第一次个人编程作业
Github链接地址:https://github.com/superhandsome233/project-of-software-enginerring/tree/master/061800202
1.算法介绍
(1)一开始拿到这个题目的时候感觉无从下手,经过查阅大量资料后,决定采用google 提出的simhash 算法。对于文本相似性的计算,有一种思路便是通过模仿生物学指纹的特点,对文本构造一个指纹,来作为该文本的标识,从形式上来看指纹一般为固定长度较短的字符串,相同指纹的文本可以认为是相同文本。这些年来,出现了许多文本指纹去重的算法,google 的simhash 算法便是其中之一。
(2)算法流程图
(3)算法步骤
-
分词 把需要判断文本分词形成这个文章的特征单词,最后形成去掉噪音词的单词序列并为每个词加上权重,我们假设权重分为5个级别(1~5)。比如:“ 美国“51区”雇员称内部有9架飞碟,曾看见灰色外星人 ” ==> 分词后为 “ 美国(4) 51区(5) 雇员(3) 称(1) 内部(2) 有(1) 9架(3) 飞碟(5) 曾(1) 看见(3) 灰色(4) 外星人(5)”,括号里是代表单词在整个句子里重要程度,数字越大越重要。
-
hash 通过hash算法把每个词变成hash值,这样我们的字符串就变成了一串串64位的二进制数字。
-
加权 通过前两步骤的hash生成结果,需要按照单词的权重形成加权数字串,比如“美国”的hash值为“100101”,通过加权计算为“4 -4 -4 4 -4 4”;“51区”的hash值为“101011”,通过加权计算为 “ 5 -5 5 -5 5 5”。
-
合并 把上面各个单词算出来的序列值累加,变成只有一个序列串。比如 “美国”的 “4 -4 -4 4 -4 4”,“51区”的 “ 5 -5 5 -5 5 5”, 把每一位进行累加, “4+5 -4+-5 -4+5 4+-5 -4+5 4+5” ==》 “9 -9 1 -1 1 9”。
-
降维 把4步算出来的 “9 -9 1 -1 1 9” 变成 0 1 串,形成我们最终的simhash签名。如果每一位大于0 记为 1,小于0 记为 0。最后算出结果为:“1 0 1 0 1 1”。
-
相似度计算 计算相似性。计算出两个文本之间的汉明距离,进行判断。
参考于:https://www.cnblogs.com/maybe2030/p/5203186.html#_label1
2.计算模块接口的设计与实现过程
- 模块流程图
- 模块设计
1.def getText(filepath)
根据命令行所给的文件路径,对文件读入,并用jieba库对文本进行处理
2.def simhash_similarity(text1, text2):
对处理过的文本进行simhash处理
3.output
输出文件
- simhash计算模块
def simhash_similarity(text1, text2):
simhash_1 = Simhash(text1) # 处理文本一
simhash_2 = Simhash(text2) # 处理文本二
max_hashbit = max(len(bin(simhash_1.value)), (len(bin(simhash_2.value))))
distince = simhash_1.distance(simhash_2) # 汉明距离
similar = 1 - distince / max_hashbit # 计算相似度
return similar
def getText(filepath): # 处理读入的文件
with open(filepath, 'r', encoding='utf-8') as f: # 读取文件
text = f.read()
content = jieba.cut(text) # 使用jieba库对文本进行分词处理
contents = ""
for i in content:
contents += i + " "
documents = [contents]
texts = [[word for word in document.split()] for document in documents]
f.close()
return str(texts)
3.计算模块接口部分的性能改进
- 采取pycharm自带的Profile工具来进行性能分析
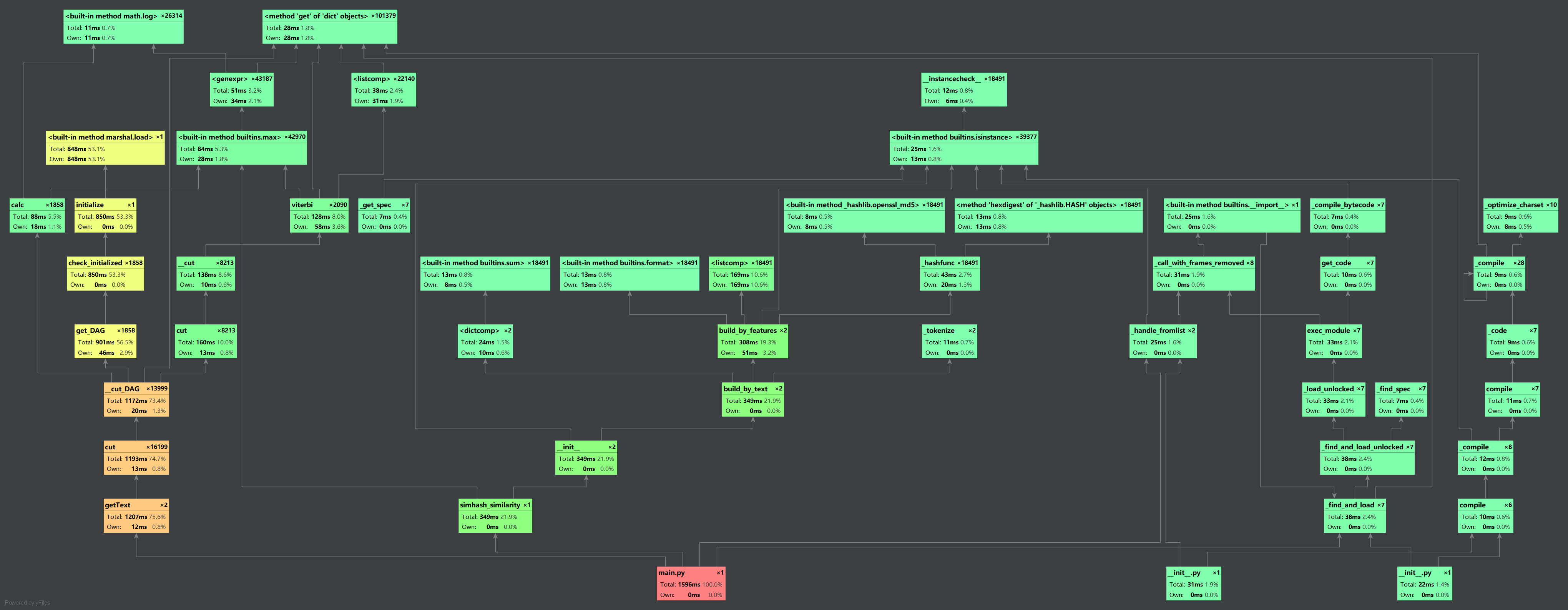


因为我选用的方法主要是调用python里现成的库,对于算法的优化也没有太好的思路,今后可能得多查查资料论文,多学习大佬的算法思路,嗯一到实战中才发现平时的积累很重要。(代码到用时方恨少T T)
4.计算模块部分单元测试展示
第一次接触对于代码进行单元测试的任务,经过查询了大量的资料,终于达到效果。
- 部分测试代码
import unittest
import testfile_main
class make_all_text(unittest.TestCase):
def test_self(self):
print("测试文本为orig.txt")
testfile_main.test_main('orig.txt', 'orig.txt', 'ans.txt')
def test_add(self):
print("测试文本为orig_0.8_add.txt")
testfile_main.test_main('orig.txt','orig_0.8_add.txt','ans.txt')
-
对模块进行测试:

-
覆盖率如下:

5.计算模块部分异常处理说明
- 这一部分主要是对输入空文件时进行异常处理
class FileErorr(Exception):
pass
class EmptyfileError(FileErorr): # 比对文本没有内容
def __init__(self):
print("出错了,对比文件为空!")
print("0")
def __str__(self, *args, **kwargs):
return "请找篇有内容的文本来进行比对"
6.PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 100 | 120 |
| · Estimate | · 估计这个任务需要多少时间 | 30 | 30 |
| Development | 开发 | 1400 | 2000 |
| · Analysis | · 需求分析 (包括学习新技术) | 400 | 460 |
| · Design Spec | · 生成设计文档 | 60 | 90 |
| · Design Review | · 设计复审 | 60 | 70 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 60 | 100 |
| · Design | · 具体设计 | 150 | 180 |
| · Coding | · 具体编码 | 480 | 560 |
| · Code Review | · 代码复审 | 120 | 150 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 240 | 360 |
| Reporting | 报告 | 100 | 120 |
| · Test Repor | · 测试报告 | 100 | 100 |
| · Size Measurement | · 计算工作量 | 30 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 120 | 120 |
| · 合计 | 3450 | 4480 |
7.总结
本次作业对我来说算是一次挑战,也从中学到了很多以前没接触过的东西,第一次接触单元测试,第一次对代码性能进行分析,第一次使用GitHub并在上面上传代码,期间总有许多意想不到的小细节,为了解决这些小细节上的问题,往往花了比自己预期更多的时间。不过我想,在这个不断碰壁的过程,也是逼着自己不断成长,不断学习,总的来说虽然辛苦但还是收获满满的。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号