玩转pod调度
【deployment和RC全自动调度】
k8s刚刚开始只有个pod副本控制器,replication controller(rc)但是它的标签选择器只能单个选择,后来出现了replicaset进(rs)一步增强了标签选择器,拥有了集合式的标签选择器,可以选择多个pod标签,
然后有了现在的继任者deployments,deployment也是通过replicaset来实现对pod副本控制功能的,deployment会将创建的pod对象副本调度到某个可用节点,但不会关心具体调度到什么节点。这个就是deployment等控制器的自动调度。
【NodeSelector定向调度】
node节点和selector标签,听名字都知道这个是通过赋予节点标签,然后让带有指定标签的pod调度到带有指定标签的节点上,就相当于管理者限制pod只能调度到某个节点上 。
例如: kubectl label nodes [节点名] [labels-key]=[label-value] #将节点打上标签然后无论是创建pod还是各种控制器(当然daemonset除外),只要的pod的spec下设置
spec:
containers:
- name: qqq
……
nodeSelector:
[key]:[value] #节点的标签相匹配
就能将某个pod调度到某个带有标签的节点上,这就是nodeselector定向调度。
随着节点的亲和性越来越提现nodeselector的功能,最终nodeselector将会被废弃。
【NodeAffinity节点亲和性调度】
NodeAffinity亲和性调度策略,是用于替换nodeselector的全新调度策略,目前有两种亲和性表达。
第一种:
RequiredDuringSchedulingIgnoredDuringExecution: #必须满足指定的规则才可以调度pod到node,是硬限制,和nodeselector很像只是语法不同。
第二种:
PreferredDuringSchedulingIgnoredDuringExecution: #强调优先满足指定规则,然后会尝试调度pod到node上,是软限制并不强求,多个优先的规则还可以设置权重值(weight 1-10)数字越大优先级越高,定义先后顺序。
举个例子:
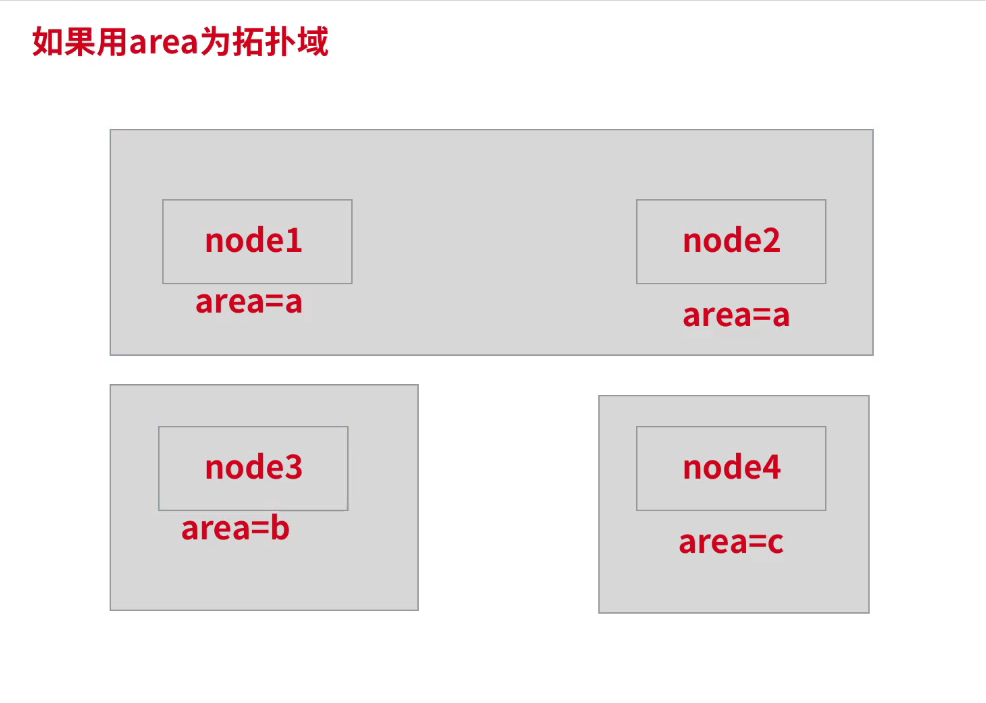
说明:这里我有两个节点分别是node1和node2,两个节点都添加上qwe:poi标签用于硬限制,然后这个pod就
只会调度到这两个节点上,然后再给node1打上ppp:aaa的标签用于软限制。这样这个pod会优先选择可以调度
节点中的node1节点。
---
apiVersion: v1
kind: Pod
metadata:
name: test
spec:
containers:
- name: test-01
image: nginx:latest
imagePullPolicy: Never
affinity: #这里开始设置亲和性调度
nodeAffinity: #类型为节点亲和性调度
requiredDuringSchedulingIgnoredDuringExecution: #硬限制
nodeSelectorTerms: #节点亲和性规则,当设置为多个的时候,因为是硬限制,所以只有一个生效
- matchExpressions: #设置规则内容,如果设置了多个条件,必须满足多个条件的节点才可调度
- key: qwe #设置标签的key
operator: In #nodeaffinity支持的操作符
values: #设置标签的value值
- poi
preferredDuringSchedulingIgnoredDuringExecution: #软限制
- weight: 1 #设置权重值,软限制的规则也可以设置多个,权重值高优先。
preference: #节点亲和性软限制规则
matchExpressions: #设置规则内容,可以设置多个条件,尽量满足不强求。
- key: ppp #设置标签的key
operator: In #nodeaffinity支持的操作符
values: #设置标签的value值
- aaa
---
operator说明:
在operator中可以设置In,NothIn,Gt,Lt,Exists,DoesNotExist
In :label的值在某个列表中
NotIn :label的值不在某个列表中
Gt :label的值大于某个值
Lt :label的值小于某个值
Exists :某个label存在
DoesNotExist :某个label不存在
在实际案例中,假设一个pod需要一个运行在amd64节点上,且磁盘类型尽量为ssd,就可以提前
给node打上标签,然后设置亲和性调度。在node上没有互斥性,但是使用notIn和DoesNotExist
就可以实现互斥性。
【podAffinity pod的亲和性调度与互斥性调度】
1,pod的亲和性调度,在实际环境当中如果一个特殊pod需要和另一个pod部署在同一节点上,或者不想和某个pod部署在同一节点上。那就需要pod亲和性调度和互斥性调度。
2,pod亲和性调度被称为PodAffinity,Pod的互斥性调度被称为PodAntiAffinity,在这里还有一个拓扑域的概念,拓扑域由一些或者一个node节点组成。这些node节点通常有地理空间的区分,例如同一个地区的node,还可以小到不同机架,机房的node,所以kubernetes就内置了一些常用的默认拓扑域,在pod亲和性调度中的一个拓扑域就限定了一个地区的node可以调度。
kubernetes内置的拓扑域通常有
kubernetes.io/hostname;
topology.kubernetes.io/region
topology.kubernetes.io/zone
也可以自行查看node的详细信息获取,pod亲和性调度中通过设置topologykey来说明拓扑域标签。
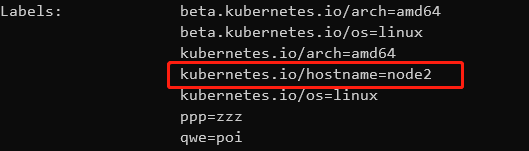
拓扑域图解:
假设设置topologykey设置为area,那area会将所有的node根据area拓扑域进行划分。如果需要放在同一个节点的pod在area=a拓扑域上,那么这个pod将被选择会被调度到node1和node2其中一个上。例如下图:
当然topologykey也可以自定义标签,可以给各个节点打上标签,然后自定义拓扑域。最常用的就是kubernetes.io/hostname标签作为评判标准,那每个node的这个标签为自己的主机名,所以每个node自己就是一个拓扑域。
当然如果反亲和性也就是互斥性就不是这样,还是以上图为例,当一个互斥的pod被调度到了一个area=a的拓扑域时,那需要创建的pod就会尽量避开调度,所以不会调度到node1和node2上去
3,pod亲和性调度和互斥性例子
先是亲和性调度,将这个新创建的pod调度到一个具有app:do标签pod的节点上。拓扑域是每个节点自己。
这里的环境是有node1和node2节点,具有需求标签的pod在node1上,所以每次调度都是node1。
apiVersion: v1
kind: Pod
metadata:
name: pod-test
spec:
containers:
- name: pod-test
image: nginx:latest
imagePullPolicy: Never
affinity: #设置亲和性调度
podAffinity: #设置pod亲和性调度
requiredDuringSchedulingIgnoredDuringExecution: #硬限制
- labelSelector: #设置硬限制规则,设置多个无意义。
matchExpressions: #设置规则内容
- key: app #设置标签,key为所需pod的标签的key
operator: In #设置操作符
values: #设置pod标签的value值
- do
topologyKey: kubernetes.io/hostname #设置拓扑域
当然使用软限制也是一样的,这里也是调度到node1,但是是尽量满足,不强求。
apiVersion: v1
kind: Pod
metadata:
name: test
spec:
containers:
- name: test-01
image: nginx:latest
imagePullPolicy: Never
affinity: #设置亲和性调度
podAffinity: #设置pod亲和性调度
preferredDuringSchedulingIgnoredDuringExecution: #硬限制
- weight: 1 #设置权重值,软限制的规则也可以设置多个,权重值高优先。
podAffinityTerm: #pod亲和性软限制
labelSelector: #设置规则,标签
matchExpressions: #设置规则内容
- key: app #设置pod的key
operator: In #设置操作符
values: #设置value值
- do
topologyKey: kubernetes.io/hostname #设置拓扑域
互斥性
互斥性的配置和亲和性调度的yaml文件几乎没有区别,将podAffinity更改为podAntiAffinity即可,这样属性就正好相反,接下来就是pod不想调度到node1了
apiVersion: v1
kind: Pod
metadata:
name: pod-test
spec:
containers:
- name: pod-test
image: nginx:latest
imagePullPolicy: Never
affinity: #设置调度
podAntiAffinity: #设置pod互斥性调度
requiredDuringSchedulingIgnoredDuringExecution: #硬限制
- labelSelector: #设置硬限制规则,设置多个无意义。
matchExpressions: #设置规则内容
- key: app #设置标签,key为所需pod的标签的key
operator: In #设置操作符
values: #设置pod标签的value值
- do
topologyKey: kubernetes.io/hostname #设置拓扑域
上面是硬限制,软限制也是一样的道理,不重复了。
【pod优先级调度】
在kubernetes种如果一个node的资源紧张,但是有用户调度了一个pod到这个节点上,那pod会一直处于pending状态,等待node上有多余的资源可以使用才能调度成功,这时便引入了pod proiority preemption调度策略,基于pod的优先级抢占调度策略,“抢占式调度”就是删除优先级低的pod,然后将腾出来的资源优先创建优先级高的的pod。
1,优先级调度有个单独的资源类型PriorityClass
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: qwe
value: 2000 #设置优先级,越大优先级越高,一亿以上的数字被保留用作k8s系统服务的优先级
globalDefault: false
preemptionPolicy: #这个值可以不设置
globalDefault值的说明:
在所有的priorityClass资源类型当中,globalDefault的值一般都是false,为false时的时候,所有新创建的pod的优先级会安装yaml文件中填写的值来定义,globalDefault的值在所有的priorityclass中只能有一个设置为true,而且一但设置所有新添加的pod的优先级会默认最高,但不会更改原本已经正在运行的pod的优先级。
preemptionPolicy值说明:
当多个scheduler在一个资源紧张的node同时创建pod,其中一个scheduler刚刚清理完资源,但是另一个scheduler已经调度了一个新的pod,然后原来的schelduler调度的时候发现资源不足,发生错误。这就是抢占资源的弊端。
所有有了preemptionPolicy,这里默认的值是preemptionLowerPriorty,就是执行抢占功能,当这个值被设置为Never时,就默认不抢占资源。而是静静地排队等待自己的调度机会。
2,然后将这个优先级给pod使用,如果没有设置优先级的pod,那么创建出来的优先级默认是0。
spec: #设置在pod的spec中即可
priorityClassName: qwe
然后describe查看pod详细信息可以看到优先级被改变
【daemonset调度】
daemonset控制器的调度比较特殊,不同于普通的调度,在旧版本中没有默认的scheduler进程,而是通过daemonset controller进行调度,在新版本中daemonset的调度默认切换到了scheduler中,所以它能够正确的处理taint的问题,当daemonset创建的时候会在所有的node上调度一个pod。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号