

openai文档笔记
一、简介
二、文档
一、简介
现在流行出来的chatgpt,去看看文档,顺便了解下。
二、文档
如果不想看英文版,可以去w3c看看,也挺详细的,不过有些广告。:去看看
1.简介
上来就推荐到chatgpt去,不过我们要了解下整个项目的文档,看看到底有多少个可以使用的模型。

这里讲了,目前支持聊天的模型就是 GPT-3.5-Turbo , 而最新的模型到了GPT-4,到今天,gpt4 是需要申请资格才能使用的,以后可能就可以用了。
然后我们得先说gpt是什么。
语言模型是什么, 简单来说,就是人们把互联网上的文字数据统统收集到了一起,通过一系列算法,做出了一个功能, 就是你输入上文, 它可以帮你补全下文。
比如说:我先输入这样一段文字: ”我有一只小狗,我非常喜欢它,有一天“, 然后我把这段话丢给gpt,它就会帮你写出后面的内容

绿色字体背景就是它生成的内容,是不是一点都不违和。 这就是比以前通过收集数据,统计人们使用最多的组合,然后输出的内容,更加人性化了,懂的人都知道这意味着什么。虽然,内容确实还是会有些怪异。
而聊天的 GPT-3.5-Turbo, 它更是训练成了一个对话模式,它将根据你的内容,推测出回答你的方案,当然,这些过程,用户是看不到的,但是我们做程序的必须知道的。
2.key
值得说的是,目前最难的是,chatgpt是不支持亚洲地区的,我们上openai,,得先使用一些手段去上海外网的工具。这个还不是什么问题
但是在注册账号的时候,会需要你的邮箱,手机号码, 都必须不是亚洲地区的。
更加变态的是,网站会有第三方检测,检查你的ip地址,缓存。
以上,如果你都把困难克服了,那么恭喜你,可有了可以调用api接口的资格。
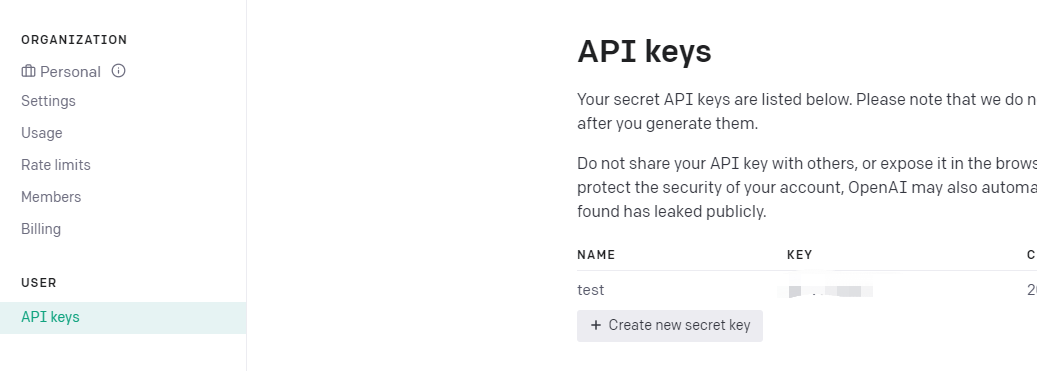
在个人设置里就可以配置,密钥了
3.费用
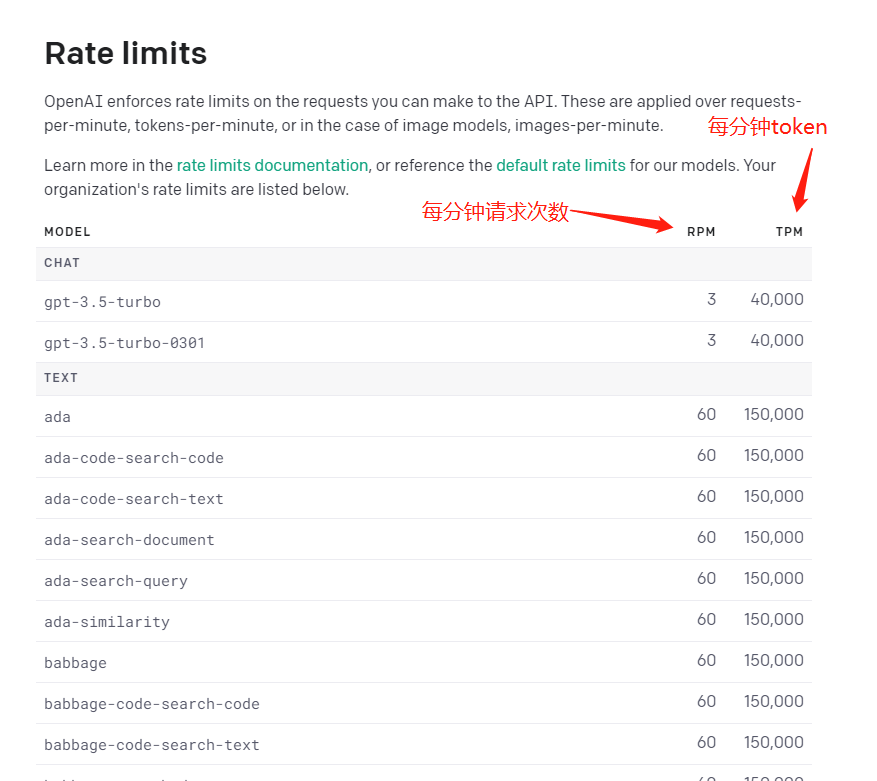
OpenAI AIP 调用次数限制 | 根据了解到的信息,OpenAI API 的免费用户的API调用次数原本是30次/分钟,后来调整为20次/分钟,现在变成了3次/分钟。如果想解除该限制,可以按照OpenAI提示绑定付款方式后可提高调用限制。不过,OpenAI 并没有注明绑定后调用限制会改成多少,查看
OpenAI 之前写的速率限制,应该是变成60次/分钟。另外,免费试用用户现在除了3次请求/分钟外,还有个 token 数量限制,每分钟最多发送4万个tokens。
Ada:Ada是OpenAI推出的最新模型,它是一种大规模的、多任务的语言模型,能够执行多种不同的自然语言任务,如问答、生成、分类等。Ada使用了GPT-3的一部分技术,并在其上进行了一些改进,使其具有更好的性能和效率。
Babbage:Babbage是OpenAI推出的一种中型语言模型,它由6亿个参数组成,可用于生成文本、回答问题和分类任务等。相比较于Ada、Curie和Davinci,Babbage的规模更小,因此通常可以更快地生成结果。
Curie:Curie是OpenAI推出的一种中大型语言模型,它由13亿个参数组成,可以用于自然语言生成、回答问题和文本分类等任务。相比Babbage,Curie在多任务学习和文本生成等方面表现更好,同时具有更高的性能和精度。
Davinci:Davinci是OpenAI推出的最大型的语言模型,它由175亿个参数组成,是目前最先进、最强大的语言模型之一。Davinci能够执行多种自然语言任务,如问答、生成、摘要等,并且在这些任务中表现出色。
5.目前主要功能模型

gpt4,gpt3.5 是用于对话聊天的模型
dall e 是可以将文字转变成图片的模型
whisper 是可以将音频转换成文字的模型
embeddings 可以将文字转换成数字的模型
moderation 是来检测敏感词,暴力之类的模型
gpt-3 是语言预测模型,后面的gpt3.5和4都是从这一路走来的
codex 是理解文字并生成代码的模型。
相关对应模型的接口表

并不是所有模型你都可以调用得到,openai 对你得key是加以限制得
比如:如果你没有获得使用gpt4使用条件,你调用该接口是不会正常返回数据得。
5.微调
chatgpt是不可微调的,它可以配置system 就是在对话前增加要求,但是这个不是微调
微调只限定与Completion, 也就是上面对应得/v1/completions
如果想了解具体操作可以去这里查看:去看看
6.使用python调用openai 的chat模型(调用接口需要外网,并且不能被检测出亚洲地区ip)
首先得安装openai
pip install openai
然后
# Note: you need to be using OpenAI Python v0.27.0 for the code below to work import openai openai.ChatCompletion.create( model="gpt-3.5-turbo", messages=[ {"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "Who won the world series in 2020?"}, {"role": "assistant", "content": "The Los Angeles Dodgers won the World Series in 2020."}, {"role": "user", "content": "Where was it played?"} ] )
它这里面有三个角色, system(系统), user (用户),assistant(ai)
如果需要预设一个人设,或者一些条件,你就可以在system里面增加你要求的内容,当然,不是一定会听你的话,需要调试。
每次用户的话,和ai的话都得带进去,一起发送出去, 你没听出,每次都得发出去
正因为发送出去,ai才会跟你有上下文。能明白之前说了什么。
也就意味着,messages 会越来越大,你得在代码里考虑下,是否在列表多长得时候删除一些,
因为内容越过,意味着运算量越大,可能openai那边要很长时间才能跟你返回结果。
而接口返回得内容大概是
{ 'id': 'chatcmpl-6p9XYPYSTTRi0xEviKjjilqrWU2Ve', 'object': 'chat.completion', 'created': 1677649420, 'model': 'gpt-3.5-turbo', 'usage': {'prompt_tokens': 56, 'completion_tokens': 31, 'total_tokens': 87}, 'choices': [ { 'message': { 'role': 'assistant', 'content': 'The 2020 World Series was played in Arlington, Texas at the Globe Life Field, which was the new home stadium for the Texas Rangers.'}, 'finish_reason': 'stop', 'index': 0 } ] }
其中choices里面,如果你在前面设定了n=2,那就会返回两个结果供你选择,默认是只有一个结果的。而usage里面返回了你使用的token.
6.图片生成模型
response = openai.Image.create( prompt="古风美女", n=1, size="1024x1024" ) image_url = response['data'][0]['url']

说实话,美女长成这样,有点难以接受。。。
它还有其他两个功能,一个是给两张图片,一张透明化部分,你可以要它按要求补全。
代码如下:
response = openai.Image.create_edit( image=open("sunlit_lounge.png", "rb"), mask=open("mask.png", "rb"), prompt="A sunlit indoor lounge area with a pool containing a flamingo", n=1, size="1024x1024" ) image_url = response['data'][0]['url']

还有个就是原图微调,变体
response = openai.Image.create_variation( image=open("corgi_and_cat_paw.png", "rb"), n=1, size="1024x1024" ) image_url = response['data'][0]['url']

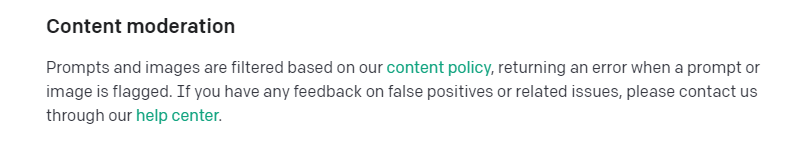
当然,图片也会被审核,如果是不良图片,会返回错误。
7.微调模型

这个是可以微调对应已经成型的gpt,只能使用预测模型,也就是,Completion, 在见面有推荐参考文章,我自己也试了下,最好在美国服务器使用,我用代理没效果,而且要python 3.7以上,不然上传不了那个文档,python版本不够也无法使用自带工具

 浙公网安备 33010602011771号
浙公网安备 33010602011771号