
Python学习笔记-----文本处理
Python文本处理
1.CSV文件(Comma-Separated Values )
2.TSC文件(Tab-Separated Values )
1.文本文件的打开和读取,写入
file = open(file_name [, mode='r' [ , buffering=-1 [ , encoding = None ]]])
- file:表示要创建的文件对象。
- file_name:要创建或打开文件的文件名称,该名称要用引号(单引号或双引号都可以)括起来。需要注意的是,如果要打开的文件和当前执行的代码文件位于同一目录,则直接写文件名即可;否则,此参数需要指定打开文件所在的完整路径。
- mode:可选参数,用于指定文件的打开模式。可选的打开模式如表 1 所示。如果不写,则默认以只读(r)模式打开文件。
- buffering:可选参数,用于指定对文件做读写操作时,是否使用缓冲区(本节后续会详细介绍)。
- encoding:手动设定打开文件时所使用的编码格式,不同平台的 ecoding 参数值也不同,以 Windows 为例,其默认为 cp936(实际上就是 GBK 编码)。
注意点:
1.如果显示使用open()方法打开文件后,一定要记住使用close()方法关掉文件
另外一种方法是使用: with open(file_path,'r', encoding='utf-8') as f:
这样打开后,可以直接处理,就不用再手动关闭文件了
2.读取文件的方法
2.1调用read()会一次性读取文件的全部内容,如果文件有10G,内存就爆了,所以,要保险起见,可以反复调用read(size)方法,每次最多读取size个字节的内容。另外,
2.2 调用readline()可以每次读取一行内容,
2.3调用readlines()一次读取所有内容并按行返回list。
因此,要根据需要决定怎么调用。
如果文件很小,read()一次性读取最方便;如果不能确定文件大小,反复调用read(size)比较保险;如果是配置文件,调用readlines()最方便
3.写文件操作
写文件和读文件是一样的,唯一区别是调用open()函数时,传入标识符'w'或者'wb'表示写文本文件或写二进制文件:
以'w'模式写入文件时,如果文件已存在,会直接覆盖(相当于删掉后新写入一个文件)。
如果我们希望追加到文件末尾怎么办?可以传入'a'以追加(append)模式写入。
4.读写模式的类型有:
| 模式 | 描述 |
|---|---|
| t | 文本模式 (默认)。 |
| x | 写模式,新建一个文件,如果该文件已存在则会报错。 |
| b | 二进制模式。 |
| + | 打开一个文件进行更新(可读可写)。 |
| U | 通用换行模式(不推荐)。 |
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。一般用于非文本文件如图片等。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。一般用于非文本文件如图片等。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
with open("D:\\Programming\\Python_Virtaul_Env\\Python_Study\\txtfile_Process\\samplefiles\\Store_List-data.txt", 'r') as reader: #Read and print the entire file line by line line = reader.readline() while line != '': #The EOF char is an empty string print(line, end='') line = reader.readline()
file_path="D:\\Programming\\Python_Virtaul_Env\\Python_Study\\txtfile_Process\\samplefiles\\Store_List-data.txt" try: f=open(file_path,'r', encoding='utf-8') #f=open(file_path,'r', encoding='gbk') read_str=f.read() print(read_str) finally: if f: f.close() print("*************222222**************") with open(file_path,'r', encoding='utf-8') as f: read_str = f.readline() print(read_str) read_str = f.readline() print(read_str) print("***********333333***************") with open(file_path,'r', encoding='utf-8') as f: read_str = f.readlines() print(read_str) print("***********44444444***************") with open(file_path,'r', encoding='utf-8', errors='ignore') as f: for line in f.readlines(): print(line.strip()) # 把末尾的'\n'删掉 print("***********55555555----Write file**************") with open(file_path,'a', encoding='utf-8', errors='ignore') as f: f.write('Hello, world!\n') print("***********66666***************") with open(file_path,'r', encoding='utf-8', errors='ignore') as f: for line in f.readlines(): print(line.strip()) # 把末尾的'\n'删掉
2.文本文件读取的方法有哪些
------------恢复内容开始------------
Python文本处理
1.CSV文件(Comma-Separated Values )
2.TSC文件(Tab-Separated Values )
1.文本文件的打开和读取,写入
file = open(file_name [, mode='r' [ , buffering=-1 [ , encoding = None ]]])
- file:表示要创建的文件对象。
- file_name:要创建或打开文件的文件名称,该名称要用引号(单引号或双引号都可以)括起来。需要注意的是,如果要打开的文件和当前执行的代码文件位于同一目录,则直接写文件名即可;否则,此参数需要指定打开文件所在的完整路径。
- mode:可选参数,用于指定文件的打开模式。可选的打开模式如表 1 所示。如果不写,则默认以只读(r)模式打开文件。
- buffering:可选参数,用于指定对文件做读写操作时,是否使用缓冲区(本节后续会详细介绍)。
- encoding:手动设定打开文件时所使用的编码格式,不同平台的 ecoding 参数值也不同,以 Windows 为例,其默认为 cp936(实际上就是 GBK 编码)。
注意点:
1.如果显示使用open()方法打开文件后,一定要记住使用close()方法关掉文件
另外一种方法是使用: with open(file_path,'r', encoding='utf-8') as f:
这样打开后,可以直接处理,就不用再手动关闭文件了
2.读取文件的方法
2.1调用read()会一次性读取文件的全部内容,如果文件有10G,内存就爆了,所以,要保险起见,可以反复调用read(size)方法,每次最多读取size个字节的内容。另外,
2.2 调用readline()可以每次读取一行内容,
2.3调用readlines()一次读取所有内容并按行返回list。
因此,要根据需要决定怎么调用。
如果文件很小,read()一次性读取最方便;如果不能确定文件大小,反复调用read(size)比较保险;如果是配置文件,调用readlines()最方便
3.写文件操作
写文件和读文件是一样的,唯一区别是调用open()函数时,传入标识符'w'或者'wb'表示写文本文件或写二进制文件:
以'w'模式写入文件时,如果文件已存在,会直接覆盖(相当于删掉后新写入一个文件)。
如果我们希望追加到文件末尾怎么办?可以传入'a'以追加(append)模式写入。
4.读写模式的类型有:
| 模式 | 描述 |
|---|---|
| t | 文本模式 (默认)。 |
| x | 写模式,新建一个文件,如果该文件已存在则会报错。 |
| b | 二进制模式。 |
| + | 打开一个文件进行更新(可读可写)。 |
| U | 通用换行模式(不推荐)。 |
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。一般用于非文本文件如图片等。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。一般用于非文本文件如图片等。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
with open("D:\\Programming\\Python_Virtaul_Env\\Python_Study\\txtfile_Process\\samplefiles\\Store_List-data.txt", 'r') as reader: #Read and print the entire file line by line line = reader.readline()
while line != '': #The EOF char is an empty string print(line, end='') line = reader.readline()
file = open("D:\\Programming\\Python_Virtaul_Env\\Python_Study\\txtfile_Process\\samplefiles\\Store_List-data.txt",'r') while True: next_line = file.readline() if not next_line: break; print(next_line.strip()) file.close()
# open the file txtcontent_list = open("D:\\Programming\\Python_Virtaul_Env\\Python_Study\\txtfile_Process\\samplefiles\\Store_List-data.txt",'r') for line in txtcontent_list: print(line.strip()) txtcontent_list.close()
with open("D:\\Programming\\Python_Virtaul_Env\\Python_Study\\txtfile_Process\\samplefiles\\Store_List-data.txt", 'r') as reader: for line in reader.readlines(): #readlines() returns a list where each element in the list represents a line in the file print(line, end='')
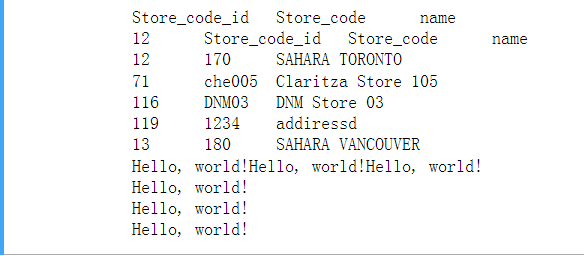
with open("D:\\Programming\\Python_Virtaul_Env\\Python_Study\\txtfile_Process\\samplefiles\\Store_List-data.txt", 'r') as reader: # Read and print the entire file line by line for line in reader: #more Pythonic and can be quicker and more memory efficient. Therefore, it is suggested to use this instead. print(line, end='')
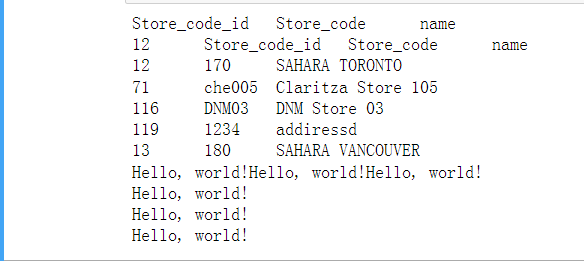
file_path="D:\\Programming\\Python_Virtaul_Env\\Python_Study\\txtfile_Process\\samplefiles\\Store_List-data.txt" try: f=open(file_path,'r', encoding='utf-8') #f=open(file_path,'r', encoding='gbk') read_str=f.read() print(read_str) finally: if f: f.close() print("*************222222**************") with open(file_path,'r', encoding='utf-8') as f: read_str = f.readline() print(read_str) read_str = f.readline() print(read_str) print("***********333333***************") with open(file_path,'r', encoding='utf-8') as f: read_str = f.readlines() print(read_str) print("***********44444444***************") with open(file_path,'r', encoding='utf-8', errors='ignore') as f: for line in f.readlines(): print(line.strip()) # 把末尾的'\n'删掉 print("***********55555555----Write file**************") with open(file_path,'a', encoding='utf-8', errors='ignore') as f: f.write('Hello, world!\n') print("***********66666***************") with open(file_path,'r', encoding='utf-8', errors='ignore') as f: for line in f.readlines(): print(line.strip()) # 把末尾的'\n'删掉
2.文本文件读取的方法有哪些
2.1 使用 csv 库
2.2 使用 pandas 库
在Python中,pandas是基于NumPy数组构建的,使数据预处理、清洗、分析工作变得更快更简单。
pandas是专门为处理表格和混杂数据设计的,而NumPy更适合处理统一的数值数组数据。
2.3 使用 DataFrame 库
pandas官方对DataFrame的定义了三个特点:Two-dimensional(二维), size-mutable(尺寸可变), potentially heterogeneous tabular data(潜在的异构表格型数据)。
通俗的说,DataFrame是一种表格型数据结构,由行(rows)和列(columns)组成,每列可以是不同的值类型(数值、字符串、布尔值等)。DataFrame既有行索引也有列索引,
它可以被看做由series组成的字典(共用同一个索引)。index为行索引,column为列索引。我们可以对整行和整列进行操作。可以理解成是一种存放Series对象,结构类似于字典的容器。
由于DataFrame用起来方便,很多库都基于DataFrame编写。
2.4 使用 scipy 库
SciPy是python的一个著名的开源科学库,SciPy一般都是操纵NumPy数组来进行科学计算,统计分析,可以说是基于NumPy之上。
SciPy提供了许多科学计算的库函数,如线性代数,微分方程,信号处理,图像处理,系数矩阵计算等
2.5 使用 csv 库

 浙公网安备 33010602011771号
浙公网安备 33010602011771号