RagFlow优化&代码解析(二)
引子
前文写到RagFlow优化&代码解析(一),感兴趣的童鞋可以移步(https://blog.csdn.net/zzq1989_/article/details/148055465)。上一篇主要写了检索优化以及整体代码结构和流程。这一篇打算重点写下LLM相关的代码解析。OK,那我们开始吧。
一、RagFlow大模型相关代码总体概述
首先我们看下大模型相关代码结构,如下,不得不说,github上的热门项目代码层级还是很清晰明了的。在rag目录下有个llm目录,这个目录里面就是大模型相关的全部代码实现。
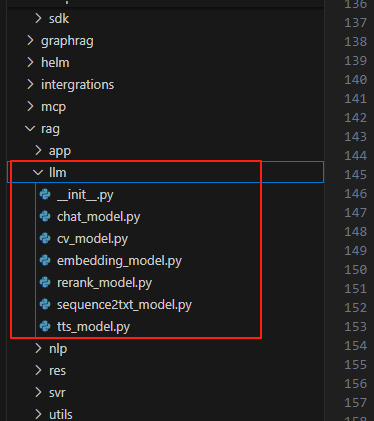
我们可以看到除了初始化代码外,分别如下:
chat_model.py:对话模型代码实现,
cv_model.py:计算机视觉/多模态模型代码实现,
embedding_model.py:嵌入模型代码实现。
rerank_model.py:重排模型代码实现
sequence2txt_model.py:语音转文字代码实现
tts_model.py:文本转语音代码实现
下面我会对llm目录下的代码进行逐一解析,借此学习优秀开源项目,看是否能有一些启发。
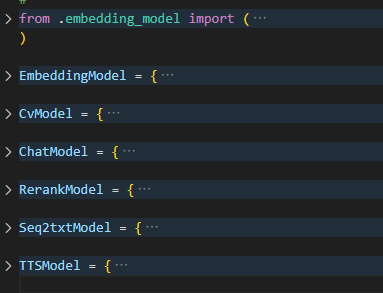
二、初始化部分(__init__.py)
如下图,导入包的部分不提,蓝色字体部分为每种类型的模型所支持的类别,这个会在各个模型部分进行详解。
三、嵌入模型部分(embedding_model.py)
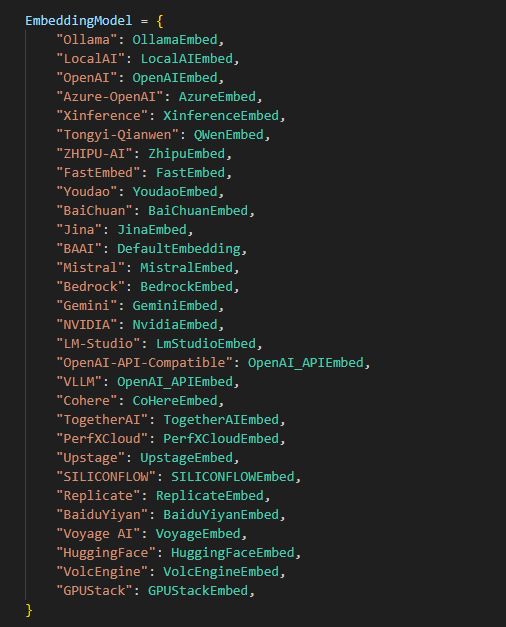
通过__init__.py文件我们可以知道支持Embedding模型的种类还是很多,有Ollama、OpenAI、Xinference等类别。接下来我们随便挑一个OllamaEmbed看下具体实现。embedding_model.py代码部分如下。这段代码定义了一个base基类,继承于ABC类,代码实现,3个主要功能函数,一个是encode编码函数,另外一个是encode_queries编码查询函数,最后一个就是token计数函数。
class Base(ABC): def __init__(self, key, model_name): pass def encode(self, texts: list): raise NotImplementedError("Please implement encode method!") def encode_queries(self, text: str): raise NotImplementedError("Please implement encode method!") def total_token_count(self, resp): try: return resp.usage.total_tokens except Exception: pass try: return resp["usage"]["total_tokens"] except Exception: pass return 0
我们看下OllamaEmbed的具体实现,OllamaEmbed继承上面的base类,并使用Ollama的Client类作为发送接收请求工具。具体实现encode编码功能和encode_queries编码查询功能。实现都封装的很好,看起来很简单,直接调用Ollama的client已有的embeddings函数,Ollama的embedding函数输出维度是128。
class OllamaEmbed(Base): def __init__(self, key, model_name, **kwargs): self.client = Client(host=kwargs["base_url"]) if not key or key == "x" else \ Client(host=kwargs["base_url"], headers={"Authorization": f"Bear {key}"}) self.model_name = model_name def encode(self, texts: list): arr = [] tks_num = 0 for txt in texts: res = self.client.embeddings(prompt=txt, model=self.model_name, options={"use_mmap": True}) arr.append(res["embedding"]) tks_num += 128 return np.array(arr), tks_num def encode_queries(self, text): res = self.client.embeddings(prompt=text, model=self.model_name, options={"use_mmap": True}) return np.array(res["embedding"]), 128
四、对话模型部分(chat_model.py)
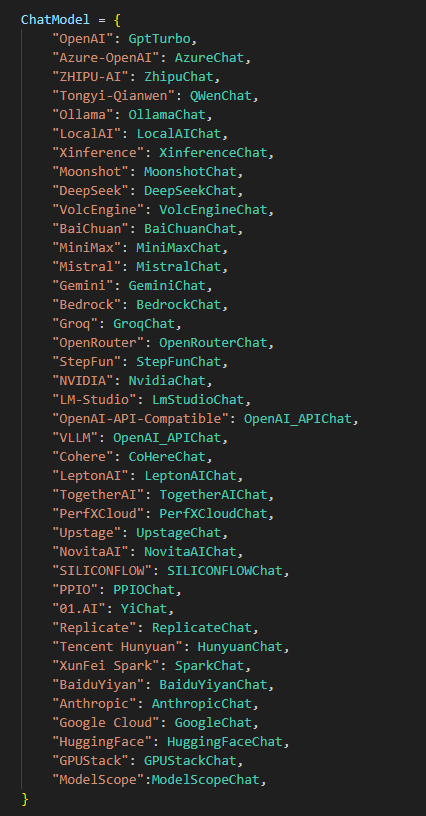
我们具体来看下代码,代码风格与Embed_model.py类似,有个Base基类,这个类显然就比上文中的Base类复杂的多。首先是初始化,这个直接client使用OpenAI的标准接口。max_retries和base_delay定义最大尝试次数以及delay时长。接下来内部函数_get_delay获取delay时长。内部函数_classify_error报错分类。bind_tools函数确定是否绑定工具。chat_with_tools函数实现利用工具chat功能,具体可以看我代码中的注释内容。chat函数和chat_with_tools函数类似。不再赘述。chat_streamly_with_tools函数实现利用工具流式输出功能。chat_streamly函数与带工具的流式输出类似,不再赘述。
class OllamaEmbed(Base): def __init__(self, key, model_name, **kwargs): self.client = Client(host=kwargs["base_url"]) if not key or key == "x" else \ Client(host=kwargs["base_url"], headers={"Authorization": f"Bear {key}"}) self.model_name = model_name def encode(self, texts: list): arr = [] tks_num = 0 for txt in texts: res = self.client.embeddings(prompt=txt, model=self.model_name, options={"use_mmap": True}) arr.append(res["embedding"]) tks_num += 128 return np.array(arr), tks_num def encode_queries(self, text): res = self.client.embeddings(prompt=text, model=self.model_name, options={"use_mmap": True}) return np.array(res["embedding"]), 128
具体来看下deepseek的chat实现,很简单,仅仅是进行了一个deepseek的初始化。
class DeepSeekChat(Base): def __init__(self, key, model_name="deepseek-chat", base_url="https://api.deepseek.com/v1"): if not base_url: base_url = "https://api.deepseek.com/v1" super().__init__(key, model_name, base_url)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号