DFloat11环境搭建&推理测试
引子
很少关注大模型压缩这个领域,碰巧碰上了,那就来吧。为了应对 LLM 不断增长的模型尺寸,通常会采用量化技术,将高精度权重转换为低位表示。这显著减少了内存占用和计算需求,有助于在资源受限的环境中实现更快的推理和部署。然而,量化本质上是一种有损压缩技术,引入了一个基本缺点:它不可避免地改变了 LLMs 的输出分布,从而影响模型的准确性和可靠性。相比之下,无损压缩技术在有效减少 LLM 规模的同时,保留了精确的原始权重,确保模型的输出分布与未压缩表示(例如 BFloat16)完全相同。DFloat11(Dynamic-Length Float),这是一种无损压缩框架,可以在保持与原始模型完全相同的输出的情况下,将 LLM 的规模减少 30%。OK,那就让我们开始吧。
一、模型介绍
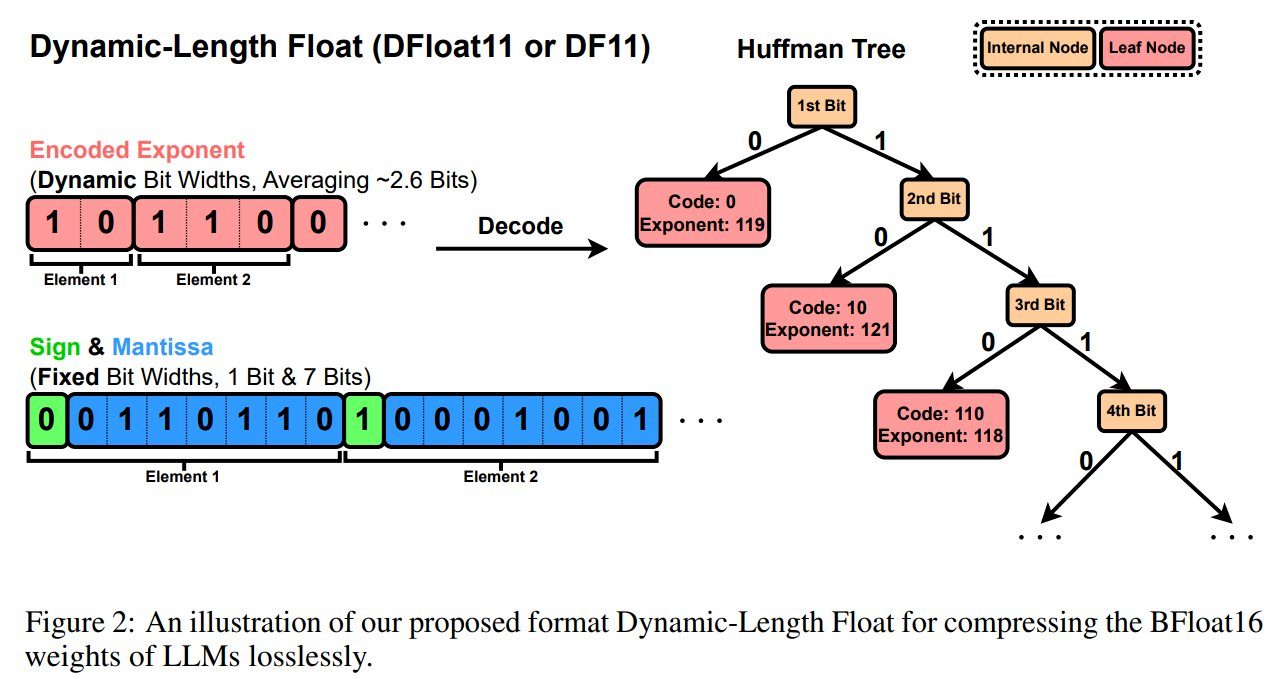
DFloat11 的提出源于当前 LLM 模型中 BFloat16 权重表示的低熵问题,这暴露出现有存储格式存在显著的低效性。通过应用熵编码技术,DFloat11 根据权重出现频率为其分配动态长度编码,在不损失任何精度的情况下实现了接近信息理论极限的压缩效果。
为了支持动态长度编码的高效推理,该研究还开发了定制化的 GPU 内核来实现快速在线解压缩。其设计包含以下内容:
1、将内存密集型查找表(LUT)分解为适应 GPU SRAM 的紧凑型查找表;
2、采用双阶段内核设计,通过轻量级辅助变量协调线程读写位置;
3、实现 Transformer 块级解压缩以最小化延迟。
该研究在 Llama-3.1、Qwen-2.5 和 Gemma-3 等最新模型上进行了实验:DFloat11 能在保持比特级(bit-for-bit)精确输出的同时,将模型体积缩减约 30%。与将未压缩模型部分卸载到 CPU 以应对内存限制的潜在方案相比,DFloat11 在 token 生成吞吐量上实现了 1.9–38.8 倍的提升。在固定 GPU 内存预算下,DFloat11 支持的上下文长度是未压缩模型的 5.3–13.17 倍。值得一提的是,基于该方法 Llama-3.1-405B(810GB)在配备 8×80GB GPU 的单节点上实现了无损推理。
二、环境搭建
1、模型下载
2、环境安装
docker run -it --rm -v /datas/work/zzq/:/workspace --gpus=all --net host pytorch/pytorch:2.4.0-cuda12.4-cudnn9-devel bash
pip install dfloat11[cuda12] -i https://pypi.tuna.tsinghua.edu.cn/simple
三、推理测试
CUDA_VISIBLE_DEVICES=0 python inference.py --model_name_or_path ../DeepSeek-R1-Distill-Qwen-7B --df11_name_or_path DFloat11/Llama-3.1-8B-Instruct-DF11 --prompt "Question: What is a binary tree and its applications? Answer:" --num_tokens 512 --batch_size 1

 浙公网安备 33010602011771号
浙公网安备 33010602011771号