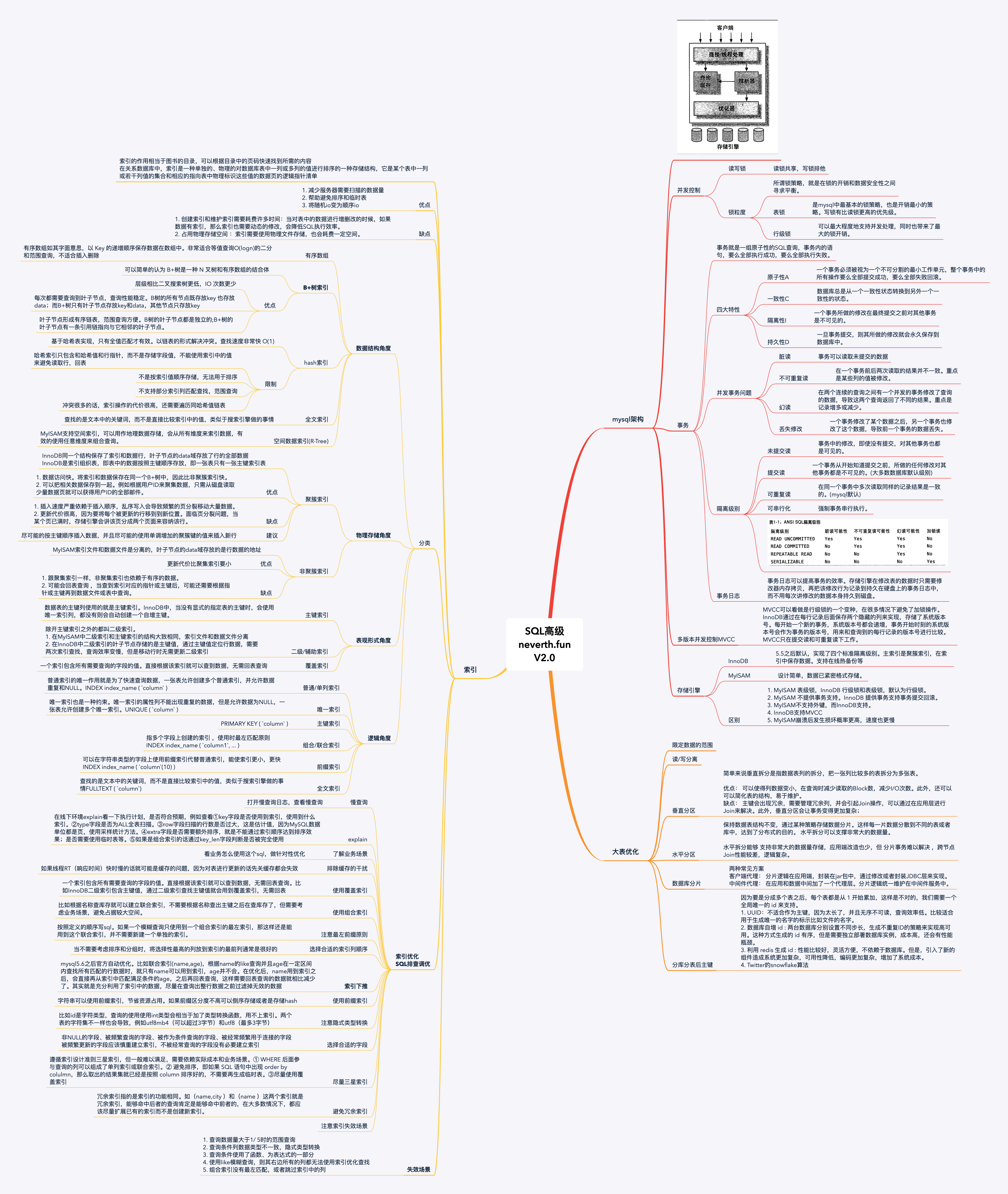
SQL精华总结索引类型优化SQL优化事务大表优化思维导图❤️
索引类型
从数据结构角度:
- B+树索引,
- hash索引,基于哈希表实现,只有全值匹配才有效。以链表的形式解决冲突。查找速度非常快 O(1)
- 全文索引,查找的是文本中的关键词,而不是直接比较索引中的值,类似于搜索引擎做的事情。
- 空间数据索引(R-Tree),MyISAM支持空间索引,可以用作地理数据存储,会从所有维度来索引数据,有效的使用任意维度来组合查询。
从物理存储角度:
-
聚簇索引,InnoDB同一个结构保存了索引和数据行,叶子节点的data域存放了行的全部数据。
优点:数据访问快。将索引和数据保存在同一个B+树种,因此比非聚簇索引快。可以把相关数据保存到一起。例如根据用户ID来聚集数据,只需从磁盘读取少量数据页就可以获得用户ID的全部邮件。
缺点:插入速度验证依赖于插入顺序,乱序写入会导致频繁的页分裂移动大量数据。更新代价很高,因为要将每个被更新的行移到到新位置。面临页分裂问题,当某个页已满时,存储引擎会讲该页分成两个页面来容纳该行。
尽可能的按主键顺序插入数据,并且尽可能的使用单调增加的聚簇键的值来插入新行。
-
非聚簇索引,MyISAM索引文件和数据文件是分离的,叶子节点的data域存放的是行数据的地址
优点: 更新代价比聚集索引要小 。
缺点:跟聚集索引一样,非聚集索引也依赖于有序的数据。可能会二次查询(回表) ,当查到索引对应的指针或主键后,可能还需要根据指针或主键再到数据文件或表中查询。
从逻辑角度:
- 普通 /单列索引,普通索引的唯一作用就是为了快速查询数据,一张表允许创建多个普通索引,并允许数据重复和NULL。
INDEX index_name ( column )。 - 唯一索引,唯一索引也是一种约束。唯一索引的属性列不能出现重复的数据,但是允许数据为NULL,一张表允许创建多个唯一索引。
UNIQUE ( column ) - 主键索引,数据表的主键列使用的就是主键索引
PRIMARY KEY ( column) - 联合索引,指多个字段上创建的索引
INDEX index_name ( column1, ... ),使用时最左匹配原则 - 前缀索引,索引字符串的一部分
INDEX index_name ( column(10) ) - 全文索引,查找的是文本中的关键词,而不是直接比较索引中的值,类似于搜索引擎做的事情。
FULLTEXT ( column)
从表现形式角度:
- 主键索引,数据表的主键列使用的就是主键索引。InnoDB中,当没有显式的指定表的主键时,InnoDB会自动先检查表中是否有唯一索引的字段,如果有,则选择该字段为默认的主键,否则InnoDB将会自动创建一个6Byte的自增主键。
- 二级 / 辅助索引,除开主键索引之外的都叫二级索引。在MyISAM中二级索引和主键索引的结构大致相同。在InnoDB中二级索引的叶子节点存储的是主键值,通过主键值定位行数据,需要两次索引查找。使用主键值当做指针会让二级索引占更多的空间,但是移动行时无需更新二级索引。
- 覆盖索引,如果一个索引包含(或者说覆盖)所有需要查询的字段的值,我们就称之为“覆盖索引”。覆盖索引即需要查询的字段正好是索引的字段,那么直接根据该索引,就可以查到数据了, 而无需回表查询。
索引优化SQL排查调优
- 打开慢查询日志,查看慢查询
- 首先在线下环境explain看一下执行计划,是否符合预期,例如查看①key字段是否使用到索引,使用到什么索引。②type字段是否为ALL全表扫描。③row字段扫描的行数是否过大,估计值。MySQL数据单位都是页,使用采样统计方法。④extra字段是否需要额外排序,就是不能通过索引顺序达到排序效果;是否需要使用临时表等。⑤如果是组合索引的话通过key_len字段判断是否被完全使用。
- 了解业务场景。看业务怎么使用这个sql,做针对性优化。
- 排除缓存的干扰。如果线程RT(响应时间)快时慢的话就可能是缓存的问题,因为对表进行更新的话先关缓存都会失效
- 使用覆盖索引。一个索引包含所有需要查询的字段的值。直接根据该索引就可以查到数据,无需回表查询。比如InnoDB二级索引包含主键值,通过二级索引查找主键值就会用到覆盖索引,无需回表
- 使用组合索引。比如根据名称查库存就可以建立联合索引,不需要根据名称查出主键之后在查库存了,但需要考虑业务场景,避免占据较大空间。
- 注意最左前缀原则,按照定义的顺序写sql。如果一个模糊查询只使用到一个组合索引的最左索引,那这样还是能用到这个联合索引,并不需要新建一个单独的索引。
- 选择合适的索引列顺序。当不需要考虑排序和分组时,将选择性最高的列放到索引的最前列通常是很好的。
- 索引下推,mysql5.6之后官方自动优化。比如联合索引(name,age),根据name的like查询并且age在一定区间内查找所有匹配的行数据时,就只有name可以用到索引,age并不会。在优化后,name用到索引之后,会直接再从索引中匹配满足条件的age,之后再回表查询,这样需要回表查询的数据就相比减少了。其实就是充分利用了索引中的数据,尽量在查询出整行数据之前过滤掉无效的数据。
- 使用前缀索引。当要给字符串加索引时,可以使用前缀索引,节省资源占用。如果前缀区分度不高可以倒序存储或者是存储hash。
- 注意隐式类型转换。比如id是字符类型,查询的使用使用int类型会相当于加了类型转换函数,用不上索引。两个表的字符集不一样也会导致,例如utf8mb4(可以超过3字节)和utf8(最多3字节)
- 被频繁更新的字段应该慎重建立索引,不被经常查询的字段没有必要建立索引。
- 遵循索引设计准则三星索引,但一般难以满足,需要依赖实际成本和业务场景。① WHERE 后面参与查询的列可以组成了单列索引或联合索引。② 避免排序,即如果 SQL 语句中出现 order by colulmn,那么取出的结果集就已经是按照 column 排序好的,不需要再生成临时表。③尽量使用覆盖索引
- 注意索引失效场景。
思维导图

 浙公网安备 33010602011771号
浙公网安备 33010602011771号