

本文转自:http://blog.csdn.net/qq_27469517/article/details/53482563
整个第四章都是数据预处理。
4.1是数据清洗。就是处理无关数据,缺失或者异常数据等等。
具体看书,就不赘述了,还是上代码实践。
书上给的代码是有问题的!
[python] view plain
copy


-
拉格朗日插值代码
- import pandas as pd #导入数据分析库Pandas
- from scipy.interpolate import lagrange #导入拉格朗日插值函数
-
- inputfile = 'data/catering_sale.xls' #销量数据路径
- outputfile = 'tmp/sales.xls' #输出数据路径
-
- data = pd.read_excel(inputfile) #读入数据
- data[u '销量' ][(data[u '销量' ] < 400 ) | (data[u '销量' ] > 5000 )] = None #过滤异常值,将其变为空值
-
-
自定义列向量插值函数
-
-
s为列向量,n为被插值的位置,k为取前后的数据个数,默认为5
- def ployinterp_column(s, n, k= 5 ):
- y = s[list(range(n-k, n)) + list(range(n+ 1 , n+ 1 +k))] #取数
- y = y[y.notnull()] #剔除空值
- return lagrange(y.index, list(y))(n) #插值并返回拉格朗日插值结果
-
-
逐个元素判断是否需要插值
-
- for i in data.columns:
- for j in range(len(data)):
- if (data[i].isnull())[j]: #如果为空即插值。
- data[i][j] = ployinterp_column(data[i], j)
-
- data.to_excel(outputfile) #输出结果,写入文件
究其原因,应该是
[python] view plain
copy
- data[u '销量' ][(data[u '销量' ] < 400 ) | (data[u '销量' ] > 5000 )] = None #过滤异常值,将其变为空值
这句话有问题。
改正方法主要是 .loc 函数进行修改。
.loc 函数主要是选定指定列操作,参见 http://blog.csdn.net/chixujohnny/article/details/51095817
参考下面这个链接
http://blog.csdn.net/o1101574955/article/details/51627401
给出了修改版:
[python] view plain
copy
-
-- coding:utf-8 --
-
拉格朗日插值代码
- import pandas as pd #导入数据分析库Pandas
- from scipy.interpolate import lagrange #导入拉格朗日插值函数
-
- inputfile = 'data/catering_sale.xls' #销量数据路径
- outputfile = 'tmp/sales.xls' #输出数据路径
-
- data = pd.read_excel(inputfile) #读入数据
-
data[u'销量'][(data[u'销量'] < 400) | (data[u'销量'] > 5000)] = None #过滤异常值,将其变为空值
- row_indexs = (data[u '销量' ] < 400 ) | (data[u '销量' ] > 5000 ) #得到过滤数据的索引
- data.loc[row_indexs,u '销量' ] = None #过滤数据
-
-
自定义列向量插值函数
-
-
s为列向量,n为被插值的位置,k为取前后的数据个数,默认为5
- def ployinterp_column(s, n, k= 5 ):
- y = s[list(range(n-k, n)) + list(range(n+ 1 , n+ 1 +k))] #取数
- y = y[y.notnull()] #剔除空值
- return lagrange(y.index, list(y))(n) #插值并返回拉格朗日插值结果
-
-
逐个元素判断是否需要插值
-
- for i in data.columns:
- for j in range(len(data)):
- if (data[i].isnull())[j]: #如果为空即插值。
-
data[i][j] = ployinterp_column(data[i], j)
- data.loc[j,i] = ployinterp_column(data[i], j)
- data.to_excel(outputfile) #输出结果,写入文件
这时候我在 http://blog.csdn.net/aq_cainiao_aq/article/details/53257136
也看见一篇,我没试过,可以参考。
def那段代码应该要结合拉格朗日插值法具体看,现在简单分析一下:
s为列向量,n为被插值的位置,k为取前后的数据个数,默认为5。
返回的拉格朗日函数有两个值,y.index应该是插值位置,list(y) 就是结果吧。
可惜没找到关于 lagrange 函数的说明,只能猜。
现在的问题是,日期全变成了 ######,想想怎么修改呢?
其实日期是没问题的,但是后面多了时分秒,太长了就变成了######。我不想要这个东西。
去百度搜索了很久,http://blog.csdn.net/dm_vincent/article/details/48696857
参考了一下这个,但是感觉没看懂。
不过呢,插值算是处理好了。
===================================================================================================
4.3讲的是数据变换
主要是数据的规范化处理,把数据转换成“适当的”形式。
代码就是狗屎,我自己补充了一下,给的代码不仅没有 print ,还tm少了一个 import,真的服了
[python] view plain
copy
-
-- coding: utf-8 --
-
数据规范化
- import pandas as pd
- import numpy as np
-
- datafile = 'data/normalization_data.xls' #参数初始化
- data = pd.read_excel(datafile, header = None ) #读取数据
-
- print (data - data.min())/(data.max() - data.min()) #最小-最大规范化
- print (data - data.mean())/data.std() #零-均值规范化
- print data/ 10 **np.ceil(np.log10(data.abs().max())) #小数定标规范化

就是如此。
==================================================================================================
4.3.3讲的是连续属性离散化。 但是这代码都是什么鬼???
[python] view plain
copy
-
-- coding: utf-8 --
-
数据规范化
- import pandas as pd
-
- datafile = 'data/discretization_data.xls' #参数初始化
- data = pd.read_excel(datafile) #读取数据
- data = data[u '肝气郁结证型系数' ].copy()
- k = 4
-
- d1 = pd.cut(data, k, labels = range(k)) #等宽离散化,各个类比依次命名为0,1,2,3
-
http://pandas.pydata.org/pandas-docs/stable/generated/pandas.cut.html pd.cut
-
-
等频率离散化
-
- w = [ 1.0 *i/k for i in range(k+ 1 )]
- w = data.describe(percentiles = w)[ 4 : 4 +k+ 1 ] #使用describe函数自动计算分位数
- w[ 0 ] = w[ 0 ]*( 1 - 1e - 10 )
- d2 = pd.cut(data, w, labels = range(k))
-
- from sklearn.cluster import KMeans #引入KMeans
- kmodel = KMeans(n_clusters = k, n_jobs = 4 ) #建立模型,n_jobs是并行数,一般等于CPU数较好
- kmodel.fit(data.reshape((len(data), 1 ))) #训练模型
- c = pd.DataFrame(kmodel.cluster_centers_).sort( 0 ) #输出聚类中心,并且排序(默认是随机序的)
- w = pd.rolling_mean(c, 2 ).iloc[ 1 :] #相邻两项求中点,作为边界点
- w = [ 0 ] + list(w[ 0 ]) + [data.max()] #把首末边界点加上
- d3 = pd.cut(data, w, labels = range(k))
-
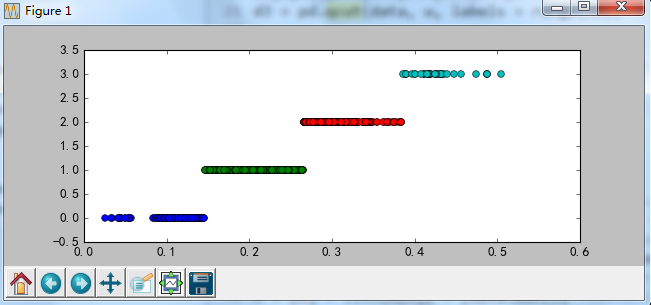
- def cluster_plot(d, k): #自定义作图函数来显示聚类结果
- import matplotlib.pyplot as plt
- plt.rcParams[ 'font.sans-serif' ] = [ 'SimHei' ] #用来正常显示中文标签
- plt.rcParams[ 'axes.unicode_minus' ] = False #用来正常显示负号
-
- plt.figure(figsize = ( 8 , 3 ))
- for j in range( 0 , k):
- plt.plot(data[dj], [j for i in d[dj]], 'o' )
-
- plt.ylim(- 0.5 , k- 0.5 )
- return plt
-
- cluster_plot(d1, k).show()
-
- cluster_plot(d2, k).show()
- cluster_plot(d3, k).show()
运行无限报错。回头再来试试。
以下内容转自http://blog.csdn.net/xuyaoqiaoyaoge/article/details/52678307
2.连续属性离散化
首先是确定分成几个区间,每个区间的范围多大,然后是将每个区间用符号或者整数值来表示。
1.等宽法
相同宽度的区间
2.等频法
将相同数量的记录放入每个区间
3.基于聚类的方法
先聚类,用K-Means,然后对簇进行处理,每个簇一个标记。
总之,区间的数量自己决定。
#-*- coding: utf-8 -*-
#数据离散化
import pandas as pd
datafile = 'E:/PythonMaterial/chapter4/demo/data/discretization_data.xls' #参数初始化
data = pd.read_excel(datafile) #读取数据
data = data[u'肝气郁结证型系数'].copy()#将这一列的数据抓出来
k = 4#分成4个区间
d1 = pd.cut(data, k, labels = range(k)) #等宽离散化,各个类比依次命名为0,1,2,3
# print d1
print pd.value_counts(d1)
#等频率离散化,qcut函数就是用来做按照分位数切割的
#如果是分成4个区间,可以使用qcut函数,4表示按照4分位数进行切割
d2=pd.qcut(data,4,labels = range(k))
# print d2
print pd.value_counts(d2)
#如果想分成10个等份,则如下
w=[0,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1]
d3 = pd.qcut(data, w, labels = range(10))
# print d3
print pd.value_counts(d3)
#也可以按照任意的分位数进行分割,使得每个区间按照自己设定的个数展示
w=[0,0.1,0.5,0.9,1]
d4 = pd.qcut(data, w, labels = range(4))#labels是可以替换的,如:labels=['hao','zhong','yiban','huai']
# print d4
print pd.value_counts(d4)
#基于聚类的划分
from sklearn.cluster import KMeans #引入KMeans
kmodel = KMeans(n_clusters = k, n_jobs = 1) #建立模型,n_jobs是并行数,一般等于CPU数较好
kmodel.fit(data.reshape((len(data), 1))) #训练模型
c = pd.DataFrame(kmodel.cluster_centers_).sort(0) #输出聚类中心,并且排序(默认是随机序的)
w = pd.rolling_mean(c, 2).iloc[1:] #相邻两项求中点,作为边界点
w = [0] + list(w[0]) + [data.max()] #把首末边界点加上
d3 = pd.cut(data, w, labels = range(k))
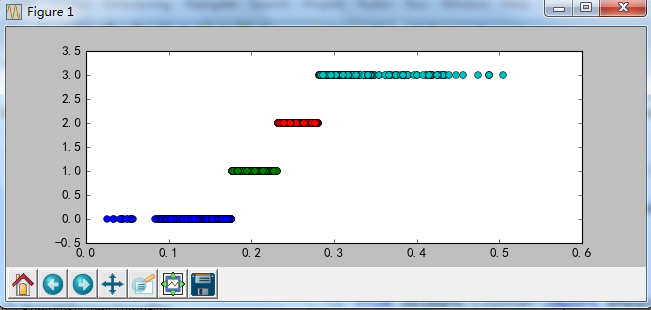
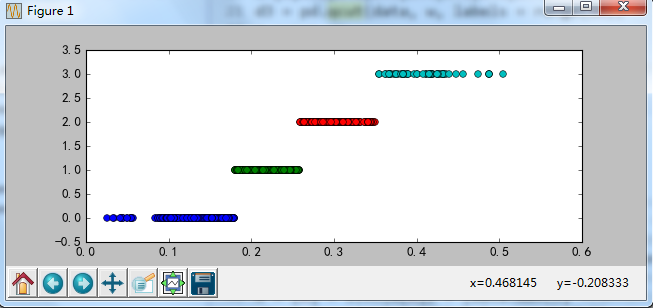
def cluster_plot(d, k): #自定义作图函数来显示聚类结果
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
plt.figure(figsize = (8, 3))
for j in range(0, k):
plt.plot(data[d==j], [j for i in d[d==j]], 'o')
plt.ylim(-0.5, k-0.5)
return plt
cluster_plot(d1, k).show()
cluster_plot(d2, k).show()
cluster_plot(d3, k).show()
-
1
-
2
-
3
-
4
-
5
-
6
-
7
-
8
-
9
-
10
-
11
-
12
-
13
-
14
-
15
-
16
-
17
-
18
-
19
-
20
-
21
-
22
-
23
-
24
-
25
-
26
-
27
-
28
-
29
-
30
-
31
-
32
-
33
-
34
-
35
-
36
-
37
-
38
-
39
-
40
-
41
-
42
-
43
-
44
-
45
-
46
-
47
-
48
-
49
-
50
-
51
-
52
-
53
-
54
-
55
-
1
-
2
-
3
-
4
-
5
-
6
-
7
-
8
-
9
-
10
-
11
-
12
-
13
-
14
-
15
-
16
-
17
-
18
-
19
-
20
-
21
-
22
-
23
-
24
-
25
-
26
-
27
-
28
-
29
-
30
-
31
-
32
-
33
-
34
-
35
-
36
-
37
-
38
-
39
-
40
-
41
-
42
-
43
-
44
-
45
-
46
-
47
-
48
-
49
-
50
-
51
-
52
-
53
-
54
-
55
1 508
2 275
0 112
3 35
Name: 肝气郁结证型系数, dtype: int64
1 234
3 233
0 233
2 230
Name: 肝气郁结证型系数, dtype: int64
6 97
0 97
4 95
2 94
8 93
9 92
1 92
5 91
7 90
3 89
Name: 肝气郁结证型系数, dtype: int64
2 371
1 370
0 97
3 92
Name: 肝气郁结证型系数, dtype: int64
-
1
-
2
-
3
-
4
-
5
-
6
-
7
-
8
-
9
-
10
-
11
-
12
-
13
-
14
-
15
-
16
-
17
-
18
-
19
-
20
-
21
-
22
-
23
-
24
-
25
-
26
-
1
-
2
-
3
-
4
-
5
-
6
-
7
-
8
-
9
-
10
-
11
-
12
-
13
-
14
-
15
-
16
-
17
-
18
-
19
-
20
-
21
-
22
-
23
-
24
-
25
-
26


 浙公网安备 33010602011771号
浙公网安备 33010602011771号