02-20 kd树(鸢尾花分类)
人工智能从入门到放弃完整教程目录:https://www.cnblogs.com/nickchen121/p/11686958.html
kd树(鸢尾花分类)
一、导入模块
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
from matplotlib.font_manager import FontProperties
from sklearn import datasets
from sklearn.neighbors import KDTree
%matplotlib inline
font = FontProperties(fname='/Library/Fonts/Heiti.ttc')
二、获取数据
iris_data = datasets.load_iris()
X = iris_data.data[:, [2, 3]]
y = iris_data.target
label_list = ['山鸢尾', '杂色鸢尾', '维吉尼亚鸢尾']
三、构建决策边界
def plot_decision_regions(X, y, classifier):
marker_list = ['o', 'x', 's']
color_list = ['r', 'b', 'g']
cmap = ListedColormap(color_list[:len(np.unique(y))])
x1_min, x1_max = X[:, 0].min() - 1, X[:, 0].max() + 1
x2_min, x2_max = X[:, 1].min() - 1, X[:, 1].max() + 1
t1 = np.linspace(x1_min, x1_max, 666)
t2 = np.linspace(x2_min, x2_max, 666)
x1, x2 = np.meshgrid(t1, t2)
# y_hat_ind:最近的3个邻居的索引
# y_hat_dist:距离最近的3个邻居的距离
y_hat_dist, y_hat_ind = classifier.query(
np.array([x1.ravel(), x2.ravel()]).T, k=3) # 搜索最近的3个邻居
# 选出类别最多的邻居作为自己类别
y_hat_list = []
for i in range(len(y_hat_ind)):
y_hat_i = Counter(y_hat_ind[i, :]).most_common(1)[0][0]
y_hat_list.append(y_hat_i)
y_hat = y[y_hat_list]
y_hat = y_hat.reshape(x1.shape)
plt.contourf(x1, x2, y_hat, alpha=0.2, cmap=cmap)
plt.xlim(x1.min(), x1.max())
plt.ylim(x2.min(), x2.max())
for ind, clas in enumerate(np.unique(y)):
plt.scatter(X[y == clas, 0], X[y == clas, 1], alpha=0.8, s=50,
c=color_list[ind], marker=marker_list[ind], label=label_list[clas])
四、训练模型
kdtree = KDTree(X)
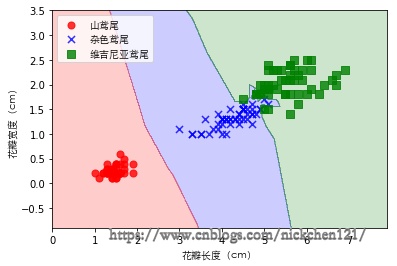
五、可视化
plot_decision_regions(X, y, classifier=kdtree)
plt.xlabel('花瓣长度(cm)', fontproperties=font)
plt.ylabel('花瓣宽度(cm)', fontproperties=font)
plt.legend(prop=font)
plt.show()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号