04-08 梯度提升算法代码(鸢尾花分类)
目录
人工智能从入门到放弃完整教程目录:https://www.cnblogs.com/nickchen121/p/11686958.html
梯度提升算法代码(鸢尾花分类)+交叉验证调参
一、导入模块
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
from matplotlib.font_manager import FontProperties
from sklearn.datasets import load_iris
from sklearn.ensemble import GradientBoostingClassifier
from sklearn import metrics
from sklearn.model_selection import GridSearchCV
%matplotlib inline
font = FontProperties(fname='/Library/Fonts/Heiti.ttc')
二、导入数据
iris_data = load_iris()
X = iris_data.data[0:100, [2, 3]]
y = iris_data.target[0:100]
label_list = ['山鸢尾', '杂色鸢尾']
三、构造决策边界
def plot_decision_regions(X, y, classifier=None):
marker_list = ['o', 'x', 's']
color_list = ['r', 'b', 'g']
cmap = ListedColormap(color_list[:len(np.unique(y))])
x1_min, x1_max = X[:, 0].min()-1, X[:, 0].max()+1
x2_min, x2_max = X[:, 1].min()-1, X[:, 1].max()+1
t1 = np.linspace(x1_min, x1_max, 666)
t2 = np.linspace(x2_min, x2_max, 666)
x1, x2 = np.meshgrid(t1, t2)
y_hat = classifier.predict(np.array([x1.ravel(), x2.ravel()]).T)
y_hat = y_hat.reshape(x1.shape)
plt.contourf(x1, x2, y_hat, alpha=0.2, cmap=cmap)
plt.xlim(x1_min, x1_max)
plt.ylim(x2_min, x2_max)
for ind, clas in enumerate(np.unique(y)):
plt.scatter(X[y == clas, 0], X[y == clas, 1], alpha=0.8, s=50,
c=color_list[ind], marker=marker_list[ind], label=label_list[clas])
四、训练模型
gbc = GradientBoostingClassifier(random_state=1)
gbc.fit(X, y)
y_pred = gbc.predict(X)
y_predprob = gbc.predict_proba(X)[:, 1]
print("精准度:{:.4f}".format(metrics.accuracy_score(y, y_pred)))
print("AUC分数(训练集):{:.4f}".format(metrics.roc_auc_score(y, y_predprob)))
精准度:1.0000
AUC分数(训练集):1.0000
4.1 可视化
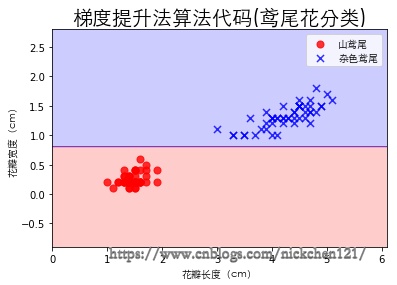
plot_decision_regions(X, y, classifier=gbc)
plt.xlabel('花瓣长度(cm)', fontproperties=font)
plt.ylabel('花瓣宽度(cm)', fontproperties=font)
plt.title('梯度提升法算法代码(鸢尾花分类)',
fontproperties=font, fontsize=20)
plt.legend(prop=font)
plt.show()
五、交叉验证训练模型
5.1 找到合适n_estimators
param_test1 = {'n_estimators': range(20, 81, 10)}
gsearch1 = GridSearchCV(estimator=GradientBoostingClassifier(learning_rate=0.1, min_samples_split=300,
min_samples_leaf=20, max_depth=8, max_features='sqrt', subsample=0.8, random_state=10),
param_grid=param_test1, scoring='roc_auc', iid=False, cv=5, return_train_score=True)
gsearch1.fit(X, y)
print('交叉验证流程:\n{}\n最优参数:{}\n平均交叉验证得分:{}'.format(
gsearch1.cv_results_, gsearch1.best_params_, gsearch1.best_score_))
交叉验证流程:
{'mean_fit_time': array([0.00935884, 0.01195612, 0.01114783, 0.01175175, 0.01477156,
0.01706672, 0.02215848]), 'std_fit_time': array([0.00116642, 0.00235501, 0.00147974, 0.00020805, 0.00056141,
0.0004948 , 0.00429558]), 'mean_score_time': array([0.00141163, 0.00101204, 0.00096631, 0.00072584, 0.00078516,
0.00075955, 0.00102429]), 'std_score_time': array([6.53798458e-04, 6.07125129e-05, 2.87727706e-04, 4.16611072e-05,
4.73834118e-05, 2.78423089e-05, 5.01388442e-04]), 'param_n_estimators': masked_array(data=[20, 30, 40, 50, 60, 70, 80],
mask=[False, False, False, False, False, False, False],
fill_value='?',
dtype=object), 'params': [{'n_estimators': 20}, {'n_estimators': 30}, {'n_estimators': 40}, {'n_estimators': 50}, {'n_estimators': 60}, {'n_estimators': 70}, {'n_estimators': 80}], 'split0_test_score': array([0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5]), 'split1_test_score': array([0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5]), 'split2_test_score': array([0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5]), 'split3_test_score': array([0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5]), 'split4_test_score': array([0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5]), 'mean_test_score': array([0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5]), 'std_test_score': array([0., 0., 0., 0., 0., 0., 0.]), 'rank_test_score': array([1, 1, 1, 1, 1, 1, 1], dtype=int32), 'split0_train_score': array([0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5]), 'split1_train_score': array([0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5]), 'split2_train_score': array([0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5]), 'split3_train_score': array([0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5]), 'split4_train_score': array([0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5]), 'mean_train_score': array([0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5]), 'std_train_score': array([0., 0., 0., 0., 0., 0., 0.])}
最优参数:{'n_estimators': 20}
平均交叉验证得分:0.5
5.2 找到合适max_depth和min_samples_split
param_test2 = {'max_depth': range(
3, 14, 2), 'min_samples_split': range(100, 801, 200)}
gsearch2 = GridSearchCV(estimator=GradientBoostingClassifier(learning_rate=0.1, n_estimators=60, min_samples_leaf=20,
max_features='sqrt', subsample=0.8, random_state=10),
param_grid=param_test2, scoring='roc_auc', iid=False, cv=5, return_train_score=True)
gsearch2.fit(X, y)
gsearch2.cv_results_, gsearch2.best_params_, gsearch2.best_score_
({'mean_fit_time': array([0.02237329, 0.01351748, 0.01450391, 0.01599288, 0.01583681,
0.01453352, 0.01576724, 0.02226548, 0.02175894, 0.02245622,
0.0193892 , 0.0176538 , 0.01604352, 0.01569099, 0.01467667,
0.01587796, 0.01446023, 0.01470103, 0.02507586, 0.03041081,
0.01509953, 0.01349149, 0.01589556, 0.02044396]),
'std_fit_time': array([0.00706648, 0.00041068, 0.00074293, 0.00067953, 0.00044884,
0.00030283, 0.0010576 , 0.00311013, 0.00114113, 0.00230299,
0.00162901, 0.00136881, 0.00113474, 0.00100254, 0.00077541,
0.00092828, 0.00043059, 0.00036572, 0.00721405, 0.00216457,
0.00308352, 0.00029451, 0.00250799, 0.00247415]),
'mean_score_time': array([0.00111475, 0.00069857, 0.00075006, 0.00089993, 0.00082245,
0.00074048, 0.00086002, 0.0015542 , 0.00116477, 0.001577 ,
0.00108557, 0.00095901, 0.00076284, 0.00108142, 0.000741 ,
0.00077958, 0.00085745, 0.00087228, 0.00177569, 0.00125322,
0.00074091, 0.00070515, 0.00095592, 0.00091 ]),
'std_score_time': array([3.68407752e-04, 2.53321283e-05, 5.35613586e-05, 1.78281602e-04,
8.23241919e-05, 5.30854908e-06, 1.20393724e-04, 5.88781049e-04,
1.75142463e-04, 8.11823820e-04, 1.99134722e-04, 1.57118574e-04,
2.29866176e-05, 3.24591827e-04, 2.65607286e-05, 3.89133597e-05,
7.89597701e-05, 1.00572361e-04, 9.80008117e-04, 3.96108848e-04,
6.47420548e-05, 2.96792733e-05, 2.87524922e-04, 1.13747143e-04]),
'param_max_depth': masked_array(data=[3, 3, 3, 3, 5, 5, 5, 5, 7, 7, 7, 7, 9, 9, 9, 9, 11, 11,
11, 11, 13, 13, 13, 13],
mask=[False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False],
fill_value='?',
dtype=object),
'param_min_samples_split': masked_array(data=[100, 300, 500, 700, 100, 300, 500, 700, 100, 300, 500,
700, 100, 300, 500, 700, 100, 300, 500, 700, 100, 300,
500, 700],
mask=[False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False],
fill_value='?',
dtype=object),
'params': [{'max_depth': 3, 'min_samples_split': 100},
{'max_depth': 3, 'min_samples_split': 300},
{'max_depth': 3, 'min_samples_split': 500},
{'max_depth': 3, 'min_samples_split': 700},
{'max_depth': 5, 'min_samples_split': 100},
{'max_depth': 5, 'min_samples_split': 300},
{'max_depth': 5, 'min_samples_split': 500},
{'max_depth': 5, 'min_samples_split': 700},
{'max_depth': 7, 'min_samples_split': 100},
{'max_depth': 7, 'min_samples_split': 300},
{'max_depth': 7, 'min_samples_split': 500},
{'max_depth': 7, 'min_samples_split': 700},
{'max_depth': 9, 'min_samples_split': 100},
{'max_depth': 9, 'min_samples_split': 300},
{'max_depth': 9, 'min_samples_split': 500},
{'max_depth': 9, 'min_samples_split': 700},
{'max_depth': 11, 'min_samples_split': 100},
{'max_depth': 11, 'min_samples_split': 300},
{'max_depth': 11, 'min_samples_split': 500},
{'max_depth': 11, 'min_samples_split': 700},
{'max_depth': 13, 'min_samples_split': 100},
{'max_depth': 13, 'min_samples_split': 300},
{'max_depth': 13, 'min_samples_split': 500},
{'max_depth': 13, 'min_samples_split': 700}],
'split0_test_score': array([0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5,
0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5]),
'split1_test_score': array([0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5,
0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5]),
'split2_test_score': array([0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5,
0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5]),
'split3_test_score': array([0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5,
0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5]),
'split4_test_score': array([0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5,
0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5]),
'mean_test_score': array([0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5,
0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5]),
'std_test_score': array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0.]),
'rank_test_score': array([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1], dtype=int32),
'split0_train_score': array([0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5,
0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5]),
'split1_train_score': array([0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5,
0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5]),
'split2_train_score': array([0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5,
0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5]),
'split3_train_score': array([0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5,
0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5]),
'split4_train_score': array([0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5,
0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5]),
'mean_train_score': array([0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5,
0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5]),
'std_train_score': array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0.])},
{'max_depth': 3, 'min_samples_split': 100},
0.5)
gbm2 = GradientBoostingClassifier(learning_rate=0.1, n_estimators=20, max_depth=3,
min_samples_split=100, random_state=10)
gbm2.fit(X, y)
y_pred = gbm1.predict(X)
y_predprob = gbm1.predict_proba(X)[:, 1]
print("精准度:{:.4f}".format(metrics.accuracy_score(y, y_pred)))
print("AUC分数(训练集):{:.4f}".format(metrics.roc_auc_score(y, y_predprob)))
精准度:0.5000
AUC分数(训练集):0.5000
5.3 使用最优参数训练模型
gbm1 = GradientBoostingClassifier(learning_rate=0.1, n_estimators=20, max_depth=3,
min_samples_split=100, random_state=10)
gbm1.fit(X, y)
y_pred = gbm1.predict(X)
y_predprob = gbm1.predict_proba(X)[:, 1]
print("精准度:{:.4f}".format(metrics.accuracy_score(y, y_pred)))
print("AUC分数(训练集):{:.4f}".format(metrics.roc_auc_score(y, y_predprob)))
精准度:1.0000
AUC分数(训练集):1.0000
5.4 使用非最优参数训练模型
gbm2 = GradientBoostingClassifier(learning_rate=0.1, n_estimators=20, max_depth=3, min_samples_leaf=60,
min_samples_split=100, max_features='sqrt', subsample=0.8, random_state=10)
gbm2.fit(X, y)
y_pred = gbm1.predict(X)
y_predprob = gbm1.predict_proba(X)[:, 1]
print("精准度:{:.4f}".format(metrics.accuracy_score(y, y_pred)))
print("AUC分数(训练集):{:.4f}".format(metrics.roc_auc_score(y, y_predprob)))
精准度:1.0000
AUC分数(训练集):1.0000
5.5 小结
上述展示的是工业上寻找最优参数的一个过程,一般都是选择使用交叉验证获取最优参数,当然,工业上是远没有这么简单的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号