记一次idea性能调优
因自研的自动化测试工具包含压测功能,在自己本地代码开发完毕后进行测试,对目标接口进行1000次访问,发现idea在执行结束后变的异常卡顿,怀疑是idea工具或者程序代码存在问题,遂进行排查。
----------------------------------------------------------------------------------------------
本地所用MacBook Pro 2015配置
处理器:i7 2.2GHz
核心数:4
内存:16GB
系统:macOS Mojave
----------------------------------------------------------------------------------------------
先从idea排查开始:
1、打开jdk自带的jconsole工具,连接idea;同时打开活动监控器
启动idea,可以看到idea的cpu跟内存消耗并不高:


启动程序,再次观察cpu跟内存,cpu从2%到了10%,内存增长300M:


本以为jconsole能明显看到jvm的变化情况,结果不然,而且显示的数值很小,只有47兆:
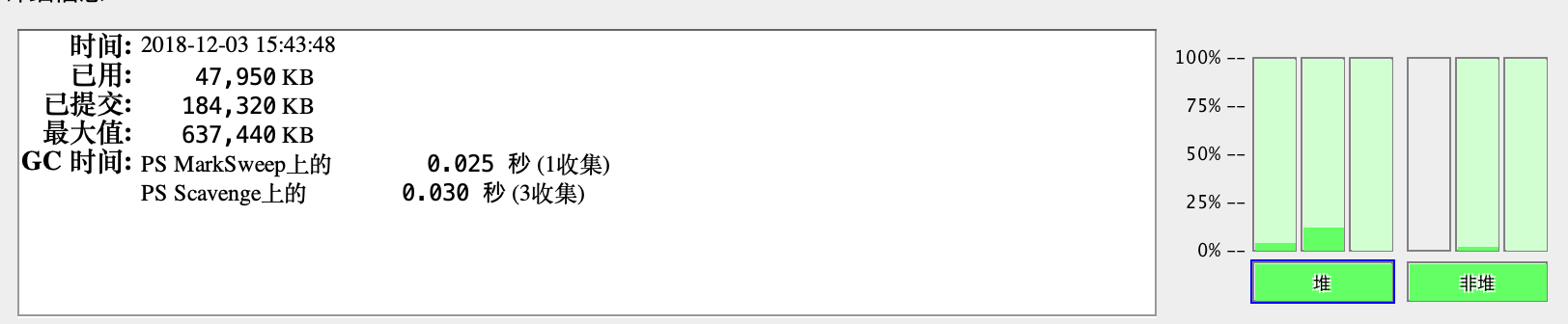
这跟系统的活动监视器的结果明显不符合嘛,后来发现,jconsole实际把idea跟程序的jvm内存使用都分开了,这个显示的只是idea的,其实本例中如果要查看内存大小,应该直接监控程序的。这个是程序的执行模块的内存情况:
2、执行压测程序,1000访问量,第一次执行
idea变得非常卡顿,系统的监控器看到明显的内存变化:


同时,jconsole看到了明显的内存跟cpu变化情况:
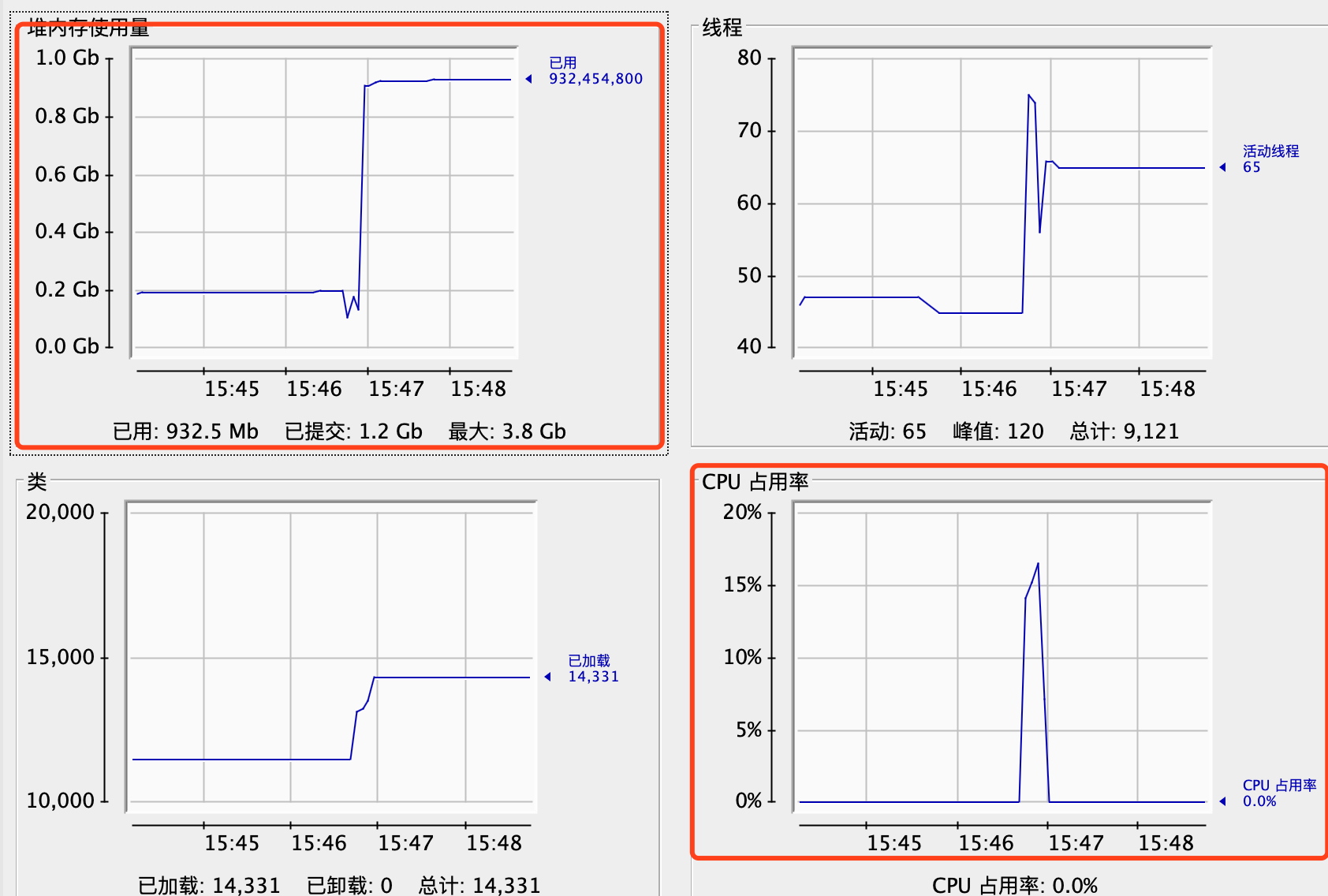
堆中老年代old:62M,新生代eden:780M左右,幸存区15M,之所以看到新生代跟幸存区一样高,是因为这里显示的百分比,实际新生代占用的非常多。这里多说一句,jvm的各个区的命名也是挺有意思的,新对象刚出生,就叫eden区,eden,,,伊甸园么,亚当跟夏娃开始的那个地方,这名字挺合适的;然后会有垃圾收集,挺不过去就被回收了,对对象来说这辈子也就算完了,挺过去的话,这条命算是保住了,属于幸存者,于是到了幸存区(survivor)。可是生活并没有结束,接下来还是有一次次的gc来考验我们的对象,很多人没能坚持下来,最终经历15次gc而没被回收的,相对来说年龄也不小了,进入的区域叫老年代(old)。挺有意思。
这次执行结束之后,idea的响应速度还是可以的,不是怎么卡顿。
3、压测1000访问量,第二次
从之前的经历来看,就是这次压测会导致idea非常卡顿,监控器情况:


执行过程中跟上次相比,并无明显区别,cpu跟内存均没有明显增长,但idea抛出了OOM提示框:
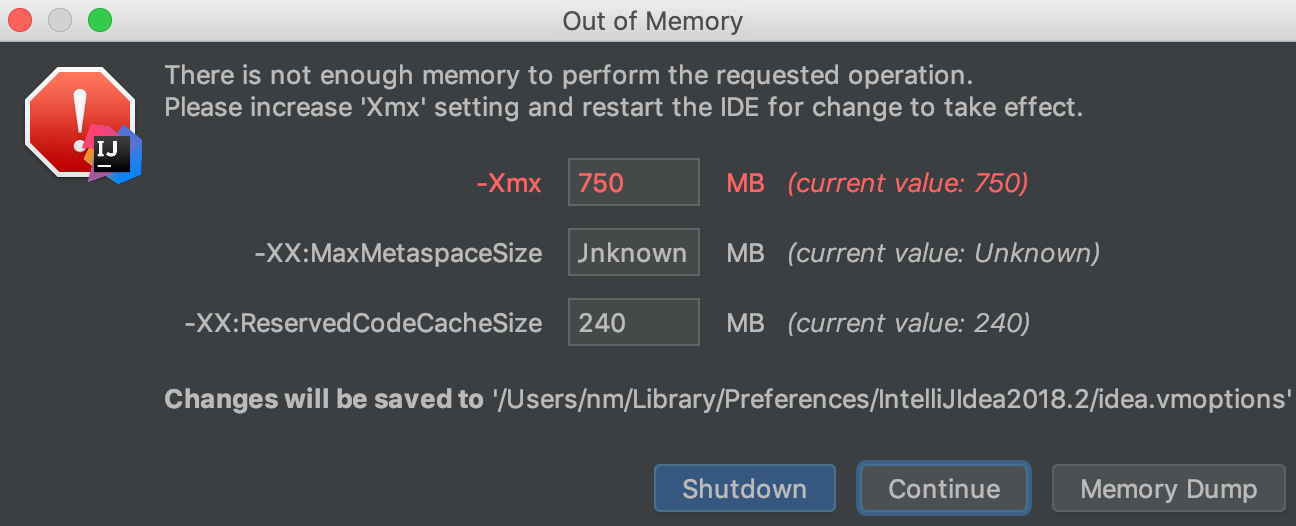
如果修改这几个参数,修改后的内容将被保存到/Users/nm/Library/Preferences/IntelliJIdea2018/idea.vmoptions中,idea默认读的配置文件也是这个,而不是安装目录的bin下的。
压测程序执行结束之后,监控器看到的idea占用cpu依然很高,对idea的操作也会有卡顿(有时比较明显,也偶尔有相对流畅的):
点击Memory Dump,信息会被存到idea.vmoptions,然后点击continue继续。
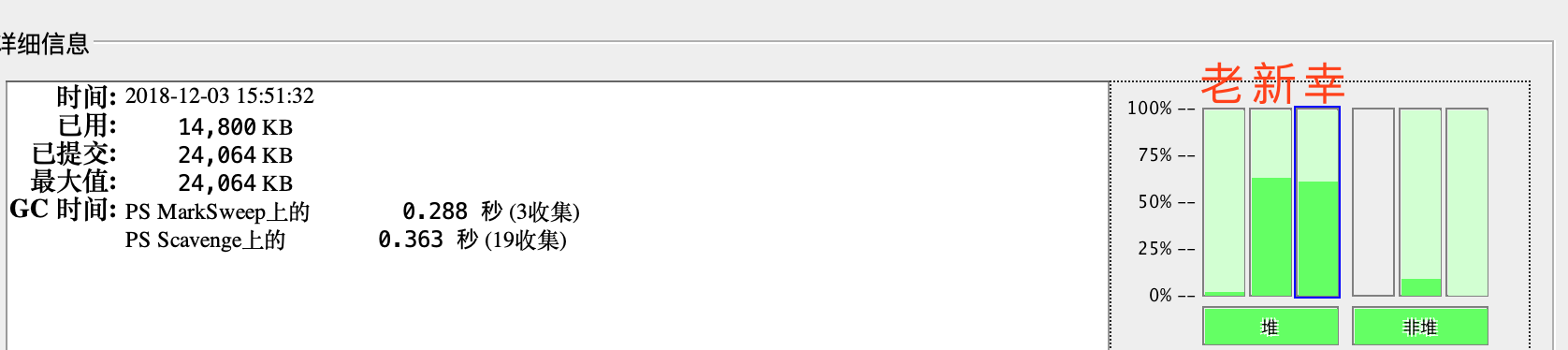
jconsole同样看到了内存跟cpu的增长:

图表中的15:54左右的内存下降应该是jvm的gc导致,后边16:10分左右的cpu跟内存暴增然后降低才是这次压测的表现。(为何堆内存在16:10会骤降,怀疑可能正好有一次gc,jconsole的vm概要有gc次数,忘了截图)
idea OOM框dump出的信息保存在$USER_HOME/heapDump_Leak_Supports.zip中,解压有heapDump.hprof文件,内容如下:
用Memory Analyzer Tool打开这个hprof进行查看:
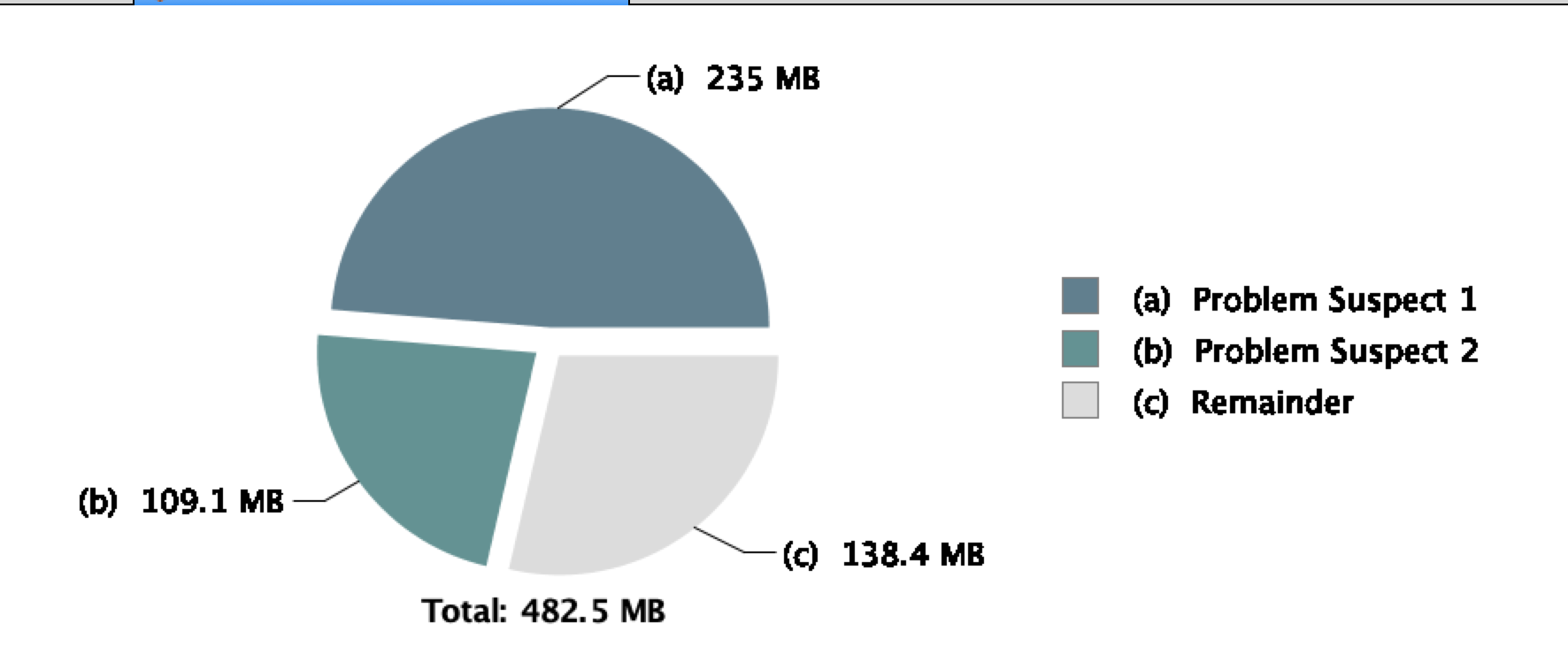
说是a、b两部分内容“怀疑有罪”,分别235M跟109M,这两个都是什么东西呢?
两个都是idea自己的一个类的对象com.intellij.openapi.editor.impl.DocumentImpl,看名字是个文档实现类
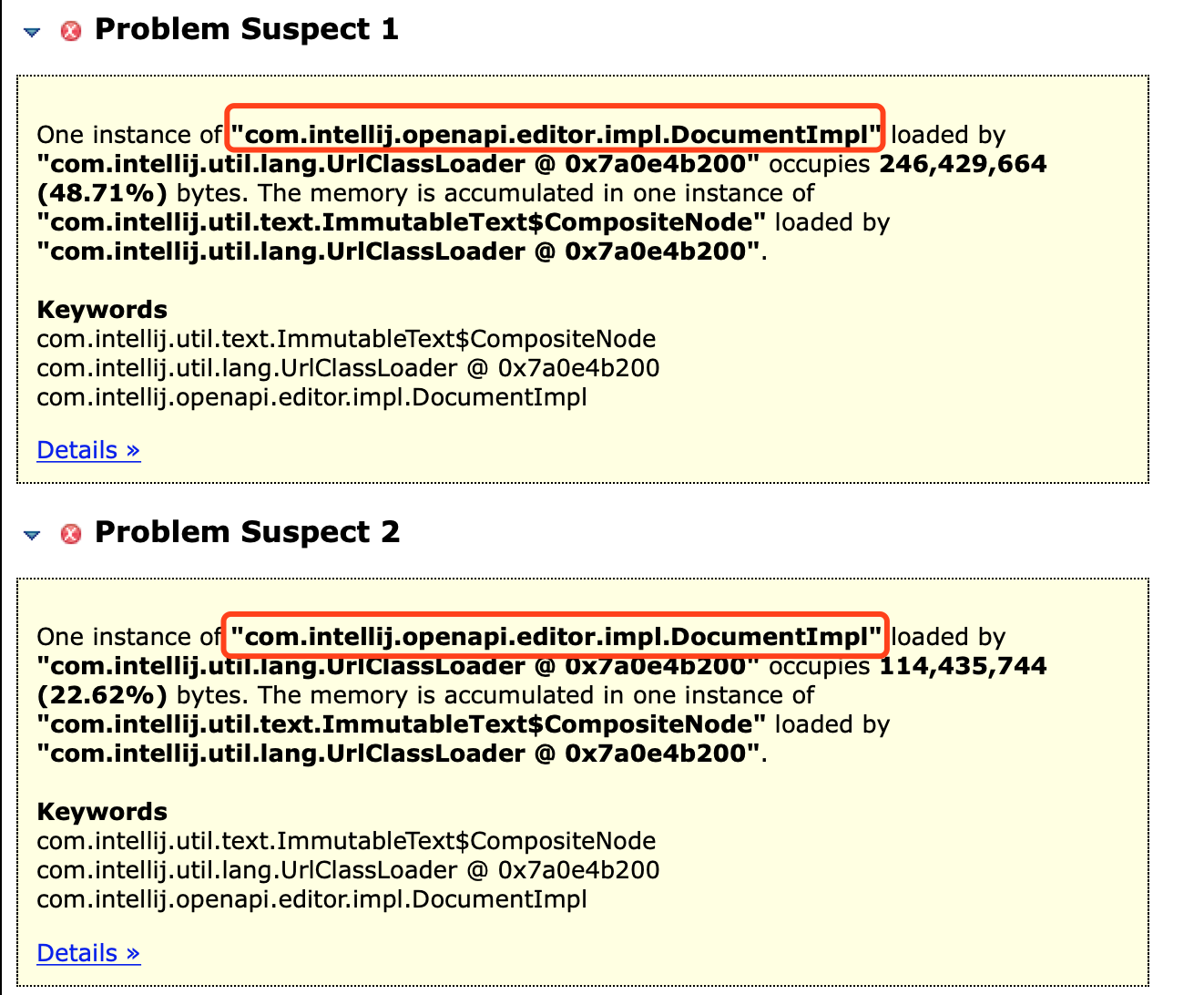
到这里,其实我已经猜出问题出在哪里了,是日志!因为我以前把控制台的输出设置为无限制,而为了本地调试方便,我又把hibernate的日志也打印了出来,在执行单个案例的时候并不明显,而如果执行大量案例执行,这个日志的量就非常大了,多次压测1000访问量后系统产生大量日志,这些日志都被作为文本类的内容被保存了起来,又因为我把控制台日志设为无限,idea不清除这些类对象,最终导致对象越来越大,拖垮了idea。
如果检测的不是idea而是自己的程序,那么还可以继续通过histogram跟dominator_tree进行跟踪。因为强引用、软引用、弱引用跟虚引用只有强引用不会被gc,如果多次gc没有回收掉,肯定有强引用在关联这个对象,通过支配树 dominator_tree(展示对象层级关系跟内存占用百分比)跟Merge Shortest Paths to GC Roots(展示gc树引用关系图)可以慢慢找到强引用的所在,从而定位内存溢出原因。
定位了问题后,稍后又对idea的各个参数进行了一次调整,因为默认的配置相对来说低了点,参考:https://segmentfault.com/a/1190000010144588
4、参数修正
明白了问题所在,那么进行修复并测试,修改idea的相关参数配置为:
-Xms512m -Xmn512m -Xmx2048m -XX:ReservedCodeCacheSize=240m -XX:+UseCompressedOops -Dfile.encoding=UTF-8 -XX:+UseG1GC //使用G1收集器,好处是并行收集 -XX:+UseNUMA //优先使用速度较快的内存 -XX:SoftRefLRUPolicyMSPerMB=50 -ea -Dsun.io.useCanonCaches=false -Djava.net.preferIPv4Stack=true -Djdk.http.auth.tunneling.disabledSchemes="" -XX:+HeapDumpOnOutOfMemoryError -XX:-OmitStackTraceInFastThrow -Xverify:none -XX:ErrorFile=$USER_HOME/java_error_in_idea_%p.log -XX:HeapDumpPath=$USER_HOME/java_error_in_idea.hprof -javaagent:JetbrainsCrack-3.1-release-enc.jar
主要是将堆内存最小设为512,最大为2G,变为了原来的3倍,然后把gc算法改为了G1,并优化内存读取为NUMA。NUMA我也不熟悉,网上查到的结果如下:
numa 是一个 CPU 的特性。SMP 架构下,CPU 的核是对称,但是他们共享一条系统总线。所以 CPU 多了,总线就会成为瓶颈。在 NUMA 架构下,若干 CPU 组成一个组,组之间有点对点的通讯,相互独立。启动它可以提高性能。
NUMA 需要硬件,操作系统,JVM 同时启用,才能启用。Linux 可以用 numactl 来配置 numa,JVM 通过-XX:+UseNUMA来启用。
5、执行,查看结果
按照以上步骤,同样程序启动后执行两次请求数量均为1000的压测,jconsole如图:
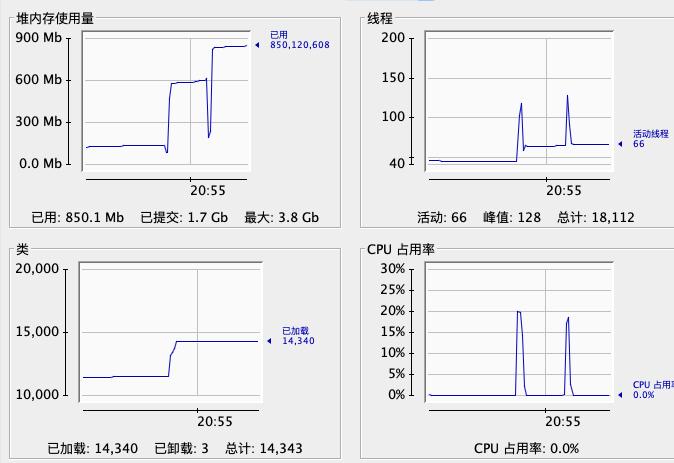
两次明显的内存增长跟cpu消耗,监控器看到的内存情况:

相比之前,idea的内存增长到了2.5G,cpu在压测结束后恢复正常。点击idea使用,没有在发生卡顿的情况,可知的确是日志导致idea卡顿的。而当时idea的cpu消耗亦很高,应该是频繁gc所致。
当然,我仅仅这么修改是肯定不行的,如果控制台仍旧是无限,那么总有一天还是会oom的,我目前是手动清空控制台,发现效果也还可以,会有效。如果不手动清空,则一定要设置控制台最大行数,或者内存值,防止因日志而导致的idea卡死现象。
--------------------------------------------------------------------------
对jconsole的使用并不熟练,如有错误之处请留言指正,多谢多谢。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号