

软工第二次作业——文本查重
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/gdgy/Networkengineering1834 |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/gdgy/Networkengineering1834/homework/11146 |
| 这个作业的目标 | 实现论文查重算法,学会使用PSP表格估计,学会 Git commit 规范,学会单元测试 |
1. Github仓库
https://github.com/NYH5288/5288
2. PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 20 | 25 |
| · Estimate | · 估计这个任务需要多少时间 | 20 | 25 |
| Development | 开发 | 465 | 600 |
| · Analysis | · 需求分析 (包括学习新技术) | 30 | 30 |
| · Design Spec | · 生成设计文档 | 60 | 80 |
| · Design Review | · 设计复审 | 60 | 70 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 15 | 15 |
| · Design | · 具体设计 | 30 | 40 |
| · Coding | · 具体编码 | 180 | 280 |
| · Code Review | · 代码复审 | 60 | 60 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 30 | 35 |
| Reporting | 报告 | 60 | 90 |
| · Test Report | · 测试报告 | 30 | 40 |
| · Size Measurement | · 计算工作量 | 10 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 20 | 25 |
| Total | · 合计 | 545 | 1425 |
3.接口的设计与实现过程
原理:文本相似度分析,顾名思义是分析文本之间相似程度,实际应用范围很广泛,小到文章的筛选推荐、拼写纠错,大到浏览器的搜索,都离不开这项技术。文本相似度的计算方法使用的是基于TF-IDF模型的相似度分析方法。配置的环境是python3.8,借用了Python工具包的三个包,分别是jieba,codecs,以及gensim下的3个包。
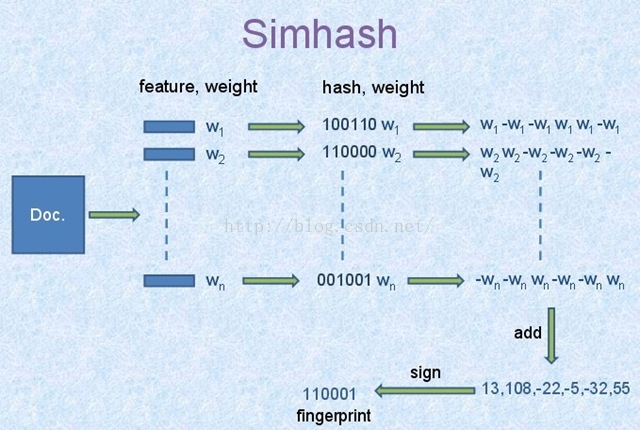
核心算法:Simhash
对于所需要进行对比的文章进行分词,可得到该文本的有效特征向量,同时给特征向量附加权重来体现出现的频率以及重要程度。接着通过hash函数来对其计算hash值,将字符串转换为数字,对其进行加权,然后降维,形成哈希签名。
一、去停用词
由于文章中的停用词对文章的内容影响不大,所以要考虑先把文章中的停用词给去掉,stopwords.txt可以直接在网上下载。 jieba分词里面也对词性做了分类,如果没有stopwords.txt可以考虑用jieba分词自带的词库进行去分词的操作。

二、文件的读入
将要进行比对的TXT用文件夹进行存放或者直接加入项目中。
三、创建词袋模型
建立稀疏矩阵,把上一环节分好的词,转化成方便计算机处理的格式,把句子变成字典形式,出现的数字对应词语频率,数字的位置对应词语的位置。

四、创建IF-TDF模型
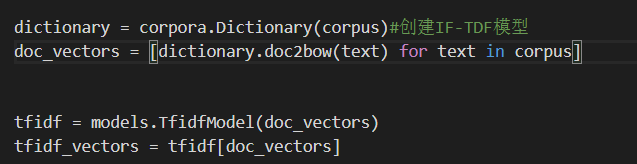
五、结果

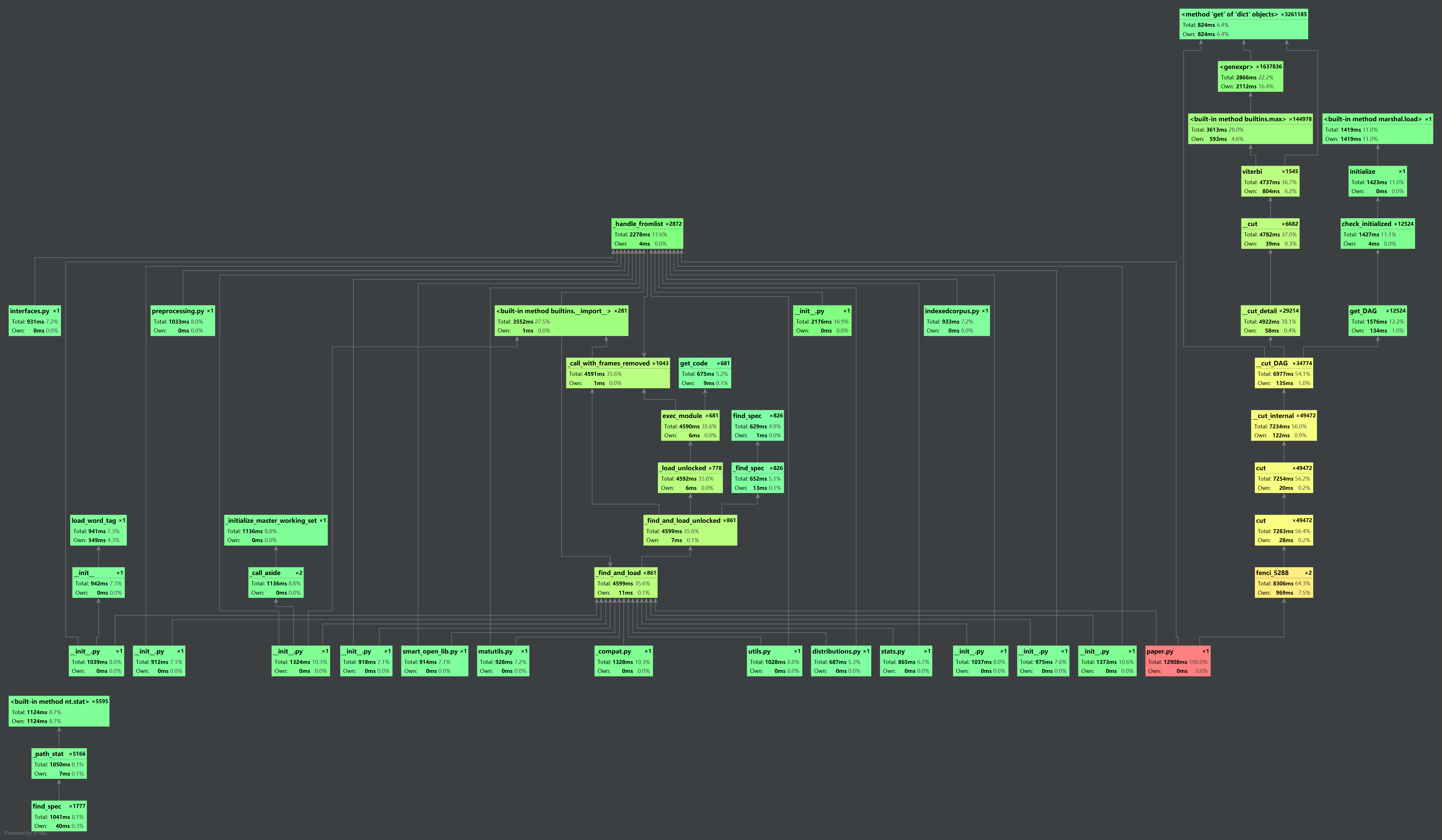
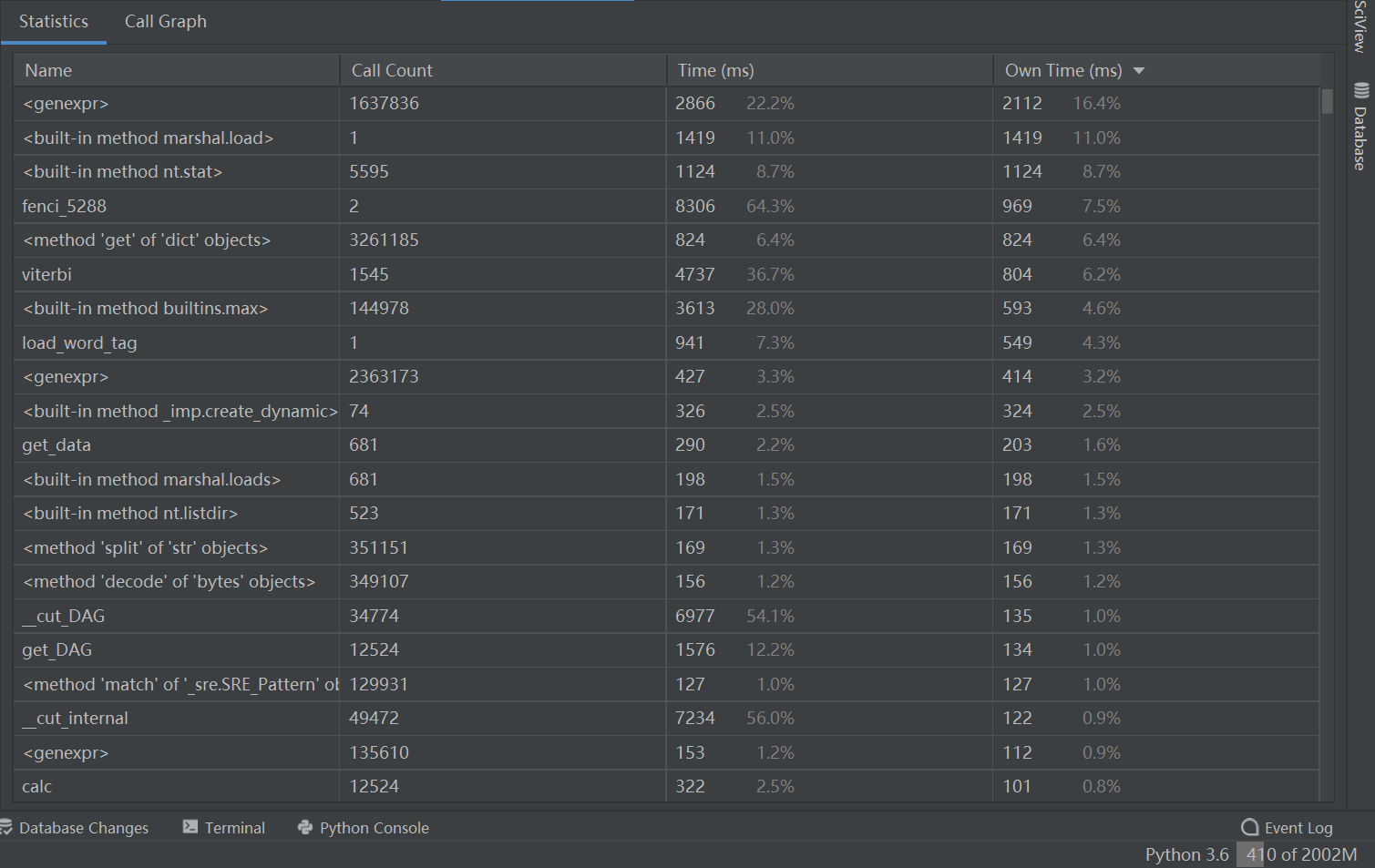
4.计算模块接口部分的性能改进

5.代码块部分单元测试展示

 浙公网安备 33010602011771号
浙公网安备 33010602011771号