python生成器和模块
生成器对象
# 本质其实还是迭代器 只不过是我们自己通过写代码产生
也是有__iter__和__next__方法
#举例说明:
假如我们定义了一个泡茶的函数(迭代器),然后将泡茶步骤的方法封装进这个函数。每一次调用这个函数就返回一个步骤,并保存好当前执行到哪个状态。如果中途有事,比如我们执行到步骤二的时候突然去接了个电话,回来调用这个函数就会得到步骤三(水开了,就开始泡茶),也就是状态保存好了。我们可以执行这个泡茶函数直到调用完所有步骤为止。
定义一个方法,这个方法是一步步执行的,并能保存状态,这就是迭代器。
#代码示例:
def index():
print("泡茶流程")
yield 1
print("煮水")
yield 2
print("拿出茶叶")
yield 3
print("泡茶")
res= index() # 没有调用之前 就是一个普通的函数
'加括号调用并接收结果:不执行代码 而是变成生成器对象(迭代器)
'
'变成生成器对象之后调用__next__就会开始执行函数体代码'
print(res.__next__()) # 泡茶流程 1
print(res.__next__()) # 煮水 2
print(res.__next__()) # 拿出茶叶 3
"""
如果函数体代码中含有多个yield关键字 执行一次__next__返回后面的值并且让代码停留在yield位置
再次执行__next__基于上次的位置继续往后执行到下一个yield关键字处
如果没有了 再执行也会报错 StopIteration
"""
自定义range方法
# range方法其实是一个可迭代对象
for i in range(1, 10):
print(i)
通过生成器模拟range方法:
#代码示例:
def my_range(n,m):
while n < 10:
yield n
n += 1
res = my_range(0,10)
for i in res:
print(i)
#以两个参数的range方法为例:
def my_range(start, end=None, step=1):
#end可以不传值 应该设置成默认参数 end=None
if not end: # 没有给end传值 my_range(10)
end = start #代码层面做判断 将形参数据做替换处理
start = 0
while start < end:
yield start
start += step
for i in my_range(1,100):
print(i)
''' 给函数添加第三个形参 并且设置成默认参数 默认值是1 step=1
每次递增的时候只需要递增step的数值即可
start += step'''
yield关键字作用
# 1.在函数体代码中出现 可以将函数变成生成器
# 2.在执行过程中 可以将后面的值返回出去 类似于return
# 3.还可以暂停住代码的运行
# 4.还可以接收外界的传值(了解)
#代码示例:
def createGenerator():
mylist = range(3)
for i in mylist:
yield i*i
mygenerator = createGenerator() # create a generator
print(mygenerator) # mygenerator is an object!
for i in mygenerator:
print(i)
#sent()函数
最重要的作用在于它可以给yield对应的赋值语句赋值 并且自动调用一次__next__方法
生成器表达式
# 也是为了节省存储空间
在后期我们做代码优化的时候 可以考虑使用 前期学习阶段可以忽略
res = (i for i in 'jason')
print(res) # <generator object <genexpr> at 0x1130cf468>
print(res.__next__())
"""生成器内部的代码只有在调用__next__迭代取值的时候才会执行"""
'''一个生成器对象一定是迭代器对象,是可迭代的;但是一个迭代器对象不一定是生成器对象;生成器和迭代器是两个不同的对象'''
# 普通的求和函数
def add(n, i):
return n + i
# 生成器对象 返回 0 1 2 3
def test():
for i in range(4):
yield i
# 将test函数变成生成器对象
g = test()
# 简单的for循环
for n in [1, 10]:
g = (add(n, i) for i in g)
"""
第一次for循环
g = (add(n, i) for i in g)
第二次for循环
g = (add(10, i) for i in (add(10, i) for i in g))
"""
res = list(g) # list底层就是for循环 相当于对g做了迭代取值操作
print(res)
#A. res=[10,11,12,13]
#B. res=[11,12,13,14]
#C. res=[20,21,22,23]
#D. res=[21,22,23,24]
"""正确答案是C 诀窍就是抓n是多少即可"""

模块
#模块的定义:
模块是一个包含所有你定义的函数和变量的文件,其后缀名是.py。模块可以被别的程序引入,以使用该模块中的函数等功能。这也是使用 python 标准库的方法
eg:
import time 导入模块
time.time() 调用方法
'''一个模块编写完毕之后 其他模块直接调用 不用再从零开始写代码了节约了工作时间;
避免函数名称和变量名称重复 在不同的模块中可以存在相同名字的函数名和变量名'''
# 1.什么是模块?
模块就是一系列功能的结合体 可以直接使用
# 2.为什么要用模块?
1.用别人写好的模块(内置的 第三方的):典型的拿来主义 极大的提高开发效率
2.使用自己写的模块(自定义的):当程序比较庞大的时候 你的项目不可能只在一个py中那么当多个文件中都需要使用相同的方法的时候 可以将该公共的方法写到一个py文件中其他的文件以模块的形式导过去直接调用即可
# 3.模块的三种来源
1.内置的模块
无需下载 解释器自带 直接导入使用即可
2.自定义模块
自己写的代码 封装成模块 自己用或者发布到网上供别人使用
3.第三方模块
别人写的发布到网上的 可以下载使用的模块(很多牛逼的模块都是第三方)
# 4.模块的四种表现形式
1.使用python代码编写的py文件
2.多个py文件组成的文件夹(包)
'(文件夹下有一个__init__.py文件,该文件夹称之为包)'
3.已被编译为共享库或DLL的c或C++扩展(了解)
4.使用C编写并链接到python解释器的内置模块(了解)
# 模块的查找顺序是:
先从内存中找,内存中没的话会去内置中找,内置中找不到的话会去sys.path中找(环境变量)
模块的两种导入方式
方式1>>>:import...句式
#我们先自定义一个模块 名为md.py;
print("hello world")
name = "fan"
def func1():
print("fan1")
def func2():
print("fan2")
func()
#然后我们使用里一个py文件进行导入这个模块;
import md #有效
import md #无效
import md #无效
#打印输出:
hello world # 获取模块名称空间中的print
#可以发现只打印了一次,是因为每次导入模块时,解释器都回去检查一下这个模块有没有之前被导过,多次导入不会再执行模块文件。
#模块导入的过程:
1.找到这个需导入的模块;
2.判断这个模块是否被导入过;
#如果没有被导入过:
创建一个属于这个模块的命名空间;如果用户没有定义变量来引用这个模块的内存地址的话,
那么就使用模块的名称来引用这个模块的内存地址;如果用户使用as来指定变量接受这个内存地址的话,
那么就将内存地址赋值给这个变量;且下文在调用时只能使用这个变量进行调用不能再使用模块名进行调用了,然后执行这个模块中的代码。
#如果该模块已经被导入过:
那么解释器不会重新执行模块内的语句,后续的import语句仅仅是对已经加载到内存中的模块的对象
#关于导入的模块与当前空间的关系:
带入的模块会重新开辟一块独立的名称空间,定义在这个模块中的函数把这个模块的命名空间当做全局命名空间,
这样的话当前的空间就和模块运行的空间分隔了,谁也不影响谁;
#为模块起别名:
模块在导入的时候开辟了新空间内存,默认是使用模块的名称来引用这个内存地址的,有时候模块的名称很长再加上执行调用里面的功能的时候,
就显的很不方便,为了更好的使用模块,我们可以给模块起别名;也就是在导入模块的时候我们不让它使用默认的名字来引用内存地址,
而是由我们自己定义的变量来引用这个模块的内存地址;
方法:import mdddddddddd as md
这样的话就表示使用变量md来引用这个内存地址,然后我们在文中再使用这个模块的时候,只要使用md来调用这个模块里的功能即可。
方式2>>>:from...import...句式
# 方式2>>>:from...import...句式
from md import name,money,read1
# print(name) # jasonNB
# name = 'kevin'
# print(name) # kevin
print(money) # 报错 from md import name 只使用模块中的name名字
read1()
"""
1.执行当前文件产生一个名称空间
2.执行导入语句 运行模块文件产生名称空间存放运行过程中的所有名字
3.将import后面的名字直接拿到当前执行文件中
"""
"""
1.重复导入也只会导入一次
2.使用模块名称空间中的名字不需要加模块名前缀 直接使用即可
3.但是from...import的句式会产生名字冲突的问题
在使用的时候 一定要避免名字冲突
4.使用from...import的句式 只能使用import后面出现的名字
from...import...可以简单的翻译成中文
从...里面拿...来用 没有提到的都不能用 指名道姓
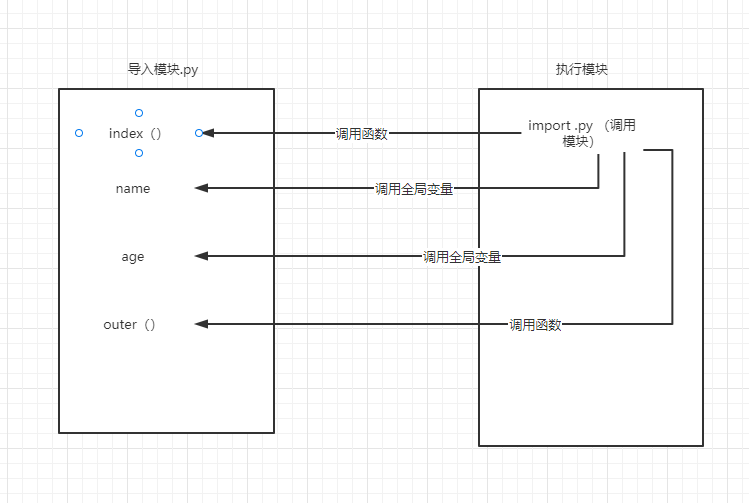
导入补充
# 连续导入多个模块或者变量名
import time, sys, md
from md import name, read1, read2
"""连续导入多个模块 这多个模块最好有相似的功能部分 如果没有建议分开导入
如果是同一个模块下的多个变量名无所谓!!!
"""
import time
import sys
import md
# 通用导入
from md import *
'''*表示md里面所有的名字 from...import的句式也可以导入所有的名字
如果模块文件中使用了__all__限制可以使用的名字 那么*号就会失效 依据__all__后面列举的名字
模块的绝对导入和相对导入
绝对导入的格式为 import A.B 或 from A import B,
相对导入格式为 from . import B 或 from ..A import B,
.代表当前模块,..代表上层模块,...代表上上层模块,依次类推。
相对导入可以避免硬编码带来的维护问题,例如我们改了某一顶层包的名,那么其子包所有的导入就都不能用了。但是存在相对导入语句的模块,不能直接运行,否则会有异常:
如果是绝对导入,一个模块只能导入自身的子模块或和它的顶层模块同级别的模块及其子模,
如果是相对导入,一个模块必须有包结构且只能导入它的顶层模块内部的模块所以,如果一个模块被直接运行,则它自己为顶层模块,不存在层次结构,所以找不到其他的相对路径,所以如果直接运行python xx.py ,而xx.py有相对导入就会报错
#代码示例:
# 绝对导入
import sys, os
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
sys.path.append(BASE_DIR)
# 相对导入:
import sys, os
from . import models
from ..proj import settings
"""
绝对导入必须依据执行文件所在的文件夹路径为准
绝对导入无论在执行文件中还是被导入文件都适用
相对导入
.代表的当前路径
..代表的上一级路径
...代表的是上上一级路径
相对导入不能再执行文件中使用
相对导入只能在被导入的模块中使用,使用相对导入 就不需要考虑
执行文件到底是谁 只需要知道模块与模块之间路径关系
"""
软件开发目录规范:
1.首先是项目名:
2.bin 文件夹:
start.py 启动文件
3.conf 文件夹:
settings.py 项目配置文件
4.core 文件夹:
src.py 项目核心逻辑
5.db 文件夹:
数据库相关文件
6.lib 文件夹:
common.py 项目所用到的公共功能
7.log 文件夹:
log.log 项目的日志文件
8.Readme:
文本文件:项目简介


 浙公网安备 33010602011771号
浙公网安备 33010602011771号