关于对话状态跟踪(DST)【转载以学习、回忆】
转载链接:https://mp.weixin.qq.com/s/X5nq0YDSSSpTl4cyWln5dw
方式一:具有预定义的槽名称和值,每一轮DST模块试图根据对话历史找到最合适的槽值对。
看成是一个multi-class或者multi-hop classification任务。
multi-class任务
做法:tracker每次读取所有槽值对,进行多分类预测
缺点:但是当value增大时,相当于模型预测的class的类别增大,那么就会增大模型的复杂度。
multi-hop classification 任务
做法:tracker每一次只读取一个槽值对,并执行二分类预测,
缺点:这种方式降低了模型的复杂度,但是提高了系统的时间复杂度
下面举例说明具有预定义的槽名称和值的DST过程。

本文转载DST部分介绍一个经典的NBT模型和一个比较复杂的TRADE模型
NBT模型:Neural belief tracker: Data-driven dialogue state tracking ACL2017。属于multi-hop classification任务。
模型遍历某个领域内每一个(slove,value)对,以判断用户真实意图中包含该slot-value对的概率大小。例如上图中的Domain Ontology存在三个可能的slot-value对,分别是(food, Indian), (food, Persian), (food, Czech),假设当前遍历到了(food, Persian)这个取值,通过表征模型可以得到它的表征c,再通过图中所示的流程,最后可以得到一个结果y,这个结果便表明了(food, Persian)这个slot-value对属于用户真实意图的可能性大小。
方式二:没有固定的槽值列表,因此DST模块尝试直接从对话上下文中查找值或根据对话上下文生成值。
TRADE(可转移的对话装填发生器)属于方式二的这种DST模型。
DST的目标是提取对话过程中表达的用户目标/意图,并将其编码为一组紧凑的对话状态,即一组slot-value对。
传统的状态跟踪方法基于本体预先定义的假设,其中所有槽及槽值都是已知的。拥有一个预定义的本体可以将DST简化为一个分类问题并提高性能。
然而这种方法主要有两个缺点:
1)在工业界,一个完整的本体很难提前获得
2)即使存在一个完整的本体,可能的槽值数量也可能很大,而且是可变的。例如,餐厅名称或火车出发时间可以包含大量可能的值。因此,以往许多基于神经分类模型的工作可能不适于实际场景。
转载以学习、回忆
转载链接:https://mp.weixin.qq.com/s/auqlefDTGhGIIM3Kp7JqPQ
参考论文2:面向任务的对话系统的可转移多域状态生成器
对领域本体的过度依赖和跨域知识共享的缺乏是对话状态追踪的两个 实际存在但是很少研究的问题。现有方法通常无法在推理过程中追踪未知槽值,并且在适应新领域时通常会遇到困难。为了处理这些新的挑战,本文认为DST模型在追踪的过程中需要能够在领域之间共享知识,以便更好地处理领域之间共享槽值的槽位。同时,领域之间的知识迁移对于追踪未知领域中的槽位也同样十分必腰。在本文中,作者提出了一种可迁移的对话状态生成器(TRADE),利用复制机制从对话文本生成对话状态,从而预测训练期间遇到的(领域、槽位、槽值)三元组时促进知识转移。该模型由编码器,槽位门和状态生成器组成。它们在不同领域之间共享。实证结果表明,对于人与人对话数据集MultiWOZ的五个域,TRADE的最新联合目标准确度达到48.62%。此外,通过zero -shot和few-shot对话状态追踪(没有出现过的领域)来显示其迁移能力。TRADE在zero -shot中达到了60.58%的联合目标精度,并且能够适应few-shot的情况而不会忘记已经训练过的领域。
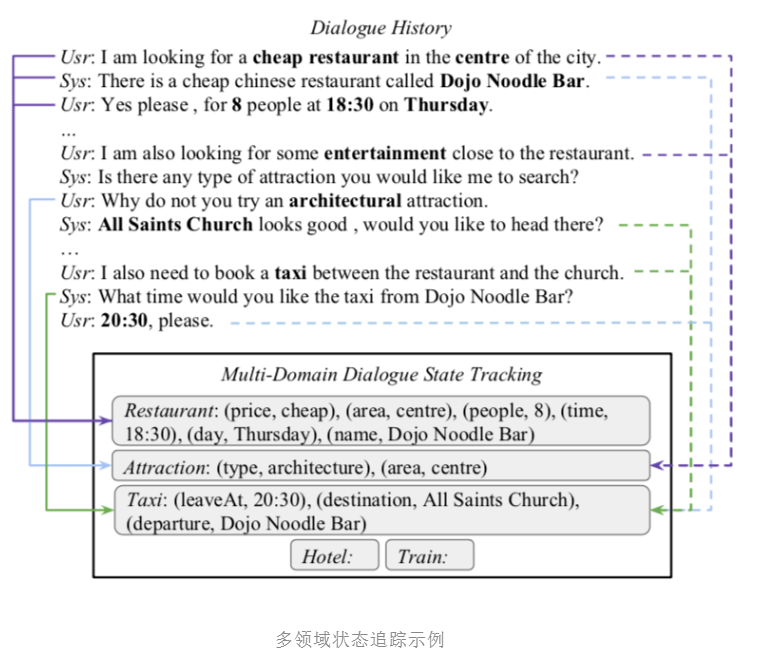
图是作者给的一个例子,该对话涉及到三个不同的领域,而且领域之间有槽位共享。
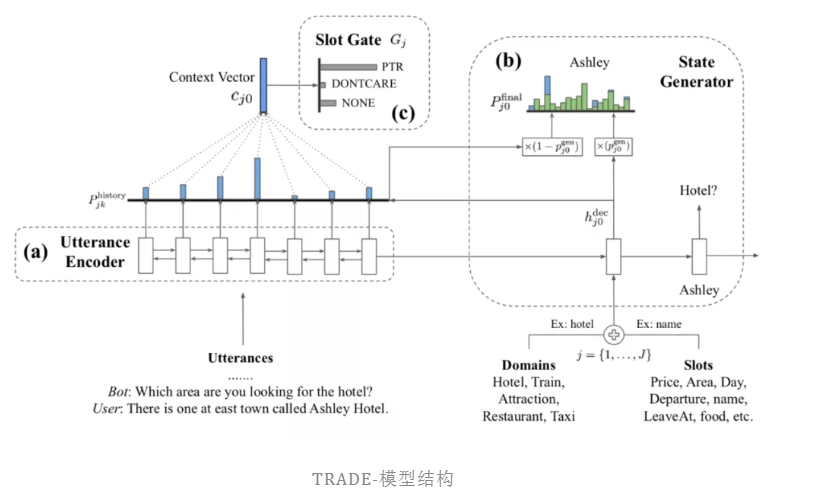
模型结构如下,主要分成三个部分,下面一一介绍:
我们这里先定义一下符号,
![]()
表示T轮内用户和系统的聊天信息,![]() 表示每一轮的对话状态,
表示每一轮的对话状态,![]() 表示三元组(领域Dn,槽位Sm,槽值
表示三元组(领域Dn,槽位Sm,槽值![]() ),
),![]() 表示所有的领域,
表示所有的领域,![]() 表示不同的槽位,假定有J个(领域、槽位)对,
表示不同的槽位,假定有J个(领域、槽位)对,![]() 为第J个领域-槽位对的值,
为第J个领域-槽位对的值,
1)首先是utterance encoder,和上面的一样,需要对文本信息进行编码,作者使用了gru编码(这个其实用transformer编码可能更好),这个地方就很简单了,在Ⅰ轮以内,将所有的信息拼接在一起。生成每个词的向量表示![]()
2)然后是State Generator(状态生成器),生成器这部分,也是使用了GRU作为其基本模型,基本过程如上图右半部分,选择J个对里面的一个domain-slot对,对其向量化,然后向佳,当作gru的第一输入,然后依次将词向量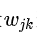 当作gru的输入,得出
当作gru的输入,得出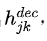 ,整体如下:
,整体如下:
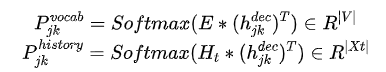
3)最后就是 Slot Gate ,这个地方其实就是一个很简单的3分类器,把映射成这个三个类别ptr(有相关的槽位), none(没有)和 dontcare (不关心),对于第二部生成的槽位值,如果slot gate判断是none和dontcare时,则会抛弃该值,因此这里其实就是相对于一个控制门。
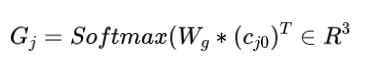
最终的是要优化State Generator和 Slot Gate,前者使用如下方式
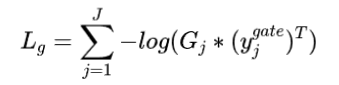
后者使用如下方式,都是交叉熵,只不过维度不一样

最后,毫无疑问,将两个损失函数相加:
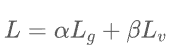
整个过程还是比较容易理解的,比较重要的是State Generator这部分,这个过程是一个解码的过程,并且将解码的向量映射到整个词向量上,可以解决未见词的问题。
为了验证模型的迁移能力,分别针对对话领域设定zero-shot和few-show两种场景。在zero-shot设定下,训练集中不包含目标领域的训练样本。假设源领域和目标领域具有相同的槽位,而训练集仅包含源领域的训练样本。
当输入目标领域和对应槽位时,模型应当可以输出通过源领域学习到的槽值序列。few-shot设定考察模型在目标领域只有极少量样本的情况下,从已知领域迁移学习到的知识到目标领域的能力。由于模型迁移到新领域时,在使用新领域样本进行fine-tune时,可能存在灾难性遗忘的问题(源领域所学习到的知识被遗忘),few-shot场景所检测的实际是模型在新领域只有少量样本且只能利用目标领域样本进行fine-tune的情况下,对于已学习到的知识进行保留和迁移的能力。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号