
DataFrame.nunique(),DataFrame.count()
1. nunique()
DataFrame.nunique(axis = 0,dropna = True )
功能:计算请求轴上的不同观察结果
参数:
- axis : {0或'index',1或'columns'},默认为0。0或'index'用于行方式,1或'列'用于列方式。
- dropna : bool,默认为True,不要在计数中包含NaN。
返回: Series
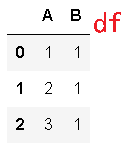
>>> df = pd.DataFrame({'A': [1, 2, 3], 'B': [1, 1, 1]})
>>> df.nunique()
A 3
B 1
dtype: int64
>>> df.nunique(axis=1) 0 1 1 2 2 2 dtype: int64
2. count()
DataFrame.count(axis = 0,level = None,numeric_only = False )
功能:计算每列或每行的非NA单元格。
None,NaN,NaT和numpy.inf都被视作NA
参数:
- axis : {0或'index',1或'columns'},默认为0(行),如果为每列生成0或'索引'计数。如果为每行生成1或'列'计数。
- level : int或str,可选,如果轴是MultiIndex(分层),则沿特定级别计数,折叠到DataFrame中。一个STR指定级别名称。
- numeric_only : boolean,默认为False,仅包含float,int或boolean数据。
返回:Series或DataFrame对于每个列/行,非NA / null条目的数量。如果指定了level,则返回DataFrame。
从字典构造DataFrame
>>> df = pd.DataFrame({"Person":
... ["John", "Myla", "Lewis", "John", "Myla"],
... "Age": [24., np.nan, 21., 33, 26],
... "Single": [False, True, True, True, False]})
>>> df
Person Age Single
0 John 24.0 False
1 Myla NaN True
2 Lewis 21.0 True
3 John 33.0 True
4 Myla 26.0 False
注意不计数的NA值
>>> df.count() Person 5 Age 4 Single 5 dtype: int64
每行计数:
>>> df.count(axis='columns') 0 3 1 2 2 3 3 3 4 3 dtype: int64
计算MultiIndex的一个级别:
>>> df.set_index(["Person", "Single"]).count(level="Person")
Age
Person
John 2
Lewis 1
Myla 1
参考文献:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号