深入掌握service
【service的四种类型】
ClusterIP:集群内部使用
NodePort:对外暴露应用(集群外)
LoadBalancer: 对外暴露应用,适用公有云
ExternalName:映射一个外部域名地址
说明:
clusterip:默认,分配一个稳定ip,只能在集群内部访问
nodeport:在每个节点上启用一个端口来暴露服务,可以在集群
外部访问,也会分配一个稳定内部集群ip地址
访问地址:任意nodeip(也就是通过任何节点的ip都可以访问)
端口范围:30000-32767
会在每一台node上监听端口接受用户流量,对用户暴露的只有一个ip和端口,太多
node可以给用户使用,所以要在前面加一个公网负载均衡器提供统一访问。
loadbalancer:与nodeport类似,在每个节点上启用一个端口来暴露服务。除此之外
kubernetes会请求底层云平台上的负载均衡器,将node(【nodeip】:【nodeport】)作为后端添加进去
简单点说,loadbalancer和nodeport差不多,只是loadbalancer在创建的时候,会云服务商从自动创建一个
负载均衡器。
ExternalName:类型服务用于将集群外部的服务定义为kubernetes的service,并且通过externalName设置外部服务的访问地址,
servcie不仅具有标准的网络协议ip地址,还以dns域名的形式存在,service域名的表示方法为
[servicename].[namespace].svc.[clusterdomain]
servicename是service名称,namespace是命名空间的名称,clusterdomain是kubernetes集群设置的域名后缀。
默认的域名后缀是cluster.local
【service的负载均衡机制】
当一个service对象在kubernetes中被定义出来的时候,从服务ip到后端pod的负载均衡机制就是由,每个node上的kube-proxy负责实现的。
1,kube-proxy的代理模式,分别有userspace和iptables和ipvs。
userspace是用户空间模式,由kube-proxy完成代理的实现,效率最低,不推荐使用。
iptables模式,kube-proxy通过设置linux kernel的iptables规则,实现从service到后端endpoint列表的负载分发规则,效率很高,但是如果某个后端的endpoint错误不可用的时候,客户端的请求还是被转发到了这个endpoint,那此次的客户端请求就会失败,相对于userspace来说更不可靠。
ipvs模式,在kubernetes1.11版本当中达到stable阶段,kube-proxy通过设置linux Kernel的netlink接口设置IPVS规则,转发效率和支持的吞吐率都是最高的。ipvs模式要求linux kernel启用ipvs模块,如果操作系统没有ipvs内核模块,kube-proxy则会自动切换至iptables模式。同时ipvs模式支持更多的负载均衡策略。
2,会话保持机制
即客户机源ip发起的请求转发到后端的某个pod上,之后从相同的客户端ip发起的请求都将被转发到相同的后端pod上,给service配置sessionAffinity实现。
apiVersion: v1
kind: Service
metadata:
name: service-new-test
spec:
sessionAffinity: ClientIP #这个的值可以是None或者ClientIP
sessionAffinityConfig: #这下面可以不设置
clientIP:
timeoutSeconds: 10800 #这里用于设置用户会话能保持的最长时间,在此之后重置客户端来源IP的保持规则。
ports:
- port: 2001
tarport: 2001
protocol: TCP
selector:
app: servicew-new
seeionAffinity的值说明:
None为随机分配,clientIP则是按照上一次的调度的pod进行调度
【service多端口设置】
1,在同一个service中可以通过设置不同的端口号达到一个service使用多个端口分别来提供不同的服务
例如:
apiVersion: v1
kind: Service
metadata:
name: service-new-test
spec:
ports:
- port: 2001
tarport: 2001
name: web
- port: 2002
tarport: 2002
name: menagement
selector:
app: servicew-new
2,或者设置不同的协议来达到同一个端口不同协议来提供不同的服务。
例如:
apiVersion: v1
kind: Service
metadata:
name: service-new-test
spec:
ports:
- port: 2001
protocol: TCP
name: web
- port: 2002
protocol: UDP
name: menagement
selector:
app: servicew-new
【将外部服务定义为service】
在普通的service中通常是通过label Selector来和后端的endpoints相匹配,然后将客户机的请求通过service和endpoint转发到pod副本集群。但是service还可以自定义其他的任意服务,所以可以是外部服务。也就是要自定义一个endpoints,然后在这个endpoints中自定义着外部服务的ip和端口号。
例如:
---
apiVersion: v1
kind: Service
metadata:
name: service
spec:
ports:
- port: 3001
protocol: TCP
targetPort: 3001
---
apiVersion: v1
kind: Endpoints
metadata:
name: my-service
subsets:
- addresses:
- IP: [外部服务ip]
ports:
- port: [外部服务端口]
如上所示,没有标签选择器的service,请求被路由到由用户指定的后端endpoint上,这个外部服务可以是另一个k8s集群,或者是数据库服务,缓存服务等。
【将service服务暴露到外部集群】
上面讲到过service的四种模式,只有三种类型是可以供给外部访问的。
nodeport:
设置为nodeport可以将内部pod副本集暴露给外部集群,通过k8s的主机地址加nodeport设置端口号进行访问。
apiVersion: v1
kind: Service
metadata:
name: service
spec:
type: NodePort
ports:
- port: 3001
protocol: TCP
nodePort: 30001 #设置访问的端口号
selector:
app: mysql #设置标签对应内部pod副本集
loadbalancer:
将service映射到共有云的某个负载均衡器上,客户端通过负载均衡器的ip和service端口就可以访问到具体的服务。
例如:
apiVersion: v1
kind: Service
metadata:
name: service
spec:
type: LoadBalancer
ports:
- port: 3001
protocol: TCP
targetPort: 3001
clusterIP: [设定clusterip]
selector:
app: mysql #设置标签对应内部pod副本集
然后在服务创建成功之后,云服务运营商会在service的定义补充LoadBalancer的ip地址字段。
status:
loadBalancer:
ingress:
- ip: 192.168.2.127
ExternalName:
externalname类型的服务用于集群外的服务定义为kubernetes集群内的service,并且通过externalname字段指定外部服务器的地址。可以使用域名或者ip格式。集群内部的客户端通过访问这个service就能访问外部服务了。这种类型的service没有后端pod,所以不用设置标签选择器。
例如:
apiVersion: v1
kind: Service
metadata:
name: service
spec:
type: ExternalName
externalName: www.baidu.com
这样集群内客户端访问service的域名即可(因为没有clusterip),系统将自动指向外部域名。
service.default.svc.cluster.local
我们还可以通过ingress将服务暴露到外部集群。
【service支持的网络协议和服务发现机制】
网络协议
目前service支持的网络协议如下:
TCP:service的默认网络协议,可以用于所有类型的service
UDP: 可以用于大多数service,loadbalancer类型取决于云服务商对UDP的支持。
HTTP:取决于云服务上是否支持HTTP和实现机制。
PROXY:取决于云服务商是否支持HTTP和实现机制。
SCTP:默认启用,如果需要关闭需要设置kube-apiserver启动参数--feature-gates=SCTPSupport=false
服务发现机制
1,环境变量方式
在一个pod运行起来的时候,系统会自动为其容器运行环境注入所有集群中有效的service信息,信息包括服务ip,服务端口号,各端口号相关协议等。创建一个新的pod,就可以看到环境自动设置的环境变量。然后客户端就能够根据service相关的环境变量的命名规则,直接访问目标服务地址。
2,DNS方式
service在k8s遵循dns命名规范,service的域名表示方法为[servicename].[namespace].svc.[clusterdomain],但是如果service中定义了端口号名称name,则该端口号也会有一个域名,在dns服务器中以ser记录的格式保存:_[portname]._[ptoyovol].[servicename].[namespace].svc.[clusterdomain]
这个也可以被解析到
【Headless Service的应用】
headless service的概念即这用服务没有入口的访问地址,(无clusterip地址),kube-proxy不会为其创建负载转发规则,而服务名(DNS域名)的解析机制取决于改headless service设置了labels selector标签选择器。
如果这个headless service有匹配到相应的服务,那会自动创建后端的endpoints,查看endpoint可以发现,k8s系统分配的endpoints的列表。
【端点分片和服务拓扑】
service的后端是一组endpoints列表,为客户端提供了极大的便利。但是随着集群规模的扩大和service数量的增加,kube-proxy需要维护的负载分发规则(例如iptables和ipvs规则的数量也会急剧增加),导致service后端endpoint的不断增加,导致更新操作的成本急剧上升。
假如10000和endpoint大约位于5000个node上,则对单个pod的更新就要大约5G的数据传输,不仅十分浪费带宽,而且会影响集群的整体性能,在deployment不断更新的情况下尤为突出。所以kubernetes从1.6开始引入endpoint slice端点分段机制,包括一个新的endpointslice资源对象和一个新的endpointslice控制器。
endpointslice对endpoint实行分片管理降低master和各个node节点网络传输数据量,及提高整体性能的目标,对于deployment的滚动升级。endpointslice根据endpoint所在的拓扑域进行分片管理。
1,端点分片
在kubernetes1.7以后,endpointslice机制在kube-apiserver是默认启用的,但是kube-proyx的默认仍然使用endpoint,为了提高性能可以设置kube-proxy启动参数--feature-gates="EndpointSliceProxying=true",让kube-proxy使用endpointslice这样可以减少kube-proxy与master之间的网络通信并提高性能。
先创建一个replicas不为1的deploymeng控制器
apiVersion: apps/v1
kind: Deployment
metadata:
name: test
spec:
replicas: 2
strategy:
type: Recreate
selector:
matchLabels:
app: test
template:
metadata:
name: test-pod
labels:
app: test
spec:
containers:
- name: test-01
image: nginx:latest
imagePullPolicy: IfNotPresent
然后在创建一个service(有serviceendpoint会自动分配ip),然后查看service和endpoint
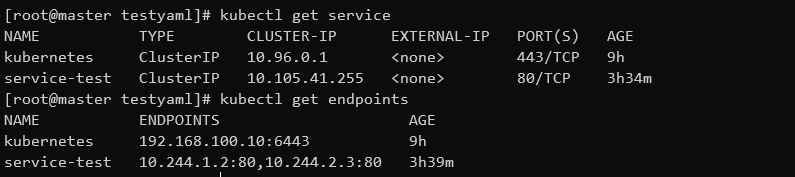
然后再查看endpointslice,发现系统已经自动创建,然后查看详细信息,查看是根据那个拓扑域进行分片
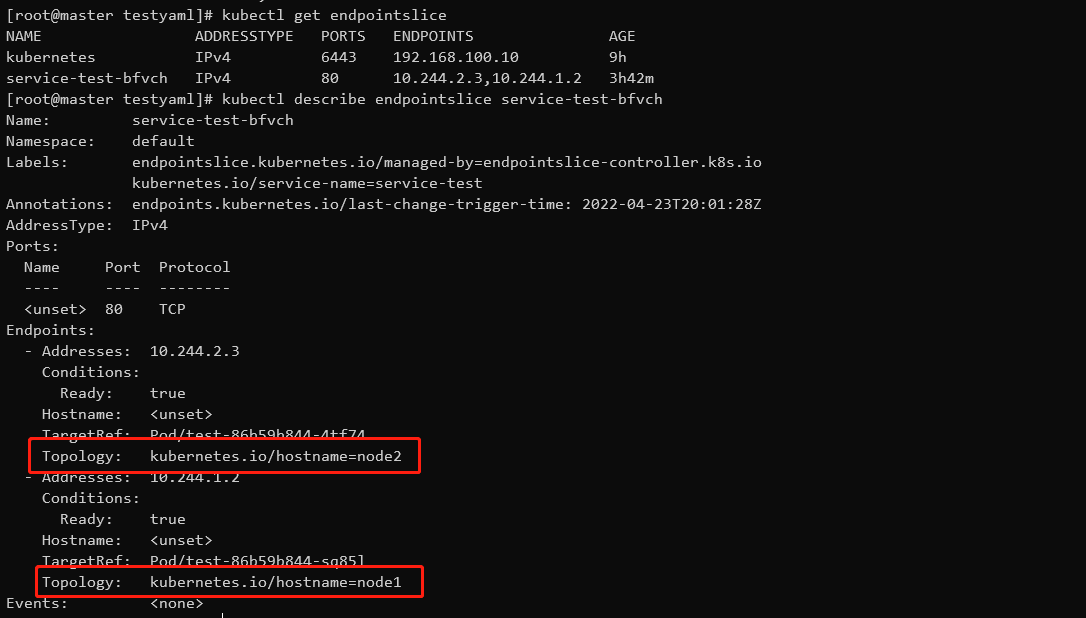
这里用kubernetes.io/hostname,每台node自己就是一个拓扑域,所以只有这台node自己更新。这里有两个endpoint,因为创建deployment控制器的时候就只有两个副本,这里将这个拓扑域内的所有endpoint都更新。就不会出现全部node都要更新的情况。然后将更新后的endpoint提供给service的后端,使得客户端访问到服务。
在endpointslice资源中能包含的endpoint数量最多是100个,但是可以设置kube-controller-manager服务的启动参数
--max-endpoints-per-slice设置,但是上限不能超过1000。
endpointslice信息说明
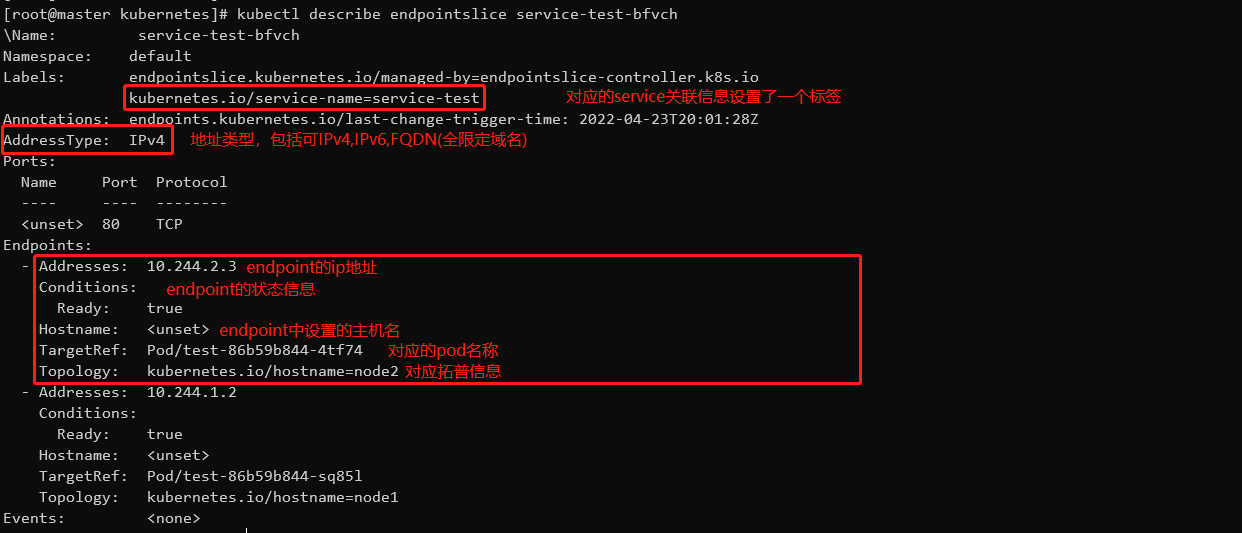
管理员可以通过不同场景对不同地域或者不同的地区的node设置相关的拓扑信息标签。
为了确保多个实体可以管理endpointslice而且不会互相产生干扰,kubernetes定义了标签
在endpointslice的标签中endpointslicelkubernetes.io/managed-by说明了有哪个控制器管理着

endpointslice-controller.k8s.io是k8s自带的管理控制器的自动设置该值。
endpointslice复制功能
应用程序有时可能会自动创建自定义的endpoint资源,为了避免应用程序在创建endpoint的情况下再去创建endpointslice资源所以kubernetes控制平面会将endpoint的资源复制为endpointslice资源,从kubernetes1.19开始使用。
如果在下面几种情况,则不会复制:
endpoint设置了label: endpointslice.kubernetes.io/skip-mirror=true
endpoint设置了annotation: control-plane.alpha.kubernetes.io/leader
endpoint对应的service资源不存在
endpoint对应的资源设置了非空的selector
2,服务拓扑
(1)默认情况下一个发送到service的流量都会被均匀转发到每个后端endpoint,但无法根据更复杂的拓扑信息设置复杂的路由策略,服务拓扑机制的引入就是为了实现node拓扑的服务路由,允许service的创建者根据node和目标node的标签来定义流量路由策略。
(2)在公有云环境当中,通常有区域zone和region的划分,云平台倾向于把服务流量限制在同一个区域内,这通常是因为跨区域网络流量会收取额外的费用,把流量保持在相同机架内的node上,以获得更低的网络延迟。
(3)启用服务拓扑机制需要通过设置kube-apiserver和kube-proxy服务的启动参数--feature-gates="ServiceTopology=true, EndpointSlice=true"来进行启用(需要同时启用endpointslice功能)。然后就可以在service上定义topologyKeys字段来控制到service的路由规则。
(4)如果启用了服务拓扑后,请求将被转发到指定的拓扑域当中,发送给这些node,但是如果标签一直没有找到匹配的ndoe,那请求将会被拒绝,就好像service没有后端endpoints一样。topologyKeys设置为*,代表任意拓扑,它只能作为配置列表中最后一个才有效,如果topoloykeys中的值为空,那就相当于没有开启服务拓扑。
(5)服务拓扑和externalTrafficPolicy=Local是不兼容的,所以一个service不能同时拥有这两种特性。
externalTrafficPolicy=Local说明:(这种模式下service类型只能是外部流量)
externaltrafficpolicy可以设置为Cluster和Locad,当它设置为Cluster时,收到客户端的请求可以转发给其他node(跨节点转发)但是容器收到的信息,客户端的源ip地址会丢失。,当它设置为Local时,它只能转发给本机,不跨节点转发,当然少了转发性能会好一点,但是这个service所有的转发就都在这一台node上了,想要所有节点的容器负载均衡,就需要上一级的loadbalancer来做了。负载均衡器设置对应转发的service。
(6)设置topologykeys的例子:
apiVersion: v1
kind: Service
metadata:
name: test
spec:
selector:
app: test
ports:
- port: 8080
topologgyKeys:
- "kubernetes.io/hostname" #将服务拓扑域设置为每台node自己
- "*" #先调度到相同node的endpoint,如果node没有可用endpoint,就转发到任意可用的endpoint。
- #还可以设置多个,但是*最后生效。
还有没有设置*
apiVersion: v1
kind: Service
metadata:
name: test
spec:
selector:
app: test
ports:
- port: 8080
topologgyKeys:
- "kubernetes.io/region"
- "kubernetes.io/zone"
#上面的规则会先将同zone,同region,这两个拓扑域的node先进行匹配,因为没有设置*
#所以如果没有可用endpoint,这个请求将会被丢弃。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号