第六次作业
作业①
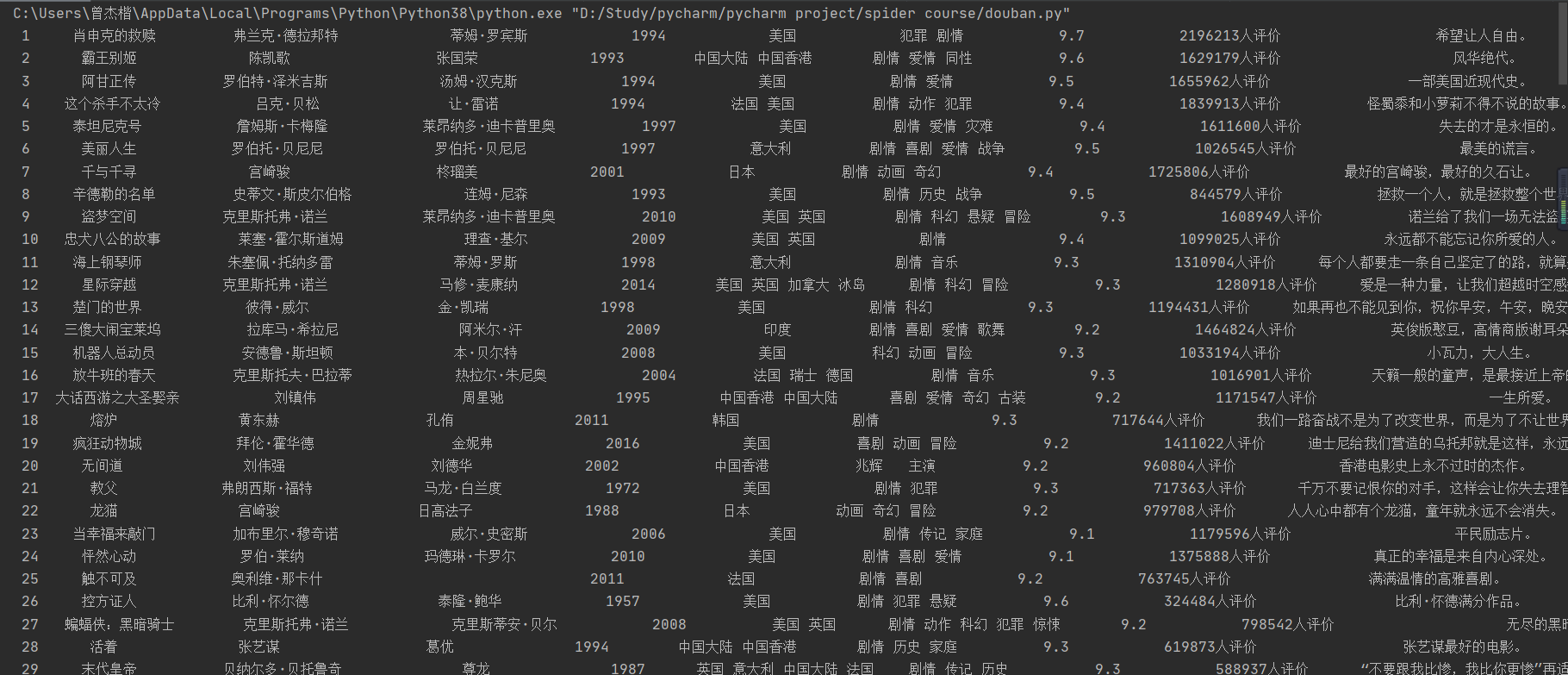
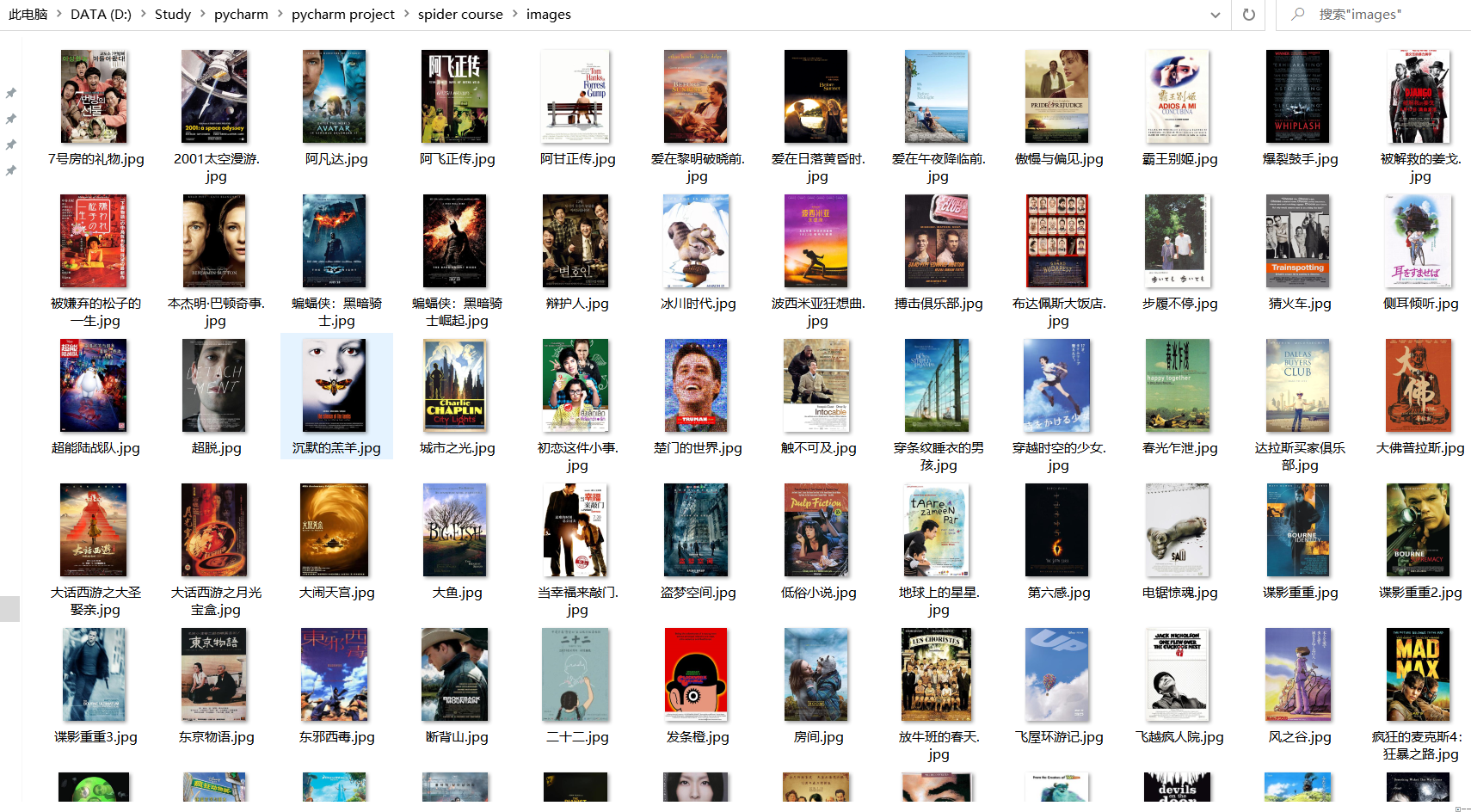
1)、用requests和BeautifulSoup库方法爬取豆瓣电影Top250数据。
douban.py
import re
import urllib.request
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import threading
count = 0
def imageSpider(start_url):
global threads
try:
urls=[]
req = urllib.request.Request(start_url,headers=headers)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data,["utf-8","gbk"])
data = dammit.unicode_markup
soup = BeautifulSoup(data,"lxml")
movies = soup.select("div[class='article'] ol[class='grid_view'] li")
for movie in movies:
try:
name = movie.select("div[class='info'] div[class='hd'] span[class='title']")[0].text
src = movie.select("div[class='pic'] a img")[0].attrs["src"]
url = urllib.request.urljoin(start_url, src)
if url not in urls:
#print(url)
T = threading.Thread(target=download, args=(url, name))
T.setDaemon(False)
T.start()
threads.append(T)
except Exception as err:
print(err)
except Exception as err:
print(err)
def download(url, name):
try:
if url[len(url) - 4]== ".":
ext=url[len(url) - 4:]
else:
ext=""
req = urllib.request.Request(url,headers=headers)
data = urllib.request.urlopen(req, timeout=100)
data = data.read()
fobj =open("images\\"+name+ext, "wb")
fobj.write(data)
fobj.close()
#print("download"+name+ext)
except Exception as err:
print(err)
def InformationSpider(start_url):
global count
try:
req = urllib.request.Request(start_url, headers=headers)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data, ["utf-8", "gbk"])
data = dammit.unicode_markup
soup = BeautifulSoup(data, "lxml")
movies = soup.select("div[class='article'] ol[class='grid_view'] li")
for movie in movies:
try:
name = movie.select("div[class='info'] div[class='hd'] span[class='title']")[0].text
# print(name)
information = movie.select("div[class='info'] div[class='bd'] p")[0].text.replace("\n", "")
# print(information)
try:
reg_director = r"导演: [\u4e00-\u9fa5_a-zA-Z0-9_]{2,10}·[\u4e00-\u9fa5_a-zA-Z0-9_]{2,10}" # 导演是外国人
m = re.search(reg_director, information)
start = m.start()
end = m.end()
director = information[start + 3:end]
except:
reg_director = r"导演: [\u4e00-\u9fa5_a-zA-Z0-9_]{2,10}" # 导演是中国人
m = re.search(reg_director, information)
start = m.start()
end = m.end()
director = information[start + 3:end]
# print(director)
try:
reg_actor = r"主演: [\u4e00-\u9fa5_a-zA-Z0-9_]{1,10}·[\u4e00-\u9fa5_a-zA-Z0-9_]{1,10}" # 主演是外国人
m1 = re.search(reg_actor, information)
start1 = m1.start()
end1 = m1.end()
actor = information[start1 + 3:end1]
except:
reg_actor = r"主演: [\u4e00-\u9fa5_a-zA-Z0-9_]{1,10}" # 主演是中国人
m1 = re.search(reg_actor, information)
# print(m1)
try:
start1 = m1.start()
end1 = m1.end()
actor = information[start1 + 3:end1]
except: # 有个别影片因为导演名称太长,主演没有显示出来。。。因此为空
actor = " "
# print(actor)
reg_year = r"\d+\s/" # 年份
m = re.search(reg_year, information)
year = information[m.start():m.end() - 1]
# print(year)
reg_nation = r"\d+\s/\s([\u4e00-\u9fa5_a-zA-Z0-9_]\s*)+\s*" # 国家
m = re.search(reg_nation, information)
nation = information[m.start() + len(year) + 2:m.end()]
# print(nation)
reg_type = r"([\u4e00-\u9fa5_]\s*)+\s*\s/\s([\u4e00-\u9fa5_a-zA-Z0-9_]\s*)+\s*" # 影片类型
m = re.search(reg_type, information)
type = information[m.start() + len(nation) + 2:m.end()]
# print(type)
score = movie.select("div[class='info'] div[class='bd'] div[class='star'] span[class='rating_num']")[
0].text
num = movie.select("div[class='info'] div[class='bd'] div[class='star'] span")[3].text
quote = movie.select("div[class='info'] div[class='bd'] p[class='quote']")[0].text
count += 1
print("{:^4}{:^12}{:^20}{:^20}{:^15}{:^15}{:^15}{:^15}{:^20}{:>20}".format(count, name.rstrip(),
director.rstrip(), actor,
year, nation, type.rstrip(),
score, num, quote.strip(),
chr(12288)))
except Exception as err:
print(err)
except Exception as err:
print(err)
#start_url = "https://movie.douban.com/top250?start=0&filter="
headers = {"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
threads=[]
for page in range(0,250,25):
start_url = "https://movie.douban.com/top250?start="+str(page)+"&filter="
InformationSpider(start_url)
imageSpider(start_url)
for t in threads:
t.join()
2)、心得体会
本题是使用requests和BeautifulSoup库的方法来对电影信息进行爬取,同时并采取多线程的方法对图片进行下载。这道题目让我很好地复习了requests和BeautifulSoup库的知识以及多线程下载图片的使用方法。同时在爬取的过程中,通过观察网站的布局,发现其中的导演、主演、年份、电影类型等信息是一坨放在一起的,因此还需要通过正则表达式来将其中的信息给提取出来,于是我又因此学习了如何对中文进行匹配,从而取出想要的信息。
作业②
1)、爬取科软学校排名,并获取学校的详细链接,进入下载学校Logo存储、获取官网Url、院校信息等内容
shanghairanking.py
import urllib
from schoolrank.items import SchoolrankItem
import scrapy
from bs4 import UnicodeDammit
class ShanghairankingSpider(scrapy.Spider):
name = 'shanghairanking'
headers = {"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
count = 1
def start_requests(self):
url = 'https://www.shanghairanking.cn/rankings/bcur/2020'
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
try:
url_init = "https://www.shanghairanking.cn"
dammit = UnicodeDammit(response.body, ["utf-8", "gbk"])
data = dammit.unicode_markup
selector = scrapy.Selector(text=data)
schools = selector.xpath("//table[@class ='rk-table']//tbody//tr")
for school in schools:
name = school.xpath("./td[position()=2]//a/text()").extract_first()
city = school.xpath("./td[position()=3]/text()").extract_first()
school_url = school.xpath("./td[position()=2]//a/@href").extract_first()
url_final = urllib.request.urljoin(url_init, school_url)
req1 = urllib.request.Request(url_final, headers=self.headers)
data1 = urllib.request.urlopen(req1)
data1 = data1.read()
dammit = UnicodeDammit(data1, ["utf-8", "gbk"])
data1 = dammit.unicode_markup
selector1 = scrapy.Selector(text=data1)
info = selector1.xpath("//div[@class='univ-introduce']//p/text()").extract_first()
image_url = selector1.xpath("//td[@class='univ-logo']//img/@src").extract_first()
item = SchoolrankItem()
item["rank"] = self.count
item["name"] = name.strip() if name else ""
item["city"] = city.strip() if city else ""
item["school_url"] = url_final if url_final else ""
item["info"] = info.strip() if info else ""
item["mfile"] = str(self.count)+".jpg"
print("{:^2}{:^10}{:^10}{:^10}{:^10}".format(self.count, name.strip(), city.strip(),
url_final, info.strip()))
self.download(image_url, str(self.count))
yield item
self.count += 1
except Exception as err:
print(err)
def download(self, url, image_name):
try:
if url[len(url) - 4] == ".":
ext = url[len(url) - 4:]
else:
ext = ""
req = urllib.request.Request(url, headers=self.headers)
data = urllib.request.urlopen(req, timeout=100)
data = data.read()
fobj = open("logo\\" + image_name + ext, "wb")
fobj.write(data)
fobj.close()
except Exception as err:
print(err)
pipelines.py
import pymysql
class SchoolrankPipeline(object):
def open_spider(self, spider):
print("opened")
try:
self.con = pymysql.connect(host="127.0.0.1", port=3308, user="root",passwd = "root", db = "mydb", charset = "utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute("DROP TABLE IF EXISTS schoolrank")
# 创建表
self.cursor.execute("CREATE TABLE IF NOT EXISTS schoolrank(sNo INT PRIMARY KEY,"
"schoolName VARCHAR(32),"
"city VARCHAR(32),"
"officalUrl VARCHAR(256),"
"info VARCHAR(512),"
"mfile VARCHAR(32))")
self.opened = True
self.count = 0
except Exception as err:
print(err)
self.opened = False
def close_spider(self, spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened = False
print("closed")
def process_item(self, item, spider):
try:
if self.opened:
self.cursor.execute(
"insert into schoolrank (sNo,schoolName,city,officalUrl,info,mfile) values( % s, % s, % s, % s, % s, % s)",
(item["rank"], item["name"], item["city"], item["school_url"], item["info"], item["mfile"]))
except Exception as err:
print(err)
return item
items.py
import scrapy
class SchoolrankItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
rank = scrapy.Field()
name = scrapy.Field()
city = scrapy.Field()
school_url = scrapy.Field()
info = scrapy.Field()
mfile = scrapy.Field()
settings.py
ITEM_PIPELINES = {
'schoolrank.pipelines.SchoolrankPipeline': 300,
}
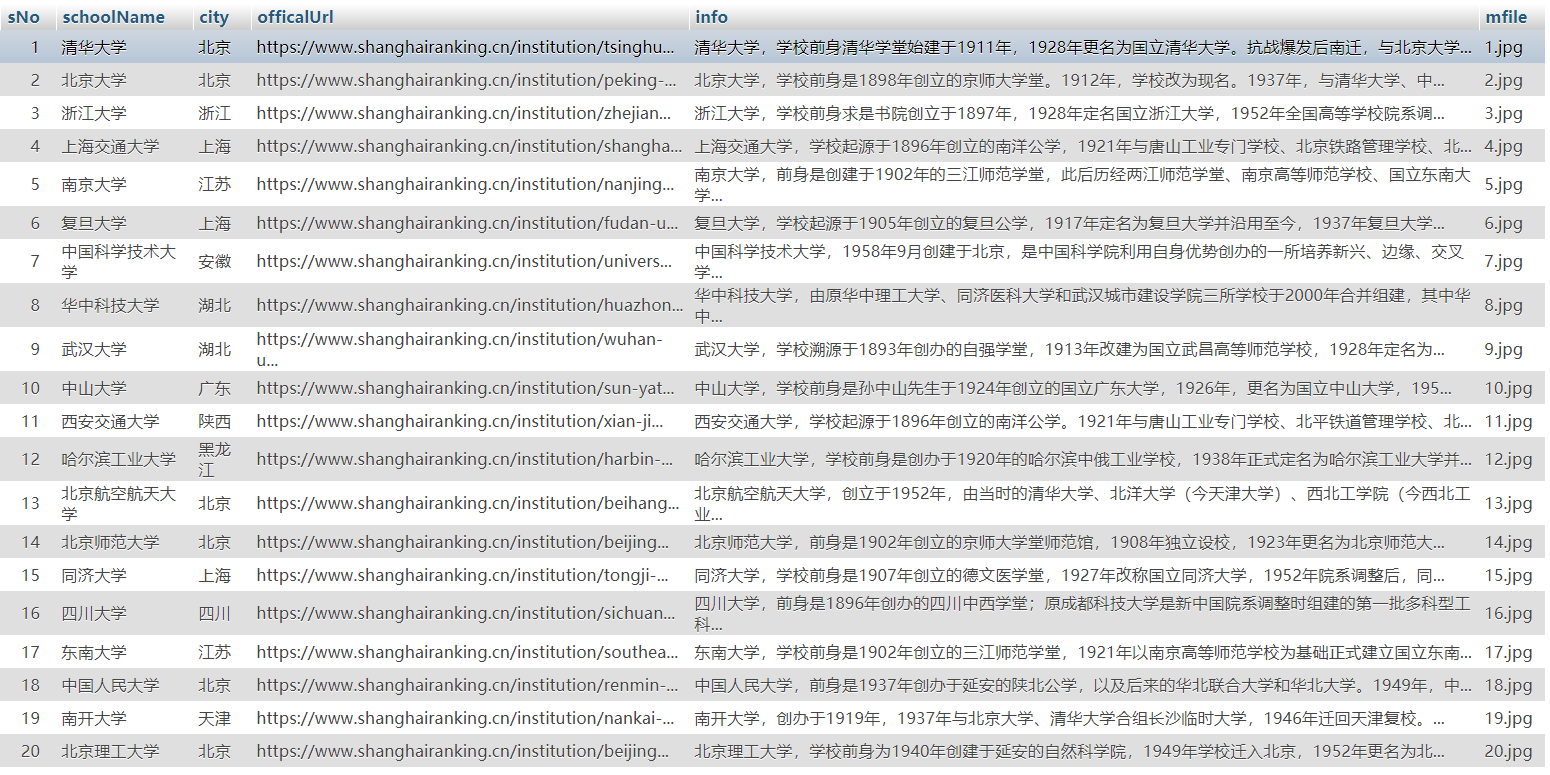

2)、心得体会
本次作业主要是对于scrapy框架的应用,通过此次的实验让我很好的回顾了scrapy框架的知识点,同时也熟练了xpath的使用方法。
作业③
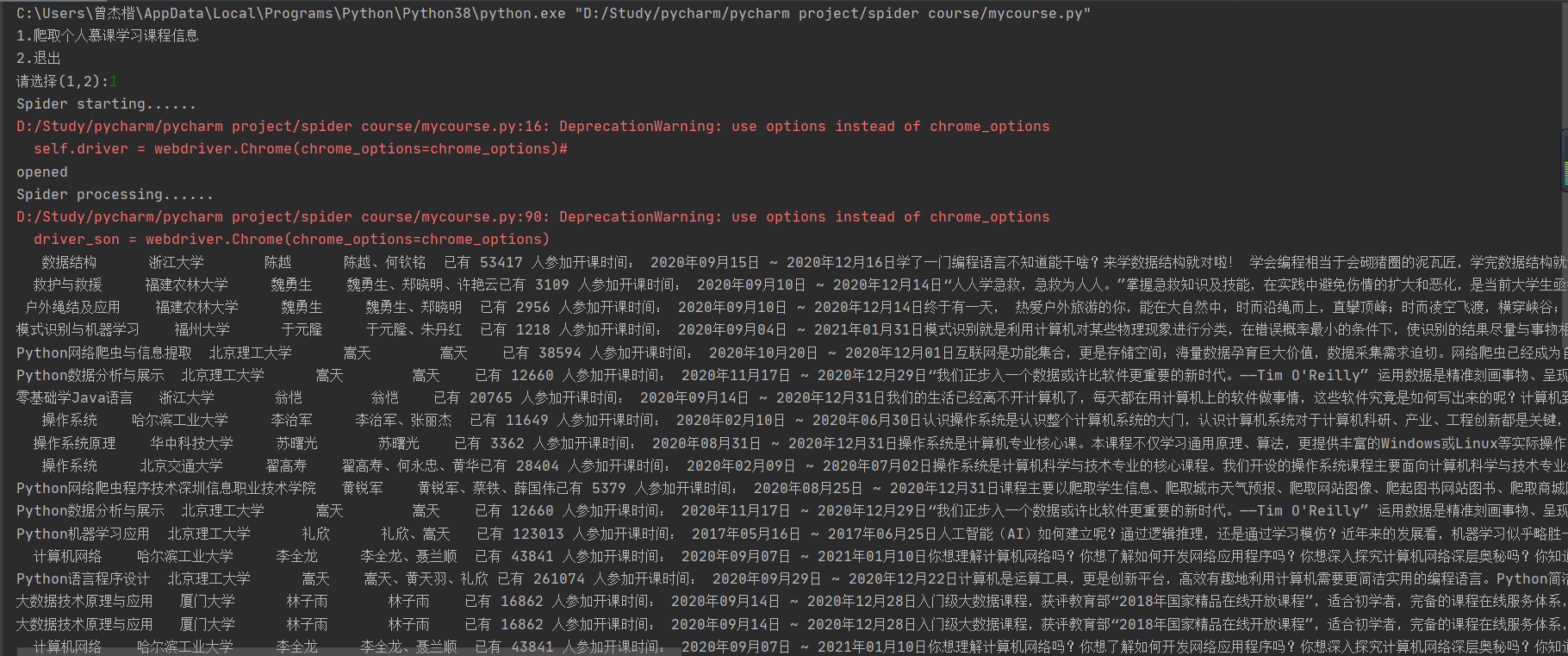
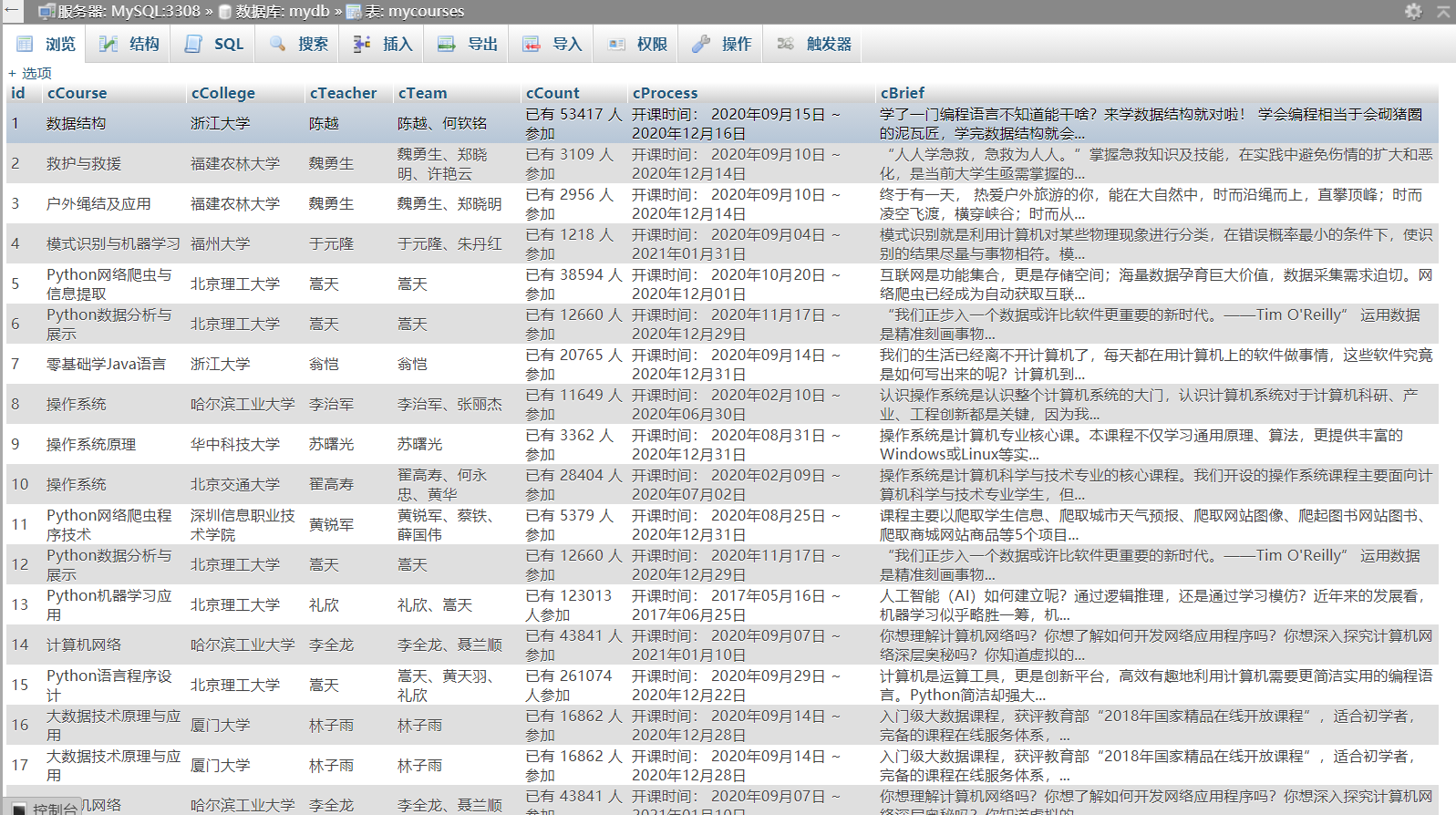
1)、使用Selenium框架+MySQL爬取中国mooc网课程资源信息
mycourse.py
import datetime
import time
import urllib.request
from selenium.webdriver import ActionChains
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.keys import Keys
import pymysql
class Myspider:
def startUp(self, url):
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
self.driver = webdriver.Chrome()#chrome_options=chrome_options
self.driver.get(url)
time.sleep(2)
try:
print("opened")
self.con = pymysql.connect(host="127.0.0.1", port=3308, user="root",passwd = "root", db = "mydb", charset = "utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
try:
self.cursor.execute("drop table mycourses")
except:
pass
self.opened = True
self.count = 0
except Exception as err:
print(err)
self.opened = False
if self.opened:
self.cursor.execute("create table mycourses (id varchar(32), cCourse varchar(32) , cCollege varchar(32), cTeacher varchar(32), cTeam varchar(512), cCount varchar(32), cProcess varchar(64), cBrief varchar(1024))")
def closeUp(self):
try:
if self.opened:
self.con.commit()
self.con.close()
self.opened = False
self.driver.close()
except Exception as err:
print(err)
def insertDB(self, name, college, teacher, team, participants, process, brief):
try:
sql = "insert into mycourses (id, cCourse, cCollege, cTeacher, cTeam, cCount, cProcess, cBrief)values(%s,%s,%s,%s,%s,%s,%s,%s)"
self.cursor.execute(sql, (self.count, name, college, teacher, team, participants, process, brief))
except Exception as err:
print(err)
def login(self):
button = self.driver.find_element_by_xpath("//div[@class='_1Y4Ni']//div[@class='_3uWA6']") # 弹出登录界面
button.click()
time.sleep(1)
button = self.driver.find_element_by_xpath("//div[@class='ux-login-set-scan-code_ft']//span[@class='ux-login-set-scan-code_ft_back']")
button.click()
button = self.driver.find_element_by_xpath("//ul[@class='ux-tabs-underline_hd']//li[position()=2]") # 手机登录
button.click()
time.sleep(5)
iframe_id = self.driver.find_elements_by_tag_name("iframe")[1].get_attribute('id')
self.driver.switch_to.frame(iframe_id)
input_account = self.driver.find_element_by_xpath("//input[@id='phoneipt']") # 找到账号框
input_account.send_keys("15759640581")
input_password = self.driver.find_element_by_xpath("//input[@class='j-inputtext dlemail']") # 找到密码框
input_password.send_keys("************")
self.driver.find_element_by_xpath("//div[@class='f-cb loginbox']//a[@class='u-loginbtn btncolor tabfocus ']").click() # 点击登录
time.sleep(3)
self.driver.find_element_by_xpath("//div[@class='u-navLogin-myCourse-t']//span[@class='nav']").click() # 进入我的课程
time.sleep(4)
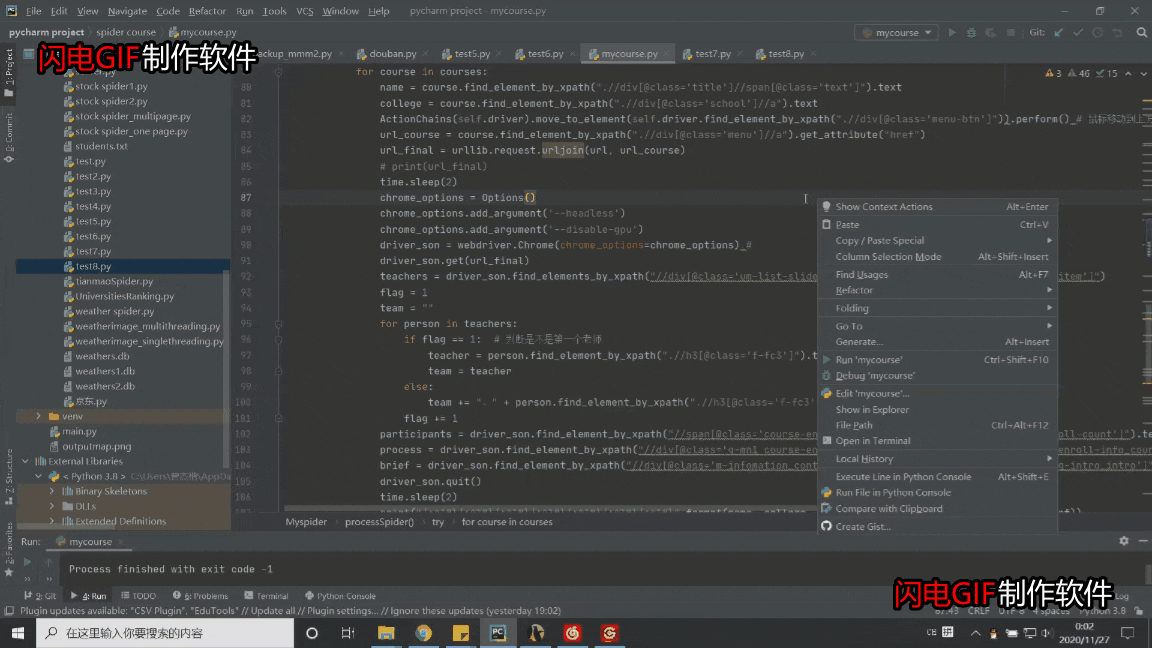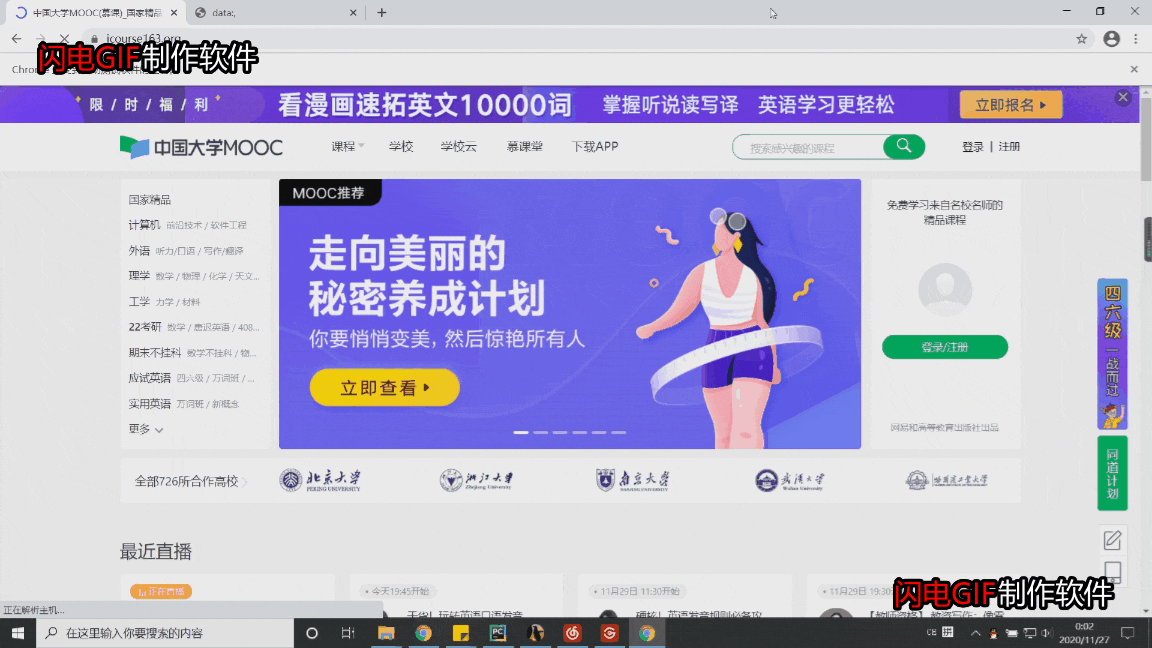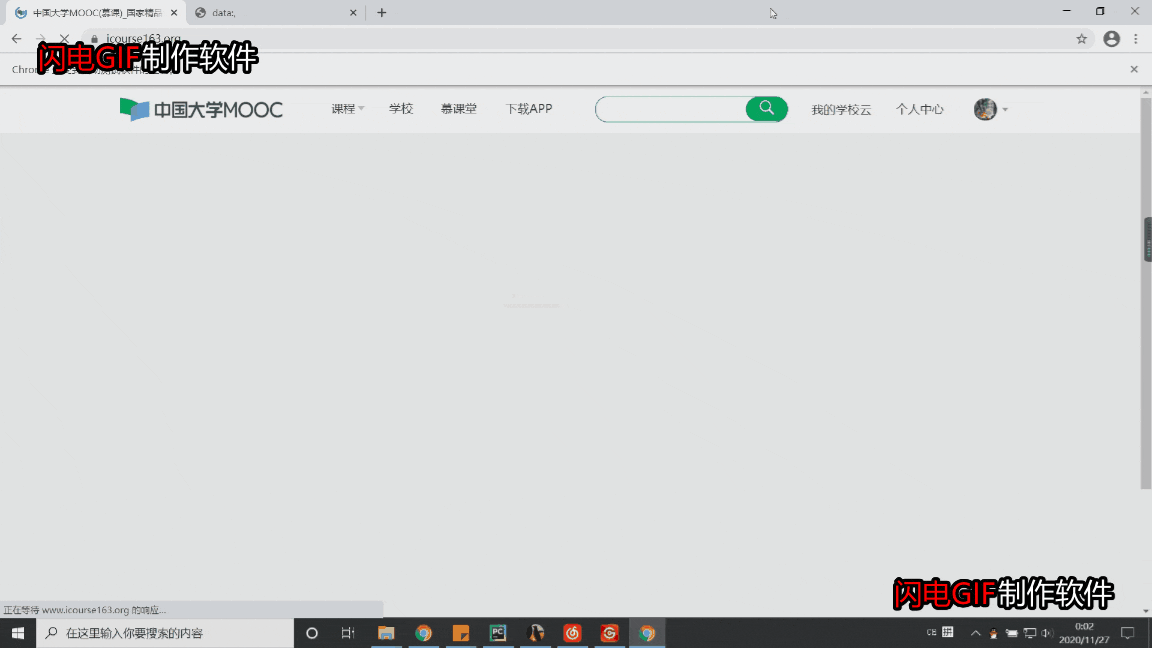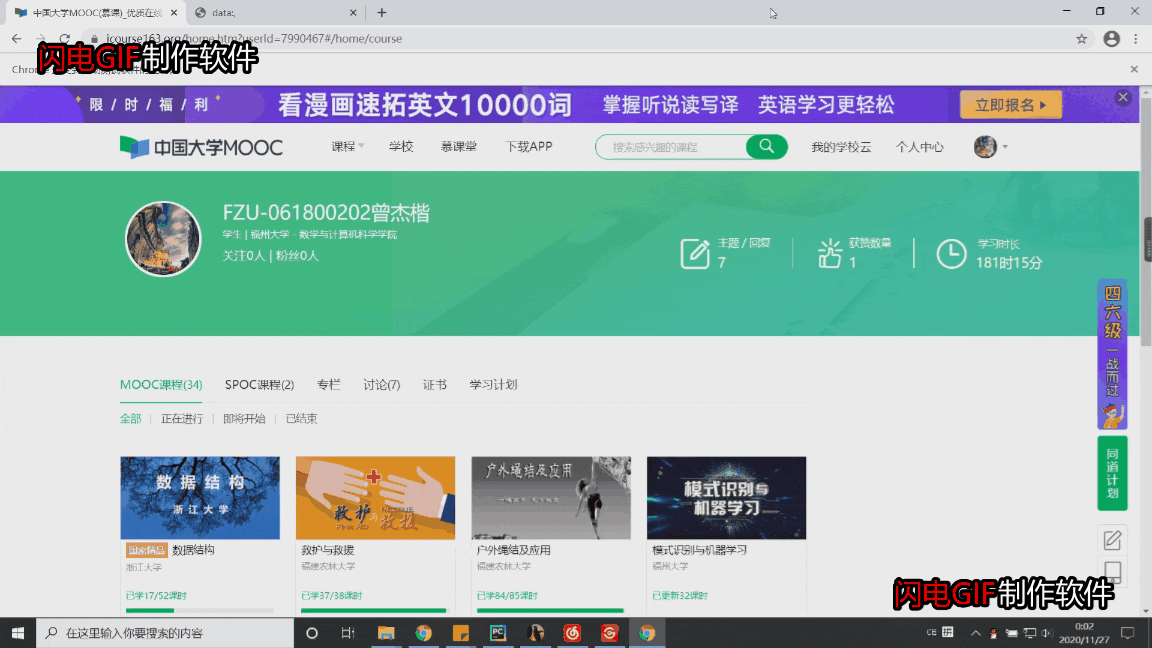
def processSpider(self):
try:
time.sleep(3)
# print(self.driver.current_url)
courses = self.driver.find_elements_by_xpath("//div[@class='course-panel-body-wrapper']//div[@class='course-card-wrapper']")
for course in courses:
name = course.find_element_by_xpath(".//div[@class='title']//span[@class='text']").text
college = course.find_element_by_xpath(".//div[@class='school']//a").text
ActionChains(self.driver).move_to_element(self.driver.find_element_by_xpath(".//div[@class='menu-btn']")).perform() # 鼠标移动到上方悬浮以显示出菜单
url_course = course.find_element_by_xpath(".//div[@class='menu']//a").get_attribute("href")
url_final = urllib.request.urljoin(url, url_course)
# print(url_final)
time.sleep(2)
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
driver_son = webdriver.Chrome(chrome_options=chrome_options) #
driver_son.get(url_final)
teachers = driver_son.find_elements_by_xpath("//div[@class='um-list-slider_con']//div[@class='um-list-slider_con_item']")
flag = 1
team = ""
for person in teachers:
if flag == 1: # 判断是不是第一个老师
teacher = person.find_element_by_xpath(".//h3[@class='f-fc3']").text
team = teacher
else:
team += "、" + person.find_element_by_xpath(".//h3[@class='f-fc3']").text # 把所有其他的老师加到团队里面
flag += 1
participants = driver_son.find_element_by_xpath("//span[@class='course-enroll-info_course-enroll_price-enroll_enroll-count']").text
process = driver_son.find_element_by_xpath("//div[@class='g-mn1 course-enroll-info-wrapper']//div[@class='course-enroll-info_course-info_term-info_term-time']").text
brief = driver_son.find_element_by_xpath("//div[@class='m-infomation_content-section']//div[@class='course-heading-intro_intro']").text
driver_son.quit()
time.sleep(2)
print("{:^10}{:^10}{:^10}{:^10}{:^10}{:^10}{:^10}".format(name, college, teacher, team, participants,process, brief))
self.count += 1
self.insertDB(name, college, teacher, team, participants, process, brief)
# 取下一页的数据,直到最后一页
try:
self.driver.find_element_by_xpath("//li[@class='ux-pager_btn ux-pager_btn__next']//a[@class='th-bk-disable-gh']") # 此时已经到达最后一页
except:
nextPage = self.driver.find_element_by_xpath("//li[@class='ux-pager_btn ux-pager_btn__next']//a[@class='th-bk-main-gh']")
nextPage.click()
time.sleep(2)
self.processSpider()
except Exception as err:
print(err)
def executeSpider(self, url):
starttime = datetime.datetime.now()
print("Spider starting......")
self.startUp(url)
self.login()
print("Spider processing......")
self.processSpider()
print("Spider closing......")
self.closeUp()
print("Spider completed......")
endtime = datetime.datetime.now()
elapsed = (endtime - starttime).seconds
print("Total ", elapsed, " seconds elapsed")
url = "https://www.icourse163.org/"
spider = Myspider()
while True:
print("1.爬取个人慕课学习课程信息")
print("2.退出")
s = input("请选择(1,2):")
if s == "1":
spider.executeSpider(url)
continue
elif s == "2":
break
2)、心得体会
这一作业主要是通过使用selenium框架来实现用户的登录,进而对自己账户的课程的信息进行爬取。进行用户登录时,要对输入账号和密码的输入框进行定位时需要对浏览器switch_to处理一下,否则会找不到想要定位的登录界面。其他的一些内容基本都是以前做过的内容,因此这次实验也是一次很好的复习。
最后一次作业终于完成了,完结撒花 (//▽//)/


 浙公网安备 33010602011771号
浙公网安备 33010602011771号