Qwen3环境搭建&推理测试
引子
2025年4月29日,阿里推出Qwen3, 模型依旧采用宽松的 Apache2.0 协议开源,全球开发者、研究机构和企业均可免费在 HuggingFace、魔搭社区等平台下载模型并商用,也可以通过阿里云百炼调用 Qwen3 的 API 服务,具体来讲,Qwen3 系列模型包含两款 MoE 模型以及六款密集模型,其中每一款又包含更多细分版本(比如基础版和量化版)。如下图,OK,那就让我们开始吧。
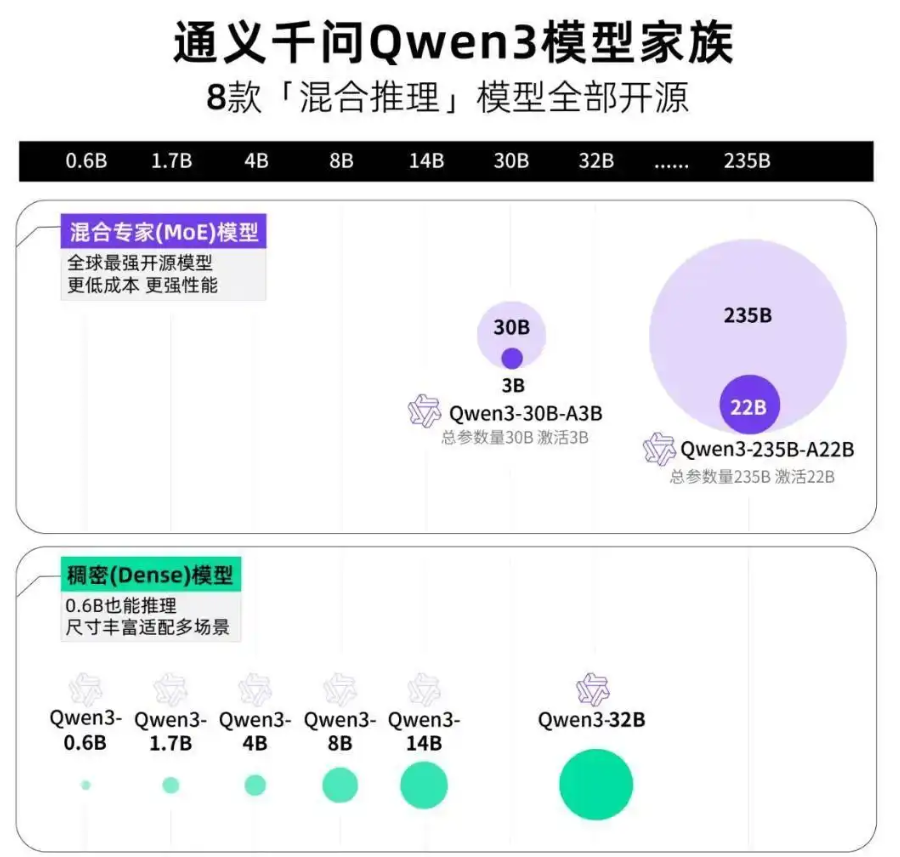
一、模型介绍
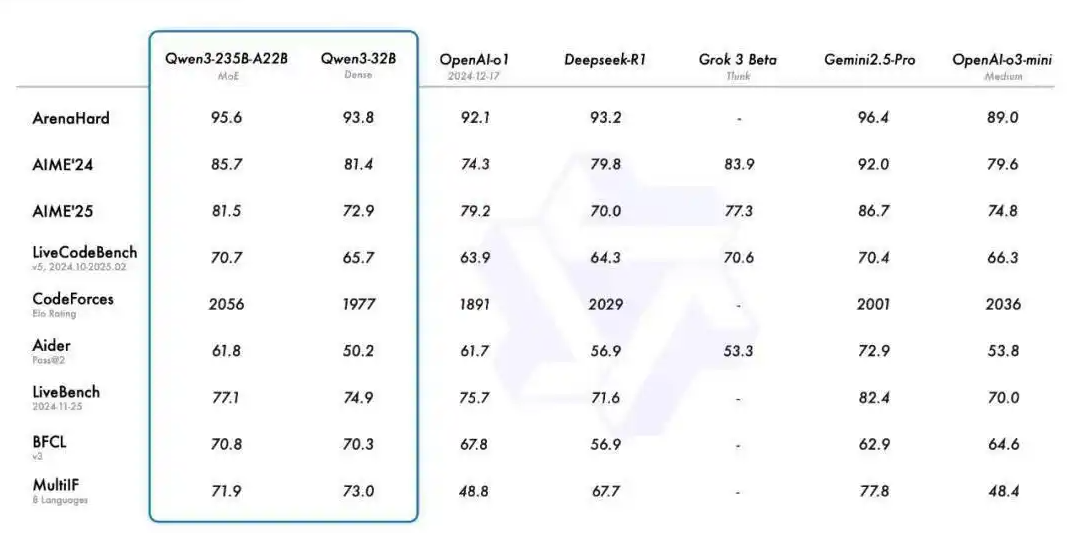
性能方面,在代码、数学、通用能力等基准测试中,旗舰模型 Qwen3-235B-A22B 与 DeepSeek-R1、o1、o3-mini、Grok-3 和 Gemini-2.5-Pro 等顶级模型表现相当。
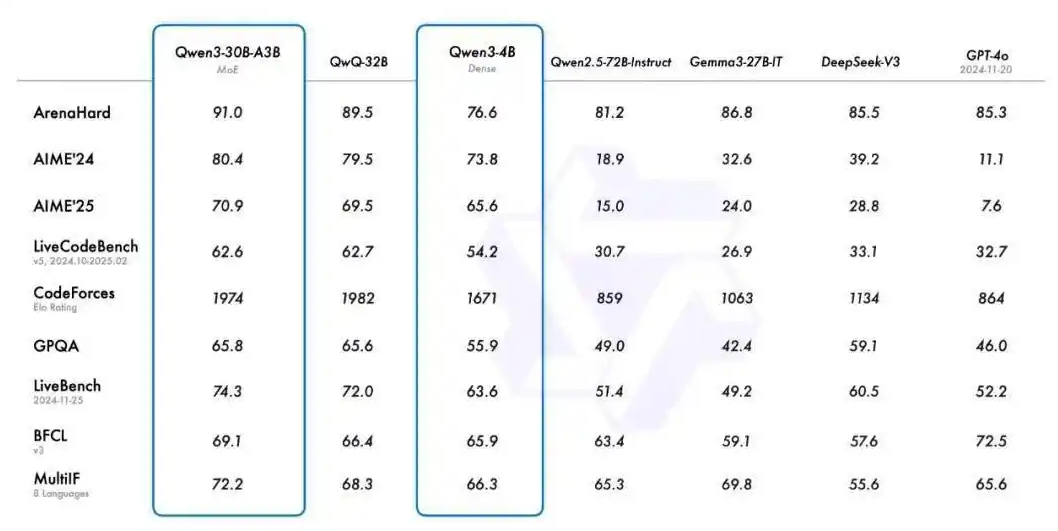
此外,小型 MoE 模型 Qwen3-30B-A3B 的激活参数数量是 QwQ-32B 的 10%,表现却更胜一筹。甚至像 Qwen3-4B 这样的小模型也能匹敌 Qwen2.5-72B-Instruct 的性能。
性能大幅提升的同时,Qwen3 的部署成本还大幅下降,仅需 4 张 H20 即可部署满血版,显存占用仅为性能相近模型的三分之一。
开发团队也在博客中给出了一些推荐设置:对于部署,我们推荐使用 SGLang 和 vLLM 等框架;而对于本地使用,像Ollama、LMStudio、MLX、llama.cpp 和 KTransformers 这样的工具也非常值得推荐。这些选项确保用户可以轻松将 Qwen3 集成到他们的工作流程中,无论是用于研究、开发还是生产环境。
三大核心功能
1、支持两种思考模式
思考模式,模型逐步推理,经过深思熟虑后给出最终答案,尤其适合需要深入思考的复杂问题。
非思考模式,模型提供快速、近乎即时的响应,适用于那些对速度要求高于深度的简单问题。
2、支持更多语言
目前,Qwen3 模型支持 119 种语言和方言。增强的多语言能力为国际应用开辟了新的可能性,可以让更广泛的全球用户体验到模型的强大能力。
3、Agent 能力增强
Agent 已经是大模型领域重点关注的能力之一,尤其是最近 MCP 模型上下文协议的引入更是大大增强了 Agent 的适用性和灵活性,大大拓宽了应用场景。
二、环境搭建
1、模型下载
modelscope download --model Qwen/Qwen3-4B --local_dir ./Qwen3-4B
2、环境安装
docker run -it --rm --gpus=all -v /datas/work/zzq:/workspace pytorch/pytorch:2.4.0-cuda12.4-cudnn9-devel bash
pip install transformers -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install accelerate -i https://pypi.tuna.tsinghua.edu.cn/simple
三、推理测试
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen3-4B"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# prepare the model input
prompt = "Give me a short introduction to large language models."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True # Switches between thinking and non-thinking modes. Default is True.
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# the result will begin with thinking content in <think></think> tags, followed by the actual response
print(tokenizer.decode(output_ids, skip_special_tokens=True))
python test.py


 浙公网安备 33010602011771号
浙公网安备 33010602011771号