


抖音的数据抓取与数据背后的淘宝
分析的背景
截至今年7月,抖音日活已突破3.2亿。抖音总裁张楠预测,到2020年,国内短视频行业的总日活用户数,将达到10亿。抖音推出多元变现方式,要让1000万创作者赚到钱 ,抖音说要让这1000万创作者赚到钱,其中变现的方式有很多种,我今天主要是想分享抖音背后的淘宝产业链,我们刷抖音视频的过程中,我们会发现有些视频是在推广淘宝的商品,这个就是创作者变现的渠道之一,从淘宝店铺角度来说,抖音达人帮其推广商品,需要付给达人一定的广告费用;从淘宝角度来说,淘宝有一个叫淘宝联盟的平台,每一个帮淘宝推销商品的人,淘宝联盟将其定义为淘宝客,只要淘宝客推广的商品有人购买,那么淘宝联盟会支付给淘宝客一定比例的佣金。简而言之,抖音达人有两部分收入:淘宝商家的广告费+淘宝联盟的佣金(交易成功的前提下)。本文主要分析抖音达人发帖到淘宝之间的过程。
抖音的帖子
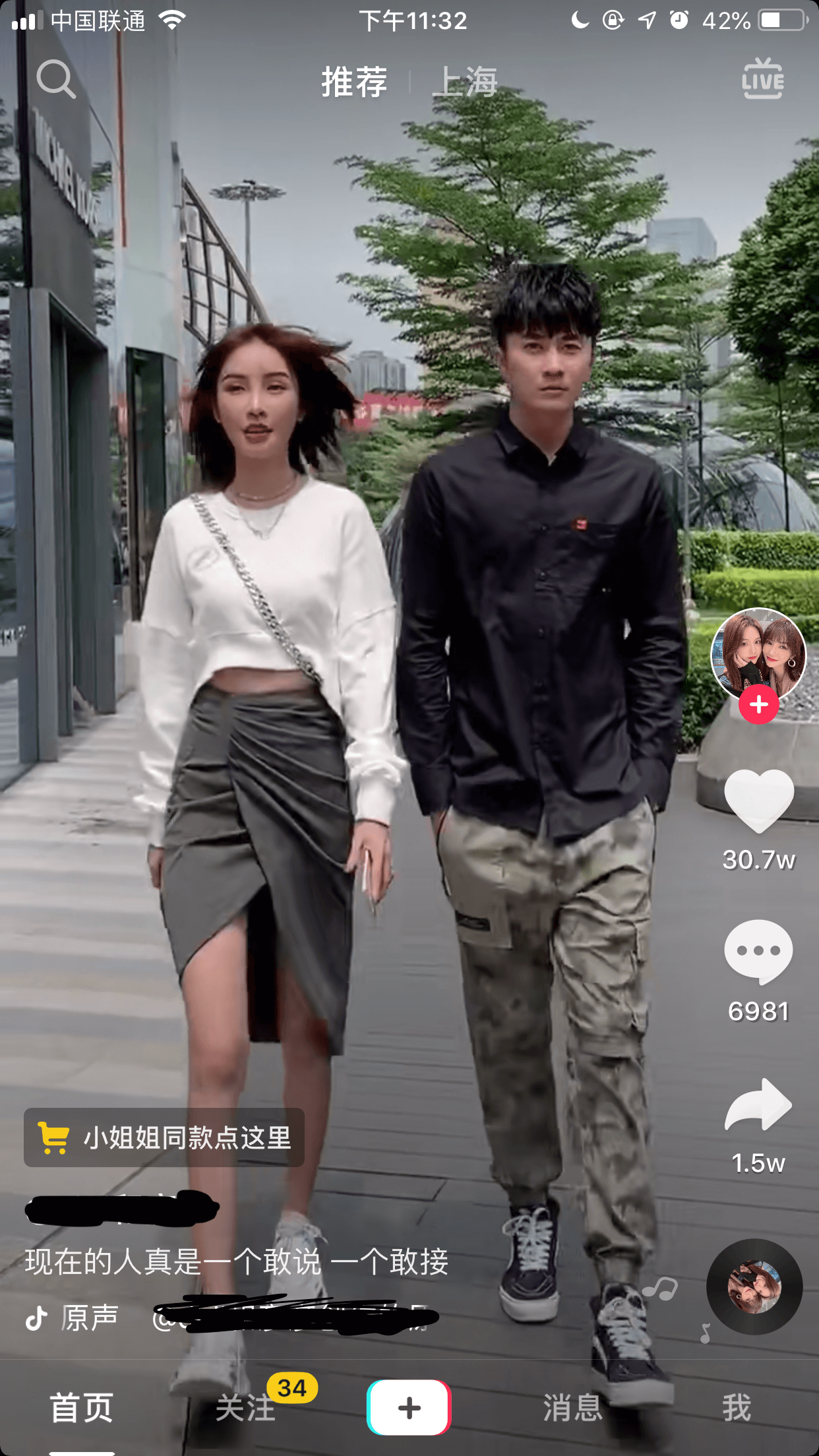
帖子的正文
我们可以看到左下角有一个购物车的标示。没错,他就是淘宝商品的链接,点击打开如下

这个就是达人帖子推广的商品,点击即可跳到淘宝APP
综上所述,我们可以抓取某个达人的列表数据来分析背后的商品数据,从而可以得到对应的淘宝店铺的数据。
抖音APP抓包
本次使用的iphone 的抖音version8.0.0的版本,anyproxy作为代理的抓包工具
anyproxy是阿里巴巴开发的一个优秀的代理的轮子,当然啦,国外还有一个mitmproxy
anyproxy 的安装教程可以参考:
https://link.zhihu.com/?target=https%3A//www.jianshu.com/p/d978d3b8f2aa
anyproxy 的官方链接: 貌似需要稳定的国际网络环境才可以访问
https://link.zhihu.com/?target=http%3A//anyproxy.io
anyproxy 的项目地址:
https://link.zhihu.com/?target=https%3A//github.com/alibaba/anyproxy
我们可以使用anyproxy和mitmproxy来作为抓包的分析工具,
anyproxy 是基于nodeJs开发的 (推荐熟悉nodeJs的人使用)
mitmproxy 是基于python开发的 (推荐熟悉python的人使用)
使用这个两个工具主要是可以做数据的拦截与转发,这两者的都是利用到来中间人的攻击的原理,后面的我们爬虫开发也是利用这个原理。当然了单纯的做数据分析,可以使用fidder和charles等常见的抓包工具。
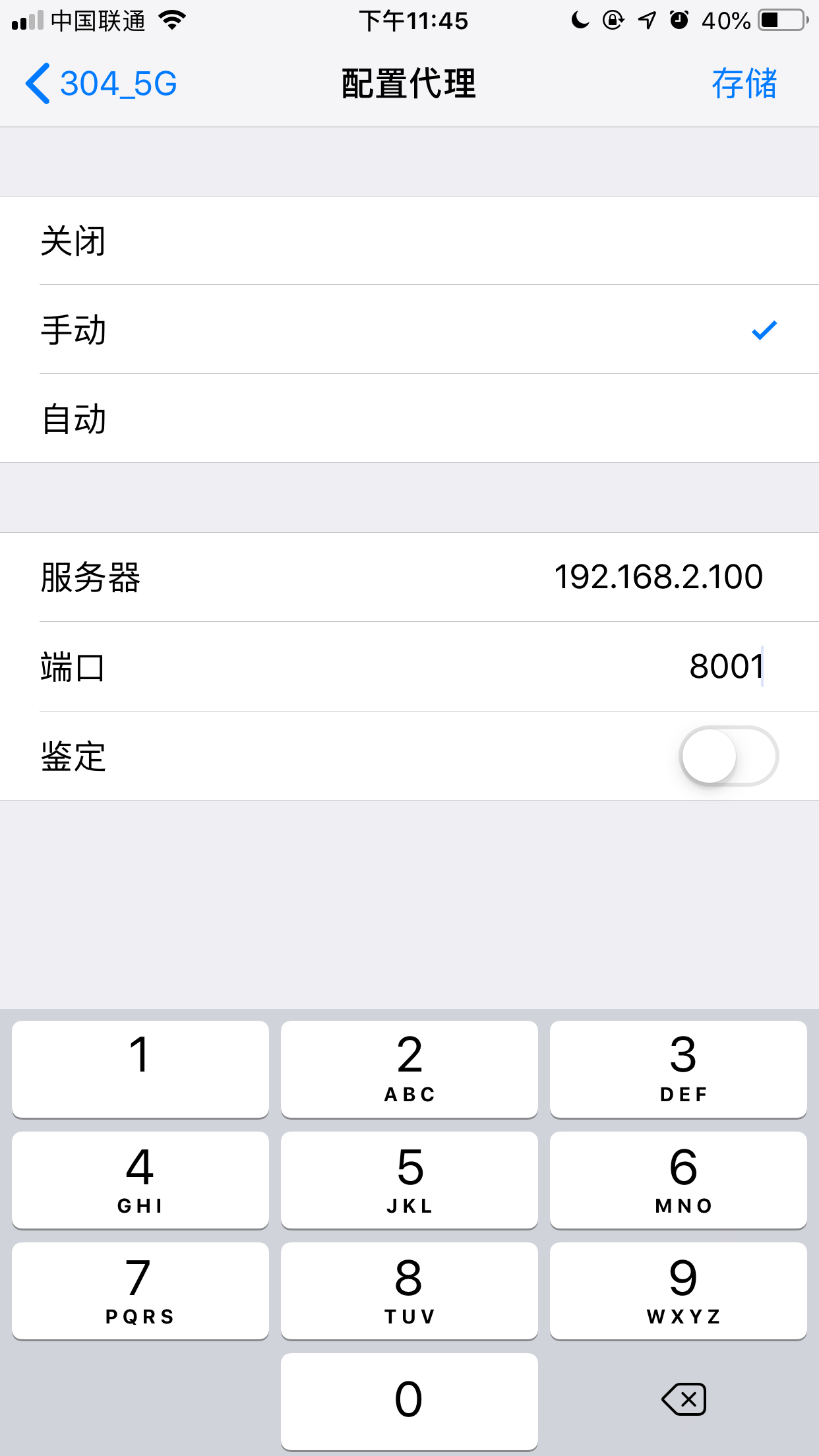
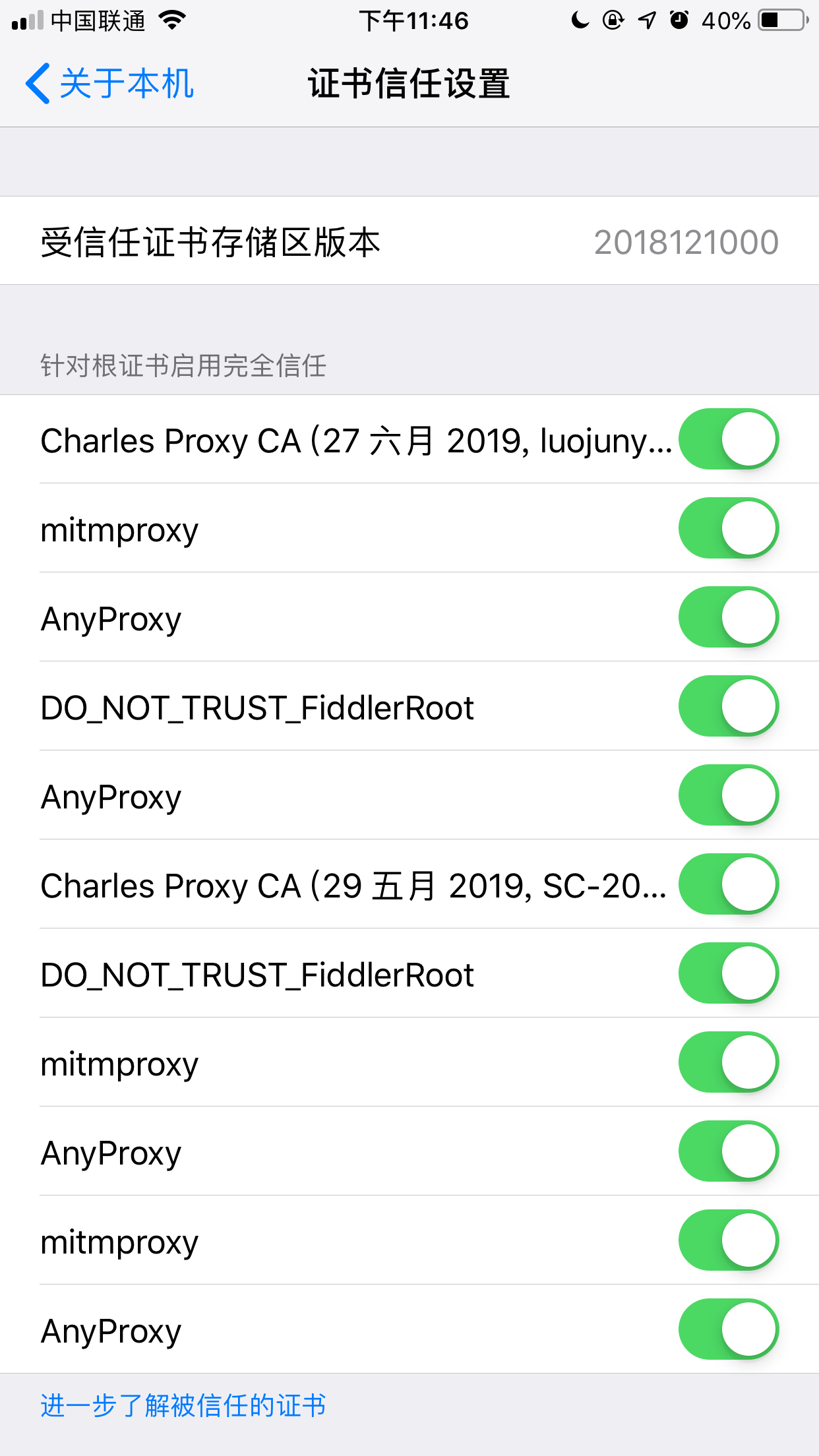
安装好anyproxy 需要手机设置信任证书以及代理
代理的设置,anyproxy 默认使用8001端口作为代理的端口
设置代理
设置信任证书
手机打开抖音APP其中的一个达人帖子的列表
某个达人的帖子列表页面
电脑打开:http://localhost:8002/ 可以看到流经手机所有的数据,其中当然也包含了抖音APP的数据. 可以看见抖音达人的帖子链接
做一下URL的条件过滤:https://api-hl.amemv.com/aweme/v1/aweme/post/
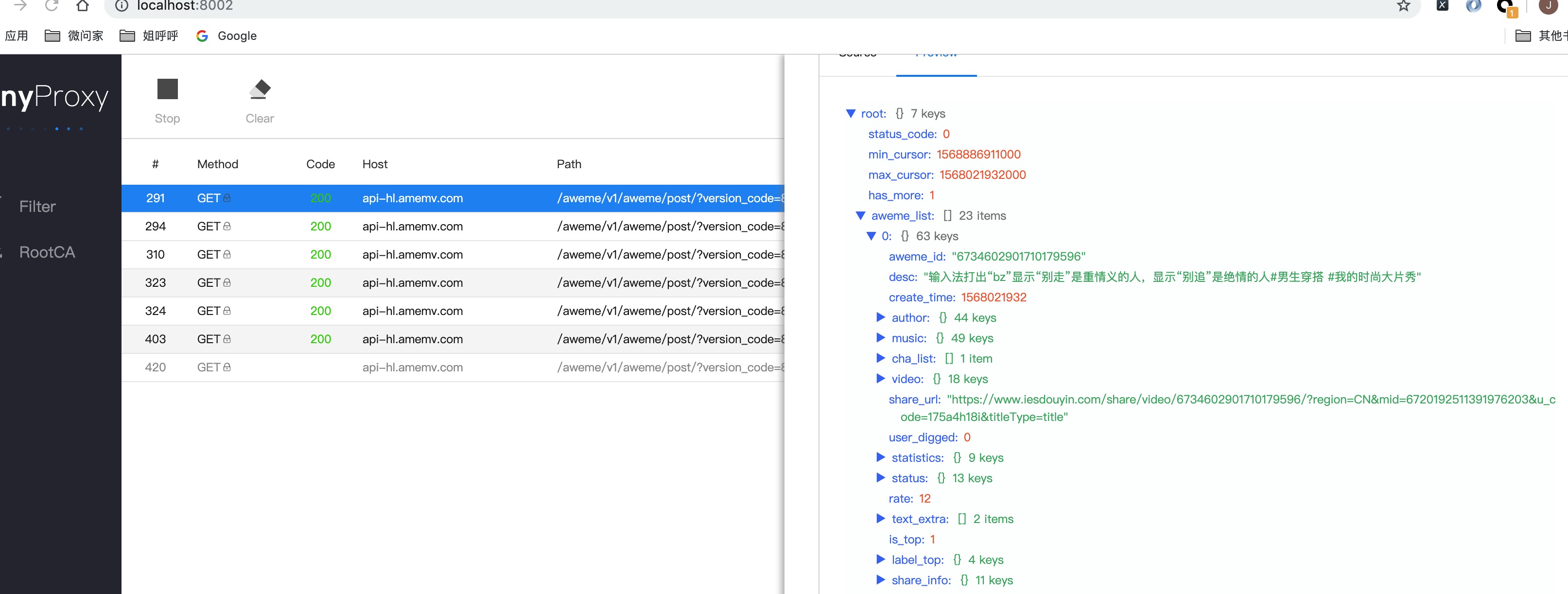
通过这个分析可以看到每一篇帖子都有simple_promotions的字段,这个字段就是携带推广商品的信息,我们可以先把这个ID存到数据,再根据商品的ID来获取到淘宝店铺的其他信息

anyproxy默认的代理拦截与转发的设置

这里说明一下,默认在终端执行anyproxy -i ,anyproxy 会自动加载在/usr/local/lib/node_modules/anyproxy/lib/rule_default.js的文件,我们需要拦截抖音的数据,我们需要在其同级的目录新建一个douyin.js 文件即可,执行anuproxy -i douyin.js,那么anyproxy就根据douyin.js里面的逻辑做拦截转发的操作。这个mac的文件的默认位置,window的默认文件位置自己全局搜索一下rule_default.js即可以找到
具体的文件douyin.js代码如下
1 'use strict'; 2 3 module.exports = { 4 5 summary: 'the default rule for AnyProxy', 6 7 /** 8 * 9 * 10 * @param {object} requestDetail 11 * @param {string} requestDetail.protocol 12 * @param {object} requestDetail.requestOptions 13 * @param {object} requestDetail.requestData 14 * @param {object} requestDetail.response 15 * @param {number} requestDetail.response.statusCode 16 * @param {object} requestDetail.response.header 17 * @param {buffer} requestDetail.response.body 18 * @returns 19 */ 20 *beforeSendRequest(requestDetail) { 21 console.log('this is request') 22 return null; 23 }, 24 25 26 /** 27 * 28 * 设置截取抖音的数据 29 * @param {object} requestDetail 30 * @param {object} responseDetail 31 */ 32 *beforeSendResponse(requestDetail, responseDetail) { 33 if (requestDetail.url.indexOf('https://api-hl.amemv.com/aweme/v1/aweme/post/') >= 0) { //抖音达人的详细信息app端 34 const newResponse = responseDetail.response; 35 newResponse.body = newResponse.body.toString(); 36 const posturl="/WebCrawler/douyin/AppUserData" 37 HttpPost(newResponse.body,requestDetail.url,posturl) 38 console.log('传送app端达人的详细信息') 39 40 } 41 42 43 44 return null; 45 }, 46 47 48 /** 49 * default to return null 50 * the user MUST return a boolean when they do implement the interface in rule 51 * 52 * @param {any} requestDetail 53 * @returns 54 */ 55 *beforeDealHttpsRequest(requestDetail) { 56 return null; 57 }, 58 59 /** 60 * 61 * 62 * @param {any} requestDetail 63 * @param {any} error 64 * @returns 65 */ 66 *onError(requestDetail, error) { 67 return null; 68 }, 69 70 71 /** 72 * 73 * 74 * @param {any} requestDetail 75 * @param {any} error 76 * @returns 77 */ 78 *onConnectError(requestDetail, error) { 79 return null; 80 }, 81 82 83 /** 84 * 85 * 86 * @param {any} requestDetail 87 * @param {any} error 88 * @returns 89 */ 90 *onClientSocketError(requestDetail, error) { 91 return null; 92 }, 93 }; 94 95 96 //传输数据到本地自己的服务器进行入库存储的操作 97 function HttpPost(json,url,path) {//将json发送到服务器,str为json内容,url为历史消息页面地址,path是接收程序的路径和文件名 98 console.log("开始执行转发操作"); 99 try{ 100 var http = require('http'); 101 var data = { 102 json: json, 103 url: encodeURIComponent(url), 104 data:'Im jiehuhu' 105 }; 106 data = require('querystring').stringify(data); 107 var options = { 108 method: "POST", 109 host: "127.0.0.1",//注意没有http://,这是服务器的域名。 110 port: 8080, 111 path: path,//接收程序的路径和文件名 112 headers: { 113 'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8', 114 "Content-Length": data.length 115 } 116 }; 117 var req = http.request(options, function (res) { 118 res.setEncoding('utf8'); 119 res.on('data', function (chunk) { 120 console.log('BODY: ' + chunk); 121 }); 122 }); 123 req.on('error', function (e) { 124 console.log('problem with request: ' + e.message); 125 }); 126 127 req.write(data); 128 req.end(); 129 }catch(e){ 130 console.log("错误信息:"+e); 131 } 132 133 console.log("转发操作结束"+req); 134 }
具体的后端有一个项目来接收anyproxy 拦截转发的数据,我这的使用的javaWeb项目名字叫做WebCrawler项目来处理请求
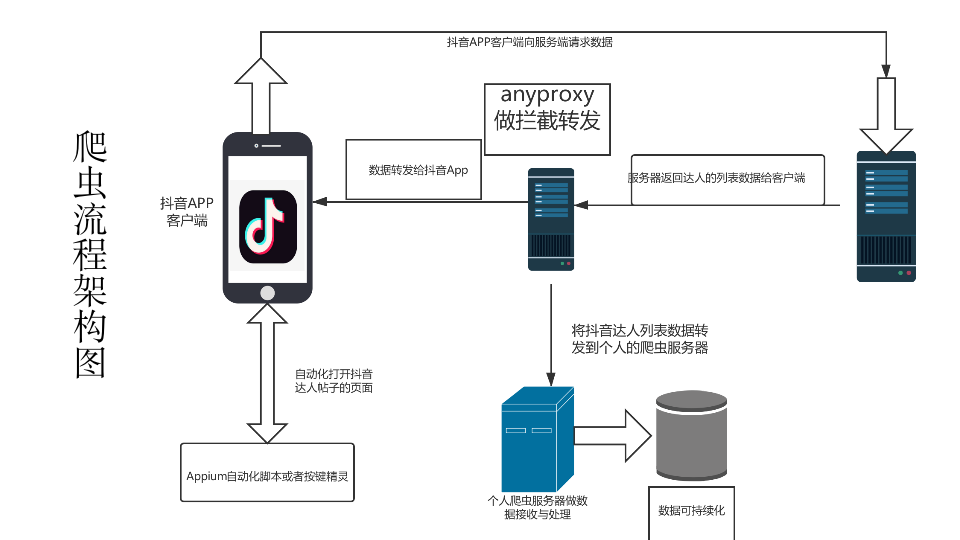
大体的抖音APP数据的采集流程图如下:
这里采用的是 java+tomcat8+mysql的技术框架,这是我一年前的技术栈 ,当然现在的我更加喜欢用mongoDB和Python,处理起来的时间比较快
也可以使用python + mongoDb 来处理anyproxy 传送过来的数据
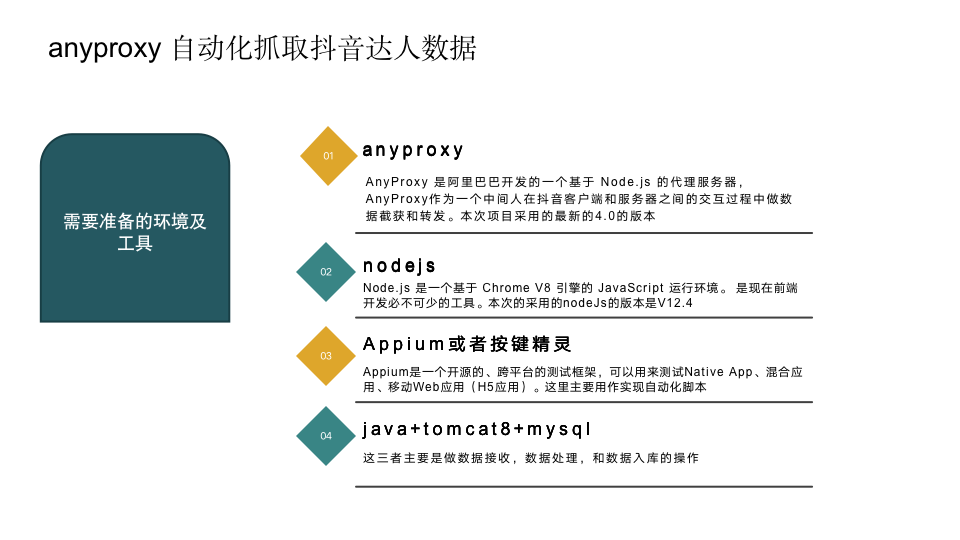
具体的自动化的操作部分暂时没有完成,可以使用手机自动化测试工具Appium或者按键精灵
数据结果如下:抖音的部分数据
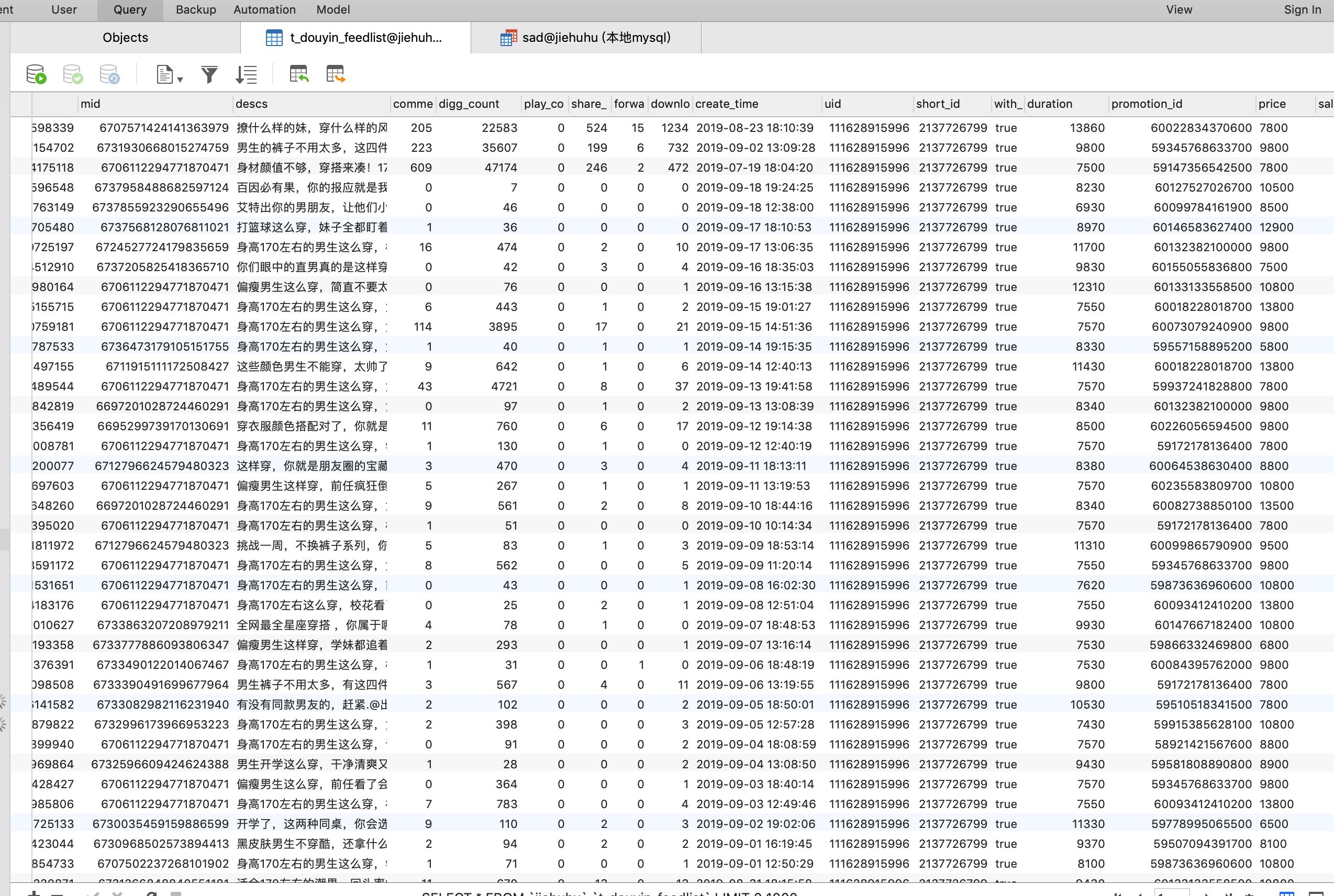
根据商品的ID获取到淘宝店铺的数据
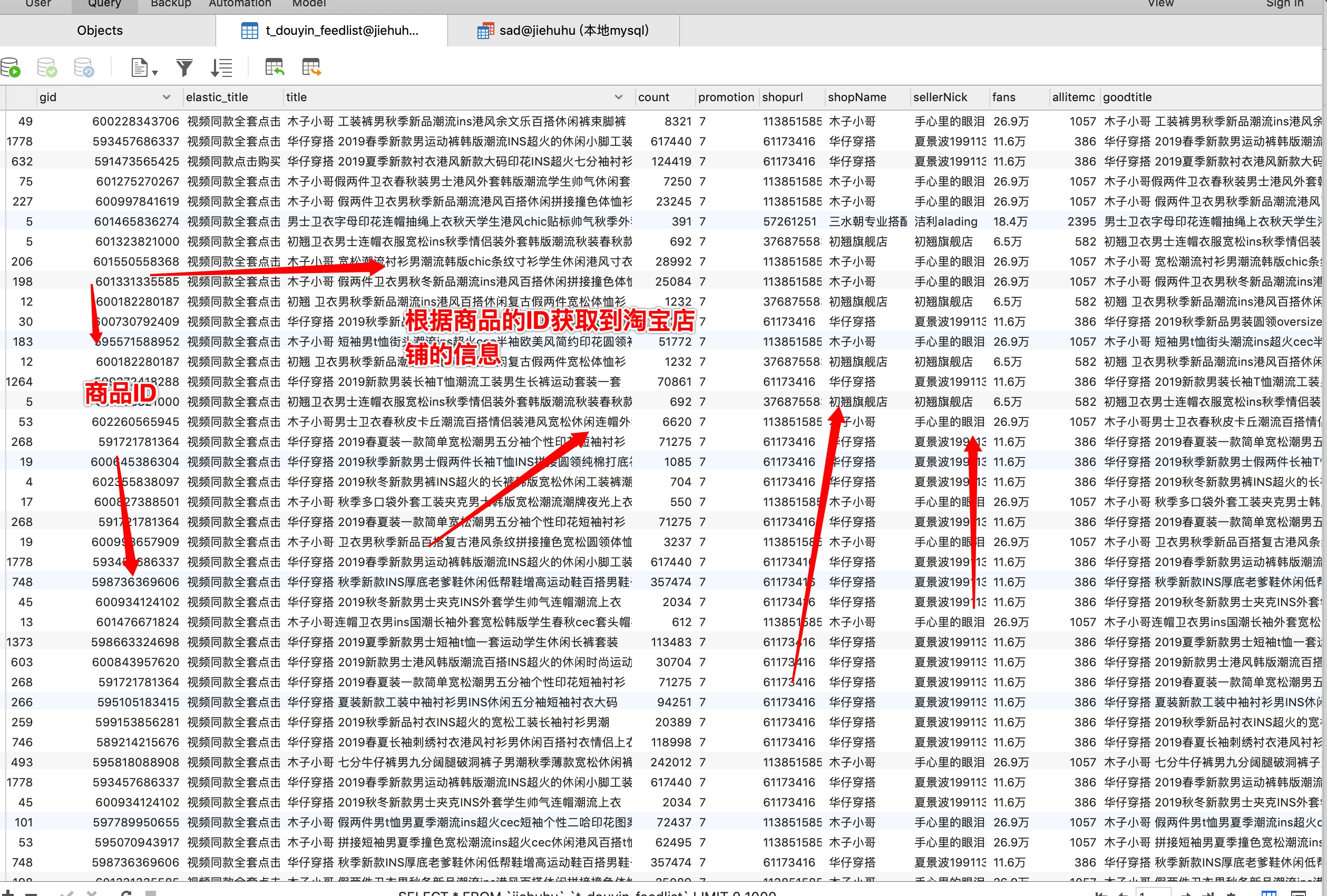
根据淘宝商品的ID来获取淘宝店铺的信息也是需要开发一个新的爬虫。这里不作过多说明,难度还是有一点,商品爬虫关键需要搞懂淘宝的签名机制
淘宝H5的签名机制,感兴趣自己慢慢研究。。。。反正我是研究出来了哈哈哈哈
具体的爬下来的数据我放在百度云,链接如下:有兴趣的可以看一下
链接:https://pan.baidu.com/s/1O5CYJeJYiL6uB7e56_WPUA 密码:1abc
以上就是抖音数据的抓取过程,以及延伸至淘宝的过程,大致的思路
- 抖音APP通过anyproxy来获取抖音达人所有的帖子
- 分析帖子里面推广的商品的ID,根据商品的ID来获取店铺相关的信息
- 分析一个达人到底在推广哪些商品,和那一些店铺在合作。
- 通过大规模的数据抓取以分析,就可以分析出那些店铺在抖音做大规模的推广
关于呼呼:会点爬虫,会点后端,会点前端,会点数据分析,会点算法,一个喜欢陈奕迅的👨
here can contact me

本文为作者原创,我一个一个字打出来的,嘤嘤,如需转载请注明原文链接
本文的目的只有一个就是学习爬虫技术,如果有人利用本文技术进行非法操作带来的后果都是操作者自己承担,和本文以及本文作者没有任何关系。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号