LHY2022-HW03-Image Classification
1. 实验
1.1 背景介绍
将食物分成11个类别.

1.2 输出文件格式
两列,一列ID,一列类别.

1.3 Model Selection
允许使用其他模型结构,但是不允许使用预训练的参数.

1.4 Data Augmentation
要过后面的Baseline必须要使用数据增强,可以使用torchvision.transforms函数.

1.4.1 Advanced Data Augmentation - mixup
一种增强的技巧是将两张照片叠加,但是实现的代码也要进行对应的更改.


1.4.2 Test Time Augmentation
这里上面技巧的延申,简单来说,测试时将原始数据做不同形式的增强,然后取结果的平均值作为最终结果,可以进一步提升最终结果的精度.

助教这里讲的没有看懂,先放着.

1.5 Cross Validation
如果我们想获得更好的结果,要使用交叉验证.
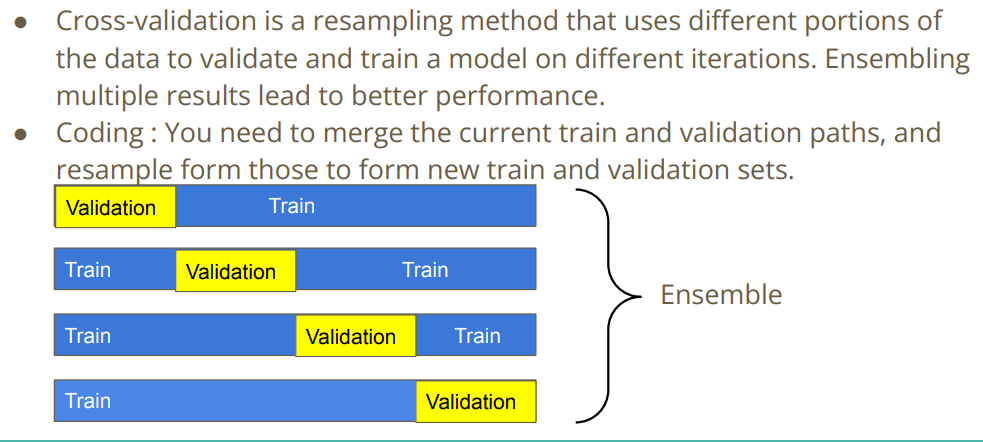
这里也提示说需要将训练集设置更多会有好的提升.

1.6 Ensemble
提示使用集成学习.使用不同不同模型,对它们的输出采用不同的规则.

1.7 Tips
- 数据增强是必要的,防止过拟合
- 如果使用的是自定义的model structure,不用害怕将模型结果调大.
![image]()

2. 实验过程
2.1 Simple Baseline
- acc>0.50099
(1) 什么都不做
![image]()

2.2 Medium Baseline
- acc>0.73207
助教提示使用Training Augmentation + Train Longer
(1) 增加transform方式、修改epoch,earlystopping的patience
具体来说,将epoch设置为400,earlystopping的patience设置为30,跑到了287次epoch才停(...).
设置的train_tf如下:
![image]()
似乎normalize会恶化训练结果.
![image]()


2.3 Strong Baseline
- acc>0.81872
助教提示Training Augmentation + Model Design + Train Looonger(+Cross Validation + Ensemble).
(1) 重新划分数据集、更换模型结构
没有改变数据增强的方式.但是重新划分了数据集.助教设计的\(Dataset\)采用一定技巧的话,重新划分数据集不需要重写代码.这个老哥Click实现Cross Validation给了我一个idea.将\(train\ set\)和\(valid\ set\)的路径放在一个\(list\)里,然后随机取样就不用把数据集下载下来再融合.训练集占比\(0.85\),向上取整.
#所有数据集路径
father_path = '/kaggle/input/ml2022spring-hw3b/food11'
file_path = [father_path + '/training/' + file for file in os.listdir(father_path + '/training') if file.endswith('.jpg')]
file_path.extend([father_path + '/validation/' + file for file in os.listdir(father_path + '/validation') if file.endswith('.jpg')])
file_path = sorted(file_path)
random.shuffle(file_path)
len(file_path)#13296
除此之外,将模型结构换成了\(vgg16\),不过没有用\(torchvision\)提供的包,而是使用了网上根据论文实现的代码.
class Classifier(nn.Module):
def __init__(self, num_classes=11):
super(Classifier, self).__init__()
self.block1 = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
self.block2 = nn.Sequential(
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.Conv2d(in_channels=128, out_channels=128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1)
)
self.block3 = nn.Sequential(
nn.Conv2d(in_channels=128, out_channels=256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.Conv2d(in_channels=256, out_channels=256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.Conv2d(in_channels=256, out_channels=256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1),
)
self.block4 = nn.Sequential(
nn.Conv2d(in_channels=256, out_channels=512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1)
)
self.block5 = nn.Sequential(
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1),
)
self.block6 = nn.Sequential(
nn.Flatten(),
# 使用自适应池化
nn.Linear(in_features=512 * 4 * 4, out_features=4096),
nn.ReLU(),
nn.Dropout(p=0.5, inplace=False),
nn.Linear(in_features=4096, out_features=4096),
nn.ReLU(),
nn.Dropout(p=0.5, inplace=False),
nn.Linear(in_features=4096, out_features=num_classes),
)
def forward(self, input):
output = self.block1(input)
output = self.block2(output)
output = self.block3(output)
output = self.block4(output)
output = self.block5(output)
output = self.block6(output)
return output
其他都没有变,从结果来看,跑了\(264\)个\(epoch\),过了\(Strong\ baseline\).

2.4 Boss Baseline
- acc>0.88446
Training Augmentation + Model Design +Test Time
Augmentation + Train Looonger (+ Cross Validation + Ensemble)
(1) 添加了Test Time Augmentation
但是只有Public过了线,跑一次代码时间太长了,如果增大训练集与验证集的比例可能会好一点.
![image]()
TTA的实现代码如下,关键是需要添加5个按train_tfm变化的图像.

test_loaders = []
test_counts = 5
for i in range(test_counts):
test_set_i = FoodDataset(os.path.join(_dataset_dir,"test"), tfm=train_tfm)
test_loader_i = DataLoader(test_set_i, batch_size=batch_size, shuffle=False, num_workers=0, pin_memory=True)
test_loaders.append(test_loader_i)
model_best = Classifier().to(device)
model_best.load_state_dict(torch.load(f"/kaggle/working/{_exp_name}_best.ckpt"))
model_best.eval()
prediction = []
#每个存放不同结果,每个元素是(3347,11)的矩阵
preds = [[],[],[],[],[],[]]
with torch.no_grad():
#第0个是预测测试集
for data,_ in tqdm(test_loader):
test_pred = model_best(data.to(device)).cpu().data.numpy()
#test_label = np.argmax(test_pred.cpu().data.numpy(), axis=1)
#prediction += test_label.squeeze().tolist()
preds[0].extend(test_pred)
for idx,test_loader_i in enumerate(test_loaders):
for data,_ in tqdm(test_loader_i):
test_pred = model_best(data.to(device)).cpu().data.numpy()
preds[idx+1].extend(test_pred)
#将5个train_tfm和test_tfm相加
#preds.shape is (5,3347,11)
pred_np = np.array(preds,dtype=np.float32)
res = np.zeros(shape=(pred_np.shape[-2],pred_np.shape[-1]))
for i in range(len(preds)):
if i == 0:
res = res + pred_np[i] * 0.5
else:
res = res + pred_np[i] * 0.1#平均乘0.5相当于每个乘0.1
print(f'res shape:{res.shape}')
prediction = np.argmax(res,axis=1).squeeze().tolist()
3. 结论与心得
3.1 关于Batch Norm2d
我们知道使用\(BN\)的目的是防止在不同特征上,特征之间的取值差距过大,而造成不好训练.但\(Batch\ Norm2d\)是对channel层之外的所有维度进行平均.这里我个人理解,在原来的BN中,我们对每个神经元的输入进行标准化,防止它们之间的输入差距太大,在\(BN2d\)里,我们神经元对应是卷积核,每个输入与卷积核对应相乘.每个\(channel\)对应一个卷积核,所以在BN2D中,可能是将\(B\times H\times\ W\)看作一个\(batch\).
参考Click.
3.2 关于torchvision的transform方法
Click这个网址有助于更好地理解RandomResizedCrop函数.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号