重学transformer【学习笔记】
以前对transformer的了解只能说个大概 你要说会吧 会的不彻底 不会吧 还能扯一顿。
来源:B站 老弓的学习笔记
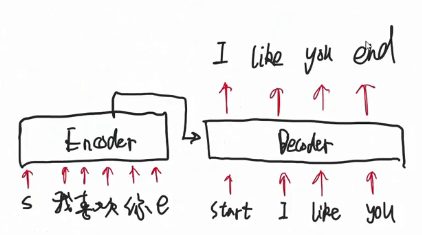
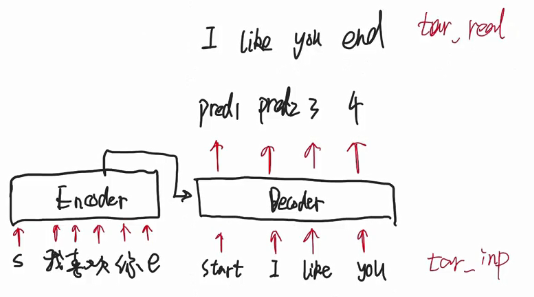
这一步讲 decoder的工作原理 怎么感觉像个串行的?一会需要多注意

分批的时候是按照批次内的最长 我记得不是可设置吗 填充到多少?
拿一个batch举例
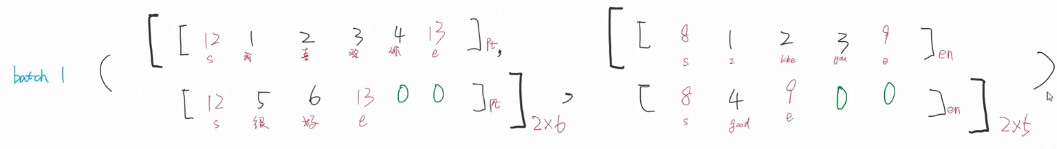
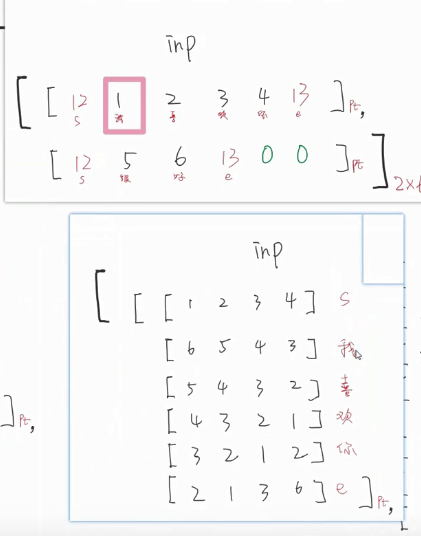
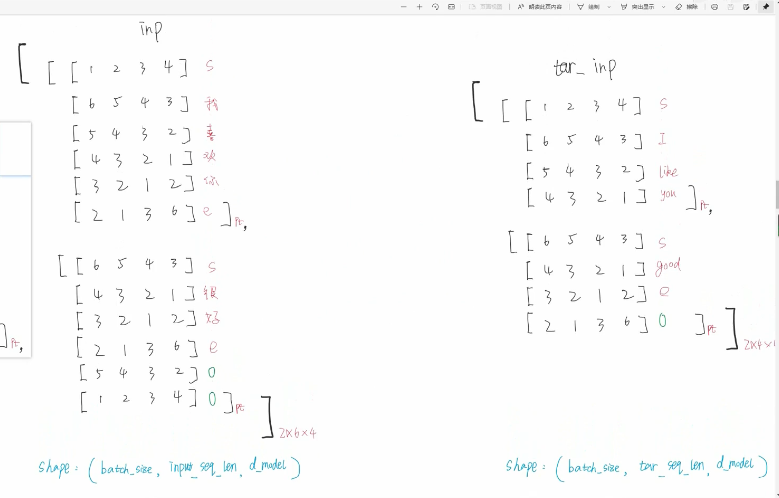
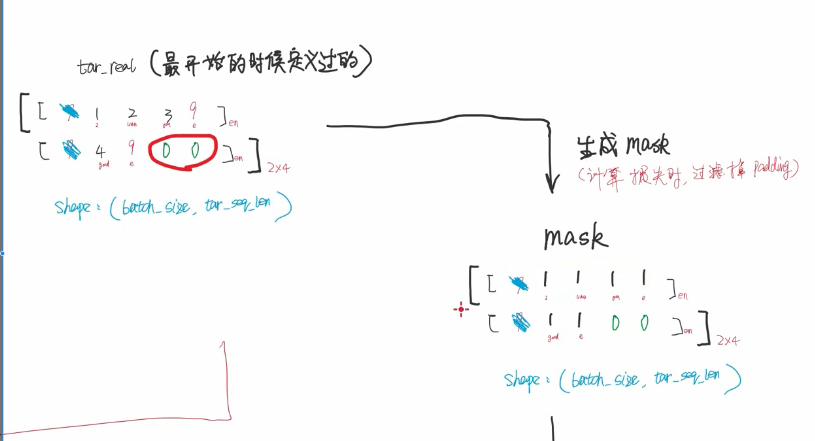
input不需要处理 ,tar需要处理
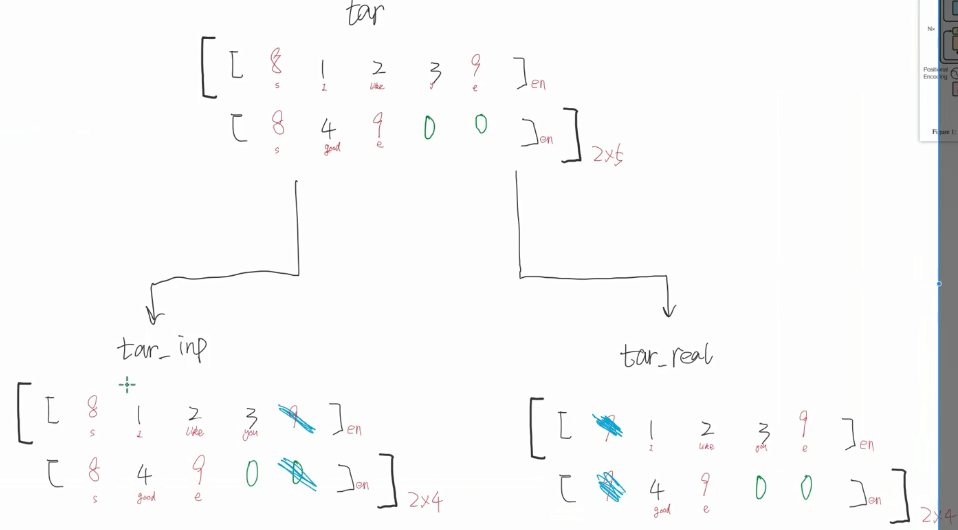
为什么要做这个处理呢 原因如下
还有个创建mask的过程(要我看就跟 就是分段似的 )就是对不起来的符号置1 原来的还是0
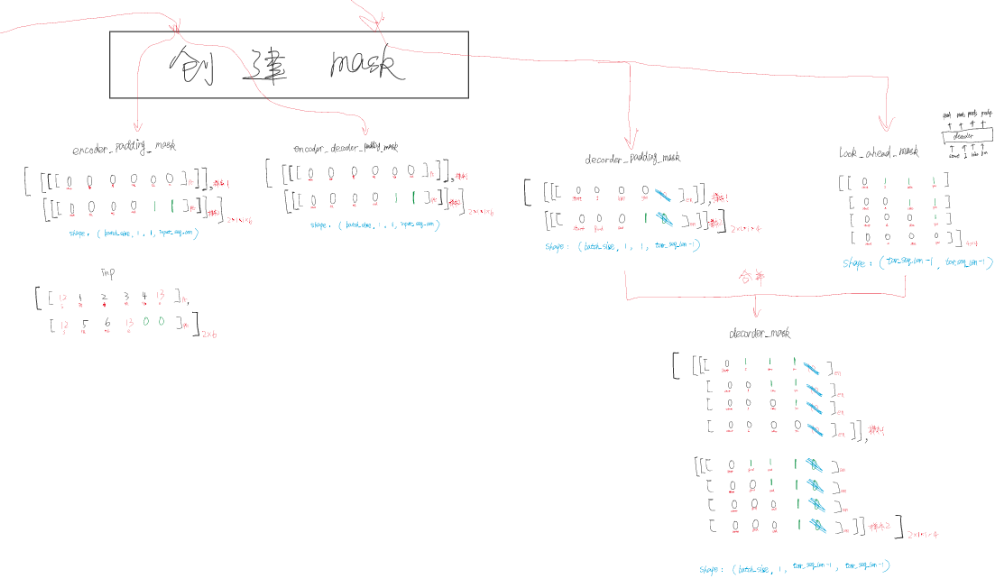
这里要仔细看原图。看看 decoder_padding_mask是怎么来的
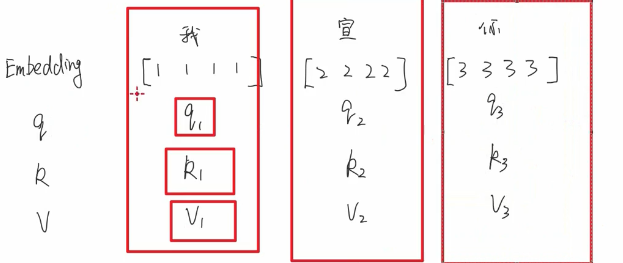
【输入层】embedding这里用最原始的embedding 比如说 将每个字用一个4维的向量表示
【位置编码】
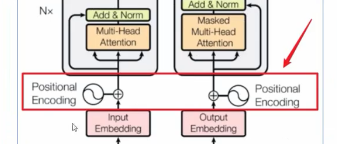
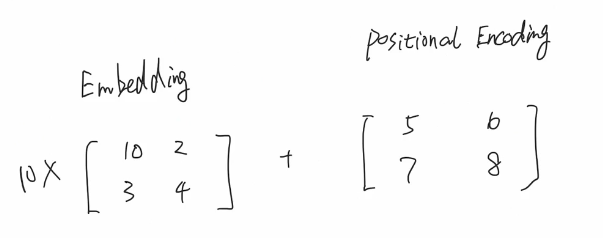
embedding的结果加上这个位置编码。因为transformer并行计算 没理解到位置信息
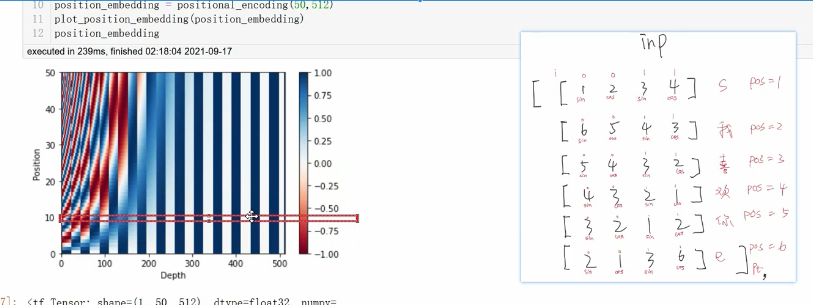
位置编码公式:
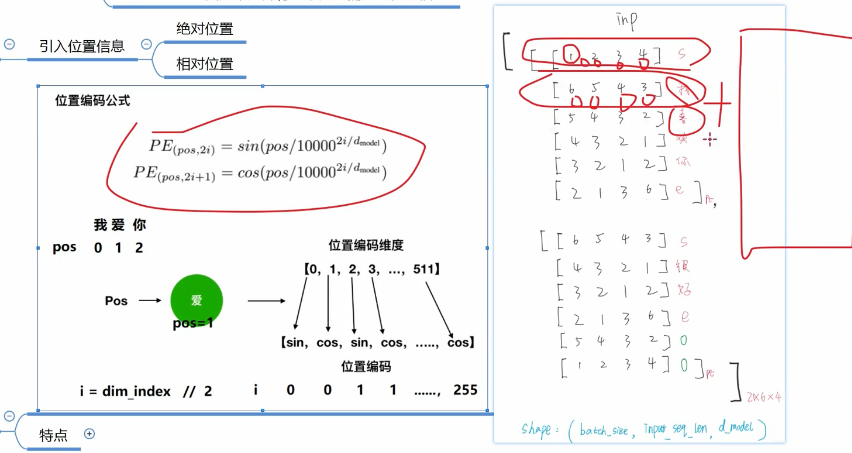
所得的位置向量和embedding相加
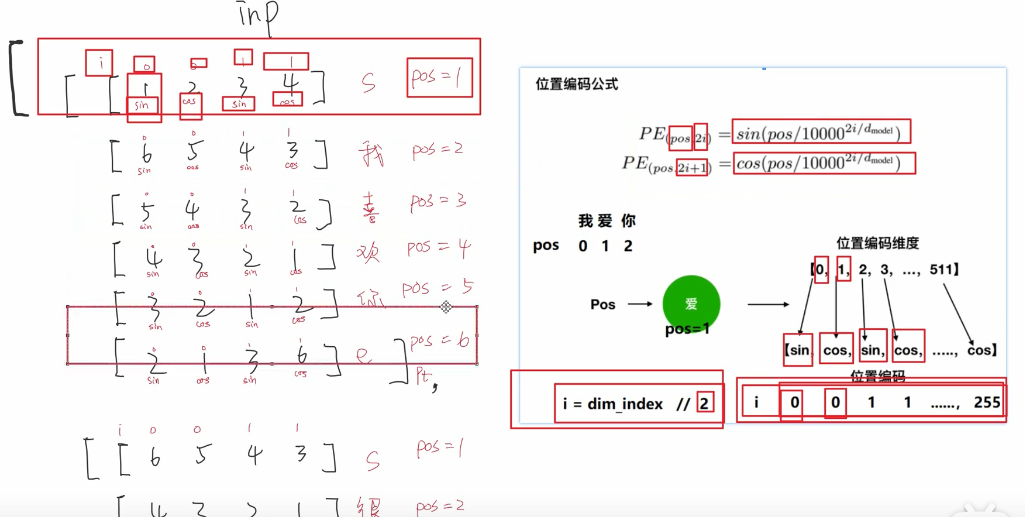
在每个字的维度中 sin cos是交错的。
特点:1 当d_model 跟seq_length确定时候,位置编码即可确定(d_model按照自己通常的理解就是 每个字的维度长,seq_len则是句子长)2.同时引入了绝对位置信息与相对位置信息。
绝对位置:每个横框相当于一个 向量 可以看到是独一无二的
相对位置:周期性变化规律

改进方向:也就是说存在缺陷
现存缺点:相对位置信息在self-attention线性变化后消失(为什么消失??)

缩放 希望是embedding占绝大部分
【Encoder部分】
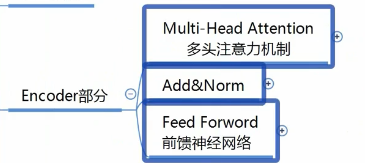
self-attention
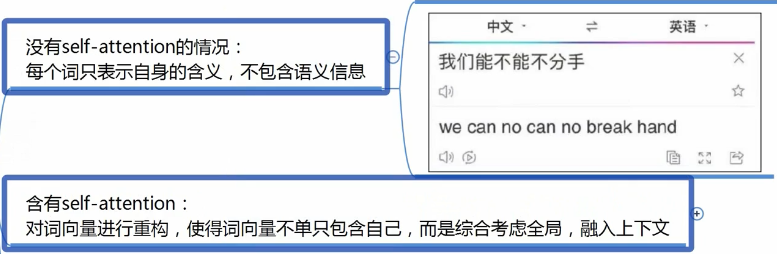
self-attention大致过程

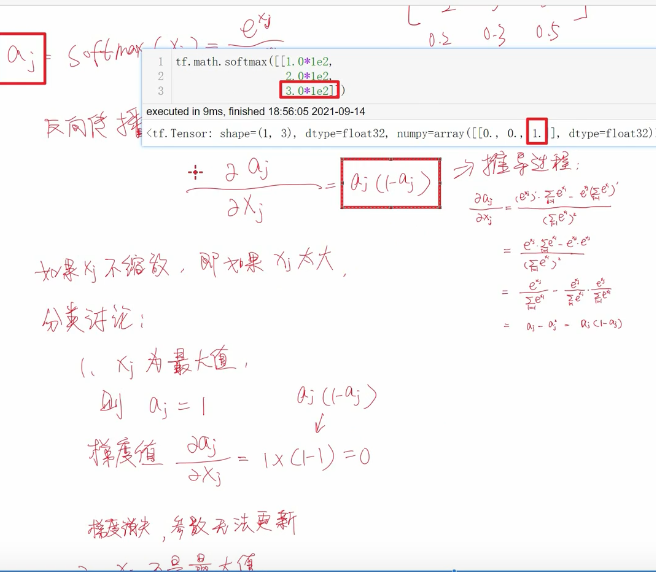
【scaled dot-product attention缩放点积注意力】
原因:1 前向传播角度 2.反向传播角度
前向传播角度

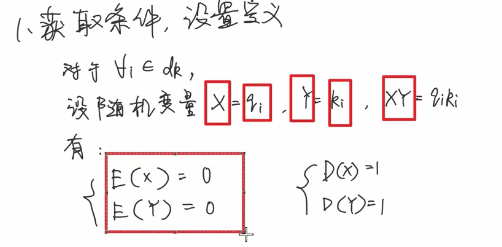
为什么q*k之后均值是0 方差是dk了呢?

 相当于求这块的呗
相当于求这块的呗






(自注:终于从方差角度讲清楚了 居然还听懂了 嘿嘿)
反向传播角度

(自注 为啥会梯度消失 )
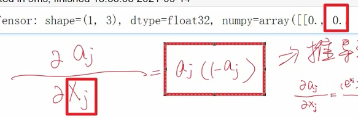 为0也不行
为0也不行
【Multi head】
理论上
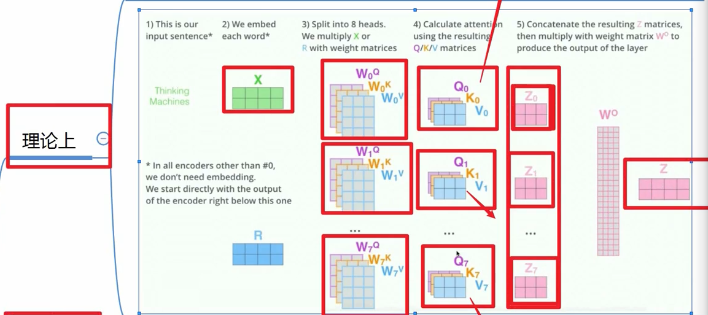
实际上
用同一套W参数 然后将QKV拆分
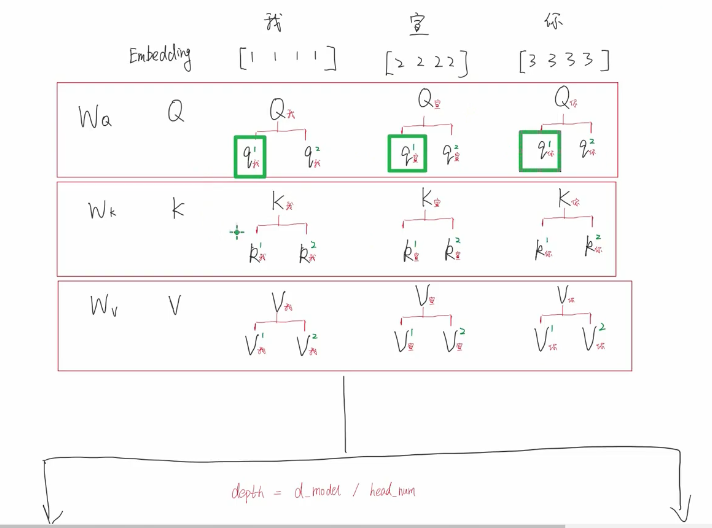
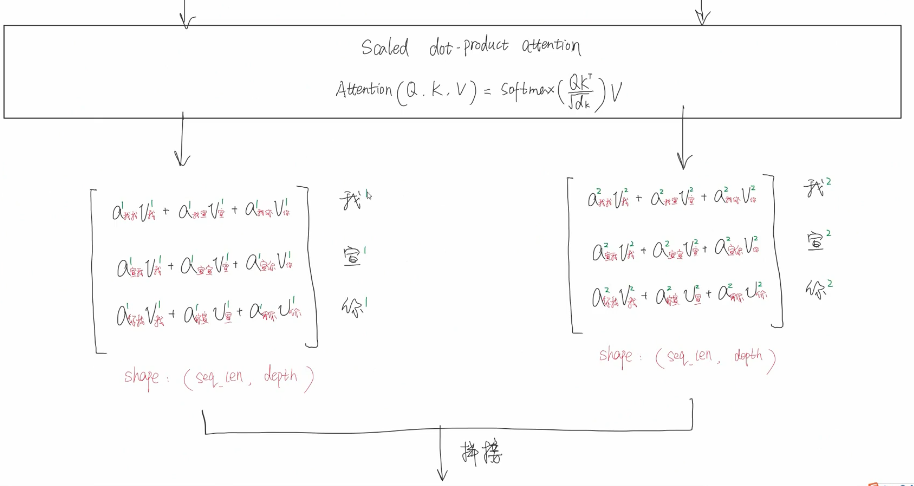
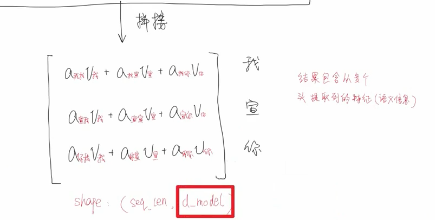
为什么要使用多头:
保证了transformer可以注意到不同子空间的信息,捕捉到更加丰富的特征信息
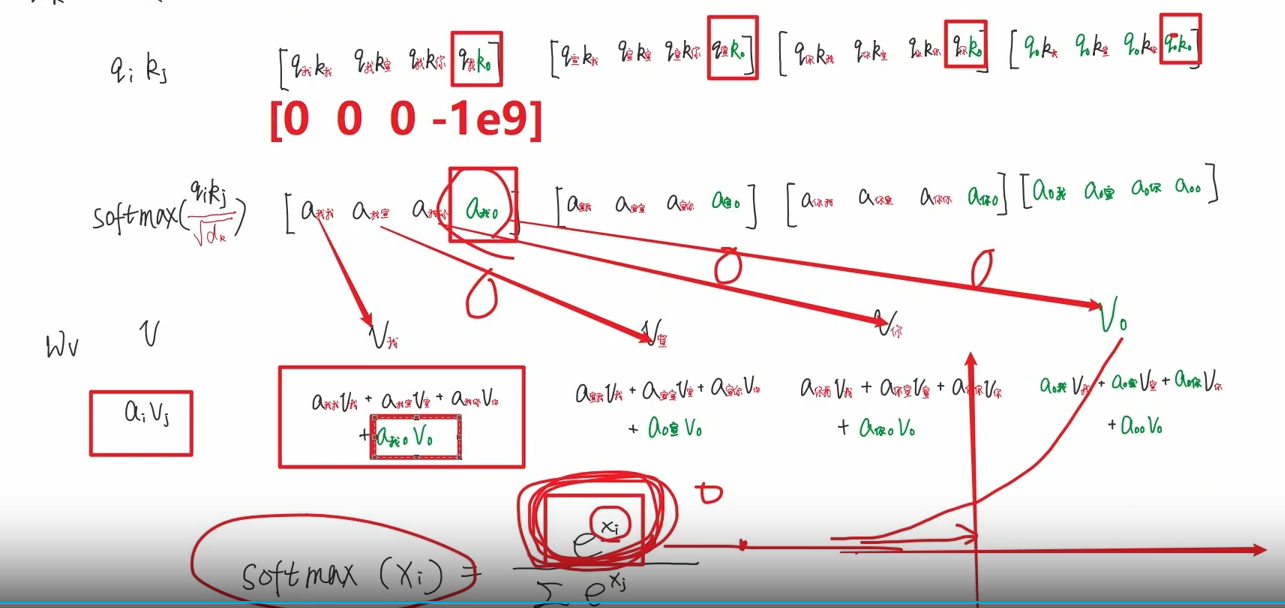
11【padding 掩码】消除padding的影响 具体就产生在softmax处

如果没有掩码 那绿色的0项目也会产生对应权重。
【add & norm】
add实际上是残差网络

这个add残差 就是 这个Inp输入经过多头注意力后 在与这个inp相加
作用:能使训练层数达到比较深的层次。
这里作者主要讲述了原因:(ps:以前自己只知道面上的作用,并不了解其原理)
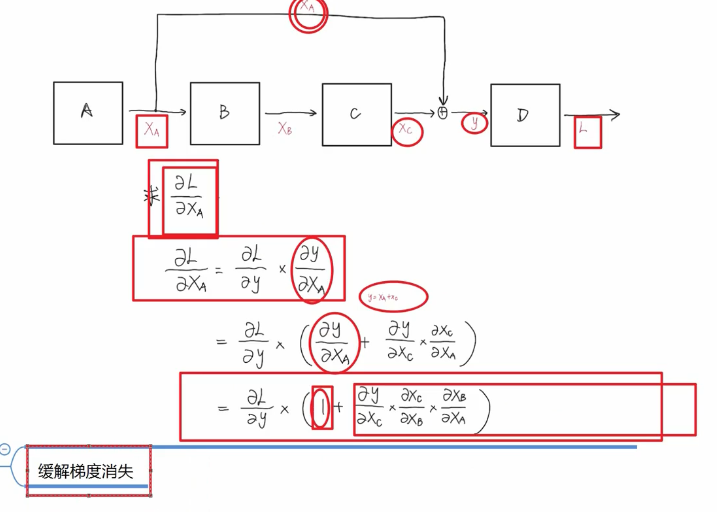
仔细看图中的1是哪来的,y=XA+XC所以  为1.
为1.
有了1这项保证,无论第二项怎么样 也不会造成梯度消失。
 这个视频有专门去讲
这个视频有专门去讲
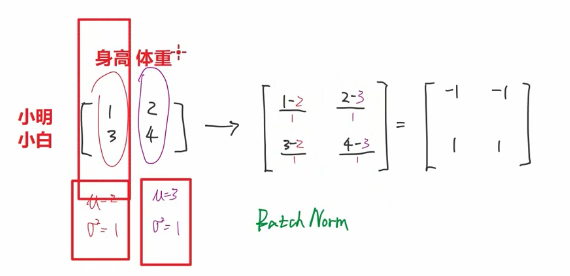
什么是batchnorm 对每个特征求一个均值 方差。对每个值减去均值 除以 标准差
什么是layernorm?
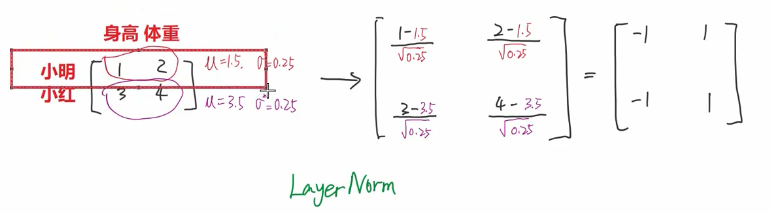
为什么用layernorm而不用batchnorm
首先最直观的原因是batchnorm在nlp领域效果不好

如图所示,你这个batchnorm加了padding项算出来的 肯定不好啊

【前馈神经网络】
其实就是两层全连接层
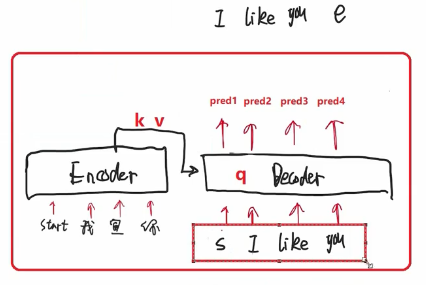
【decoder】
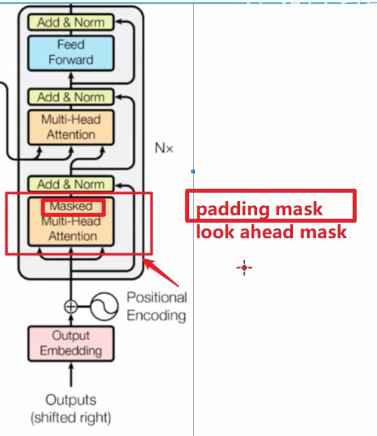

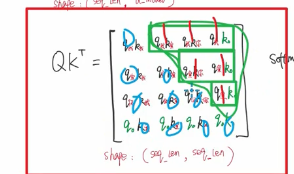
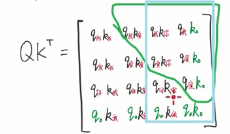
看一个并集 上三角是look ahead mask 矩形是padding mask
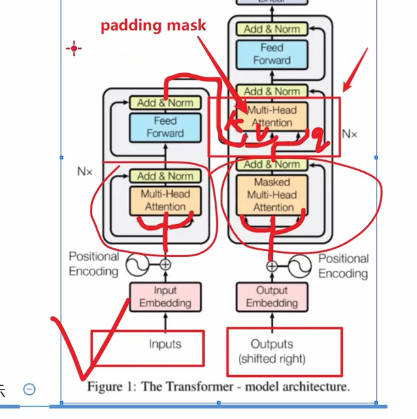
这个的多头注意力 是左边产生了 k v 右边decoder的产生了q
这里为什么没有Look ahead mask呢?
因为现在是decoder跟encoder进行交互
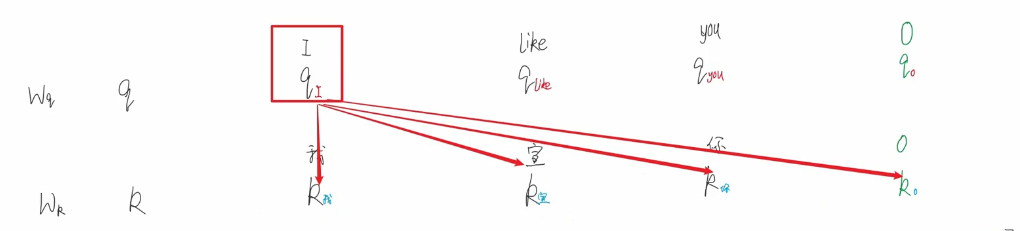
【linear层】隐藏神经元的个数是词表个数包含开头结尾
【损失函数】交叉熵损失
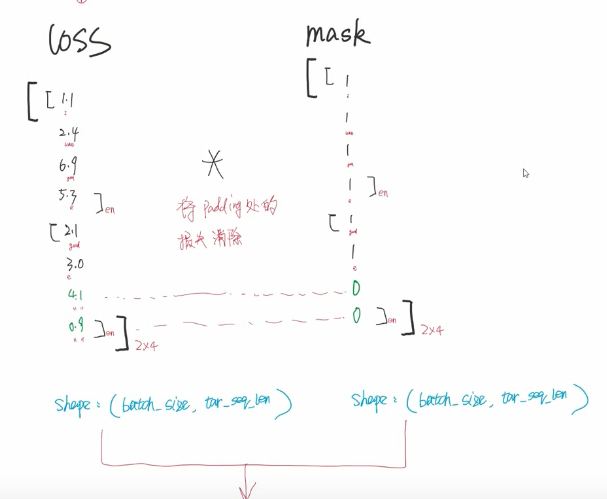
要有1 标签值 2消除padding项带来的影响。
注意此处的padding项 与以前的做法相反 此处是padding的置为0
准确的说是两项相乘。之前是相加是因为后边经过softmax
注意:
如果标签是one-hot就可以categoricalCrossentropy

如上图所示 右边的标签是个one hot的时候
注意这个交叉熵损失 解决了自己以前的一个困惑 就是每个字符都分类 得出一个序列的损失如何计算
查pytroch里边该是什么函数没查到啊 看起来像这个?
nn.MultiMarginLoss https://blog.csdn.net/weixin_43687366/article/details/107927693?utm_medium=distribute.pc_relevant.none-task-blog-2~default~baidujs_baidulandingword~default-1.pc_relevant_default&spm=1001.2101.3001.4242.2&utm_relevant_index=4
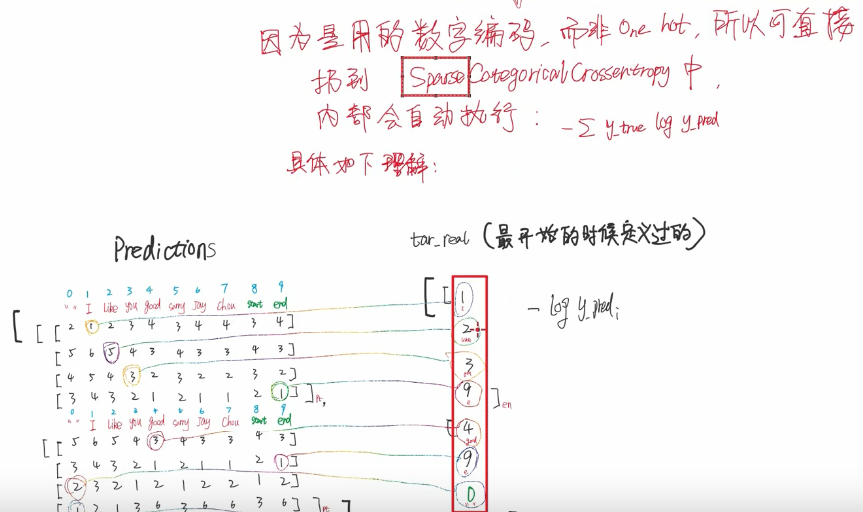
(这里他说 进来的predi是个概率值 那yi是个什么东西 是1?不能吧)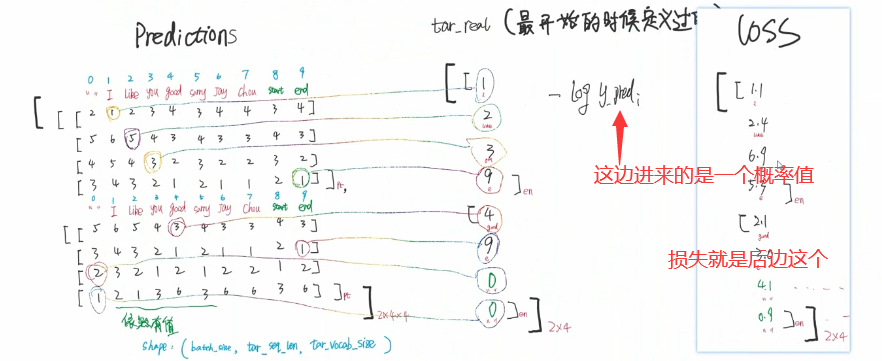
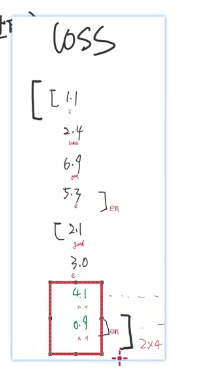 要把绿色产生的损失消除掉 因为是填充的 准不准的无所谓
要把绿色产生的损失消除掉 因为是填充的 准不准的无所谓
然后对这个loss求一个平均的损失

【自定义学习率】


 浙公网安备 33010602011771号
浙公网安备 33010602011771号