

Anaconda 环境下 对Tushare进行测试
Anaconda下安装好Tushare后,就搬一搬Tushare的砖吧(搬砖的内容是在 https://jingyan.baidu.com/article/3065b3b68d7fb5becff8a494.html 进行学习和总结的!)
一 历史交易数据获取
import tushare as ts
df = ts.get_hist_data('601998') #获取股票代码为601998的历史数据
ts.get_hist_data('601998',ktype='5')
ts.get_hist_data('cyb') df.tail(5)
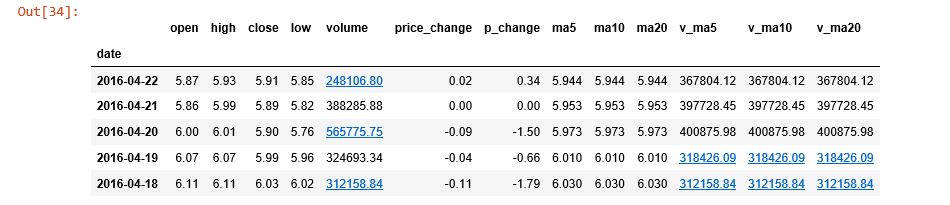
(获取指数k线数据 sz sh hs300 sz50 zxb cyb
数据框列标题代表含义 open:开盘价 high:最高价 close:收盘价 low:最低价 volume:成交量 price_change:价格变动 p_change:涨跌幅 ma5:最近5日收盘价平均值
ma10:最近10日收盘价平均值 ma20:最近20日收盘价平均值 v_ma5:5日均量 v_ma10:10日均量 v_ma20:20日均量)
二 获取历史分笔数据
df = ts.get_hist_data('601998','2018-05-10')
df.head(10) #(获取前十条数据)
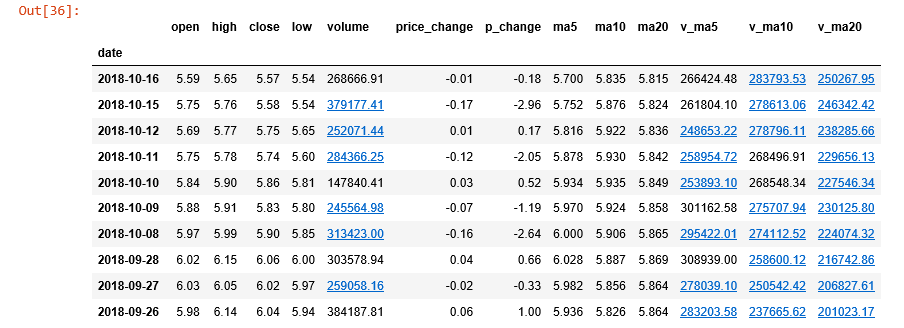
三 获取实时单笔数据
df = ts.get_realtime_quotes('601998')
result = df[['code','name','amount','b1_v','high']]
print(result)

(返回值 name:股票名字 :open:今日开盘价 pre_close:昨日收盘价 price:当前价格 high:今日最高价 low:今日最低价 bid:竞买价,即“买一”报价 ask:竞卖价,即“卖一”报价 volumn:成交量 maybe you need do volumn/100 amount:成交金额(元 CNY) b1_v:委买一(笔数 bid volume) b1_p,委买一(价格 bid price) b2_v:“买二” b2_p:“买二” b3_v:“买三” b3_p:“买三” b4_v:“买四” b4_p:“买四” b5_v:“买五” b5_p:“买五” a1_v:委卖一(笔数 ask volume) a1_p:委卖一(价格 ask price) date:日期 time:时间)
四 获取其他数据
df = ts.get_hs300s() #获取沪深300成份股及权重
df.head(10)#提取前十条数据

(行业分类:ts.get_industry_classified()
概念分类:ts.get_concept_classified()
地域分类:ts.get_area_classified()
中小板分类:ts.get_sme_classified()
创业板分类:ts.get_gem_classified()
风险警示板分类:ts.get_st_classified()
沪深300成份股及权重:ts.get_hs300s()
上证50成份股:ts.get_sz50s() )
五 基本面数据
df = ts.get_report_data(2015,4) #获取2015年4月的业绩报告
df.head(10)

(沪深股票列表(基础数据,沪深所有股票情况) ts.get_stock_basics()
业绩报告(主表) ts.get_report_data(年,月)
盈利能力数据 ts.get_profit_data(年,月)
营运能力数据 ts.get_operation_data(年,月)
成长能力数据 ts.get_growth_data(年,月)
偿债能力数据 ts.get_debtpaying_data(年,月)
现金流量数据 ts.get_cashflow_data(年,月) )
六 数据存储
# 1.csv 格式
import tushare as ts
df = ts.get_hist_data('601998')
df.to_csv('C:/Users/lalala/Desktop/Tomato/Hundreds of millions/2018.10.17/c.csv',columns=['open','high','low','close']) # colunms 保存指定的列索引
# 2.保存excel格式
import tushare as ts
df = ts.get_hist_data('601998')
df.to_excel('C:/Users/lalala/Desktop/Tomato/Hundreds of millions/2018.10.17/e.xlsx',startrow=3,startcol=6) #startrow=3 startcol=6 是指从第三行第六列开始插入数据
# 3.保存成json格式
import tushare as ts
df = ts.get_hist_data('601998')
df.to_json('C:/Users/lalala/Desktop/Tomato/Hundreds of millions/2018.10.17/j.json')
# 4.保存成HDF5格式
import tushare as ts
df = ts.get_hist_data('601998')
df.to_hdf('C:/Users/lalala/Desktop/Tomato/Hundreds of millions/2018.10.17/j.h5','601998') # 注意在保存hdf的格式时 ,要在路径后加上查询的股票代码

 浙公网安备 33010602011771号
浙公网安备 33010602011771号