Informer原理详解
基于 client-go@v0.31.13
informer 介绍
informer 是 k8s 客户端库提供的一个组件,用于 资源变更监听+资源缓存,用于高效感知 k8s 集群中的资源变化。
实际上它就是构建用户控制器 Controller 的基础,Controller 一般是用来监听 k8s 中资源的状态更新然后我们去写业务逻辑代码对资源进行调谐,而所谓“监听”的功能就是 informer 实现的,即:
- Informer:负责监听和缓存资源变化
- Controller:负责消费这些变化,比如执行 Reconcile(调谐逻辑)
当然,informer 可以单独拿来用,不与 Controller 强绑定,监听资源不一定就是做资源的调谐,还可以去做一些比如 k8s 资源实时可视化的功能,我这里只是拿 informer+Controller 来举例子,因为它比较常见。
informer 架构
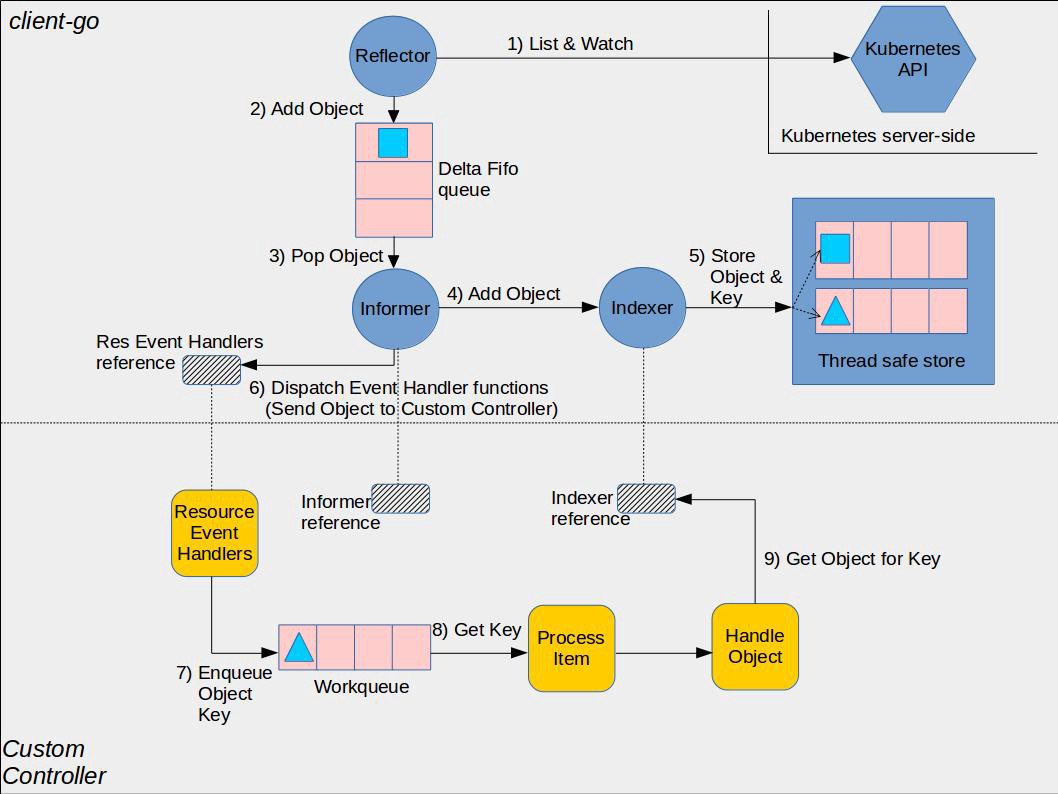
这张图清晰地表达了 informer+controller 所涉及到的组件以及它们的各自的组件边界,上半部分是 client-go 库内部实现 informer 的相关组件,下半部分是用户自定义 Controller。我们下面都会围绕这张架构图来展开讨论。
informer 核心组件包括:
- Reflector:负责监听 API Server 中的资源变化,将这些变化包装成事件发送到 DeltaFIFO
- DeltaFIFO:先进先出的队列,队列元素是资源对象一段时间内的历史变更事件
- Indexer:存放全量的资源对象,并提供索引用于快速访问对象
- Informer:消费 DeltaFIFO 中的事件,并分发给 ResourceEventHandler 进行处理
以及用户代码部分的组件:
- ResourceEventHandler:用户注册的事件处理器,由 informer 进行调用。该回调函数的实现一般是拿到对象的 key 然后放进 workqueue 让 worker 协程去处理
- WorkQueue:用于解耦事件的接收与处理,用来做一些比如限流、出队策略等定制化操作
- ProcessItem:用于处理事件的函数,一般会持有 Indexer 的引用,通过 key 快速查询事件对应的资源对象
示例代码
talk is cheap,理解任何东西的原理之前首先得会用这个东西,因此先看看 informer 怎么在代码中使用,直接参考 这篇文章,里面的示例代码涵盖了 informer 的前生今世,从原始 http 请求、到 clientset、到 informer 再到 sharedIndexInformer 一步步是怎么演进的。
Reflector
Reflector 负责监听 API Server 中的资源变化,具体来说,Reflector 首先通过 list 获取 apiserver 中的全量数据并通过 watch 持续监听增量变化。
Reflector 构造函数如下,创建一个 Reflector 必须指定一个 ListerWatcher 以及要监听的资源类型,由此可以看出,一个 reflector 只负责一种资源类型(比如只监听 pod 相关事件)
func NewReflectorWithOptions(lw ListerWatcher, expectedType interface{}, store Store, options ReflectorOptions) *Reflector
ListerWatcher 是将 Lister 和 Watcher 两个接口合并成同一个接口(类似 ReaderWriter 那样),提供 List 和 Watch 的能力,具体实现是 cache.ListWatch:
type ListWatch struct {
ListFunc ListFunc
WatchFunc WatchFunc
}
func (lw *ListWatch) List(options metav1.ListOptions) (runtime.Object, error) {
return lw.ListFunc(options)
}
func (lw *ListWatch) Watch(options metav1.ListOptions) (watch.Interface, error) {
return lw.WatchFunc(options)
}
cache.ListWatch 具体的实现交给了 ListFunc 和 WatchFunc,这两个函数由具体的资源类型来实现,下面看看 pod 的 ListFunc 和 WatchFunc:
// client就是ClientSet
func NewFilteredPodInformer(client kubernetes.Interface, /* ... */) cache.SharedIndexInformer {
return cache.NewSharedIndexInformer(
&cache.ListWatch{
// List
ListFunc: func(options metav1.ListOptions) (runtime.Object, error) {
return client.CoreV1().Pods(namespace).List(context.TODO(), options)
},
// Watch
WatchFunc: func(options metav1.ListOptions) (watch.Interface, error) {
return client.CoreV1().Pods(namespace).Watch(context.TODO(), options)
},
},
// ...
)
}
由此可以发现,Reflector 的本质是对 client 提供的 List 和 Watch 的进一步封装:
Reflector 会开一个协程不断地去监听资源保持缓存与 apiserver 同步。为了兼容不同 apiserver 版本,可能会细分为两种不同的同步方式。
第一种是传统的 ListWatch,通过分块/分页一次性 list 完成后关闭连接,再开新的 watch 长连接监听后续资源:
List(获取快照) → Watch(监听变化)
第二种是使用同一个 watch 连接,先发全量数据,继续使用同一条连接获取增量数据,即全程都使用流式传输的方式进行同步:
Watch(带 SendInitialEvents) → 收到所有 Added → Bookmark → 继续 Watch
相比第一种方式,流式 list 的好处在于这样可以降低 apiserver 的压力,详情可见 proposal。下面是开始 ListWatch 的实现代码:
// ListWatch方法会获取全量资源对象以及持续监听后续变更
func (r *Reflector) ListAndWatch(stopCh <-chan struct{}) error {
klog.V(3).Infof("Listing and watching %v from %s", r.typeDescription, r.name)
var err error
var w watch.Interface
useWatchList := ptr.Deref(r.UseWatchList, false)
fallbackToList := !useWatchList
// stream方式list
if useWatchList {
w, err = r.watchList(stopCh)
if err != nil {
klog.Warningf("The watchlist request ended with an error, falling back to the standard LIST/WATCH semantics because making progress is better than deadlocking, err = %v", err)
fallbackToList = true
w = nil
}
}
// chunking方式list(fallback行为)
if fallbackToList {
err = r.list(stopCh)
if err != nil {
return err
}
}
// watch
return r.watchWithResync(w, stopCh)
}
下面把两种方式都介绍下,做个对比(代码省略了一些 err 处理)
流式 list
func (r *Reflector) watchList(stopCh <-chan struct{}) (watch.Interface, error) {
// ...
for {
// ...
// 最后一次观察到的最大RV,该RV作为List和Watch的分界点,即小于该RV的对象属于全量数据,后续的对象都属于增量数据。初始时还没有观察到任何数据,因此RV="",表示使用当前集群最大RV
lastKnownRV := r.rewatchResourceVersion()
// 临时存储接收到的全量
temporaryStore = NewStore(DeletionHandlingMetaNamespaceKeyFunc)
options := metav1.ListOptions{
ResourceVersion: lastKnownRV,
AllowWatchBookmarks: true,
// 为了以watch的方式进行list,使用该参数指定watch在发送增量数据之前还要发送当前的全量数据,并且这些全量数据以Added事件表示
SendInitialEvents: pointer.Bool(true),
ResourceVersionMatch: metav1.ResourceVersionMatchNotOlderThan,
TimeoutSeconds: &timeoutSeconds,
}
// 开始流式list
w, err = r.listerWatcher.Watch(options)
// ...
// 处理接收的到的数据,并存入temporaryStore中
watchListBookmarkReceived, err := handleListWatch(start, w, temporaryStore, r.expectedType, r.expectedGVK, r.name, r.typeDescription,
func(rv string) { resourceVersion = rv },
r.clock, make(chan error), stopCh)
// ...
// 收到了Bookmark事件,意味着list已完成,否则进行下一次循环重试
if watchListBookmarkReceived {
break
}
}
// 使用Replace整体更新现有的缓存数据
if err := r.store.Replace(temporaryStore.List(), resourceVersion); err != nil {
return nil, fmt.Errorf("unable to sync watch-list result: %w", err)
}
// 更新观察到的最大的RV
r.setLastSyncResourceVersion(resourceVersion)
// 返回w,后续将使用同一个w进行watch
return w, nil
}
流式 list 的处理核心点在于对 bookmark 的处理,bookmark 是 list 与 watch 之间的分割点。
分块 list
不同于 watch 的持续监听事件流,list 的行为是发一次请求,就返回一次数据
func (r *Reflector) list(stopCh <-chan struct{}) error {
// ...
go func() {
// 使用 pager 进行分页读取数据
pager := pager.New(pager.SimplePageFunc(func(opts metav1.ListOptions) (runtime.Object, error) {
return r.listerWatcher.List(opts)
}))
// 决定是否分页、分页的大小
switch {
case r.WatchListPageSize != 0:
pager.PageSize = r.WatchListPageSize
case r.paginatedResult:
case options.ResourceVersion != "" && options.ResourceVersion != "0":
pager.PageSize = 0
}
// 开始分块 list
list, paginatedResult, err = pager.ListWithAlloc(context.Background(), options)
// ...
close(listCh)
}()
select {
// ...
case <-listCh:
}
// list 已结束
// 此后的 list 调用一直启用分页(详解见下面第 3 点)
if options.ResourceVersion == "0" && paginatedResult {
r.paginatedResult = true
}
//...
// 使用 Replace 整体更新现有的缓存数据
if err := r.syncWith(items, resourceVersion); err != nil {
return fmt.Errorf("unable to sync list result: %v", err)
}
// ...
}
关于分页这块可以注意一下:
- 目前没有开放的 API 让用户设置分页大小,因此分页大小使用默认的大小 500(每次最多返回 500 个对象)
- 不一定会进行分页,即可能会一次性返回所有对象。原因与 设置的参数/API 协议 有关,不过多深究,想了解的话可以看 3
- (TL; DR)首次 list 时将会使用 RV = "0",在数据一致性方面,这意味这返回的数据是非强一致性的,可能是旧一点的数据,但读取效率比较高;在数据源方面,将会优先从 apiserver 的 watch cache 中读取,watch cache 会忽略分页,一次性返回所有数据,但如果 watch cache 没有启用,将会从 etcd 的 follower 或者 leader 读取。首次 list 结束之后,如果发现请求的 RV = "0" 并且数据是以分页的方式返回的,说明 watch cache 没有启用,并且返回的对象比较多,已经超过了一页,那么将 r.paginatedResult 设置为 true,以后的每次 list 都会使用分页的方式去拉数据。当 RV 等于某个精确值时,将始终从 watch cache 中拉数据,此时禁止分页。当 RV = "" 时,将从 etcd 拉数据,此时需要使用分页。
分块 list 的处理核心点在于是否分页以及分页大小。
watch
watchList 或 list 完了之后,就开始持续不断地 watch 了。在 watch 的同时,还会周期性地执行 resync。resync 用于将不在 DeltaFIFO 中的本地缓存对象,以 Sync 事件放到 DeltaFIFO 中通知上层去处理一下它们。至于为什么要 resync,可以参考 这个问答,以及 这篇博客。
// watchWithResync runs watch with startResync in the background.
func (r *Reflector) watchWithResync(w watch.Interface, stopCh <-chan struct{}) error {
resyncerrc := make(chan error, 1)
cancelCh := make(chan struct{})
defer close(cancelCh)
// 定时resync
go r.startResync(stopCh, cancelCh, resyncerrc)
// watch
return r.watch(w, stopCh, resyncerrc)
}
resync 不是我们的重点,来看下 watch:
// watch simply starts a watch request with the server.
func (r *Reflector) watch(w watch.Interface, stopCh <-chan struct{}, resyncerrc chan error) error {
// ...
for {
// ...
// w==nil说明之前可能用的是分块list,主动发起Watch即可
if w == nil {
timeoutSeconds := int64(r.minWatchTimeout.Seconds() * (rand.Float64() + 1.0))
options := metav1.ListOptions{
ResourceVersion: r.LastSyncResourceVersion(),
TimeoutSeconds: &timeoutSeconds,
AllowWatchBookmarks: true,
}
w, err = r.listerWatcher.Watch(options)
// ...
}
// 持续watch,处理接收到的事件并直接存入store中
err = handleWatch(start, w, r.store, r.expectedType, r.expectedGVK, r.name, r.typeDescription, r.setLastSyncResourceVersion,
r.clock, resyncerrc, stopCh)
// ...
// 错误处理
// 可能会进行下一轮循环重新建立Watch,或者退出
}
}
DeltaFIFO
DeltaFIFO 顾名思义是一个先进先出队列,队列元素是 Deltas,一个 Deltas 包含多个 Delta,Delta 是对象事件:
type Deltas []Delta
type Delta struct {
Type DeltaType // 在对象上发生的事件,比如新增、删除等
Object interface{} // 对象
}
因此每次从队列 pop 元素时,是 pop 对象的在这段时间内发生的所有事件,用张图举个例子:
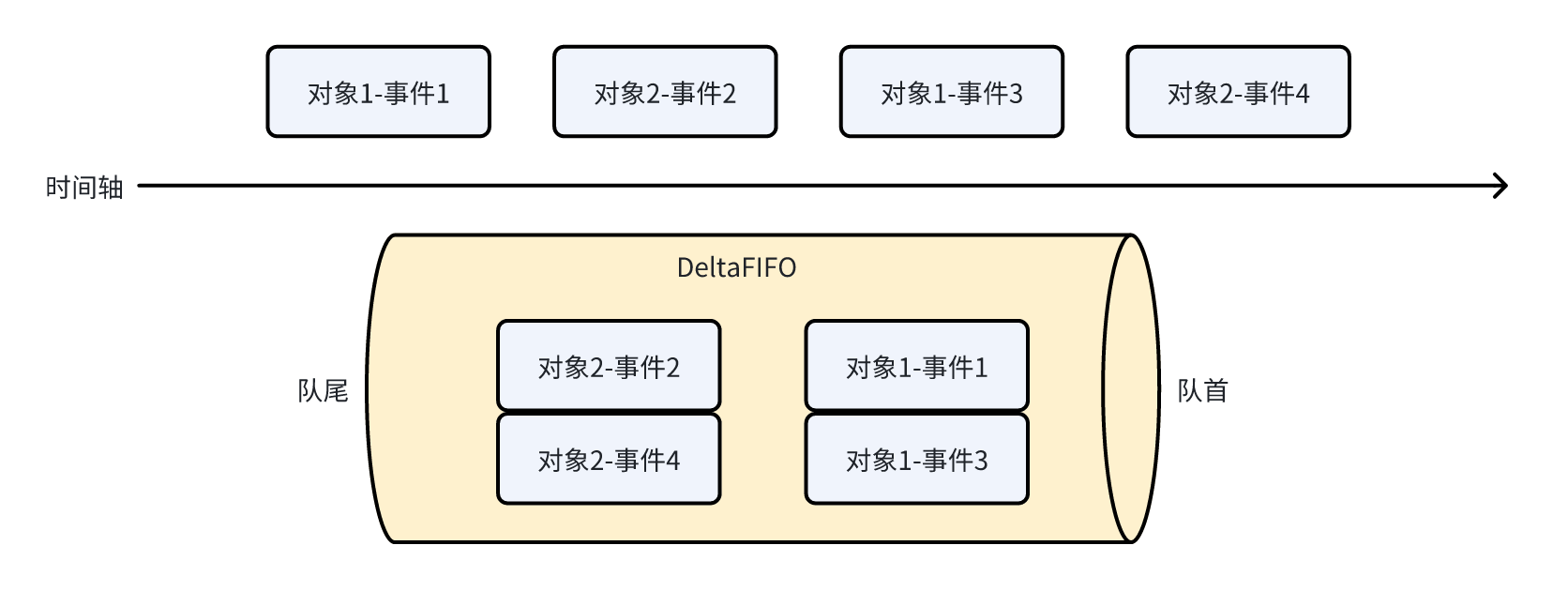
按照时间序,在两个对象上发生了四个事件,最终 pop 的时候是以对象为粒度进行 pop,即先将对象 1 的两个事件作为整体 pop,再到对象 2。
DeltaFIFO 的代码部分就没必要细看了,知道它在 Pop 元素的时候会处理被 pop 的元素即可,Pop 简化一下大概如下:
func (f *DeltaFIFO) Pop(process PopProcessFunc) (interface{}, error) {
f.lock.Lock()
defer f.lock.Unlock()
for {
// 弹出队首元素(Deltas)
id := f.queue[0]
f.queue = f.queue[1:]
item, ok := f.items[id]
delete(f.items, id)
// 处理元素
err := process(item, isInInitialList)
// 将元素的所有权移交给外界
return item, err
}
}
Indexer
Indexer 顾名思义是用来做索引的,索引什么呢?索引对象的 key 的。比如要获取 namespace = "default" 的所有的 pod,用 Indexer 就能快速得到这些对象的 key 集合(比如 "pod1"、"pod2" 这样的字符串集合),然后用这些 key 访问 map 获取对象。索引过程有点像倒排索引,即搜索属性为给定值的所有资源,比如 namespace 就是 pod 的属性。因此,索引的结构大概是这样的:
{
// 属性名称
"namespace": {
// 属性值 对应的资源
"default": ["pod1", "pod2"],
"kube-system": ["pod3"],
},
"nodeName": {
"node-1": ["pod1", "pod3"],
"node-2": ["pod2"],
},
}
实际上 Indexer 的本质还是一个存储了所有对象的本地缓存,只不过在这之基础上提供了索引功能。
存储相关接口
上面说到的 Indexer 只是一个接口,可以看到 Indexer 是在 Store 接口基础上提供了索引的相关方法:
type Indexer interface {
Store
// Index returns the stored objects whose set of indexed values
// intersects the set of indexed values of the given object, for
// the named index
Index(indexName string, obj interface{}) ([]interface{}, error)
// IndexKeys returns the storage keys of the stored objects whose
// set of indexed values for the named index includes the given
// indexed value
IndexKeys(indexName, indexedValue string) ([]string, error)
// ListIndexFuncValues returns all the indexed values of the given index
ListIndexFuncValues(indexName string) []string
// ByIndex returns the stored objects whose set of indexed values
// for the named index includes the given indexed value
ByIndex(indexName, indexedValue string) ([]interface{}, error)
// GetIndexers return the indexers
GetIndexers() Indexers
// AddIndexers adds more indexers to this store. This supports adding indexes after the store already has items.
AddIndexers(newIndexers Indexers) error
}
Indexer 的实现类是 cache,cache 又依赖于 threadSafeMap 提供索引功能。另外,DeltaFIFO 所实现的 Queue 接口其实也是 Store。
说到这里我觉得可以捋一下这些本地存储相关的各个接口的关系,因为看起来还挺乱的,类图如下: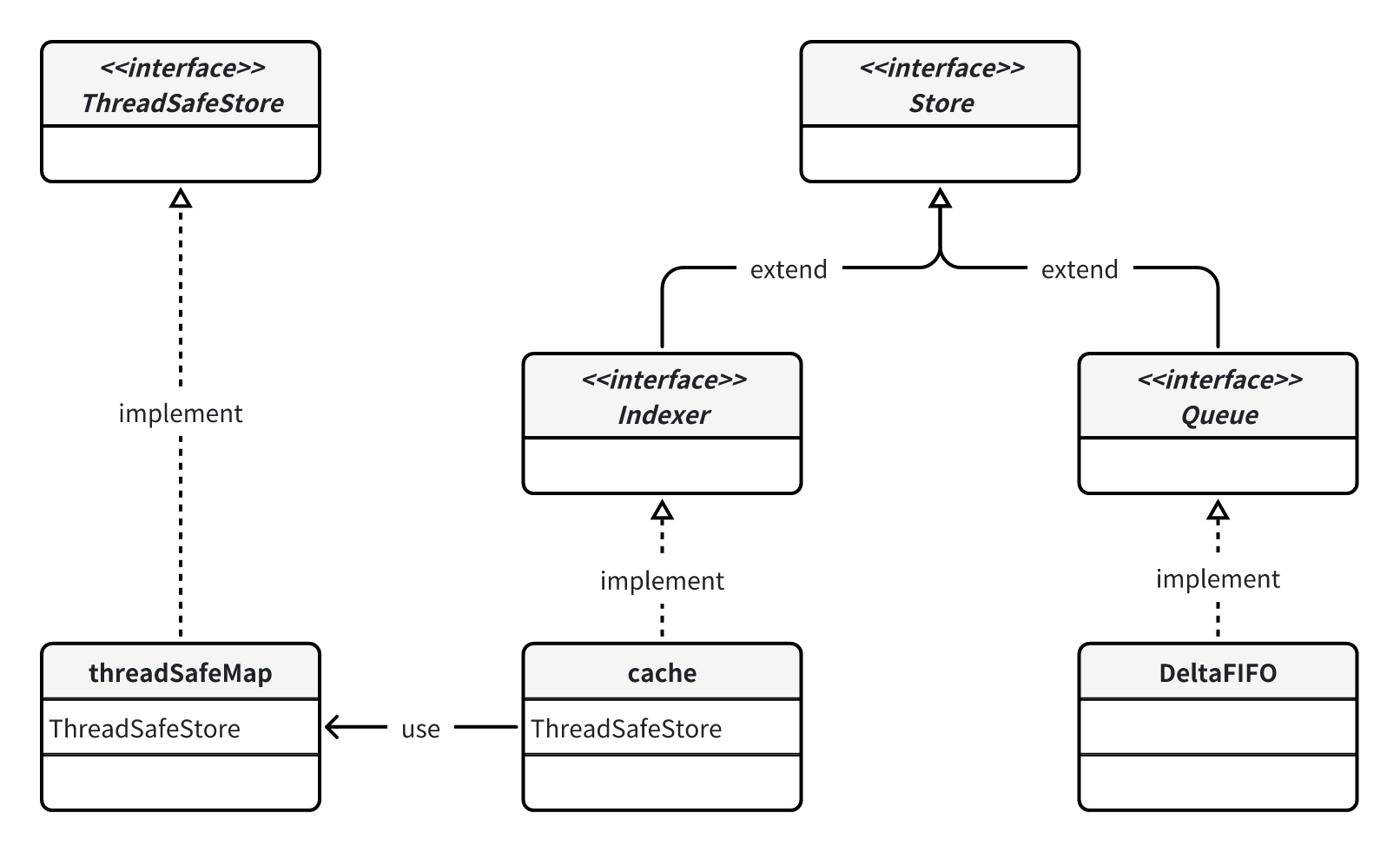
Store 提供了最基础的 key-value 存储能力,但是要注意这里 key 是通过 value 计算出来的,所以可以看到 Store 的许多方法都只传 value 不需要传 key,比如插入一个对象时,key 是通过 keyFunc(obj)计算得到的:
Add(obj interface{}) error
需要注意的是,key 对应的 value 实际上叫 accumulator。accumulator 可以被实现为简单的一个 obj,即简单 kv 存储,比如图中的 cache;accumulator 也可以被实现为对象的集合,比如 DeltaFIFO 的实现中,accumulator 就是一个 Deltas。
Indexer 和 Queue 则是在这个 Store 的基础上扩展了其它能力:Indexer 提供了对 key 进行索引查找的能力,Queue 提供了对象先进先出的能力。
最后再来看看结构体,我们关注的是 cache 和 DeltaFIFO。cache 缓存了所有的对象,缓存的是 apiserver 中的对象,并且 cache 实现了 Indexer 提供索引查找的能力。cache 的实现很简单,因为具体的存储与索引实现放在了 threadSafeMap 中。DeltaFIFO 虽然是 Store,但目的不是存下所有对象,只是复用 Store 提供的方法,比如 Add 方法实际上类似 Push 的能力。
Controller(Informer)
我们在代码中使用 cache.NewInformer 或者 cache.NewIndexInformer 时,会发现返回的是一个 Controller 接口:
type Controller interface {
// Run does two things. One is to construct and run a Reflector
// to pump objects/notifications from the Config's ListerWatcher
// to the Config's Queue and possibly invoke the occasional Resync
// on that Queue. The other is to repeatedly Pop from the Queue
// and process with the Config's ProcessFunc. Both of these
// continue until `stopCh` is closed.
Run(stopCh <-chan struct{})
// HasSynced delegates to the Config's Queue
HasSynced() bool
// LastSyncResourceVersion delegates to the Reflector when there
// is one, otherwise returns the empty string
LastSyncResourceVersion() string
}
实际返回对象是 controller 对象:
// `*controller` implements Controller
type controller struct {
config Config
reflector *Reflector
reflectorMutex sync.RWMutex
clock clock.Clock
}
但是这里的 Controller 并不是指用户层面的那个控制器,对照上方的架构图来说,这里的 Controller 对应于架构图中的 Informer 组件,属于图中上方 client-go 的那层。因此,我觉得代码里的 Controller 应该命名为 Informer 才对,同样地 controller 应该命名为 informer。
controller 的运行逻辑很简单,就是启动 reflector 然后运行 processLoop 不断地消费 DeltaFIFO 中的资源事件。
func (c *controller) Run(stopCh <-chan struct{}) {
// 创建reflector
r := NewReflectorWithOptions(/*...*/)
r.WatchListPageSize = c.config.WatchListPageSize
// ...
// 启动reflector
wg.StartWithChannel(stopCh, r.Run)
// 启动processLoop
wait.Until(c.processLoop, time.Second, stopCh)
wg.Wait()
}
func (c *controller) processLoop() {
for {
// 不断从DeltaFIFO中pop事件并处理
obj, err := c.config.Queue.Pop(PopProcessFunc(c.config.Process))
// ...
}
}
处理事件的函数是 c.config.Process:
func newInformer(clientState Store, options InformerOptions) Controller {
// ...
cfg := &Config{
// ...
Process: func(obj interface{}, isInInitialList bool) error {
if deltas, ok := obj.(Deltas); ok {
// 直接交给processDeltas处理
return processDeltas(options.Handler, clientState, deltas, isInInitialList)
}
return errors.New("object given as Process argument is not Deltas")
},
}
return New(cfg)
}
具体由 processDeltas 去处理:
func processDeltas(
handler ResourceEventHandler,
clientState Store,
deltas Deltas,
isInInitialList bool,
) error {
// from oldest to newest
for _, d := range deltas {
obj := d.Object
switch d.Type {
case Sync, Replaced, Added, Updated:
if old, exists, err := clientState.Get(obj); err == nil && exists {
// update
// 更新Indexer
if err := clientState.Update(obj); err != nil {
return err
}
// 回调ResourceEventHandler
handler.OnUpdate(old, obj)
} else {
// add
// ...
}
case Deleted:
// delete
// ...
}
}
return nil
}
结合之前给出的示例代码,当我们去用 cache.NewXXXInformer 创建一个 informer 时,它处理事件的逻辑就是简单的两个步骤:
- 更新 Indexer
- 回调用户注册的 ResourceEventHandler
SharedIndexInformer
当我们一个程序里有多个地方需求监听同一种资源,如果每次都是 cache.NewXXXInformer 去创建新的 Informer 的话,这个动作的背后实际上在创建多个 Reflector,即创建了多条与 apiserver 的连接,但监听的实际上是同一样东西,并且每个 Informer 中都缓存了一样的东西。如此一来既增加了 apiserver 的压力,又浪费了本地的内存。
因此 client-go 在 Informer(即 Controller 接口)的基础上进一步封装,提供了 SharedInformer 接口,使得对同一种资源只需一次 ListWatch、一个缓存,就能在程序任意地方去消费事件,从每个消费者的视角来看就好像自己独占一个 Informer 一样,也就是实现了所谓的 fan-out,一次发送,多处消费。
其实要实现这个很简单,用伪代码表示大概是这样的:
// 从DeltaFIFO获取事件
item := DeltaFIFO.pop()
// 通知所有ResourceEventHandler
for _, handler := range handlers {
handler.handle(item)
}
在真正的代码实现上,sharedIndexInformer 运用了设计模式中非常经典的 代理模式:在不改动 controller 代码的前提下,sharedIndexInformer 自身实现了 ResourceEventHandler 接口,将自己提供给 controller,如此一来,之前 controller 处理事件第 2 步中的“回调用户注册的 ResourceEventHandler”就变成了“回调 sharedIndexInformer”。同时,sharedIndexInformer 对外提供 AddEventHandler(handler ResourceEventHandler) 方法,在内部维护这些用户添加进来的 ResourceEventHandler,将收到的事件逐一分发给这些 ResourceHandler。
代码就没必要细看了,明白这个道理就行。
另外,SharedInformer 其实就是 SharedIndexInformer,因为索引功能几乎是一定会用得上的,所以 client-go 官方并不提供有 "shared" 但没有 "index" 的实现类。
WorkQueue
光看架构图的话,我一直不理解为什么要有 WorkQueue 这个东西,监听到事件之后直接去 processItem 不就可以了吗?但我们要知道,在 k8s 的设计理念中,控制器不是简单的事件回调,而是一个状态收敛循环,控制器会去访问 apiserver 对资源状态进行调谐,那么处理事件流时,自然就需要对事件进行去重、限流等操作,这就是 WorkQueue 所能提供的能力。
以示例代码使用到的 workqueue 为例:
workqueue.NewRateLimitingQueue(workqueue.DefaultControllerRateLimiter())
首先从名字可以看出,创建了一个具有限流功能的 workqueue,并且传入了默认的限流器。这里默认限流器其实是两个限流器的组合,限流的力度取他俩中的最大值,即只要任意一个限流器觉得该 key 应该被延迟,就延迟:
- 指数退避限流器:对于单个元素,每重复 Add 一次,下次 Get 的时长就是上次 Get 的两倍
- 令牌桶限流器:对于所有元素,采用令牌桶限流(关于令牌桶限流算法自己 chatgpt 一下)
其中,指数退避限流器的意义是控制单个 key 的重试频率,因为某个 key 重试次数越多,说明失败率有点高,让它等久一点再同时。而令牌桶限流器的意义在于避免全局事件的突发流量,比如某时刻突然有很多不同的资源事件到来,肯定也得限流一下。因此他们的侧重点不同,组合起来能更有效地去做好限流。
以上我们介绍了 WorkQueue 限流的作用,还有解耦、缓冲、去重等,其实只是这些 workqueue 顺手的事。
workqueue 看起来接口好像挺多挺乱的,可以像上面的存储相关接口一样,自己画个类图,就很容易理清了,在日后使用起来也更加得心应手。
总结
用 operator 那一套来举例:平时基于 opeartor 那一套去进行开发用户控制器进行集群资源调谐的时候,一般用 kubebuilder 去生成一些资源对象的深拷贝代码、Reconciler 的脚手架代码等,虽然这些代码看起来并没涉及 informer、indexer 那些东西,但运行起来,当集群资源对象发生变更时,确实会及时回调我们的 Reconcile 调谐方法。在了解了 informer 这套机制后,不用想就知道是 informer 在底层起作用。
实际上,kubebuilder 生成的代码里是用了 controller-runtime 这个库,它是对 client-go 进一步封装。这个库将 informer、workqueue、processitem 等封装起来,对外提供各种丰富的功能,让开发者更方便地去开发用户控制器。比如开发者只需要按照 controller-runtime 的规范,定义一个 Reconciler 并注册进去,把项目运行起来就能轻松对资源进行调谐了,十分省事。
参考
https://isekiro.com/categories/client-go/
https://github.com/kubernetes/sample-controller/blob/master/docs/controller-client-go.md
https://herbguo.gitbook.io/client-go/informer
https://github.com/cloudnativeto/sig-kubernetes/issues/11
https://gobomb.github.io/post/whats-resync-in-informer/
https://kubernetes.io/zh-cn/docs/reference/using-api/api-concepts/#resource-versions
https://www.zhaohuabing.com/post/2023-03-09-how-to-create-a-k8s-controller/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号