上一个模块的输出和 第 6个模块的输出 Concat 到一起。
- repeats: 用到 C2f 模块中,表示 Bottleneck 的个数
- module:当前模块的名字
- args:模块配置的参数。
- Conv 中表示 输出通道个数,卷积核大小,步长大小(s=2 用来宽高减半);
- C2f 中第一个参数也是输出通道个数,True 表示使用残差连接,否则不使用;
- SPPF 的第一个参数也是输出通道数,5 表示 MaxPool2d 核的大小;
- Upsample 参数为:[None, 2, 'nearest'], None 表示不需要输出的通道数,因为不改变通道数,2表示上采样2倍,'nearest' 最近邻采样;
- Detect 参数为:[nc],nc 表示检测的个数。
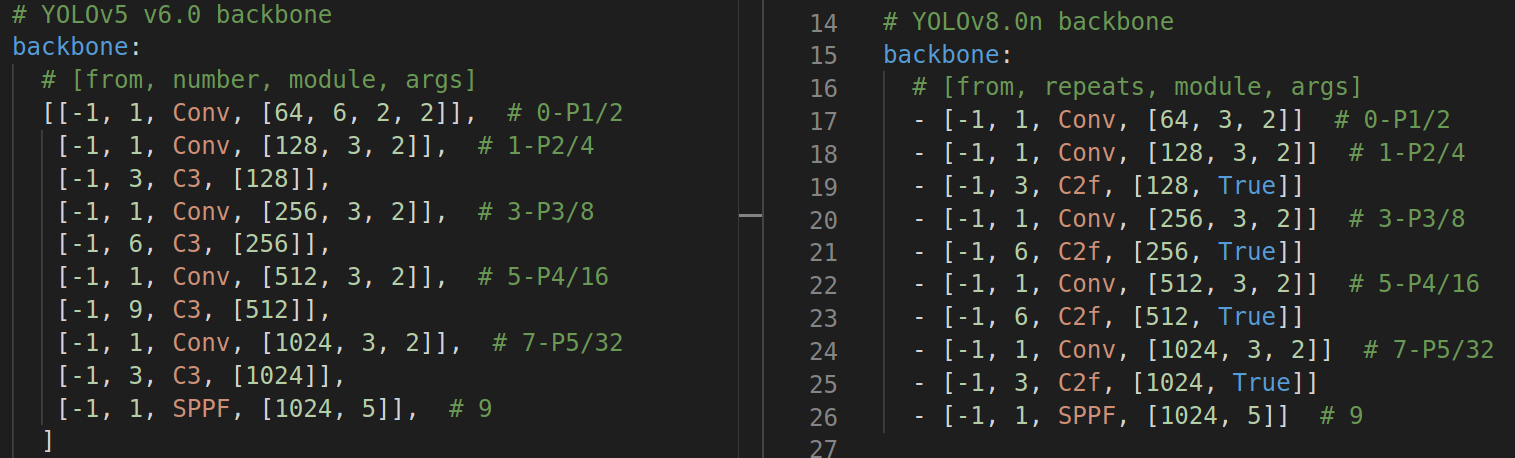
大体来说:# 0-P1/2 更加和谐了,把 kernel 从 6->3,C3 变成了 C2f 且多了个 True。
head:
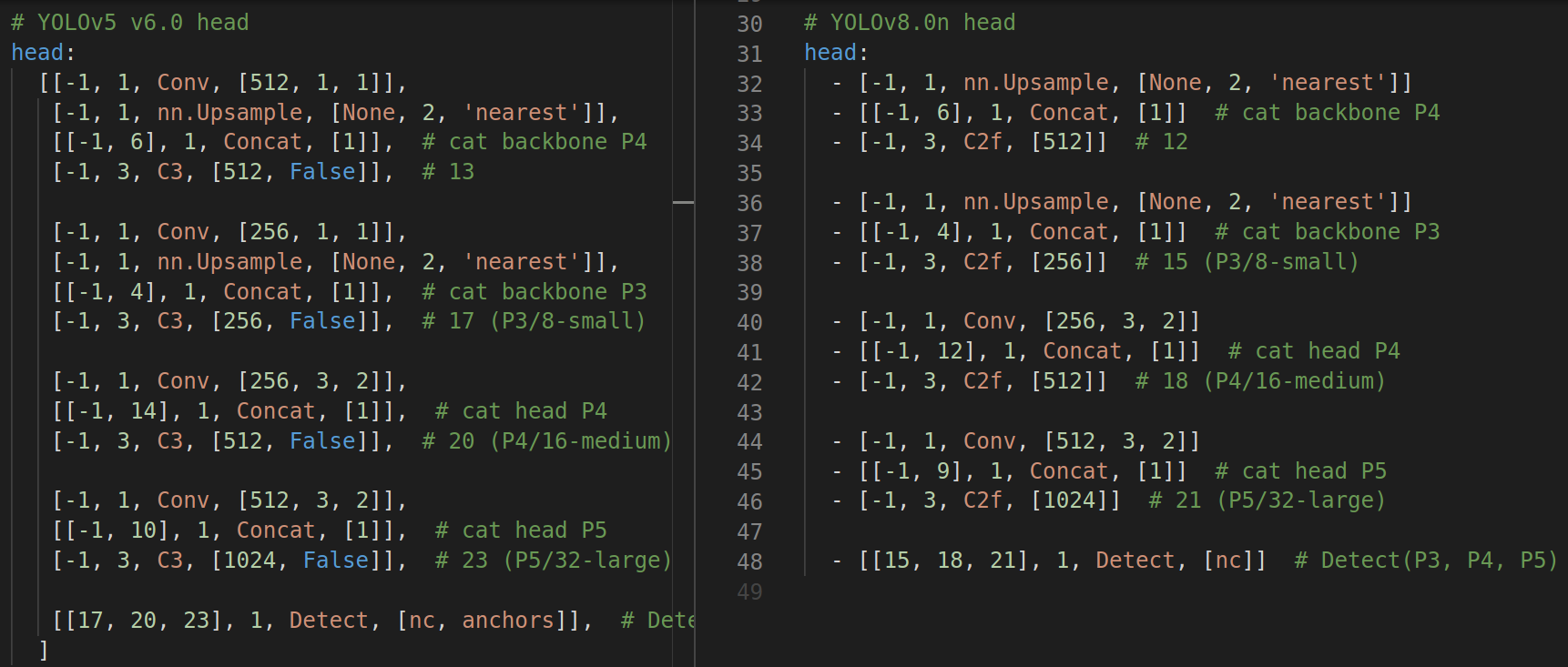
看起来,两个上采样前面的卷积没了,所以由 23 块-> 21 块(不算 Detect);C2f 同 backbone 一样,取代了 C3。
下面,我们看下具体的变化:
参考:https://github.com/ultralytics/ultralytics/issues/189
2. backbone
Conv:
代码:
注意:第一个 Conv 的 c2, k, s = [64, 3, 2]:

输出为:[bs, 32, 320,320], 通过控制 stride ,让输出的特征图大小减半。通过 width ,控制输出的特征图的个数(0.5*64)。所谓的 width 就是改变输出特征图的个数罢了。
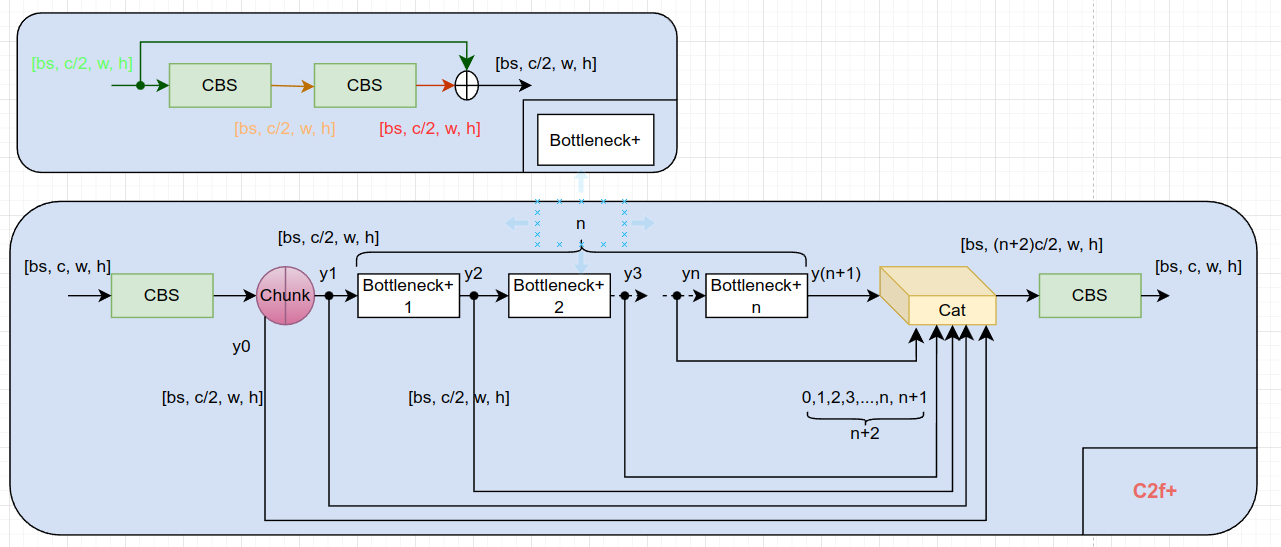
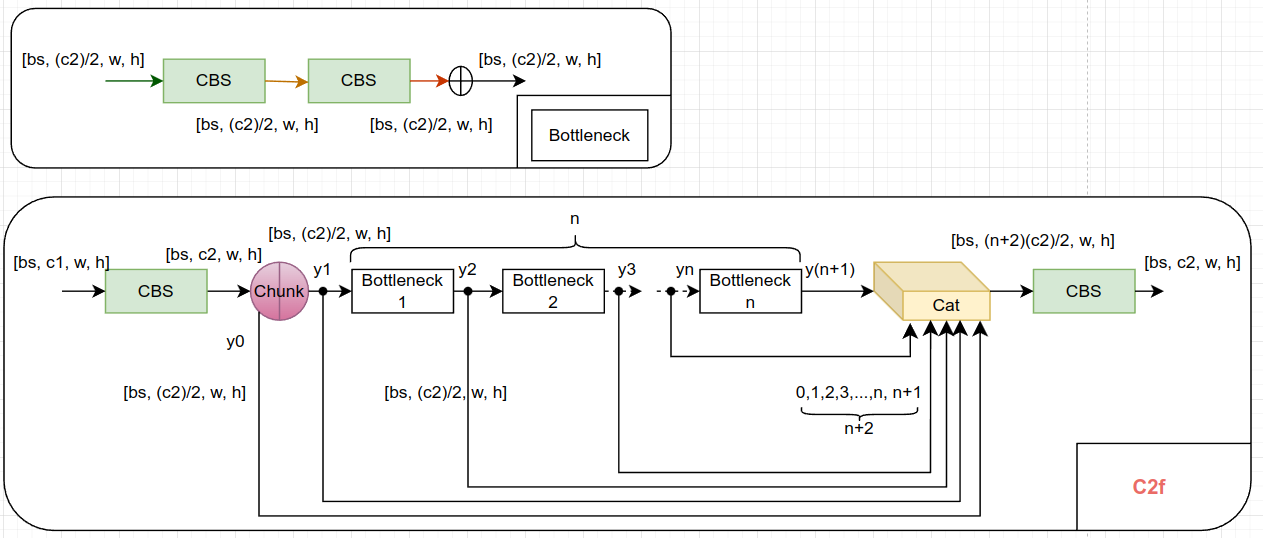
C2f+:
C2F is a function that maps the output of the second convolutional layer (C2) to feature maps with a larger number of channels (F).
https://arxiv.org/pdf/2304.00501.pdf
概念澄清:
https://www.bilibili.com/video/BV1WX4y1s7vr
https://github.com/ultralytics/ultralytics/issues/3576#issuecomment-1624624939
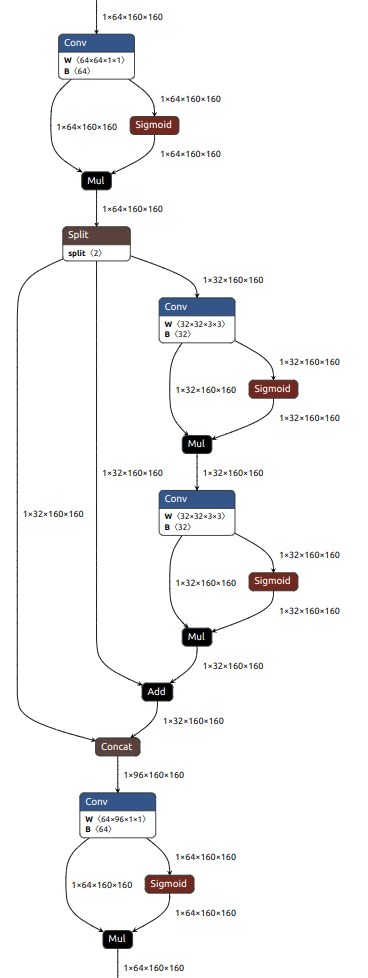
上图 netron 对 chunk 的可视化存在问题,不对! 少个分支, cat 的地方应该是 3 个输入。
C2f+ 中 + 的意思是:Bottleneck 中存在 残差(shortcut)。
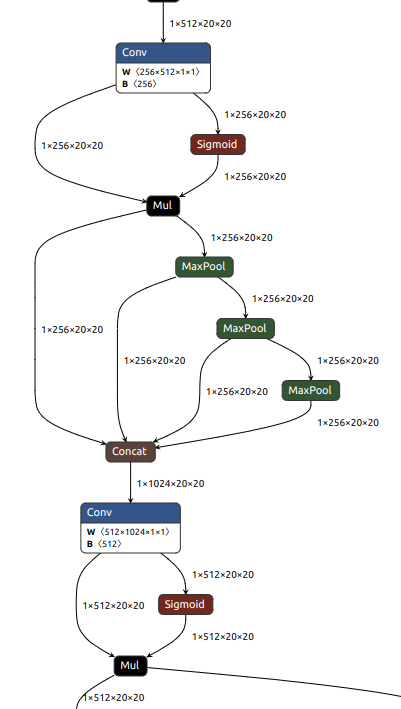
SPPF
被放在 backbone 的最后一层。
yolov8s 为例:
5.2 head
nn.Upsample
w,h 加倍,使用的 "nearest"
C2f:
Detect
class Detect(nn.Module):
"""YOLOv8 Detect head for detection models."""
dynamic = False # force grid reconstruction
export = False # export mode,用来导出部署时候使用
shape = None
anchors = torch.empty(0) # init
strides = torch.empty(0) # init
def __init__(self, nc=80, ch=()): # detection layer,coco 80类
super().__init__() # 子类 Detect 调用父类 nn.Module 的构造方法
self.nc = nc # number of classes
# https://github.com/ultralytics/ultralytics/blob/28893d9d2d200add93c0d32231a1919a79ad3776/ultralytics/cfg/models/v8/yolov8.yaml#L46C3-L46C58:
# - [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)
# https://github.com/ultralytics/ultralytics/blob/28893d9d2d200add93c0d32231a1919a79ad3776/ultralytics/nn/tasks.py#L649:
# elif m in (Detect, Segment, Pose):
# args.append([ch[x] for x in f])
# 这里 f=[15, 18, 21],所以 nl = 3, 其实就是 3个输出头
self.nl = len(ch) # number of detection layers
# DFL涉及到的reg_max参数,默认为16
self.reg_max = 16 # DFL channels (ch[0] // 16 to scale 4/8/12/16/20 for n/s/m/l/x)
# no = 80+16*4=144
self.no = nc + self.reg_max * 4 # number of outputs per anchor
self.stride = torch.zeros(self.nl) # strides computed during build
c2, c3 = max((16, ch[0] // 4, self.reg_max * 4)), max(ch[0], min(self.nc, 100)) # channels
self.cv2 = nn.ModuleList(
nn.Sequential(Conv(x, c2, 3), Conv(c2, c2, 3), nn.Conv2d(c2, 4 * self.reg_max, 1)) for x in ch)
self.cv3 = nn.ModuleList(nn.Sequential(Conv(x, c3, 3), Conv(c3, c3, 3), nn.Conv2d(c3, self.nc, 1)) for x in ch)
self.dfl = DFL(self.reg_max) if self.reg_max > 1 else nn.Identity()
def forward(self, x):
"""Concatenates and returns predicted bounding boxes and class probabilities."""
# shape-s: [1, 128, 80, 80]
shape = x[0].shape # BCHW
for i in range(self.nl):
# x[0]-s: [1, 144, 80, 80]
# x[1]-s: [1, 144, 40, 40]
# x[2]-s: [1, 144, 20, 20]
x[i] = torch.cat((self.cv2[i](x[i]), self.cv3[i](x[i])), 1)
if self.training:
return x
elif self.dynamic or self.shape != shape:
self.anchors, self.strides = (x.transpose(0, 1) for x in make_anchors(x, self.stride, 0.5))
self.shape = shape
# x_cat-s: [1, 144, 8400(80*80+40*40+20*20)]
x_cat = torch.cat([xi.view(shape[0], self.no, -1) for xi in x], 2)
if self.export and self.format in ('saved_model', 'pb', 'tflite', 'edgetpu', 'tfjs'): # avoid TF FlexSplitV ops
box = x_cat[:, :self.reg_max * 4]
cls = x_cat[:, self.reg_max * 4:]
else:
# box-s: [1, 64(self.reg_max(16) * 4), 8400]
# cls-s: [1, 80(nc), 8400]
box, cls = x_cat.split((self.reg_max * 4, self.nc), 1)
# dbox-s: [1, 4, 8400]
dbox = dist2bbox(self.dfl(box), self.anchors.unsqueeze(0), xywh=True, dim=1) * self.strides
if self.export and self.format in ('tflite', 'edgetpu'):
# Normalize xywh with image size to mitigate quantization error of TFLite integer models as done in YOLOv5:
# https://github.com/ultralytics/yolov5/blob/0c8de3fca4a702f8ff5c435e67f378d1fce70243/models/tf.py#L307-L309
# See this PR for details: https://github.com/ultralytics/ultralytics/pull/1695:
img_h = shape[2] * self.stride[0]
img_w = shape[3] * self.stride[0]
img_size = torch.tensor([img_w, img_h, img_w, img_h], device=dbox.device).reshape(1, 4, 1)
dbox /= img_size
# dbox-s: [1, 4, 8400]
# cls.sigmoid-s: [1, 80, 8400]
# y-s: [1, 84, 8400]
y = torch.cat((dbox, cls.sigmoid()), 1)
return y if self.export else (y, x)
def bias_init(self):
"""Initialize Detect() biases, WARNING: requires stride availability."""
m = self # self.model[-1] # Detect() module
# cf = torch.bincount(torch.tensor(np.concatenate(dataset.labels, 0)[:, 0]).long(), minlength=nc) + 1
# ncf = math.log(0.6 / (m.nc - 0.999999)) if cf is None else torch.log(cf / cf.sum()) # nominal class frequency
for a, b, s in zip(m.cv2, m.cv3, m.stride): # from
a[-1].bias.data[:] = 1.0 # box
b[-1].bias.data[:m.nc] = math.log(5 / m.nc / (640 / s) ** 2) # cls (.01 objects, 80 classes, 640 img)
def dist2bbox(distance, anchor_points, xywh=True, dim=-1):
"""Transform distance(ltrb) to box(xywh or xyxy)."""
lt, rb = distance.chunk(2, dim)
x1y1 = anchor_points - lt
x2y2 = anchor_points + rb
if xywh:
c_xy = (x1y1 + x2y2) / 2
wh = x2y2 - x1y1
return torch.cat((c_xy, wh), dim) # xywh bbox
return torch.cat((x1y1, x2y2), dim) # xyxy bbox
class DFL(nn.Module):
"""
Integral module of Distribution Focal Loss (DFL).
Proposed in Generalized Focal Loss https://ieeexplore.ieee.org/document/9792391
"""
def __init__(self, c1=16):
"""Initialize a convolutional layer with a given number of input channels."""
super().__init__()
self.conv = nn.Conv2d(c1, 1, 1, bias=False).requires_grad_(False)
x = torch.arange(c1, dtype=torch.float)
self.conv.weight.data[:] = nn.Parameter(x.view(1, c1, 1, 1))
self.c1 = c1
def forward(self, x):
"""Applies a transformer layer on input tensor 'x' and returns a tensor."""
b, c, a = x.shape # batch, channels, anchors
return self.conv(x.view(b, 4, self.c1, a).transpose(2, 1).softmax(1)).view(b, 4, a)
# return self.conv(x.view(b, self.c1, 4, a).softmax(1)).view(b, 4, a)
https://zhuanlan.zhihu.com/p/633094573
https://blog.csdn.net/weixin_44791964/article/details/129978504
训练的模型架构:
推理的模型架构:
6. anchor free
bbox 回归 + 分类 的解耦头 2*3
DFL
dist2bbox
没有 objness, 所以最后的输出的维度为 [1,84(xywh),8400(80*80 + 40*40 + 20*20)]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号