
出自文献:Martin-Brualla R, Radwan N, Sajjadi M S M, et al. Nerf in the wild: Neural radiance fields for unconstrained photo collections[J]. arXiv preprint arXiv:2008.02268, 2020.
摘要
- 我们提出一种学习方法,用于合成复杂场景的新视图,并且使用的是非结构化的 in-the-wild 照片集。
- 我们的工作基于神经辐射场(Neural Radiance Fields, NeRF),它使用多层感知器的权重,来建模场景的密度(density)和颜色(color),其输入是 3D 坐标。
- 尽管 NeRF 可以在控制(controlled)环境中的静态物体图像中工作,但是它并不能建模非控制(uncontrolled)图像,即大量普遍存在的、真实世界中的情形。例如不同的光照或突然出现的障碍物。
- 我们对 NeRF 进行了一系列的推广,来解决该问题,由此根据网络上的非结构化图像集,进行精确的重构。
- 我们把系统(称为 NeRF-W)应用在著名地标的网络图片集中,得到时间上一致的新视图渲染,与最新技术相比,它的真实感更强。
1 介绍

图 1 给定网络照片集(a),本方法可以渲染出不同光照的新视图(b)。
- 根据一组拍摄的稀疏图像集合,合成场景的新视图,在 CV 中是长期存在的问题,并且是很多 AR/VR 应用的前提条件。尽管很多经典的技术,使用运动恢复结构(structure-from-motion, SFM)或基于图像的渲染(image-based rendering)来解决该问题,但是该领域最近因为神经渲染(neural rendering)技术有了很大进展:将可学习的模块嵌入到 3D 几何上下文中,在用重构出的观察图像进行训练。
- NeRF 用神经网络权重建模了场景的辐射场和密度。立体渲染(Volume rendering)接着用于合成新视图,在一系列具有挑战性的场景中,都展现出非常高的保真度。
- 但是,NeRF 只适用于控制好的环境:这些场景都是在一小段时间内进行拍摄,光照影响都保持不变,并且所有场景的内容都保持不变。
- 我们后面会展示,当面对移动的物体或者光照变化情况下的场景,NeRF 的性能会明显下降。
- 这种限制阻碍了 NeRF 应用于大量 in-the-wild 的场景,这些输入图像可能在不同小时段、或不同年度进行拍摄,而且有很多行人和车辆穿过。
- 我们这里解决 NeRF 的关键限制是,NeRF 假设场景是在几何、材质和摄影角度上,都是静态的,即场景的密度和辐射场都是静态的。因此,NeRF 需要让两个在相同位置和朝向上,拍摄出的照片必须完全一致。
- 这种假设在很多真实数据集上并不成立,例如大量网络上的地标建筑的数据集。
- 我们会展示,把 NeRF 应用在这种数据集中,会出现不精确的重构:会出现鬼影、过度的平滑和其他 artifact。
- 为了处理这种场景,我们提出 NeRF-W,放宽了严格一致性的假设,对 NeRF 进行了推广。
- 首先,我们在学习到的低维隐空间中,建模图像外观的变化,如曝光、光照、天气和后处理。
- 按照生成隐优化(Generative Latent Optimization, GLO)的框架,我们优化出每个输入图像的外观嵌入(apperance embedding),因此学习到整个照片数据集中的共享外观表示,让 NeRF-W 在表示摄影和环境变化时有很大的灵活性。
- 如图 1(b)所示,学习到的隐空间,能够控制输出渲染的外观。
- 第二,我们把场景建模为共享(shared)元素和图像相关(image-dependent)元素的并集,可以把场景内容无监督地分解为静态和瞬态组件。
- 本方法使用结合了数据相关的不确定场(data-dependent uncertainty field)的次级体积辐射场(secondary volumtric radiance field),对瞬态元素进行建模。不确定场可以捕捉到观察噪音的变化,可以进一步减少瞬态对象对于静态场景的影响。
- 由于优化时能够识别和消除瞬态图像内容,因此我们只渲染出静态组件,进而合逼真的新视图。
- 总结,我们的渲染效果很好。
2 相关工作
3 背景

图 2:Phototourism 数据集中 in-the-wild 相片的示例,该数据集用于训练 NeRF-W。由于光照的变化和后处理(顶部图),相同物体的颜色在不同照片都有变化。照片同时还会包含瞬态的遮挡物(底部图)。
本文的目标是构建一个系统,其输出是照片集,然后学习出 3D 表示,它能够生成数据集里面的照片。
该场景表示应该可以对场景的 3D 结构和外观信息进行编码,进而可以合成新的视图。接下来我们描述 NeRF,即 NeRF-W 所推广的 3D 场景重建。
NeRF 把场景表示为一个可学习的连续的体积辐射场 $F_{\theta}$,其定义域是一个有边界的 3D 体积。$F_{\theta}$ 通过 MLP 来表示,它的输入是 3D 位置 $\mathbf{x}=(x, y, z)$ 和单位长度的视角方向 $\mathbf{d}=\left(d_{x}, d_{y}, d_{z}\right)$,它的输出是密度 $\sigma$ 和颜色 $\mathbf{c}=(r, g, b)$。要计算每个像素的颜色,NeRF 使用数值积分来近似立体渲染积分。令 $\mathbf{r}(t)=\mathbf{o}+t \mathbf{d}$ 是相机射线,它从相机 $\mathbf{O}$ 的投影中心出发,穿过像平面的给定像素。NeRF 对该像素的期望颜色 $\hat{\mathbf{C}}(\mathbf{r})$ 的逼近公式是:
\begin{equation}
\hat{\mathbf{C}}(\mathbf{r})=\mathcal{R}(\mathbf{r}, \mathbf{c}, \sigma)=\sum_{k=1}^{K} T\left(t_{k}\right) \alpha\left(\sigma\left(t_{k}\right) \delta_{k}\right) \mathbf{c}\left(t_{k}\right)
\end{equation}
其中:
\begin{equation}
T\left(t_{k}\right)=\exp \left(-\sum_{k^{\prime}=1}^{k-1} \sigma\left(t_{k^{\prime}}\right) \delta_{k^{\prime}}\right)
\end{equation}
其中,$\mathcal{R}(\mathbf{r}, \mathbf{c}, \sigma)$ 表示立体渲染。$\mathbf{c}(t)$ 和 $\sigma(t)$ 是位置点 $\mathbf{r}(t)$ 的颜色和密度。
$\alpha(x)=1-\exp (-x)$
$\delta_{k}=t_{k+1}-t_{k}$ 表示两个积分点的距离。并且使用了分层抽样来选择 $t_{n}$ 和 $t_{f}$ 之间的积分点,即相机射线穿过的最近和最远平面。
NeRF 使用 ReLU MLP 来表示体积密度 $\sigma(t)$ 和颜色 $\mathbf{c}(t)$。
\begin{equation}
[\sigma(t), \mathbf{z}(t)]=\mathrm{MLP}_{\theta_{1}}\left(\gamma_{\mathbf{x}}(\mathbf{r}(t))\right)
\end{equation}
\begin{equation}
\mathbf{c}(t)=\mathrm{MLP}_{\theta_{2}}\left(\mathbf{z}(t), \gamma_{\mathbf{d}}(\mathbf{d})\right)
\end{equation}
其中网络参数是 $\theta=\left[\theta_{1}, \theta_{2}\right]$,固定编码函数有 $\gamma_{\mathbf{x}}$ 和 $\gamma_{\mathbf{d}}$。生成 $\sigma(t)$ 和 $\mathbf{c}(t)$ 的激活函数分别是 ReLU 和 sigmoid。因为密度必须是非负数,而颜色必须介于 $[0,1]$。与 NeRF 不同,我们把神经网络描述为两个 MLP,其中最后一个 MLP 依赖于上一个的输出 $\mathbf{z}(t)$,这强调了体积密度 $\sigma(t)$ 和视角方向 d 无关。
为了训练参数 $\theta$,对于 RGB 图像集合,NeRF 最小化了相对于 $\left\{\mathcal{I}_{i}\right\}_{i=1}^{N}, \mathcal{I}_{i} \in[0,1]^{H \times W \times 3}$ 的重构误差的平方和。每张图像 $\mathcal{I}_{i}$ 都有用 SFM 估计出的内外参。我们重新计算相对于图像 $i$ 的像素 $j$ 上的相机光线 $\left\{\mathbf{r}_{i j}\right\}_{j=1}^{H \times W \times 3}$,每个相机射线都穿过 3D 位置 $\mathbf{O}_{i}$,方向是 $\mathbf{d}_{i j}$,即 $\mathbf{r}_{i j}(t)=\mathbf{o}_{i}+t \mathbf{d}_{i j}$。
为了提升采样效率,NeRF 同时优化两个 MLP:一个粗糙网络,一个精细网络,其中粗糙模型预测的密度,会用来决定精细模型的采样积分点。两个模型的参数都会用以下损失进行优化:
\begin{equation}
\sum_{i j}\left\|\mathbf{C}\left(\mathbf{r}_{i j}\right)-\hat{\mathbf{C}}^{c}\left(\mathbf{r}_{i j}\right)\right\|_{2}^{2}+\left\|\mathbf{C}\left(\mathbf{r}_{i j}\right)-\hat{\mathbf{C}}^{f}\left(\mathbf{r}_{i j}\right)\right\|_{2}^{2}
\end{equation}
其中 $\mathbf{C}\left(\mathbf{r}_{i j}\right)$ 是图像 $\mathcal{I}_{i}$ 上射线 $j$ 的观测颜色,而 $\hat{\mathbf{C}}^{c}$ 和 $\hat{\mathbf{C}}^{f}$ 分别是粗糙和精细模型。
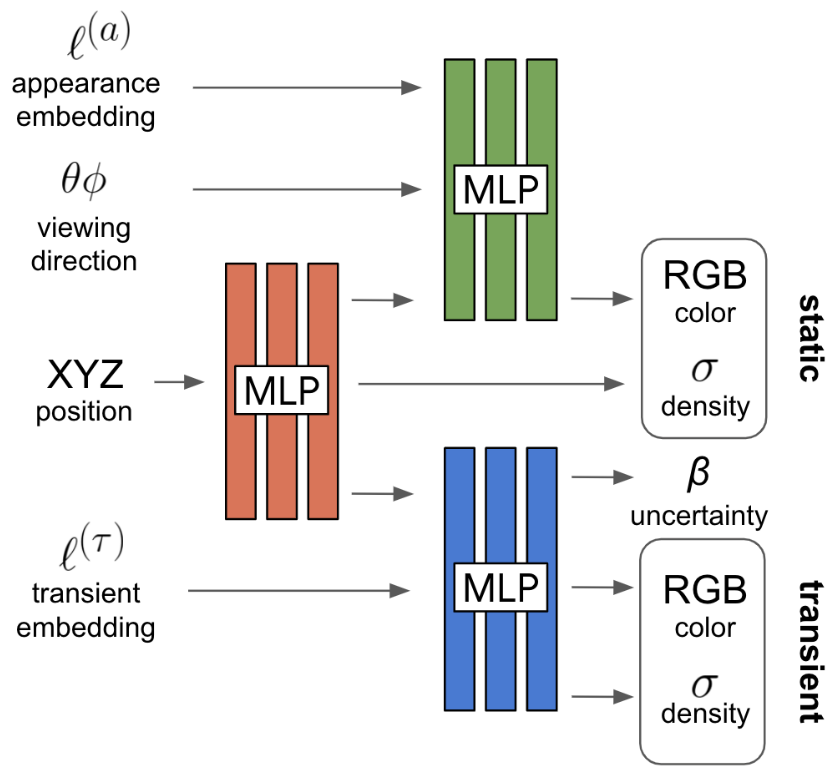
图 3:NeRF-W 模型架构。给出 3D 位置、视角方向、学习到的外观和瞬态 embedding,NeRF-W 得到静态和瞬态(带有不确定度)的颜色和密度。需要指出,静态占有率(static opacity)在模型看到外观 embedding 之前就会提前生成,保证不同图像有相同的静态几何。
4 NeRF in the Wild
我们现在提出 NeRF-W,该系统会从 in-the-wild 相片集中重构出 3D 场景。我们基于 NeRF,并明确引入了两项提升方法,用于处理非控制成像带来的挑战。
类似于 NeRF,我们会从非结构化的相片集 $\left\{\mathcal{I}_{i}\right\}_{i=1}^{N}$ 中(内外参已知),学习体积密度表示 $F_{\theta}$。在 NeRF 中,假设输入视角的连续性:给定相同的位置和视角方向,两张图像有相同的亮度(intensity)。但是这样的假设在网络照片中并不符合,主要有两个现象:
(1)光度学的变化(photometric variation):在户外摄影中,当日时间和大气状况都会直接影响场景中物体的照明(即发射的幅度亮度)。由于摄影成像流水线,这一问题还会继续放大,因为还有自动曝光的设置、白平衡、色阶重建等,最终导致摄影的不连续性。
(2)瞬态物体(transient objects):真实世界的地标很少独立地拍摄,经常会有行人等障碍物遮挡。地标的游客照片更具挑战性。
我们提出两个模型组件来解决上述问题。在 4.1 节中,我们推广了 NeRF,使得相片相关的外观和光照变化,可以显式地建模。在 4.2 节,我们进一步拓展 NeRF,瞬态物体可以进行估计,并且与 3D 世界中的静态表示相互解耦。图 3 展示了模型的总体架构。

图 4:NeRF-W 渲染场景的静态(a)和瞬态(b)部分,以及两者的组合(c)。训练过程最小化组合渲染和真实图像(d)的差异,由不确定场(e)进行加权,这可以同时优化进行识别和忽视异常的图像区域。
4.1 隐外观的建模
为了使 NeRF 能够适应不同光照和摄影后处理,我们采用了 GLO 技术,即每张图像 $\mathcal{I}_{i}$ 都会赋给一个对应的实值外观嵌入(appearance embedding)向量 $\boldsymbol{\ell}_{i}^{(a)}$,其长度为 $n^{(a)}$。我们用图像相关的辐射亮度 $\mathbf{c}_{i}(t)$,来替换方程(1)中的图像无关的辐射亮度 $\mathbf{c}(t)$,同时引入近似的像素颜色 $\hat{\mathbf{C}}_{i}$ 对图像索引 $i$ 的依赖:
\begin{equation}
\hat{\mathbf{C}}_{i}(\mathbf{r})=\mathcal{R}\left(\mathbf{r}, \mathbf{c}_{i}, \sigma\right)
\end{equation}
\begin{equation}
\mathbf{c}_{i}(t)=\operatorname{MLP}_{\theta_{2}}\left(\mathbf{z}(t), \gamma_{\mathbf{d}}(\mathbf{d}), \ell_{i}^{(a)}\right)
\end{equation}
其中,嵌入 $\left\{\ell_{i}^{(a)}\right\}_{i=1}^{N}$ 和 $\theta$ 一同优化。
让这种外观嵌入,作为网络其中分支的输入,可以赋予模型改变特定图像中场景辐射场的能力,同时依然保证 3D 几何学是静态的,由所有图像共享。把 $n^{(a)}$ 设置为一个较小值,我们鼓励优化时能够找到一个连续空间,使得光照条件可以嵌入,进而可以保证不同条件下的光滑插值,正如图 8 所示。
4.2 动态物体
我们使用两种设计来解决动态现象。
首先,我们把 NeRF 中的颜色发射(color-emitting)MLP(方程 4),作为我们模型的静态部分(static head),然后我们添加瞬态部分(transient head),发出自己的颜色和密度,其中密度允许在训练图像中有变化。这使得 NeRF-W 可以重构包含遮挡物的图像,而没有把 artifact 引入到静态场景表示。
其次,我们并不假设所有观测像素颜色都是同样可靠的,我们允许我们的瞬态部分发射出不确定性( uncertatinty)场(类似于颜色和密度),可以让模型调整重构损失,忽略不可靠的像素和 3D 位置,这些位置很可能包含遮挡物。
我们将每个像素的颜色建模为各向同性正态分布,并且进行极大似然,然后我们使用立体渲染,渲染出该分布的方差。
这两个模型组件可以让 NeRF-W 解耦静态和瞬态现象,而无需显式监督。
为了构建瞬态部分,我们基于方程(6)的立体渲染公式,用瞬态部分的 $\sigma_{i}^{(\tau)}(t)$ 和 $\mathbf{c}_{i}^{(\tau)}(t)$ 来增强静态密度 $\sigma(t)$ 和辐射亮度 $\mathbf{c}_{i}(t)$。
\begin{equation}
\hat{\mathbf{C}}_{i}(\mathbf{r})=\sum_{k=1}^{K} T_{i}\left(t_{k}\right)\left(\alpha\left(\sigma\left(t_{k}\right) \delta_{k}\right) \mathbf{c}_{i}\left(t_{k}\right)+\alpha\left(\sigma_{i}^{(\tau)}\left(t_{k}\right) \delta_{k}\right) \mathbf{c}_{i}^{(\tau)}\left(t_{k}\right)\right)
\end{equation}
其中:
\begin{equation}
T_{i}\left(t_{k}\right)=\exp \left(-\sum_{k^{\prime}=1}^{k-1}\left(\sigma\left(t_{k^{\prime}}\right)+\sigma_{i}^{(\tau)}\left(t_{k^{\prime}}\right)\right) \delta_{k^{\prime}}\right)
\end{equation}
预计的颜色 $\mathbf{r}(t)$ 接着作为静态和瞬态分量的 alpha 组合。
我们利用 Kendall 的贝叶斯学习框架,来建模观测颜色的不确定性。我们假设观测的像素强度,包含内在的噪音,即偶然的(aleatoric),进而该噪声是依赖输入的,即异方差的(heteroscedastic)。我用一个依赖图像和射线的各向同性的正态分布(方差是 $\beta_{i}(\mathbf{r})^{2}$,均值是 $\hat{\mathbf{C}}_{i}(\mathbf{r})$)来建模观测颜色 $\mathbf{C}_{i}(\mathbf{r})$。方差 $\beta_{i}(\mathbf{r})$ 类比于渲染的颜色:
\begin{equation}
\hat{\beta}_{i}(\mathbf{r})=\mathcal{R}\left(\mathbf{r}, \beta_{i}, \sigma_{i}^{(\tau)}\right)
\end{equation}
为了让场景的瞬态分量在不同的图像上变化,我们给每个训练图像 $\mathcal{I}_{i}$ 指定第二个嵌入 $\ell_{i}^{(\tau)} \in \mathbb{R}^{n^{(\tau)}}$,作为瞬态 MLP 的输入:
\begin{equation}
\left[\sigma_{i}^{(\tau)}(t), \mathbf{c}_{i}^{(\tau)}(t), \tilde{\beta}_{i}(t)\right]=\operatorname{MLP}_{\theta_{3}}\left(\mathbf{z}(t), \boldsymbol{\ell}_{i}^{(\tau)}\right)
\end{equation}
\begin{equation}
\beta_{i}(t)=\beta_{\min }+\log \left(1+\exp \left(\tilde{\beta}_{i}(t)\right)\right)
\end{equation}
ReLU 和 sigmoid 激活函数用于 $\sigma_{i}^{(\tau)}(t)$ 和 $\mathbf{c}_{i}^{(\tau)}(t)$,而 softplus 用于激活 $\beta_{i}(t)$($\beta_{\min }>0$,一个超参数,保证每条射线的最小重要性)。图 3 表明了完整的模型架构。
图像 $i$ 上射线 $\mathbf{r}$ 对真值颜色 $\mathbf{C}_{i}(\mathbf{r})$ 的损失是:
\begin{equation}
L_{i}(\mathbf{r})=\frac{\left\|\mathbf{C}_{i}(\mathbf{r})-\hat{\mathbf{C}}_{i}(\mathbf{r})\right\|_{2}^{2}}{2 \beta_{i}(\mathbf{r})^{2}}+\frac{\log \beta_{i}(\mathbf{r})^{2}}{2}+\frac{\lambda_{u}}{K} \sum_{k=1}^{K} \sigma_{i}^{(\tau)}\left(t_{k}\right)
\end{equation}
前两项是 $\mathbf{C}_{i}(\mathbf{r})$ 相对于均值 $\hat{\mathbf{C}}_{i}(\mathbf{r})$ 和方差 $\beta_{i}(\mathbf{r})^{2}$ 的正态分布的(平移后的)负对数似然。$\beta_{i}(\mathbf{r})$ 值越大,赋值给像素的重要性就越小。第一项与第二项保持平衡,第二项对应于正态分布的对数分区函数(log-partition function),并排除了 $\beta_{i}(\mathbf{r})=\infty$ 的情况。第三项是 $L_{1}$ 正则项,有一个非负的乘法系数 $\lambda_{u}$ 乘在瞬态密度 $\sigma_{i}^{(\tau)}(t)$,这会鼓励模型使用瞬态密度来解释静态现象。
在测试期间,我们会扔掉瞬态和不确定场,只渲染 $\sigma(t)$ 和 $\mathbf{c}(t)$。图 4 演示了静态、瞬态和不确定性分量。
4.3 优化
类似于 NeRF,我们同时优化 $F_{\theta}$ 的两个拷贝:精细模型使用上述的模型和损失;粗糙模型只使用隐外观的建模分量。和参数 $\theta$ 一起,我们优化每张图像的外观嵌入 $\left\{\boldsymbol{\ell}_{i}^{(a)}\right\}_{i=1}^{N}$ 和瞬态嵌入 $\left\{\ell_{i}^{(\tau)}\right\}_{i=1}^{N}$。NeRF-W 的损失函数为:
\begin{equation}
\sum_{i j} L_{i}\left(\mathbf{r}_{i j}\right)+\frac{1}{2}\left\|\mathbf{C}\left(\mathbf{r}_{i j}\right)-\hat{\mathbf{C}}_{i}^{c}\left(\mathbf{r}_{i j}\right)\right\|_{2}^{2}
\end{equation}
$\lambda_{u}$、$\beta_{\min }$ 和嵌入维度 $n^{(a)}$ 和 $n^{(\tau)}$,都是 NeRF-W 的超参数。
优化时,只会在训练集中生成外观嵌入 $\left\{\ell_{i}^{(a)}\right\}$,在测试集中并没指定嵌入。为了测试集的可视化,我们选择最能拟合目标图像的 $\ell^{(a)}$(图 8),或者将其设置为任意值。
5 实验

图 8:训练图像中外观嵌入 $\ell^{(a)}$ 的插值(最左图和最右图),让中间的渲染可以插值出颜色和光照,但是几何体保持不变。
6 结论
- 我们提出了 NeRF-W,基于 NeRF,对非结构化网络照片集的复杂环境的 3D 场景重构。
- 我们学习每张图像的隐嵌入,能够捕捉到摄影外观的变化;
- 我们还把场景分解为图像相关的和共享的分量,使得模型可以解耦瞬态元素和静态场景。
- 实验证明,该方法大大提升了目前最先进的方法。
 posted on
posted on

 浙公网安备 33010602011771号
浙公网安备 33010602011771号