污点和容忍
【taints和Tolerations污点和容忍】
在nodeaffinity中,pod被设定的优先或者强制调度到某个node上,而taints和tolerations恰恰相反,它让node拒绝某个pod运行在这个pod上,然后被设定tolerations的pod才可以调度到这个节点上。例如一个node的磁盘或者内存等资源已经快要满了但是仍有pod被调度过来,所以可以给节点设置taints拒绝pod调度上来,但是有些特殊的pod需要被调度到此节点上,就用tolerations使node容忍。
1,给一个node添加taints
kubectl taint nodes [node名称] [key]=[value]:NoSchedule #最后的值还可以取值为PreferNoSchedule和NoExecute
teints的key和value值可以自定义
删除后面加个-即可
2,在一个pod中允许它的运行,设置tolerations
在pod的spec中写入
spec:
tolerations:
- key: aaa #自定义的key
operator: Equal #可以容忍的特定类别的污点,可以设置为Exists和Equal和
value: zzz #设定的value值
effect: NoSchedule #可以设定为优先
operator的值说明:
operator的值是Exists时,无需指定value,可以匹配任何的value值,所以当value值为空这里就是Exists
operator的值是Equal时,value相等,就像上面的例子一样,value的值相等即可。
effect的值详细说明:
当值为NoSchedule时为强制禁止,还可以取值为PreferNoSchedule,也就是优先。也就是硬限制和软限制的区别。
下面有说明NoExecute
3,举个例子:
现在test这个pod被设置了软限制,与node1中的另一个pod互斥,所以被调度到了node2,现在要在node2设置taint,让这个pod不要调度到node2

然后添加taint。

然后删除这个pod,重新使用原本yaml再次创建一个pod,因为原本在node2上运行的pod不会被转移。

会发现pod被调度到node1了,因为原本在写在pod中的限制是软限制,是除了node1以外的其他节点优先调度,但是node2
设置了taint并且类型是NoSchedule强制禁止是硬限制。
这时给pod添加上tolerations,再重新创建一次。
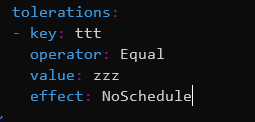
然后pod又会被互斥的规则调度到node2,node2的taint限制对这个pod已经无效。

4,effect设置为NoExecute时和综合使用
一个node可以被打上多个taint的限制,一个pod也可以被赋予多个tolerations。taint会和tolerations相互匹配,只有匹配到相同的key和value才可以进行调度。多个taint和多个tolerations值中只要有一个匹配就可以被运行在这个节点上。
当一个node的effect的值被设置为NoExecute时,如果在这个node上的pod没有匹配的taint,那这个pod将会立即被驱逐,注意pod不会调度到其他节点,但是控制器会在其他node创建,不过系统允许具有NoExecute效果的Toleration加入一个可选的tolerationSeconds字段设置表明这个pod还可以在这个node上运行多久。
举个例子:
还是之前的实验环境,test被调度到node2上

然后直接给node添加一个不匹配的标签,发现在node2上的test的pod马上被驱逐了

然后这时给test这个pod添加一个匹配标签
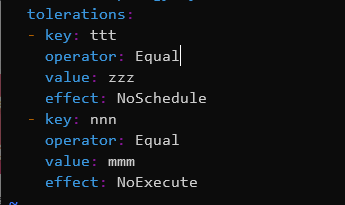
再创建testpod,然后再次查看pod,发现test可以被调度到node2上了,并且不会被驱逐

然后测试tolerationSeconds参数,设置为100s,运行100s后将会被驱逐,然后重新创建pod
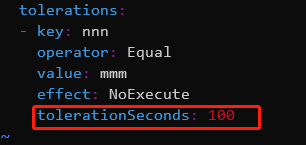
然后查看pod等待100s,发现pod自动被驱逐了

5,在某些情况下,例如node的磁盘空间已满,或者节点网络不可用,节点不可调度的时候,这个node会自动被加上Taint,例如NoExecute属性,然后阻止pod被调度到该节点,防止pod不可用和节点崩溃。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号