
利用Python多线程快速爬取某网站数据
小爬最近受同事所托,帮忙写个爬虫来获取某个网站的公开数据,该网站没有文件导出功能,后台返回的也不是完美的json格式数据,每页且只能显示不超过22行数据,合计有2200多页,约50000条数据,这就让手工取数变得遥不可及。
小爬原本想用python+selenium思路来低效爬取,实际体验了之后,发现其速度着实不够理想,且还存在稳定性问题,容易在控制翻页的过程中遭遇异常中断。经过一番思忖,小爬还是决定通过requests库来获取html,再用lxml+xpath或者RE表达式来解析,用threading来加速,用csv文件来存储爬取的内容。

说干咱就干,通过后台抓包,我们分析该网站主要是get请求,参数如下:
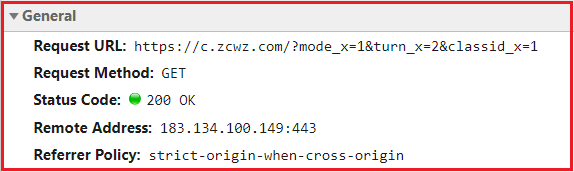
显然turn_x控制翻页,classid_x控制类别,mode_x看上去始终为1.由于我们准备爬取所有服务器存储的2206页数据,所以此时可以不区分其类型(任意类型):

我们可以定义个task函数,传入pageNum作为参数来爬取。假如我们一开始不知道服务器中总共多少页,多少条数据,我们可以先请求一次服务器,解析得到总条数和总页数,以决定后续的循环次数。不过此时考虑到它的型号数量每天基本保持不变,为了简化步骤,我们可以直接确定循环的次数。
使用requests来爬取网页信息时,为了不被反爬策略拦截导致页面404,我们需要添加必要的Request Headers,而Request Headers中最重要的就是User Agent信息。此处为了简化,我们可以如下这样定义我们的Session:

我们先定义一个task函数,将pageNum作为参数:

拿到页面元素后,我们使用浏览器的Inspect元素侦测功能,观察页面的结构:
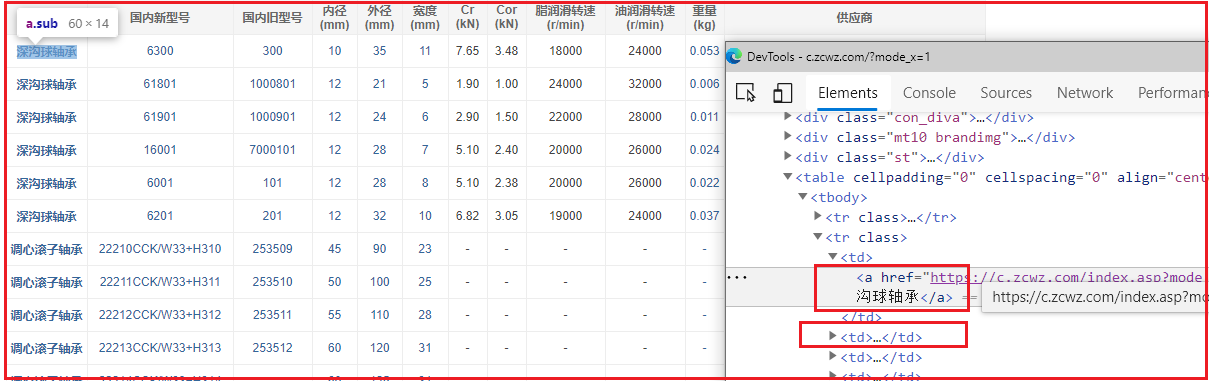
每条信息都有12个字段,其中“供应商”字段为广告,我们需要的是如下这些字段:
| 类型 | 国内新型号 | 国内旧型号 | 内径 (mm) | 外径 (mm) | 宽度 (mm) | Cr (kN) | Cor (kN) | 脂润滑转速 (r/min) | 油润滑转速 (r/min) | 重量 (kg) |
|---|
部分字段的文本带有超链接(深色文字),部分字段则只有纯文本。体现在Html源码上的差别是,部分文本为td标签下的a标签的文本,部分则直接是td标签的文本信息。
我们可以利用正则表达式的findall方法拿到所有的td标签,再对这些内容中含有a标签的数据进行进一步清洗:

上面代码中的tdList包含了所有的td标签信息,可实际上,我们每11个td标签则为一行数据,考虑到我们需要分行存储这些轴承字段信息,那么有必要将上面正则表达式得到的tdList列表进行分段,得到n个长度为11的子列表,这个可以通过python的列表表达式快速得到,python语法上简洁的优势也再一次得到印证:

紧接着,我们遍历列表的每一个元素,将含有a标签的,进一步用re表达式的search+group方法得到其文本内容:

通过上面一通操作,我们就得到了一个二维列表rows,剩下的操作就是将这个二维数组存入csv文件。

不过上面这样得到的csv文件缺少表头,我们可以在创建csv文件(使用w模式)一开始就写入表头,后面便可以用“a”模式追加行信息:

最后我们引入多线程,借助concurrent库来加速程序,这个过程中要注意几个地方:当多个线程同时对某个csv文件进行写操作时,容易由于共享文件导致写入乱码或者信息丢失,所以,在写入操作时,要引入线程锁,利用它的acquire 和release方法,以保证信息的写入安全;另外一点,我们可以利用map方法来快速传入多个pageNum参数。限于篇幅原因,完整的代码可以在公众号“小小爬虫师”中获取到。
经过一番尝试,借助多线程技术,我们的脚本,在不到40秒时间就完成了约50000条数据的爬取,可谓高效~
现实的工作中,我们往往会遇到各式各样的网站,也会面临各类爬虫需求。只有灵活使用各种爬虫方法、页面解析方法、多线程、多进程等异步加速手段,才能高效完成工作,向996 say no~
欢迎扫码关注我的公众号 获取更多爬虫、数据分析的知识!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号