MapReduce案例一:日志清洗
一、数据样式
网站日志的数据样例:
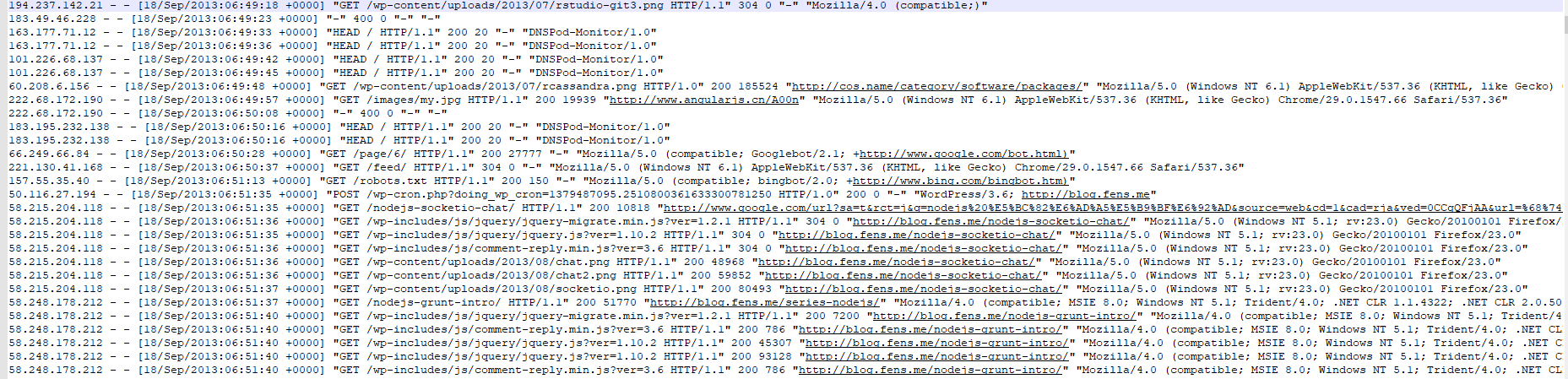
二、需求
去除日志中字段长度小于等于11的日志。
三、分析
网站日志数据类型,每一行中的每个字段用空格隔开,且每一行的字段数量并非一致。直接在mapper中切割字段进行过滤。
四、代码实现
- 1、编写LogMapper类
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class LogMapper extends Mapper<LongWritable, Text, Text, NullWritable>{
Text k = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1 获取1行数据
String line = value.toString();
// 2 解析日志
boolean result = parseLog(line,context);
// 3 日志不合法退出
if (!result) {
return;
}
// 4 设置输出数据Text
k.set(line);
// 5 写出数据
context.write(k, NullWritable.get());
}
// 2 解析日志
private boolean parseLog(String line, Context context) {
// 1 截取
String[] fields = line.split(" ");
// 2 日志长度大于11的为合法
if (fields.length > 11) {
// 系统计数器
context.getCounter("map", "true").increment(1);
return true;
}else {
context.getCounter("map", "false").increment(1);
return false;
}
}
}
- 2、编写LogDriver类
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class LogDriver {
public static void main(String[] args) throws Exception {
args = new String[]{"D:\\大数据API\\web.txt","D:\\大数据API\\data1"};
// 1 获取job信息
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
// 2 加载jar包
job.setJarByClass(LogDriver.class);
// 3 关联map
job.setMapperClass(LogMapper.class);
// 4 设置最终输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
// 5 设置输入和输出路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 6 提交
job.waitForCompletion(true);
}
}
- 3、运行结果

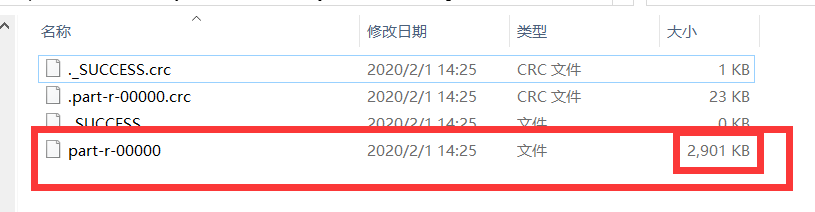
文件大小前后比较,小了70k。其部分内容图:

作者:落花桂
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号