RagFlow环境搭建&推理测试
引子
去年12月写了一篇DIfy的博客,感兴趣的童鞋可以移步(https://blog.csdn.net/zzq1989_/article/details/144657580)。Dify对企业级的应用不是太友好。最近有个RAG的项目需求,又重新好好调研了下这个问题,发现RagFlow这个项目还是很活跃,更新很及时,也支持GraghRAG。OK,那就让我们开始吧。。
一、架构介绍
RagFlow是一种融合了数据检索与生成式模型的新型系统架构,其核心思想在于将大规模检索系统与先进的生成式模型(如Transformer、GPT系列)相结合,从而在回答查询时既能利用海量数据的知识库,又能生成符合上下文语义的自然语言回复。该系统主要包含两个关键模块:数据检索模块和生成模块。数据检索模块负责在海量数据中快速定位相关信息,而生成模块则基于检索结果生成高质量的回答或文本内容。
在实际应用中,RAGFlow能够在客户服务、问答系统、智能搜索、内容推荐等领域发挥重要作用,通过检索与生成的双重保障,显著提升系统的响应速度和准确性。
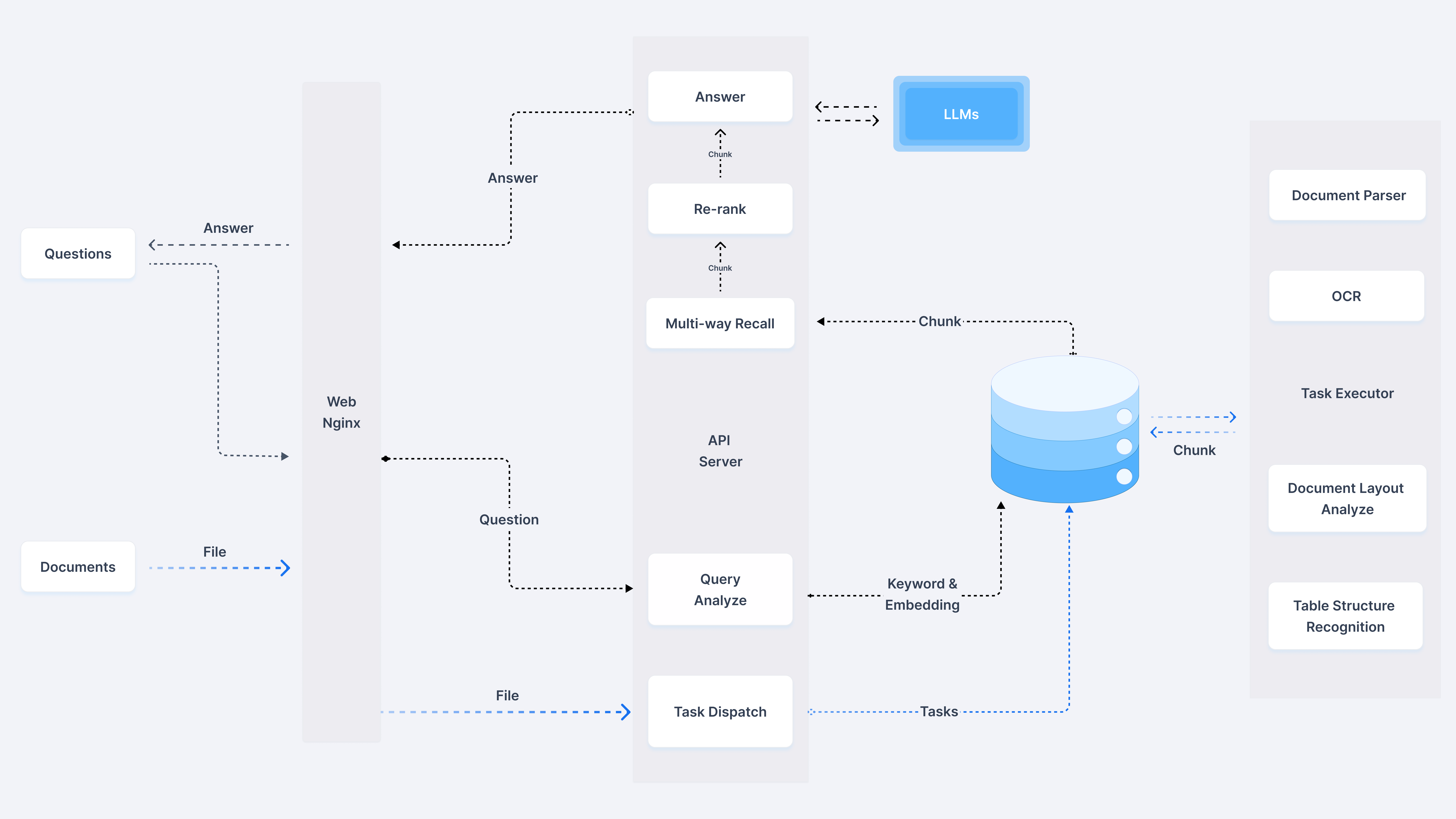
1、检索流程
(1)首先Questions提出问题,由查询分析器进行Keyword & Embedding,到AI 原生数据库(Infinity)进行相似性检索,返回Chunk数据
(2)基于多路召回、融合重排序处理,得到更精确、准确答案
(3)调用LLMs进行内容生成,返回答案给用户
2、知识加载
(1)Documents加载进行Task Dispatch分发,进行Task Exector
(2)基于深度文档理解(DeepDoc)处理,如:OCR、文档解析、文档分层分析、表结构识别
(3)基于可控可解释的模板文本切片,形成Chunk存入AI 原生数据库
3、主要功能
(1)"Quality in, quality out"
(2)基于模板的文本切片
(3)有理有据、最大程度降低幻觉(hallucination)
(4)兼容各类异构数据源
(5)全程无忧、自动化的 RAG 工作流
二、环境安装
1、环境需求
在搭建RAGFlow系统前,需要确保开发与运行环境满足以下要求:
硬件配置:建议采用多核CPU、充足内存(16GB及以上)以及支持高并发访问的存储设备;如需部署大规模检索服务,可考虑使用分布式存储集群。
操作系统:推荐使用Linux发行版(如CentOS、Ubuntu)以便于Shell脚本自动化管理;同时也支持Windows环境,但在部署自动化脚本时可能需要适当调整。
开发语言与工具:主要使用Java进行系统核心模块开发,同时结合Shell脚本实现自动化运维。
依赖环境:需要安装Java 8及以上版本,同时配置Maven或Gradle进行依赖管理;对于数据检索部分,可采用ElasticSearch、Apache Solr等开源检索引擎;生成模块则依赖于预训练模型,可以借助TensorFlow或PyTorch进行实现。
2、服务器配置
CPU >= 4 核
RAM >= 16 GB
Disk >= 50 GB
Docker >= 24.0.0 & Docker Compose >= v2.26.1
3、环境安装
cd /datas/work/zzq/RAGFlow/ragflow-main/docker
sysctl -w vm.max_map_count=262144
vi docker-compose-gpu.yml 删除
include:
- ./docker-compose-base.yml
4、拉取镜像并启动
docker compose -f docker-compose-base.yml -f docker-compose-gpu.yml up -d

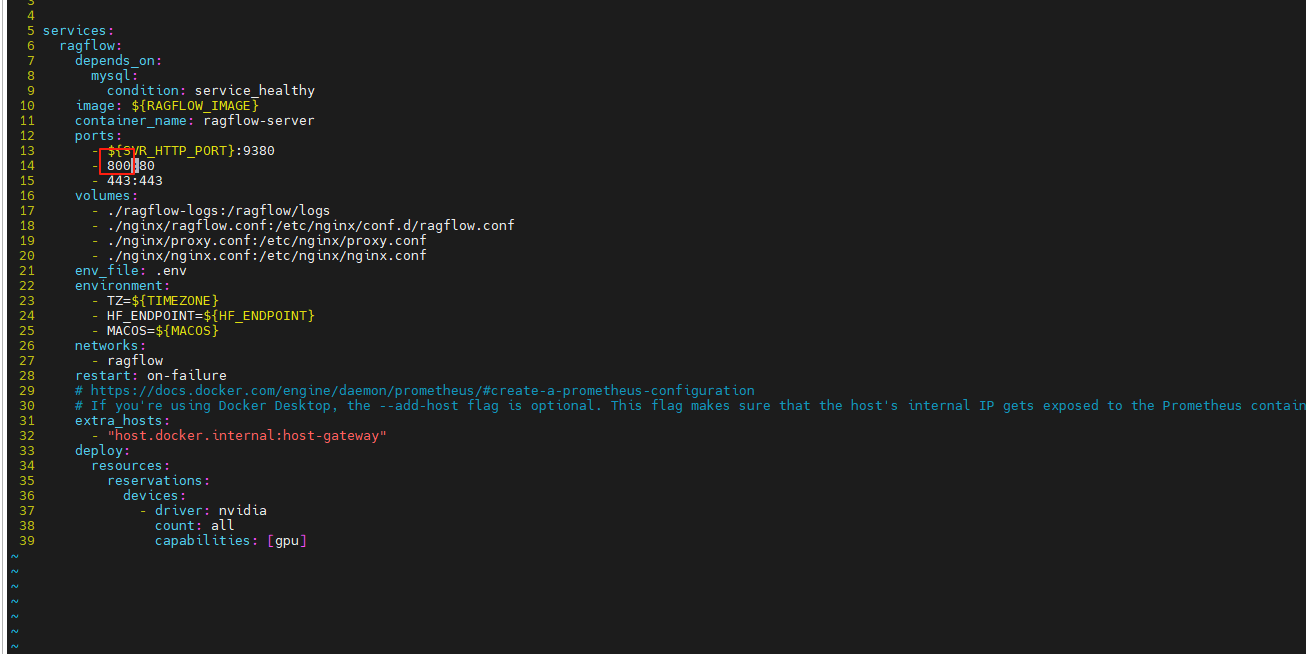
5、80端口占用报错

6、修改80端口
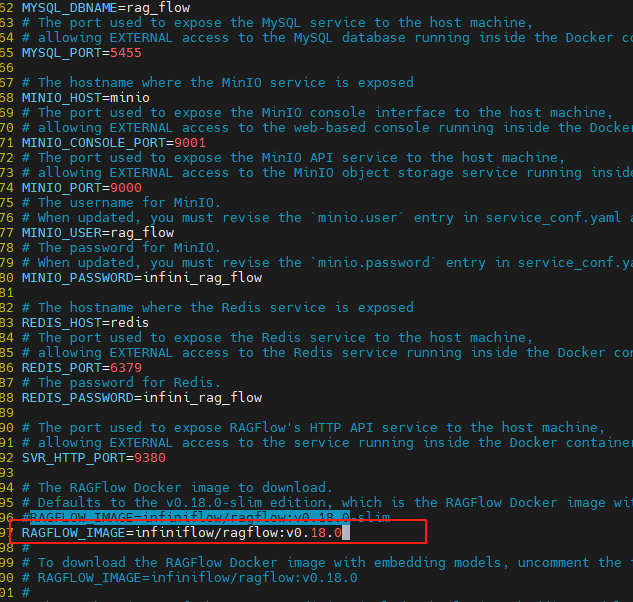
7、选择带embedding模型的镜像
8、重新执行

9、查看服务
docker logs -f ragflow-server

10、关闭容器服务
docker compose -f docker-compose-base.yml -f docker-compose-gpu.yml down -v
11、如果报Your kernel does not support swap limit capabilities or the cgroup is not mounted. Memory limited without swap.错误
三、推理测试
1、浏览器打开 http:ip:800/login,(800为二、6步骤中改的数据)
2、注册后登录,可以选择语言
3、安装Ollama(参考网址:https://github.com/infiniflow/ragflow/blob/main/docs/guides/models/deploy_local_llm.mdx)
docker pull ollama/ollama
docker run --name ollama -p 11434:11434 ollama/ollama
4、下载bge-m3嵌入模型
docker exec ollama ollama pull bge-m3
5、验证ollama是否正常
docker exec -it ragflow-server bash
curl http://host.docker.internal:11434/
退出容器
6、RagFlow不支持Ollama的reranker模型,安装Xinference,使用Xinference的reranker支持模型,安装Xinference
cd /datas/work/zzq/RagFlow/ragflow-main/docker
docker compose -f docker-compose-xinference.yml up -d
启动xinference
docker exec xinference xinference-local --host 0.0.0.0 --port 9997
网页端打开
7、下载rerank模型
modelscope download --model BAAI/bge-reranker-v2-m3 README.md --local_dir .//bge-reranker-v2-m3
8、载入rerank模型
docker exec xinference xinference launch --model-uid bge-reranker-v2-m3 --model-name bge-reranker-v2-m3 --model-type rerank --replica 1 --n-gpu auto --model-path /data/bge-reranker-v2-m3

9、注册DeepSeek语言模型

10、Xinference大语言模型加载
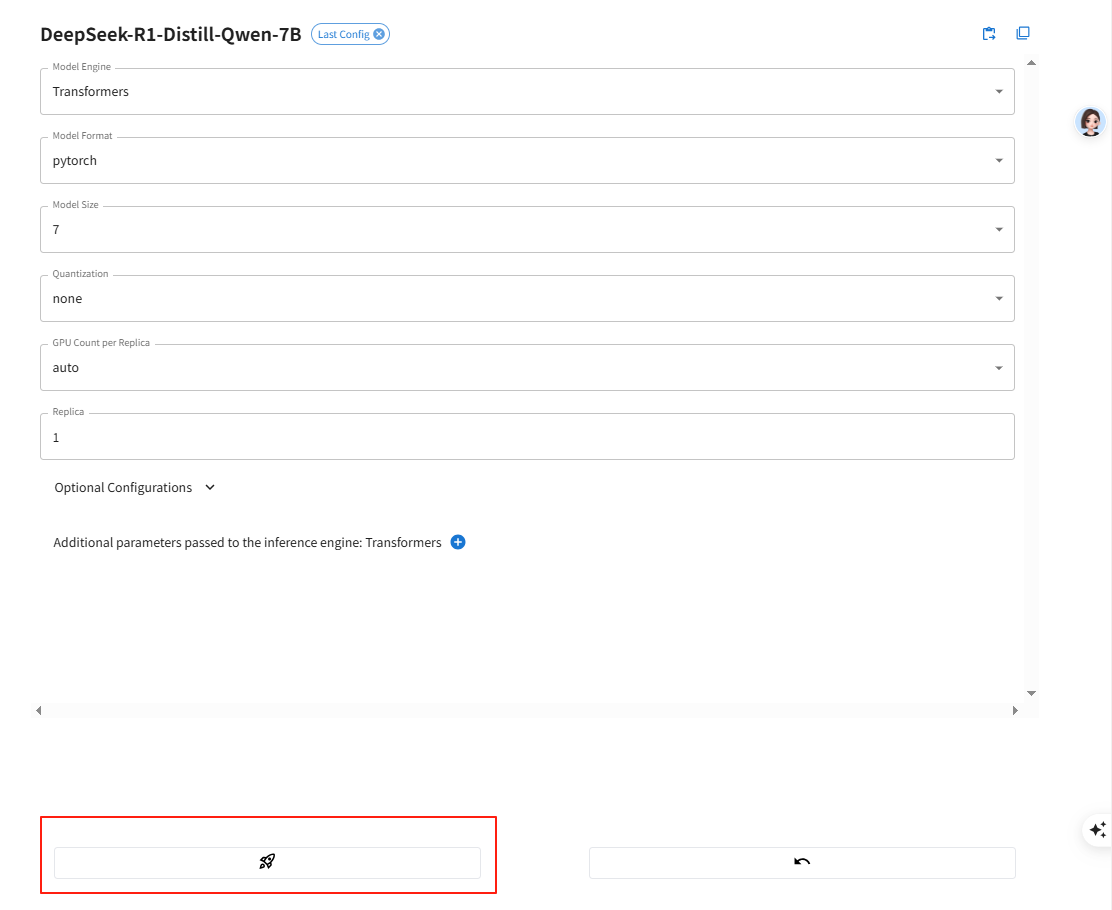
加载成功后,Running Models显示如下

11、命令行启动
docker exec xinference xinference launch --model-name DeepSeek-R1-Distill-Qwen-7B --model-format pytorch --model-engine transformers
12、选择模型提供商Ollama或者XInference
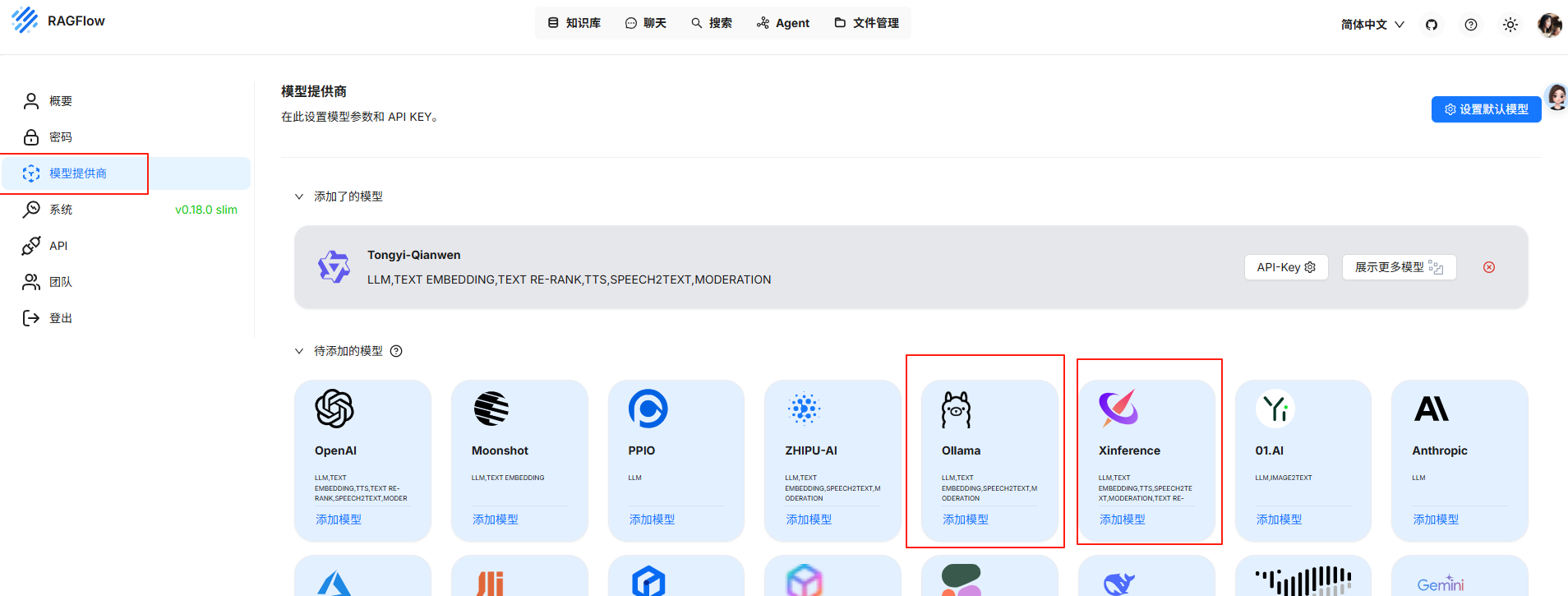
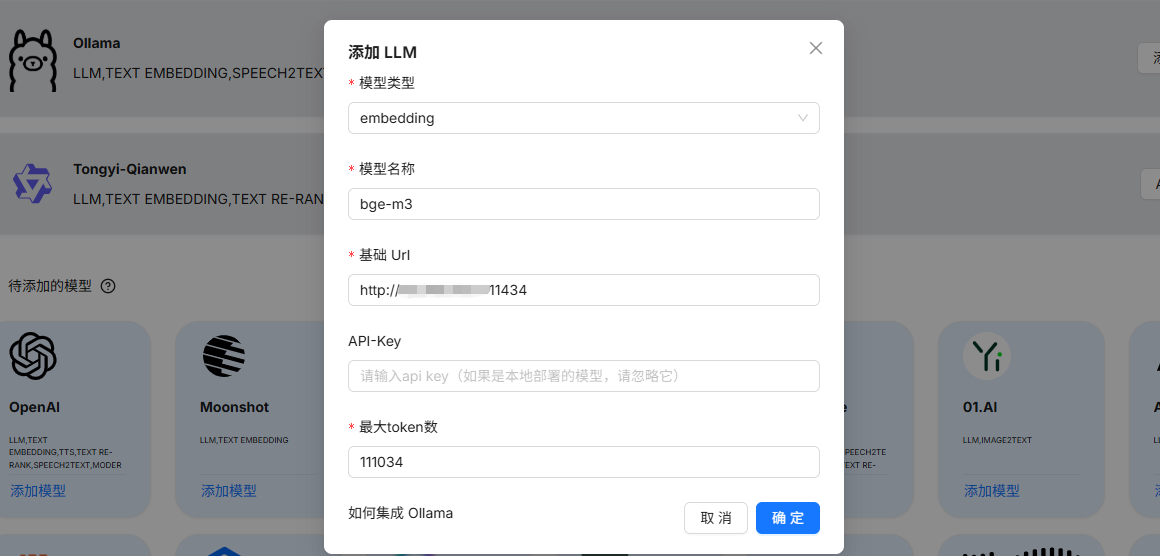
13、添加embedding模型和chat模型
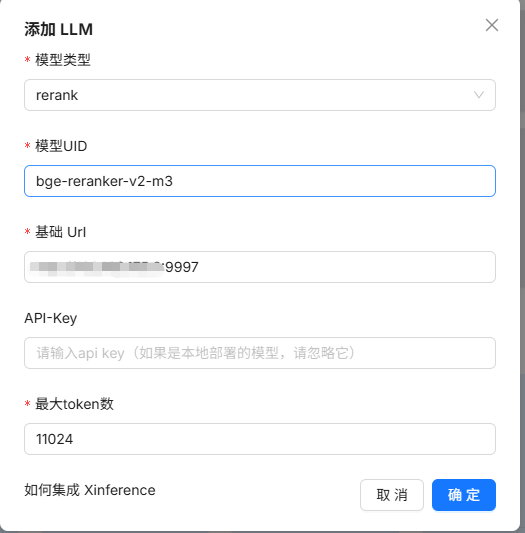
14、添加rerank模型
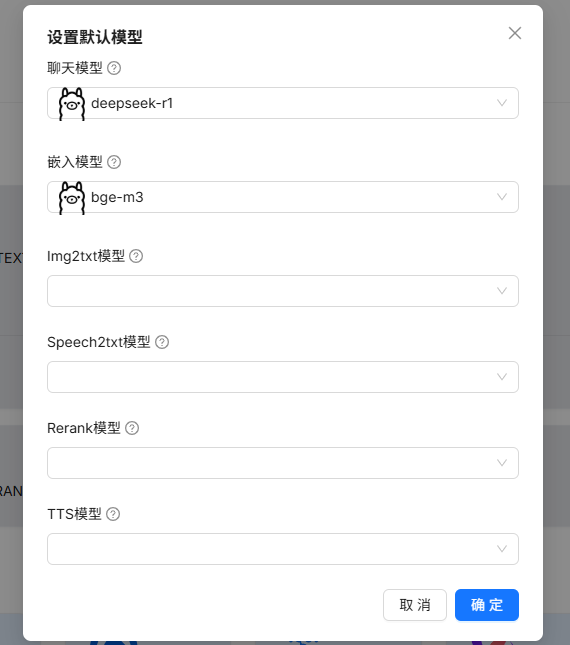
15、设置默认模型
16、知识库上传
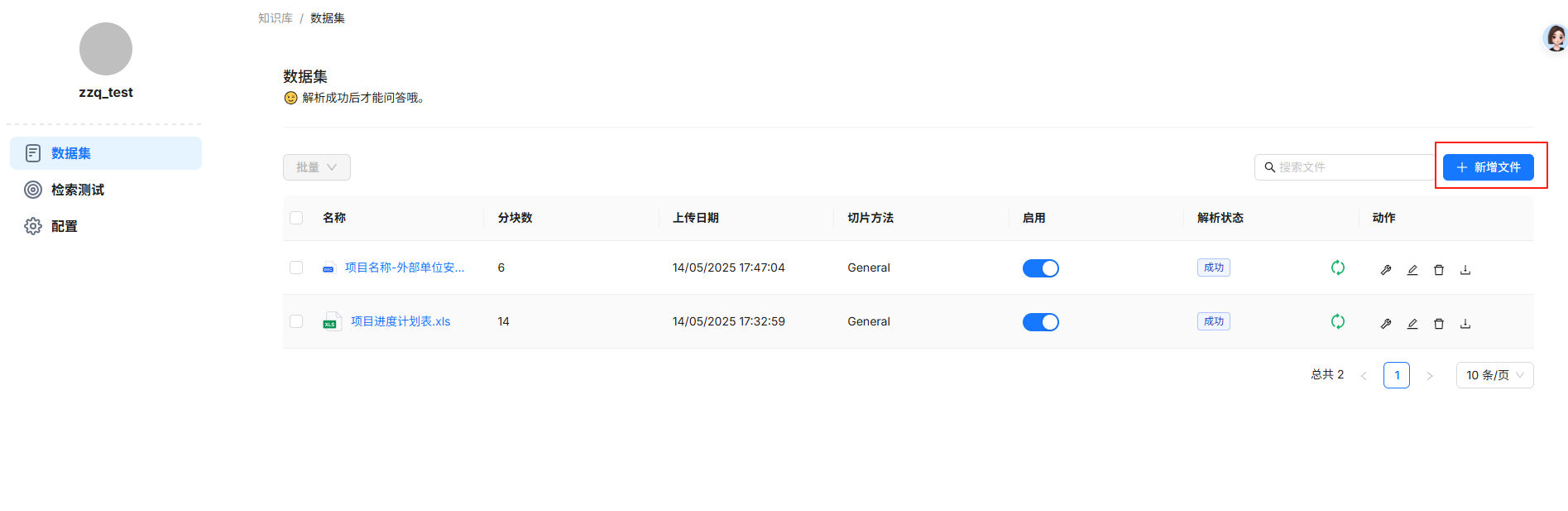
17、知识库测试
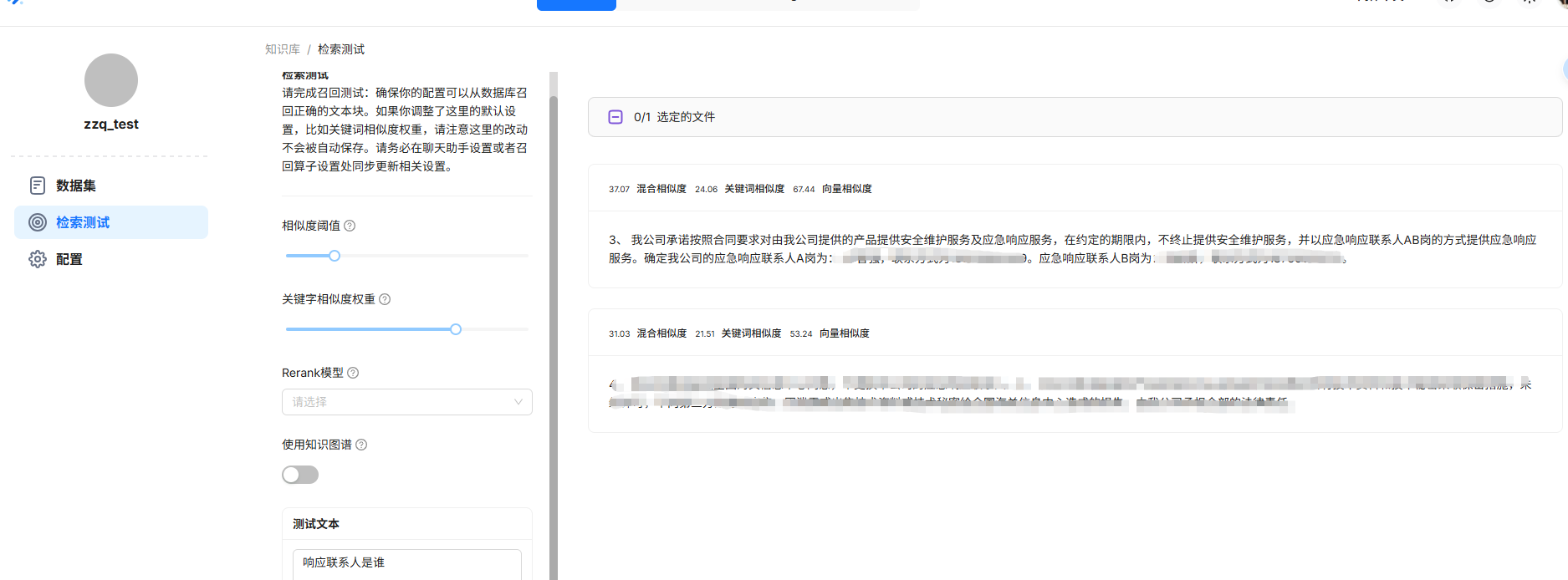
18、聊天模式设置知识库
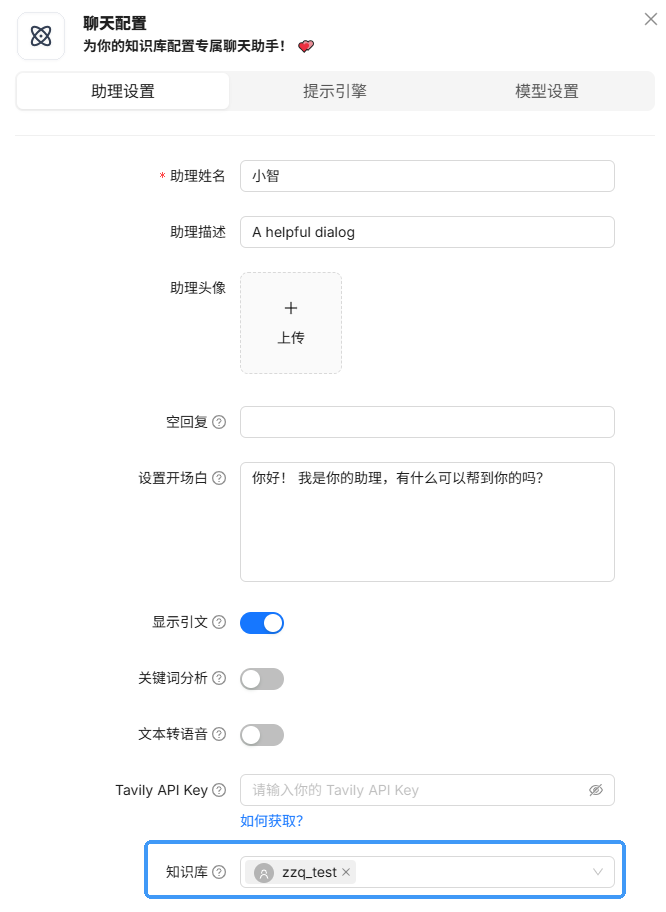
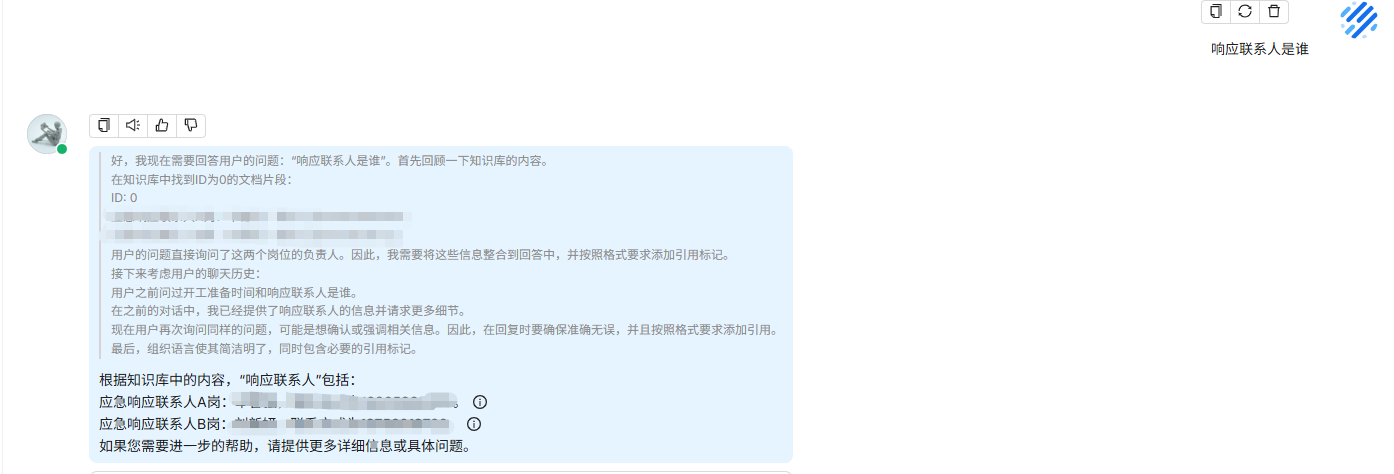
19、聊天测试

 浙公网安备 33010602011771号
浙公网安备 33010602011771号