Dream 7B推理模型环境搭建&推理测试
引子
语言是离散的,所以适合用自回归模型来生成;而图像是连续的,所以适合用扩散模型来生成。在生成模型发展早期,这种刻板印象广泛存在于很多研究者的脑海中。写了那么多主流自回归的大模型部署文档,刚巧碰到这篇反其道而行的基于扩散模型的大模型。挺有意思,OK,那就让我们开始吧。
一、模型介绍
最近,更多的研究者开始探索在图像生成中引入自回归(如 GPT-4o),在语言生成中引入扩散。香港大学和华为诺亚方舟实验室的一项研究就是其中之一。他们刚刚发布的扩散推理模型 Dream 7B 拿下了开源扩散语言模型的新 SOTA,在各方面都大幅超越现有的扩散语言模型。在通用能力、数学推理和编程任务上,这个模型展现出了与同等规模顶尖自回归模型(Qwen2.5 7B、LLaMA3 8B)相媲美的卓越性能,在某些情况下甚至优于最新的 Deepseek V3 671B(0324)。
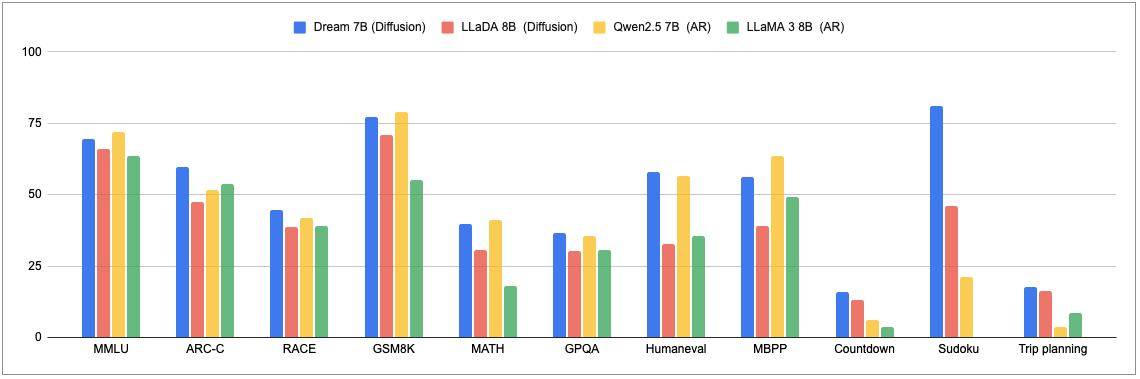
随着我们发现 自回归(AR) 模型在规模化应用中显现出一系列局限 —— 包括复杂推理能力不足、长期规划困难以及难以在扩展上下文中保持连贯性等挑战,这个问题变得愈发重要。这些限制对新兴应用领域尤为关键,如具身 AI、自主智能体和长期决策系统,这些领域的成功依赖于持续有效的推理和深度的上下文理解。
离散扩散模型(DM)自被引入文本领域以来,作为序列生成的极具潜力的替代方案备受瞩目。与 AR 模型按顺序逐个生成 token 不同,离散 DM 从完全噪声状态起步,同步动态优化整个序列。这种根本性的架构差异带来了几项显著优势:
1、双向上下文建模使信息能够从两个方向更丰富地整合,大大增强了生成文本的全局连贯性。
2、通过迭代优化过程自然地获得灵活的可控生成能力。
3、通过新颖的架构和训练目标,使噪声能够高效直接映射到数据,从而实现基础采样加速的潜力。
近期,一系列重大突破凸显了扩散技术在语言任务中日益增长的潜力。DiffuLLaMA 和 LLaDA 成功将扩散语言模型扩展至 7B 参数规模,而作为商业实现的 Mercury Coder 则在代码生成领域展示了卓越的推理效率。这种快速进展,结合扩散语言建模固有的架构优势,使这些模型成为突破自回归方法根本局限的极具前景的研究方向。
二、环境搭建
模型下载,
docker run -it --rm --gpus=all -v /datas/work/zzq/:/workspace pytorch/pytorch:2.5.1-cuda12.4-cudnn9-devel bash
pip install transformers==4.46.2 -i https://pypi.tuna.tsinghua.edu.cn/simple
三、推理测试
测试代码:
import torch
from transformers import AutoModel, AutoTokenizer
model_path = "Dream-Instruct-7B"
model = AutoModel.from_pretrained(model_path, torch_dtype=torch.float16, trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model = model.to("cuda").eval()
messages = [
{"role": "user", "content": "Please write a Python class that implements a PyTorch trainer capable of training a model on a toy dataset."}
]
inputs = tokenizer.apply_chat_template(
messages, return_tensors="pt", return_dict=True, add_generation_prompt=True
)
input_ids = inputs.input_ids.to(device="cuda")
attention_mask = inputs.attention_mask.to(device="cuda")
output = model.diffusion_generate(
input_ids,
attention_mask=attention_mask,
max_new_tokens=512,
output_history=True,
return_dict_in_generate=True,
steps=512,
temperature=0.2,
top_p=0.95,
alg="entropy",
alg_temp=0.,
)
generations = [
tokenizer.decode(g[len(p) :].tolist())
for p, g in zip(input_ids, output.sequences)
]
print(generations[0].split(tokenizer.eos_token)[0])

 浙公网安备 33010602011771号
浙公网安备 33010602011771号