k8s集群搭建及相关问题解决
环境准备
三台机器:
- master:192.168.0.1
- node1:192.168.0.2
- node2:192.168.0.3
基础环境设置
-
[1] 设置3台机器hostname基于主机名通信:/etc/hosts; 每台机器设置对应hostname
sudo hostnamectl set-hostname k8s-master sudo hostnamectl set-hostname k8s-node1 sudo hostnamectl set-hostname k8s-node2然后编辑对应hosts
vim /etc/hosts添加当前机器机器的主机名访问配置
192.168.0.1 k8s-master 192.168.0.2 k8s-node1 192.168.0.3 k8s-node2 -
[2] 时间同步
主要是需要保证集群机器的时间是一致的,这里可以自己搜索资料进行配置 我直接先忽略了
-
[3] 关闭防火墙
systemctl stop firewalld -
[4] 关闭虚拟内存交换
sudo swapoff -a -
[5] 开启内核参数
echo 1 > /proc/sys/net/bridge/bridge-nf-call-iptables如果提示没有bridge-nf-call-iptables 可以执行
modprobe br_netfilter
配置yum源进行安装
- kubernetes的yum源
[1] vim /etc/yum.repos.d/kubernetes.repo
[2] 添加如下内容
[kubernetes]
name = kubernetes
baseurl = https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled = 1
gpgcheck = 1
gpgkey = https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
- docker的yum源
[1] cd /etc/yum.repos.d/
[2] wget https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
- 执行安装
yum install kubelet kubeadm kubectl docker-ce -y
初始化k8s集群
master机器上进行执行
kubeadm init --kubernetes-version=v1.22.2 --service-cidr=10.96.0.0/12 --pod-network-cidr=10.244.0.0/16 --ignore-preflight-errors=Swap --ignore-preflight-errors=NumCPU --image-repository registry.aliyuncs.com/google_containers
解释:
--apiserver-advertise-address:指定用 Master 的哪个IP地址与 Cluster的其他节点通信。
--service-cidr:指定Service网络的范围,即负载均衡VIP使用的IP地址段。
--pod-network-cidr:指定Pod网络的范围,即Pod的IP地址段。
--image-repository:Kubenetes默认Registries地址是 k8s.gcr.io,在国内并不能访问 gcr.io,在1.13版本中我们可以增加-image-repository参数,默认值是 k8s.gcr.io,将其指定为阿里云镜像地址:registry.aliyuncs.com/google_containers。
--kubernetes-version=v1.13.3:指定要安装的版本号。
--ignore-preflight-errors=:忽略运行时的错误,例如上面目前存在[ERROR NumCPU]和[ERROR Swap],忽略这两个报错就是增加--ignore-preflight-errors=NumCPU 和--ignore-preflight-errors=Swap的配置即可。
正常会成功初始化完成,如果有相关异常提示参考最后的 问题记录
根据集群初始化成功提示 进行执行
[1] 根据提示进行执行
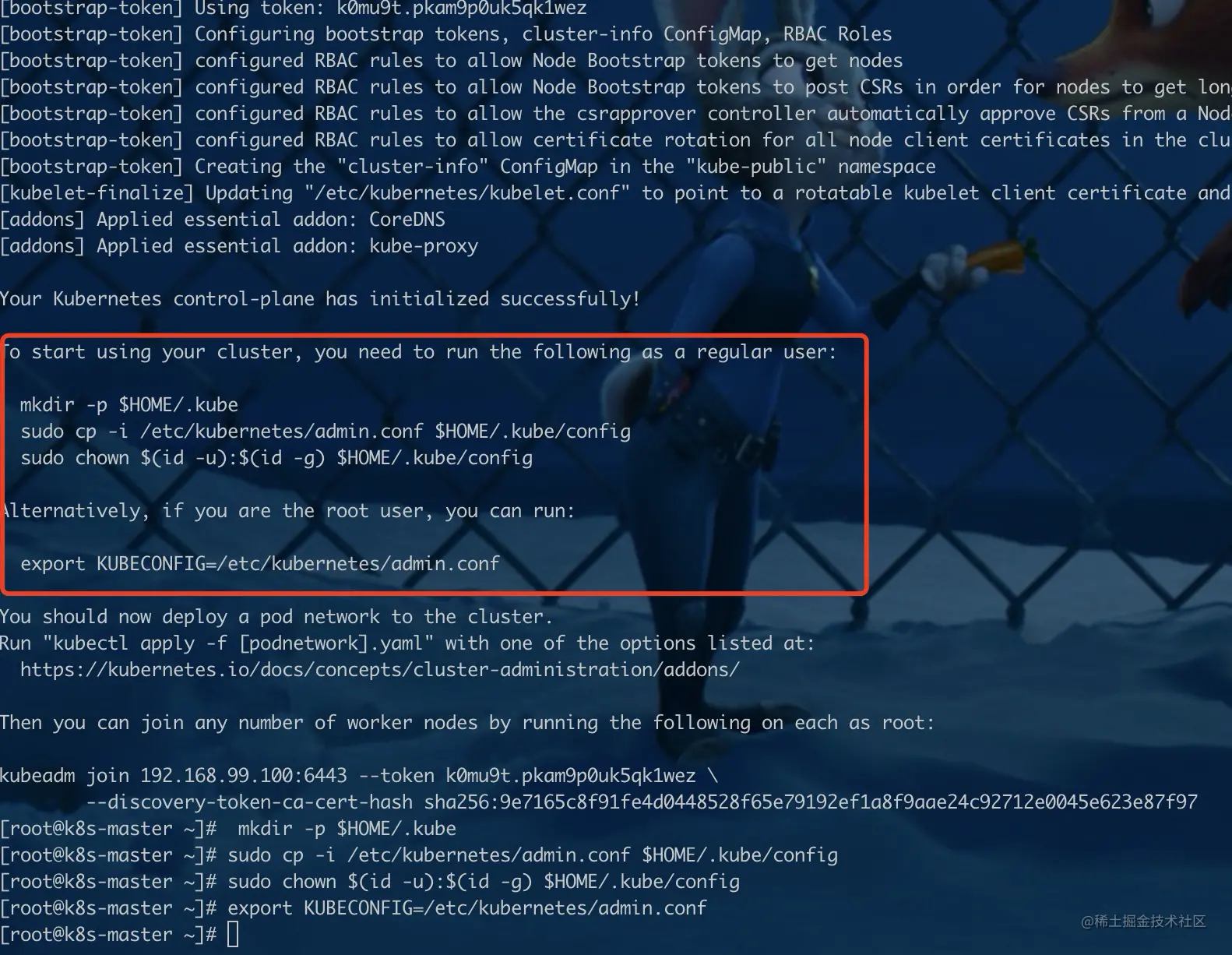
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
export KUBECONFIG=/etc/kubernetes/admin.conf
[2] 这里需要记录下这行信息,是node节点加入集群时需要使用
kubeadm join 192.168.99.100:6443 --token k0mu9t.pkam9p0uk5qk1wez \
--discovery-token-ca-cert-hash sha256:9e7165c8f91fe4d0448528f65e79193ef1a8f9aae24c92712e0045e623e87f97
添加网络插件calico
这里必须为k8s装上对应网络插件才能正常使用,也有比较多方式,这里选择的是calico 直接按照官网命令进行执行就可以了 docs.projectcalico.org/getting-sta…
添加node节点到集群
node机器上进行执行
kubeadm join 192.168.99.100:6443 --token k0mu9t.pkam9p0uk5qk1wez --discovery-token-ca-cert-hash sha256:9e7165c8f91fe4d0448528f65e79192ef1a8f9aae24c92712e0045e623e87f97;
- 注意如果你上面master搭建耽搁了过久,造成node加入时是在24小时之后,这里会加入失败,因为master的token有效期是24小时,需要重新生成token
- kubeadm token create
1hypr7.80vyju4rv72mixea
替换上面命令的 --token即可
- master 上观察是否成功加入
watch kubectl get nodes
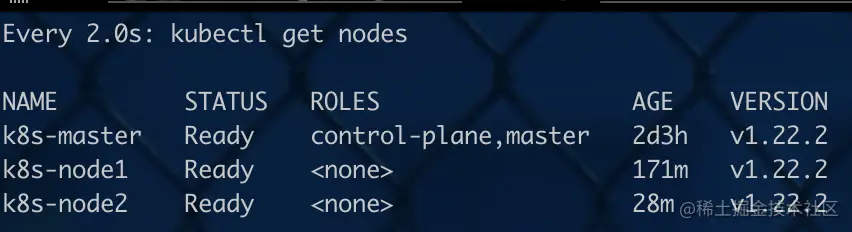
- 好了,node join以后就算基本搭建完成了 这里如果你再node节点进行执行的时候碰到一些错误,基本都是kebelet没有成功运行的问题,可以直接执行
kebelet会看到相关错误(比如node的kebelet和docker 的 cgroup driver不一致,或者重复执行后某些文件已经存在等,这些具体解决方法可以参考文章下面的问题记录) 解决具体的问题再进行执行加入集群
问题记录
- docker service 未启动
[preflight] Running pre-flight checks
[WARNING Service-Docker]: docker service is not enabled, please run 'systemctl enable docker.service'
systemctl enable docker.service
- 重新初始化会提示相关文件已经存在
error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR FileAvailable--etc-kubernetes-manifests-kube-apiserver.yaml]: /etc/kubernetes/manifests/kube-apiserver.yaml already exists
[ERROR FileAvailable--etc-kubernetes-manifests-kube-controller-manager.yaml]: /etc/kubernetes/manifests/kube-controller-manager.yaml already exists
[ERROR FileAvailable--etc-kubernetes-manifests-kube-scheduler.yaml]: /etc/kubernetes/manifests/kube-scheduler.yaml already exists
[ERROR FileAvailable--etc-kubernetes-manifests-etcd.yaml]: /etc/kubernetes/manifests/etcd.yaml already exists
删除所有的记录,rm rf /etc/kubernetes/*
- 重新初始化提示端口被占用
[preflight] Running pre-flight checks
error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR Port-10250]: Port 10250 is in use
[preflight] If you know what you are doing, you can make a check
To see the stack trace of this error execute with --v=5 or higher
kubeadm reset
- 提示
docker和kubelet的cgroup driver不一致
Sep 23 17:05:38 sa-service-istio-3 kubelet: E0923 17:05:38.928155 10560 server.go:294] "Failed to run kubelet" err="failed to run Kubelet: misconfiguration: kubelet cgroup driver: \"systemd\" is different from docker cgroup driver: \"cgroupfs\""
-
更改cgroup driver一致,这里是更改了docker的配置
[1] 查看docker的cgroup配置
docker info[2] 修改或创建/etc/docker/daemon.json
加入下面内容 { "exec-opts": ["native.cgroupdriver=systemd"] }[3] 重启docker systemctl restart docker
-
初始化成功
[kubelet-finalize] Updating "/etc/kubernetes/kubelet.conf" to point to a rotatable kubelet client certificate and key
[addons] Applied essential addon: CoreDNS
[addons] Applied essential addon: kube-proxy
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.99.100:6443 --token k0mu9t.pkam9p0uk5qk1wez \
--discovery-token-ca-cert-hash sha256:9e7165c8f91fe4d0448528f65e79192ef1a8f9aae24c92712e0045e623e87f97
-
unhealthy
这里看到这种情况,是/etc/kubernetes/manifests/下的kube-controller-manager.yaml和kube-scheduler.yaml设置的默认端口是0导致的
注释掉对应的port即可编辑两个文件,找到 prot=0的配置直接注释掉
-
重启kubelet
这里再次查看有几秒延迟,要稍等下
scheduler Healthy ok controller-manager Healthy ok etcd-0 Healthy {"health":"true","reason":""}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号