Java中四个常用集合的区别
 Java中四个常用集合的区别
ArrayList
HashSet
LinkedList
HashMap
Java中四个常用集合的区别
ArrayList
HashSet
LinkedList
HashMap
Java中四个常用集合的区别
ArrayList
ArrayList<泛型:集合中所有元素的统一类型> 自定义集合名称 = new ArrayList<从JDK1.7开始,右侧尖括号内可以省略不写>();
左右尖括号内填写相同的数据类型,且不可以是基础类型
- 集合长度可以随意改变;
- ArrayList集合打印的是内容,不是地址值,如果内容为空,就打印“[]”;
| 方法摘要 | |
|---|---|
boolean |
add(E e) 将指定的元素添加到此列表的尾部。 |
void |
add)(int index, E element) 将指定的元素插入此列表中的指定位置。 |
boolean |
addAll(Collection<? extends E> c) 按照指定 collection 的迭代器所返回的元素顺序,将该 collection 中的所有元素添加到此列表的尾部。 |
boolean |
addAll(int index, Collection<? extends E> c) 从指定的位置开始,将指定 collection 中的所有元素插入到此列表中。 |
void |
clear() 移除此列表中的所有元素。 |
Object |
clone() 返回此 ArrayList 实例的浅表副本。 |
boolean |
contains(Object o) 如果此列表中包含指定的元素,则返回 true。 |
void |
ensureCapacity(int minCapacity) 如有必要,增加此 ArrayList 实例的容量,以确保它至少能够容纳最小容量参数所指定的元素数。 |
E |
get(int index) 返回此列表中指定位置上的元素。 |
int |
indexOf(Object o) 返回此列表中首次出现的指定元素的索引,或如果此列表不包含元素,则返回 -1。 |
boolean |
isEmpty() 如果此列表中没有元素,则返回 true |
int |
lastIndexOf(Object o) 返回此列表中最后一次出现的指定元素的索引,或如果此列表不包含索引,则返回 -1。 |
E |
remove(int index) 移除此列表中指定位置上的元素。 |
boolean |
remove(Object o) 移除此列表中首次出现的指定元素(如果存在)。 |
protected void |
removeRange(int fromIndex, int toIndex) 移除列表中索引在 fromIndex(包括)和 toIndex(不包括)之间的所有元素。 |
E |
set(int index, E element) 用指定的元素替代此列表中指定位置上的元素。 |
int |
size() 返回此列表中的元素数。 |
Object[] |
toArray() 按适当顺序(从第一个到最后一个元素)返回包含此列表中所有元素的数组。 |
<T> T[] |
toArray(T[] a) 按适当顺序(从第一个到最后一个元素)返回包含此列表中所有元素的数组;返回数组的运行时类型是指定数组的运行时类型。 |
void |
trimToSize() 将此 ArrayList 实例的容量调整为列表的当前大小。 |
ArrayList中常用的几个方法
public boolean add(E e);//向集合中添加元素,参数的类型和泛型一致,返回值是true/false
public E get(int index);//从集合中获取元素,参数是索引编号,返回值是对应位置的元素
public E remove(int index);//从集合当中删除元素,参数是索引编号,返回值就是被删除的元素
public int size();//获取结合的长度,返回值就是集合中元素的个数
创建list集合→添加元素→遍历打印list集合
import java.util.ArrayList;
public class ArrayListMethod {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
list.add("①");
list.add("②");
list.add("③");
list.add("④");
list.add("⑤");//添加元素
System.out.println(list.get(4));//获取元素
list.remove(1);//移除元素
System.out.println("*************************");
//遍历集合并打印
for (int i = 0; i < list.size(); i++) {
System.out.println(list.get(i));
}
}
}
运行结果:
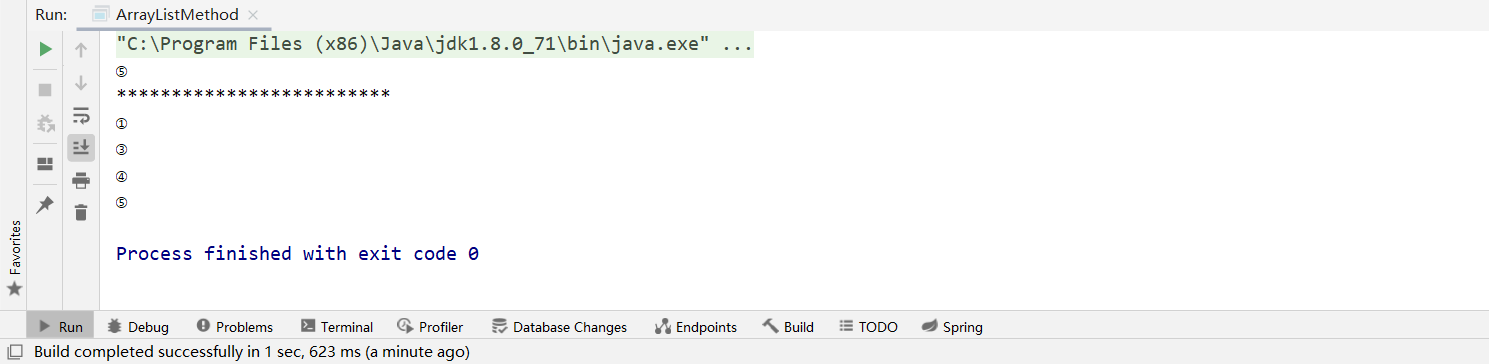
为什么ArrayList集合中泛型不能是基础类型?→→→→→因为集合中保存的都是地址值,由于基本类型没有地址值,所以就泛型就不能填基本类型(byte,short,int,long,float,double,char,boolean),
但是,泛型可以是每种基本类型的对应的包装类
| 基本数据类型 | 对应的包装类 |
|---|---|
| byte | Byte |
| short | Short |
| int | Integer |
| long | Long |
| char | Character |
| float | Float |
| double | Double |
| boolean | Boolean |
byte→Byte
short→Short
int→Integer
long→Long
flaot→Float
double→Double
char→Character
boolean→Boolean
注意:创建新集合时,用基本类型的包装类,而获取集合中的元素时,接收的数据类型就用基本类型就行。因为基本数据类型与它们对应的包装类之间可以自动装箱和自动拆箱(即可以自动转换)
- 自动装箱:基本数据类型→包装类型
- 自动拆箱:包装类型→基本数据类型
LinkedList
LinkedList集合是一个双向链表
特点:查询慢,增删快
不能使用多态
| 构造方法摘要 |
|---|
| LinkedList() 构造一个空列表。 |
| LinkedList(Collection<? extends E> c) 构造一个包含指定 collection 中的元素的列表,这些元素按其 collection 的迭代器返回的顺序排列。 |
| 方法摘要 | |
|---|---|
boolean |
add(E e) 将指定元素添加到此列表的结尾。 |
void |
[add](../../java/util/LinkedList.html#add(int, E))(int index, E element) 在此列表中指定的位置插入指定的元素。 |
boolean |
addAll(Collection<? extends E> c) 添加指定 collection 中的所有元素到此列表的结尾,顺序是指定 collection 的迭代器返回这些元素的顺序。 |
boolean |
[addAll](../../java/util/LinkedList.html#addAll(int, java.util.Collection))(int index, Collection<? extends E> c) 将指定 collection 中的所有元素从指定位置开始插入此列表。 |
void |
addFirst(E e) 将指定元素插入此列表的开头。 |
void |
addLast(E e) 将指定元素添加到此列表的结尾。 |
void |
clear() 从此列表中移除所有元素。 |
Object |
clone() 返回此 LinkedList 的浅表副本。 |
boolean |
contains(Object o) 如果此列表包含指定元素,则返回 true。 |
Iterator<E> |
descendingIterator() 返回以逆向顺序在此双端队列的元素上进行迭代的迭代器。 |
E |
element() 获取但不移除此列表的头(第一个元素)。 |
E |
get(int index) 返回此列表中指定位置处的元素。 |
E |
getFirst() 返回此列表的第一个元素。 |
E |
getLast() 返回此列表的最后一个元素。 |
int |
indexOf(Object o) 返回此列表中首次出现的指定元素的索引,如果此列表中不包含该元素,则返回 -1。 |
int |
lastIndexOf(Object o) 返回此列表中最后出现的指定元素的索引,如果此列表中不包含该元素,则返回 -1。 |
ListIterator<E> |
listIterator(int index) 返回此列表中的元素的列表迭代器(按适当顺序),从列表中指定位置开始。 |
boolean |
offer(E e) 将指定元素添加到此列表的末尾(最后一个元素)。 |
boolean |
offerFirst(E e) 在此列表的开头插入指定的元素。 |
boolean |
offerLast(E e) 在此列表末尾插入指定的元素。 |
E |
peek() 获取但不移除此列表的头(第一个元素)。 |
E |
peekFirst() 获取但不移除此列表的第一个元素;如果此列表为空,则返回 null。 |
E |
peekLast() 获取但不移除此列表的最后一个元素;如果此列表为空,则返回 null。 |
E |
poll() 获取并移除此列表的头(第一个元素) |
E |
pollFirst() 获取并移除此列表的第一个元素;如果此列表为空,则返回 null。 |
E |
pollLast() 获取并移除此列表的最后一个元素;如果此列表为空,则返回 null。 |
E |
pop() 从此列表所表示的堆栈处弹出一个元素。 |
void |
push(E e) 将元素推入此列表所表示的堆栈。 |
E |
remove() 获取并移除此列表的头(第一个元素)。 |
E |
remove(int index) 移除此列表中指定位置处的元素。 |
boolean |
remove(Object o) 从此列表中移除首次出现的指定元素(如果存在)。 |
E |
removeFirst() 移除并返回此列表的第一个元素。 |
boolean |
removeFirstOccurrence(Object o) 从此列表中移除第一次出现的指定元素(从头部到尾部遍历列表时)。 |
E |
removeLast() 移除并返回此列表的最后一个元素。 |
boolean |
removeLastOccurrence(Object o) 从此列表中移除最后一次出现的指定元素(从头部到尾部遍历列表时)。 |
E |
[set](../../java/util/LinkedList.html#set(int, E))(int index, E element) 将此列表中指定位置的元素替换为指定的元素。 |
int |
size() 返回此列表的元素数。 |
Object[] |
toArray() 返回以适当顺序(从第一个元素到最后一个元素)包含此列表中所有元素的数组。 |
<T> T[] |
toArray(T[] a) 返回以适当顺序(从第一个元素到最后一个元素)包含此列表中所有元素的数组;返回数组的运行时类型为指定数组的类型。 |
HashSet
特点:不允许存储重复元素,没有索引
或
Set集合存储元素不会重合的原理:

HashSet集合存储自定义元素
自定义存储元素类型文件:niuniu.java
import java.util.Objects;
public class niuniu {
private String name;
private int age;
private int height;
//重写equals方法
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
niuniu niuniu = (niuniu) o;
return age == niuniu.age && height == niuniu.height && Objects.equals(name, niuniu.name);
}
//重写hashCode方法
@Override
public int hashCode() {
return Objects.hash(name, age, height);
}
public niuniu() {
}
public niuniu(String name, int age, int height) {
this.name = name;
this.age = age;
this.height = height;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public int getHeight() {
return height;
}
public void setHeight(int height) {
this.height = height;
}
@Override
public String toString() {
return "niuniu{" +
"name='" + name + '\'' +
", age=" + age +
", height=" + height +
'}';
}
}
测试类文件:Demo01HashSet.java
import java.util.HashSet;
public class Demo01HashSet {
public static void main(String[] args) {
//创建一个集合用来存放等会儿添加的数据
HashSet<niuniu> niunius = new HashSet<>();
//存入数据
niunius.add(new niuniu("牛牛",18,180));
niunius.add(new niuniu("牛牛",18,180));
niunius.add(new niuniu("牛牛",19,190));
System.out.println(niunius);
}
}
运行结果:重写了equals方法和hashCode方法之后,就不会存储相同的元素了
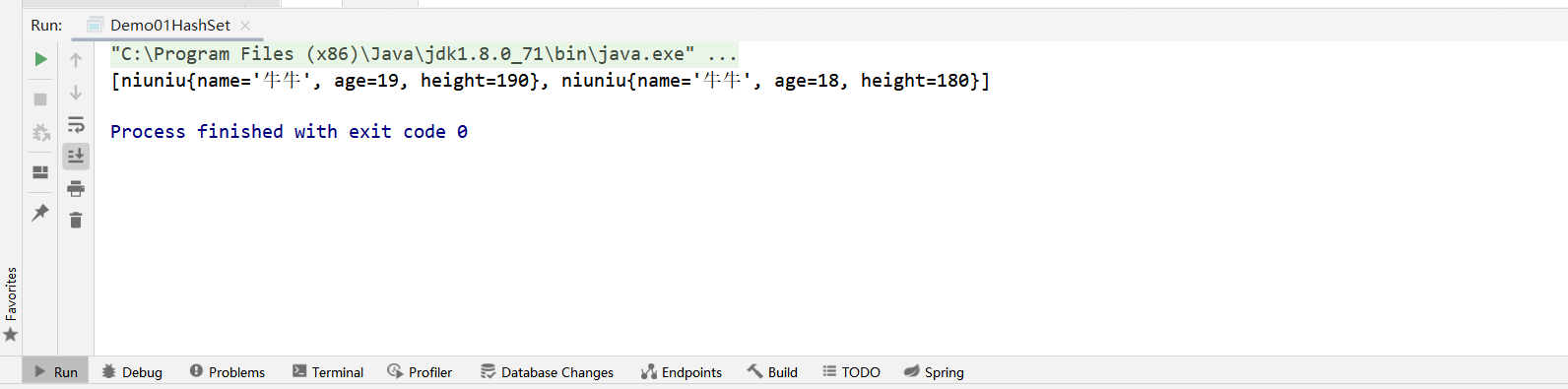
HashMap
先学Map集合
学前目标:
Map集合的特点
- Map集合是一个双列集合,每个元素包含两个值(key和value),即键值对
- 键值对跟数学里的映射关系一样,键和值一一对应,通过键就可以找到值
- (映射原理)一个键只能对应一个值,一个值可以有多个键
- (映射原理)可以有相同的值,但是不能有相同的键
Map接口中的常用方法
| 方法摘要 | |
|---|---|
void |
clear() 从此映射中移除所有映射关系(可选操作)。 |
boolean |
containsKey(Object key) 如果此映射包含指定键的映射关系,则返回 true。 |
boolean |
containsValue(Object value) 如果此映射将一个或多个键映射到指定值,则返回 true。 |
Set<Map.Entry<K,V>> |
entrySet() 返回此映射中包含的映射关系的 Set 视图。 |
boolean |
equals(Object o) 比较指定的对象与此映射是否相等。 |
V |
get(Object key) 返回指定键所映射的值;如果此映射不包含该键的映射关系,则返回 null。 |
int |
hashCode() 返回此映射的哈希码值。 |
boolean |
isEmpty() 如果此映射未包含键-值映射关系,则返回 true。 |
Set<K> |
keySet() 返回此映射中包含的键的 Set 视图。 |
V |
[put](../../java/util/Map.html#put(K, V))(K key, V value) 将指定的值与此映射中的指定键关联(可选操作)。 |
void |
putAll(Map<? extends K,? extends V> m) 从指定映射中将所有映射关系复制到此映射中(可选操作)。 |
V |
remove(Object key) 如果存在一个键的映射关系,则将其从此映射中移除(可选操作)。 |
int |
size() 返回此映射中的键-值映射关系数。 |
Collection<V> |
values() 返回此映射中包含的值的 Collection 视图。 |
常用:
- put(key,value);//给集合添加元素;
- remove(key);//移除映射关系,如果key存在,则返回与key对应的那个value;如果可以不存在,则返回null;
- get(key);//获取与key对应的value,如果key存在,则返回与key对应的那个value;如果可以不存在,则返回null;
- containsKey(key);//判断集合中是否包含此key,返回的值是boolean值(true/false)
遍历Map集合的两种方式:
-
键找值
使用keySet();方法,获取到Map集合中所有的key,然后把所有的key放到一个set集合中,然后遍历set集合就得到了每一个key,最后使用get(key);方法获取到对应的value
import java.util.HashMap; import java.util.Set; public class MapKeySet { public static void main(String[] args) { HashMap<Integer, String> map = new HashMap<>(); map.put(1,"牛1"); map.put(2,"牛2"); map.put(3,"牛3"); Set<Integer> set = map.keySet(); System.out.println(set); for (Integer integer : set) { String s = map.get(integer); System.out.println(integer+"="+s ); } } }运行结果:
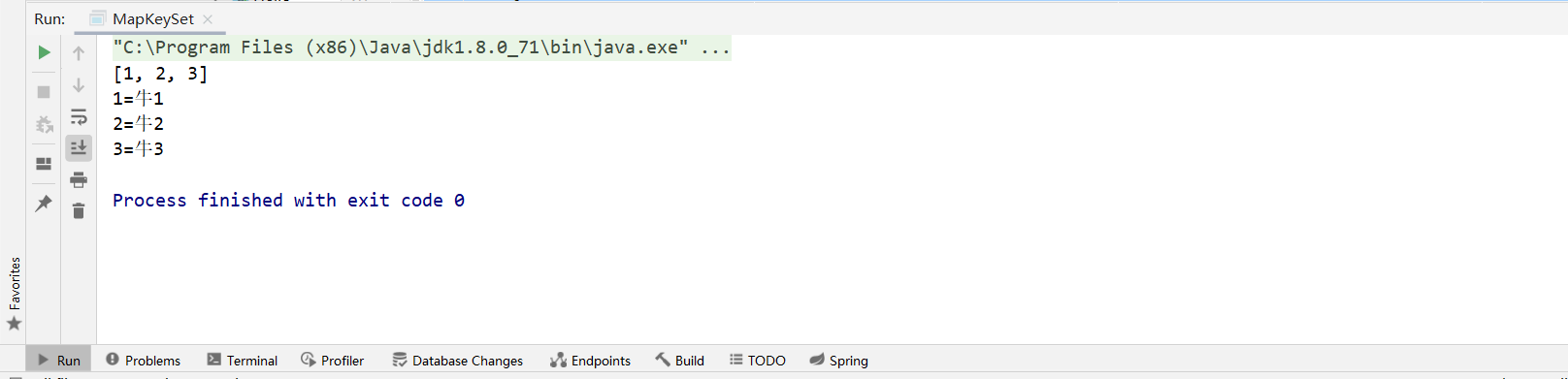
-
键-值对
在Map接口中有一个内部接口Entry--->Map.Entry<K,V>;
作用:当Map集合一创建,Map集合中就会生成一个Entry对象,用来记录键与值(键值对对象,键与值得映射关系)
所以想要遍历Map集合,就可以先用Set<Map.Entry<K,V> entrySet获取到Map集合中的每一个Entry对象,存储到一个Set集合中,然后遍历这个Set集合就得到了每一个Entry对象,然后引用Entry对象中的两个方法:getKey();和getValue();得到key和value
import java.util.HashMap; import java.util.Iterator; import java.util.Map; import java.util.Set; public class MapKeySet { public static void main(String[] args) { HashMap<Integer, String> map = new HashMap<>(); map.put(4,"牛4"); map.put(5,"牛5"); map.put(6,"牛6"); Set<Map.Entry<Integer, String>> entrySet = map.entrySet(); //使用增强for遍历集合 for (Map.Entry<Integer, String> integerStringEntry : entrySet) { Integer key = integerStringEntry.getKey(); String value = integerStringEntry.getValue(); System.out.println(key+"="+value); } System.out.println("=========================="); //使用迭代器遍历集合 Iterator<Map.Entry<Integer, String>> iterator = entrySet.iterator(); while (iterator.hasNext()){ Map.Entry<Integer, String> it = iterator.next(); System.out.println(it.getKey()+"="+it.getValue()); } } }运行结果:
//重写equals方法 @Override public boolean equals(Object o) { if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; niuniu niuniu = (niuniu) o; return age == niuniu.age && height == niuniu.height && Objects.equals(name, niuniu.name); } //重写hashCode方法 @Override public int hashCode() { return Objects.hash(name, age, height); }
Map的常用子类
-
HashMap<K,V>
-
LinkedHashMap<K,V>
HashMap存储自定义类型键与值
自定义类型键:niuniu.java
import java.util.Objects;
public class niuniu {
private String name;
private int age;
private int height;
//重写equals方法
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
niuniu niuniu = (niuniu) o;
return age == niuniu.age && height == niuniu.height && Objects.equals(name, niuniu.name);
}
//重写hashCode方法
@Override
public int hashCode() {
return Objects.hash(name, age, height);
}
public niuniu() {
}
public niuniu(String name, int age, int height) {
this.name = name;
this.age = age;
this.height = height;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public int getHeight() {
return height;
}
public void setHeight(int height) {
this.height = height;
}
@Override
public String toString() {
return "niuniu{" +
"name='" + name + '\'' +
", age=" + age +
", height=" + height +
'}';
}
}
注意:自定义的类作为键key的时候,一定要重写equals方法和hashCode方法,位的就是保证键是唯一的,不能重复
LinkedHashMap<K,V>
是一个有序集合
底层原理是--哈希表+链表(记录元素顺序)
import java.util.HashMap;
import java.util.LinkedHashMap;
public class LinkedHasnMapClass {
public static void main(String[] args) {
HashMap<String, String> hashMap = new HashMap<>();
LinkedHashMap<String, String> linkedHashMap = new LinkedHashMap<>();
hashMap.put("a","a");
hashMap.put("d","d");
hashMap.put("e","e");
hashMap.put("b","b");
hashMap.put("c","c");
hashMap.put("a","f");
System.out.println(hashMap);//结果表示hashmap集合是无序且key不重复的集合
linkedHashMap.put("a","a");
linkedHashMap.put("d","d");
linkedHashMap.put("e","e");
linkedHashMap.put("b","b");
linkedHashMap.put("c","c");
linkedHashMap.put("a","f");
System.out.println(linkedHashMap);//结果表示linkedHashMap集合是有序且key不重复的集合
}
}
运行结果:
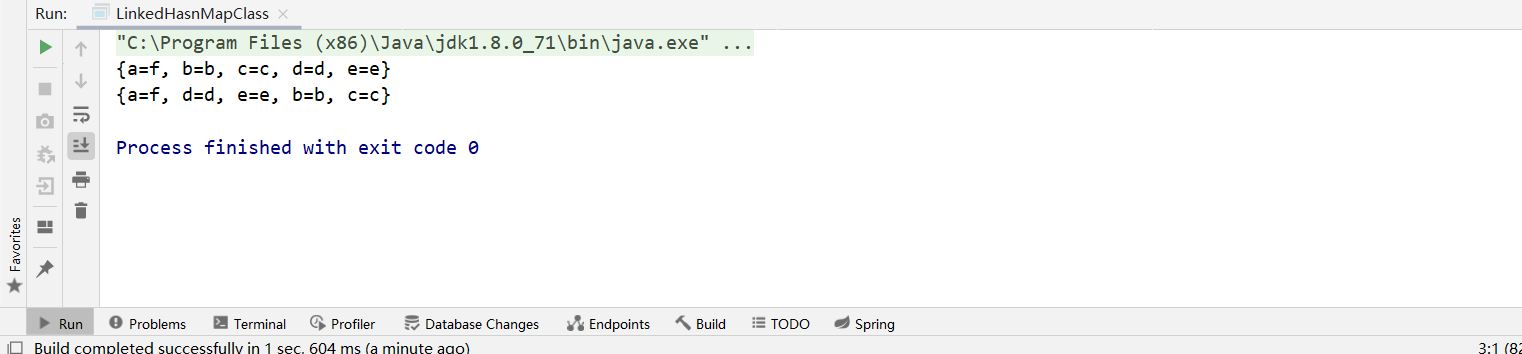
练习
HashMap编写斗地主洗牌发牌案例
import java.util.ArrayList;
import java.util.Collections;
import java.util.HashMap;
import java.util.List;
public class PokerCard {
public static void main(String[] args) {
//1.准备牌
//创建一个Map集合,存储扑克牌的索引和组装好的扑克牌
HashMap<Integer, String> map = new HashMap<>();
//创建一个List集合来存储扑克牌的索引,方便之后对扑克牌进行洗牌操作(操作索引)
ArrayList<Integer> pokerIndex = new ArrayList<>();
//定义两个List集合,用来存储扑克牌的而花色和序号
List<String> kind = List.of("♥", "♠", "♦", "♣");
List<String> number = List.of("3", "4", "5", "6", "7", "8", "9", "10", "J", "Q", "K", "A", "2");
//把大王和小王存储到集合中
//初始化索引为0
int index = 0;
map.put(index,"大王");
pokerIndex.add(index);
index++;
map.put(index,"小王");
pokerIndex.add(index);
index++;
//组装两个集合的数据,生成带花色的52张牌(可以用普通for循环,也可以用增强for循环foreach)
for (String num : number) {
for (String k : kind) {
map.put(index,k+num);
pokerIndex.add(index);
index++;
}
}
// System.out.println(map);//打印扑克牌集合
//2.洗牌
Collections.shuffle(pokerIndex);
System.out.println(pokerIndex);
//发牌
//定义4个集合,分别存储3个玩家的牌和3张底牌
ArrayList<Integer> player1 = new ArrayList<>();
ArrayList<Integer> player2 = new ArrayList<>();
ArrayList<Integer> player3 = new ArrayList<>();
ArrayList<Integer> bottoms = new ArrayList<>();
//遍历存放扑克牌索引的list集合,获取每一张牌的索引
for (int i = 0; i < pokerIndex.size(); i++) {
Integer integer = pokerIndex.get(i);
if (i>=51){
//发牌给底牌
bottoms.add(integer);
}else if (i%3==0){
//发牌给玩家1
player1.add(integer);
}
else if (i%3==1){
//发牌给玩家1
player2.add(integer);
}
else if (i%3==2){
//发牌给玩家1
player3.add(integer);
}
}
//4.排序
Collections.sort(player1);
Collections.sort(player2);
Collections.sort(player3);
Collections.sort(bottoms);//默认升序排序
//5.看牌
seePoker("player1",map,player1);
seePoker("player2",map,player2);
seePoker("player3",map,player3);
seePoker("bottoms",map,bottoms);
System.out.println("---------------");
lookPoker("player1",map,player1);
lookPoker("player2",map,player2);
lookPoker("player3",map,player3);
lookPoker("bottoms",map,bottoms);
}
//在主函数外定义一个方法用来看牌,提高代码的复用性
/*
* 参数:
* String name;玩家名称
* HashMap<Integer, String> map 存储扑克牌的集合
* ArrayList<Integer> list 存储玩家牌和底牌的list集合
*查表法:
* 遍历玩家牌或底牌集合,获取扑克牌索引
* 使用索引区装所有扑克牌的map集合中找到对应的扑克牌
*
* */
public static void seePoker(String name,HashMap<Integer,String> pokerMap,ArrayList<Integer> list){
//输出玩家名称,不换行
System.out.print(name+":");
//遍历传入该方法的扑克牌索引集合,即分别存储3个玩家的牌和3张底牌List集合,获取扑克牌索引
for (Integer key : list) {
//使用索引区装所有扑克牌的map集合中找到对应的扑克牌
String value = pokerMap.get(key);
System.out.print(value+" ");
}
System.out.println();//换行
}
//或者定义一个方法,打印玩家的牌和底牌的集合
public static void lookPoker(String name,HashMap<Integer,String> pokerMap,ArrayList<Integer> list){
//输出玩家名称,不换行
System.out.print(name+":");
ArrayList<String> arrayList = new ArrayList<>();
//遍历传入该方法的扑克牌索引集合,即分别存储3个玩家的牌和3张底牌List集合,获取扑克牌索引
for (Integer key : list) {
//使用索引区装所有扑克牌的map集合中找到对应的扑克牌
String value = pokerMap.get(key);
arrayList.add(value);
}
System.out.println(arrayList);
}
}
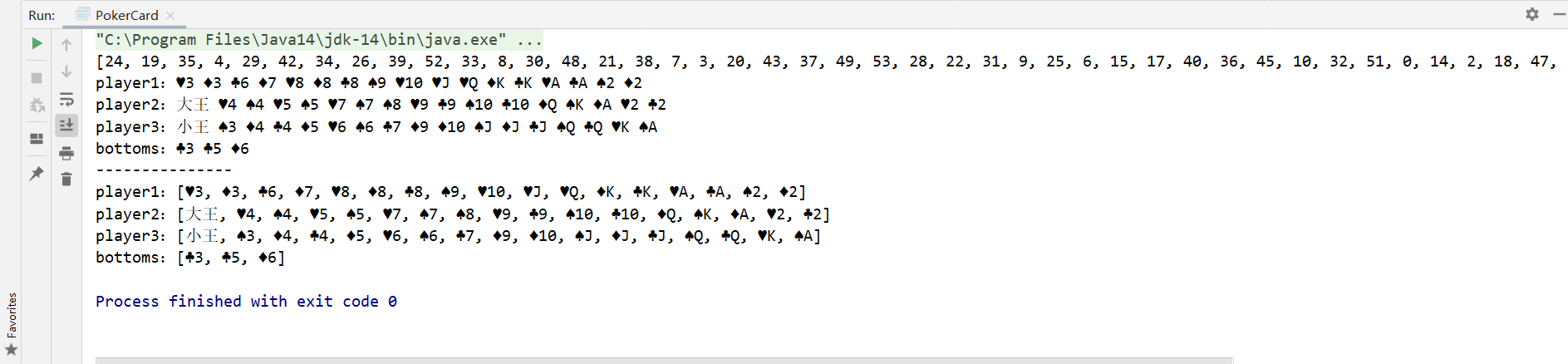
运行结果:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号