论文导读:RESOURCE ELASTICITY IN DISTRIBUTED DEEP LEARNING
1 Introduction
目前分布式学习在资源供应方面,都是依据之前的相似任务进行手动设置,但是对于首次运行的负载而言,只能反复尝试以找到最优的资源配置。
但是反复试错的代价是十分高昂的,每一轮迭代都要花几分钟重建图,而且,确定分配给当前作业多少资源需要提前知道作业的规模特征。
所以现在的资源分配策略是过量分配,这样有两种不好:第一,资源的浪费,不仅是费用高,而且物理资源也没有高效利用;第二,过量分配无法解决stragglers
问题,即如果有一台低效机器,由于分布式的效率是由最后完成的机器决定的,因此,存在个别机器拖垮整个集群的现象。
1.1 Main challenges
挑战一
当前的用户资源分配习惯主要依赖于主流的分布式学习系统,如TensorFlow和PyTorch。
TensorFlow的集群规模是在一开始就设定好的,且训练开始后是无法动态变动;而PyTorch的资源动态变化主要体现在输入和操作上。
现有的作业资源分配在其生命周期内是静态不变的,而在面对强烈的资源动态变动需求下,现有的系统难以很好的提供此类需求的扩展。
挑战二
简单的scaling out导致训练的批尺寸增大,影响模型的收敛性(详细参照博客)简单来说,就是大批尺寸的训练容易收敛成sharpminmum,而小批尺寸训练会收敛成flat minimum
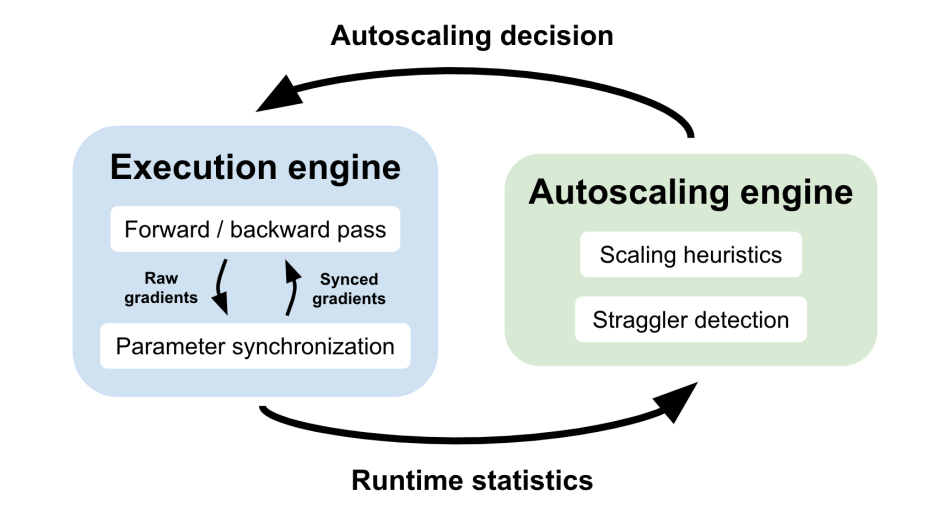
1.2 Autoscaling engine for distributed learning
本文设计的自动缩放引擎可在资源分配的变化过程中,我们的系统重用现有的进程,并将所有相关的程序状态保存在内存中,以最小化空闲时间
在考虑上述思想的同时,有以下贡献:
1.描述了当前先进的分布式学习系统在体系结构层面上对资源缩放的限制
2.设计了分布式学习的启发式缩放策略,其中考虑了吞吐和代价
3.是第一个无需过量分配资源解决了straggler问题的分布式学习引擎
2. BackGround
2.1 TensorFlow架构中的限制
在TensorFlow的分布式学习中,模型构建的图复制到各个节点中,且在每次迭代后将每个worker上的参数同步,这些通讯操作时通过TensorFlow中特殊操作SEND和RECEIVE完成的。
如果在运行时直接进行集群的扩展,那么需要将现存的send和receive操作重新连到新节点上;
且TensorFlow的同步策略是默认在程序的整个生命周期中进程的数量都是固定的。模型参数是在最初配置下创建的,因此,扩展后需要根据新的集群成员数重新构建模型图。
2.2 批尺寸的限制
这里先介绍文中的术语: local batch每个设备上的样本;global batch所有设备上的样本;minibatch每一步处理的所有设备上的样本
2.2.1 local batch的限制
由于分布式学习中,每个节点的数据是加载到内存中计算,且计算结果也是放到内存中存储的,因此在对于local batch的限制就是内存容量。
2.2.2 global batch的限制
近期的研究成果展示,全局批尺寸的大小会影响模型的收敛,对于常见的负载,一般都是有阈值导致模型的训练效果明显下降,因此,这个阈值就是global batch的限制。
而且,也需要考虑到节点扩增带来的收益问题,如成本收益。
2.2.3 缩放的限制
当有新节点添加到集群中时,对于批尺寸大小的影响,有两种方法:一是保持local batch不变,但这样会导致global batch急速爬升,会导致2.2.2中所说的训练效果下降;二是保证global batch不变,这样每个节点的local batch会下降,这样会使整体吞吐下降。
最终,本文策略采取一种取中的措施,接受用户输入的最大global batch并固定local batch直到超过阈值。
3 SYSTEM OVERVIEW
自动缩放引擎有两个主要组件:扩展启发和延迟检测。它收集这些运行时统计信息,以构建每个单独worker和每个集群大小的吞吐量分布。在这些分布中,引擎可以在小批量粒度上做出细粒度的缩放决策。在实践中,更合理的做法是每n个(例如10个)小批量地进行决策,以确保我们有足够的数据点。 一旦做出了缩放决定,系统只需要更新执行引擎的参数同步部分。其他用于计算梯度的内存状态,如预处理样本、模型参数和计算图形,可以按原样重用。这允许系统在响应资源分配的更改时最小化空闲时间。
4 SCALING HEURISTICS
4.1 Scaling schedule

依图可见,这种缩放是有延迟的,这段延迟是执行完缩放策略后收集数据进行缩放条件判断的。执行完每次扩展(如图中勾),都要收集数据计算缩放条件,如果符合条件,继续扩展,如果不符合条件(叉),跳回到最近的一个配置点,继续收集数据检测是否符合条件。
4.2 Scaling conditions
(只讲第一个吞吐效率吧,第二个太好理解了)
计算公式:

看着很麻烦,意思其实就是d个新节点的实际总吞吐量除以按照之前的平均吞吐计算下,d个新节点的期望总吞吐量,最终,条件判断为:
![]()
(算了还是说一下成本条件吧)
首先定义一下期望成本:

然后了解一下文章中列出来的常见效能模型:
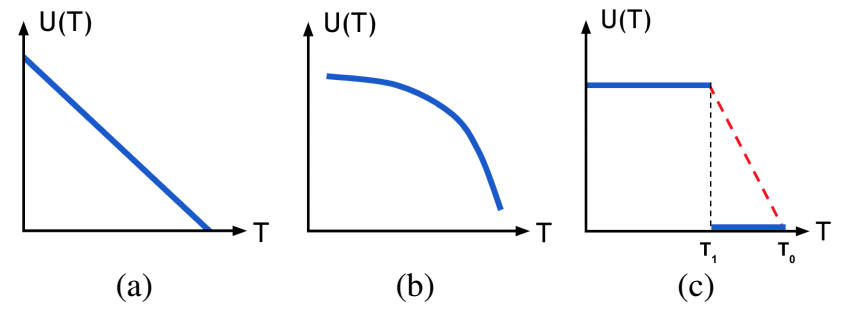
所以目标为求Min[U(T(K))-C(K)]
缩放的情况:
显而易见,当U(T(K+1))-U(T(K))>C(K+1)-C(K),即添加一个节点的效能大于其成本时,进行扩展。
5. STRAGGLER DETECTION
通过运行过程中的行为数据收集,可以监控每个节点的状态,因此有了初版的detection程序:

主要思想就是监控集群中每个worker的吞吐,用中值作为参考,若worker的吞吐低于整体吞吐的中值一个阈值,则认为是straggler。
但是这样做有些激进,如果因为特殊情况的极个别次数的低性能,就把它认定为straggler,这是不对的,本文的目的是检测出一个持续性的straggler,一个解决方式是监测到一个节点持续缓慢了n个批次,但是这样的话,会有特例,若一个worker持续执行缓慢了n-1个批次,而在第n次执行正常,那么这个情况就被忽略了。因此这里引入了指数加权移动平均算法来解决这个问题。
6. IMPLEMENTATION
这部分需要考虑执行扩展的时候,如何处理可将部署时间代价缩到最小。
一般的重启是将模型存储到check point,然后kill掉现有的进程,在新资源配置下重新部署,这样的时间成本太大。
本文中当一个新worker加入时,每个现有的worker只需要从其图中分离旧的allreduce操作并重新连接新操作。由于最初的计算比较耗时,比如加载库、构建模型图、预处理第一批数据,因此会让待加入的worker事先运行几个批次。
(原创内容,转载备注)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号