BUAA 2021春季学期OO课程第一单元(表达式求导)工作总结
OO第一单元(表达式求导)总结
前言
- 本文字数4618词,阅读本文预计需要12分钟。
- 本文为BUAA OO面向对象课程2021春季学期课程要求下的博客随笔。
- 请遵守相关协议,转发请注明出处。若想第一时间获得更新,欢迎关注本博客。
程序结构分析
类的设计——从PO走向OO
由于我之前接触过C#、C++、Python等具有面向对象性质的语言,所以在设计之初就考虑了一点对象化的想法。但是显然,没有在科班里跟着老师一步步细细地去研究OO思想的话,得出的想法都是幼稚和粗陋的。在结束第一单元的理论学习后再看自己的第一次设计实在觉得不堪入目。
一个好的程序,首先要基于正确的设计思想、正确的需求理解和良好的编程习惯。如果没有好的设计思想,写出来的就是丑陋的代码,极其难以维护和迭代;而如果没有对需求理解透彻,那么就会存在功能上的缺陷和不可挽回的BUG;没有良好的编程习惯,就会埋下难以发现的bug和难以阅读的代码。可以说,第一单元的OO作业让我深深地感受到上面三点在编程过程中的重要性。
第一次作业
首先我先贴出来自己第一次作业的类图:
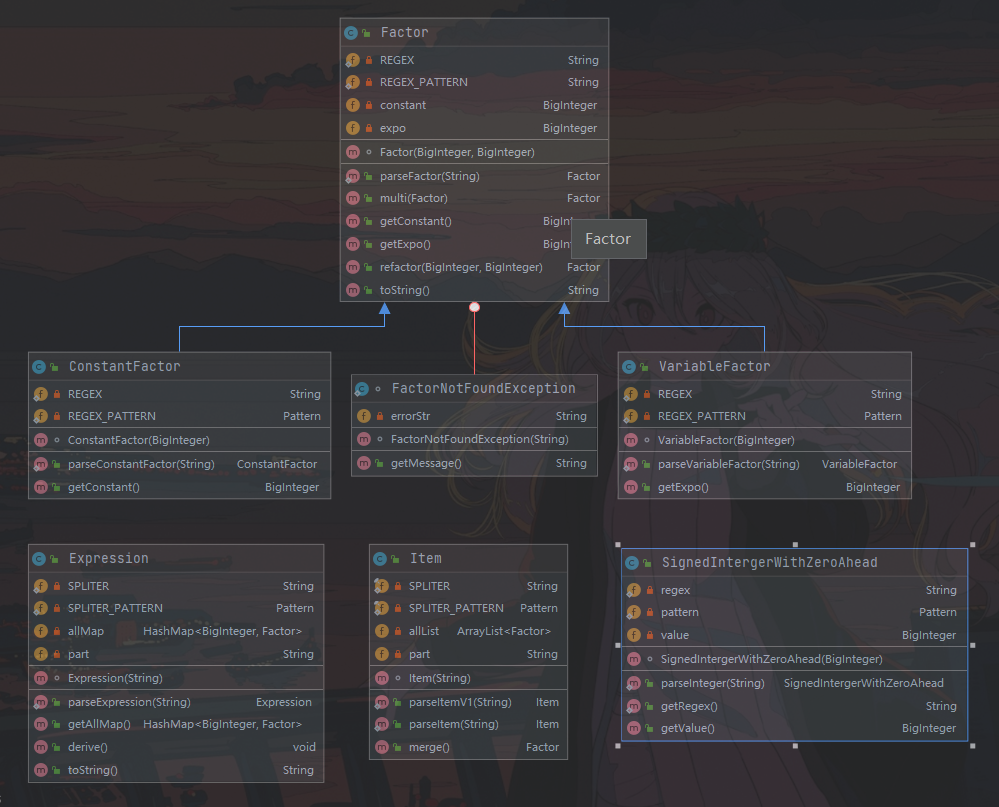
首先我简要介绍一下这个程序的设计情况,从第一次作业的要求上看,我将表达式分为了四个层次,Expression层次对应最上层的表达式类,Item对应项,而Factor对应因子,SignedIntergerWithZeroAhead对应带符号前零整数。求导方法derive()封装在Expression里,很蠢的设计……每个层次自带一个静态的parser方法,以先后调用Expression的Parser进行分割、再调用Item的Parser再次分割,最后调用Factor的Parser返回因子对象。这意味着每一层都有正则表达式匹配(REGEX、SPLITER等静态变量对应正则表达式及其Matcher对象,以此防止反复compile)。
有一说一,我现在看到这份代码都来气,如果是要挑错的话:
-
SignedIntergerWithZeroAhead设计的时候在想什么啊?明明就是个BigInteger能解决的问题,单独包装了一个类来进行匹配、分析和输出,耗费了大量的程序性能。而且Integer还是个typo……
-
实际分析下,Item就是一种Factor,不要分开设计。而且在Expression的解析过程中也压根没将Item作为一个下层的元素,而是利用Item作为一个容器进行了合并化(实际上用个ArrayList<Factor>就能够完全替代Item)。
-
Expression类如果需要分析的话也可以认为是和Item一样的复合Factor,因此所有类应该都是Factor的一种(第二次重构的重点)。
-
求导的实现有大问题,求导居然针对Expression类进行,通过在derive方法中对每个Expression所管理的Factor进行计算后在再放入新的List中来替换原List,实在是辣眼睛。这还使得Factor类需要对外保留其属性以供Expression类中进行计算,不安全。
-
Factor的设计也有问题,让幂因子和常量因子共享的变量居然是乘数和幂数……这也就意味着幂因子中乘数始终为1,而常量因子中幂数始终为0,这样的设计可以说是十分古怪了……
第二次&第三次作业的重构
第一次作业的锅始终太大了,我就以我第二次作业重构所做出的修改(不如说是重写)来进行分析如何改进。事实上,这也是经由老师提醒设计复合类才想出的方案,果然在理论指导下的设计能够体现出独特的优美性。第三次作业中改动不大,只是增加了几个异常处理而言,因此并在此处一并阐述。
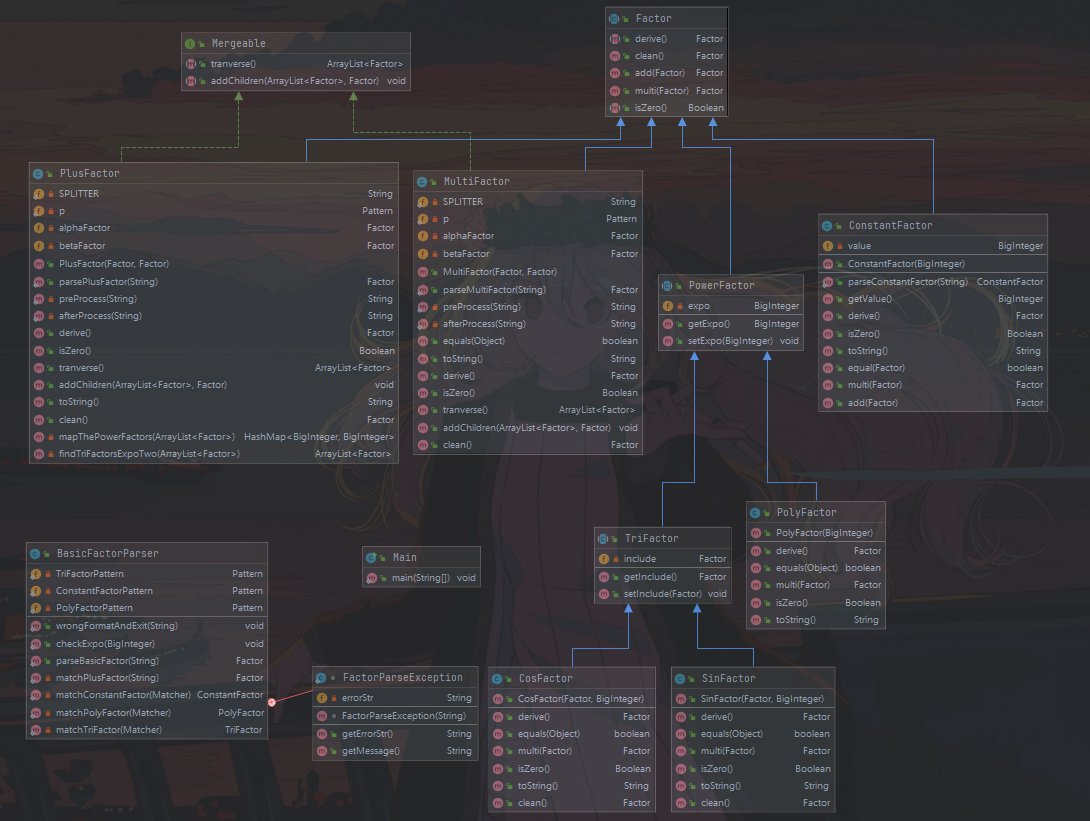
-
使用了一整个Factor抽象类来作为基础,在此基础上延伸出复合类、幂类、常量类,幂类里又包括三角函数类和幂因子类。你也许注意到了Mergeable接口,其实际上是作为复合类来提供合并优化的方法的,我认为可以直接作为Factor的子类,但是在初步设计时我并没有考虑优化问题,故在优化时决定将是否可以合并优化抽象成单独的一个接口,通过是否继承该接口来决定是否在该层次进行合并优化。
-
求导、乘除加减等我都在Factor中进行定义,而在有的因子类中进行了Override以期优化,比如幂因子相乘返回的不再是乘因子而是一个新的幂因子。因此我将两个元素的乘除加减在原子类型中就实现了优化,使得表达式树在构建过程中就进行了初步的优化。更好的是,在复合类中只需要将整个表达式树直接进行reduce操作,就能利用各个类自己Override后的操作方法来进行合并优化,而无需在复合类中对进行加乘操作时的两因子类型进行判断,大大减轻了我合并优化的压力。
-
BasicFactorParser作为一个统一对因子进行解析的类,其最主要的功能在于解析字符串和进行格式判断。其能够匹配输入的字符串到可能的因子,并在均不匹配或匹配后非法时抛出异常(有点工厂模式内味了?)。
-
PowerFactor是我对所有支持幂数的因子的抽象,主要在于添加expo这个属性。我当时考虑如果要对表达式因子也支持幂数,只需要将PlusFactor移动到PowerFactor下即可(这也是为什么我将Mergeable设置为一个接口的原因,因为如果Mergeable也抽象成一个类的话,java不支持同时继承两个类)。
-
isZero()函数是用于优化的,其在Factor这个顶层类中定义,用于标识当前对象是否在逻辑上为0。这使得我能够在乘法和加法中很方便地对两个元素的计算进行优化而不用对其类型进行特判。而实际上,经过我的分析,任何因子的值具体是多少都是不重要的,重要的只是其是否为0,因为在合并优化过程中已经通过优化操作符方法来实现了同类因子的合并,那么我们只需要考虑其是否为零来决定是否输出。
-
clean()则是用于合并优化的方法,其先通过tranverse对表达式树每个因子进行遍历形成List,然后将该List中相同类的对象分别析出,然后同组进行reduce()操作来实现合并。这是一种贪婪的思想——保证每个复合类中都被合并优化,从而期望整个表达式获得最大的性能。
但是谈到优化,我就痛哭流涕。为什么呢?因为这两次作业我都没能完全通过强测,而且都是直接或间接和优化有关。而这其中的BUG我将在第三部分中进行详细分析。
度量化分析—— 数据能说话
我使用了Designite Java来对我的代码进行量化的分析。有一说一,这给我提供了一个全新的视角来认识自己的程序,也让我认识到了程序设计中存在的很多问题。
typeMetrics 类型分析
通过使用excel进行归一化处理后,可以看出各个类在性质上的差异性。
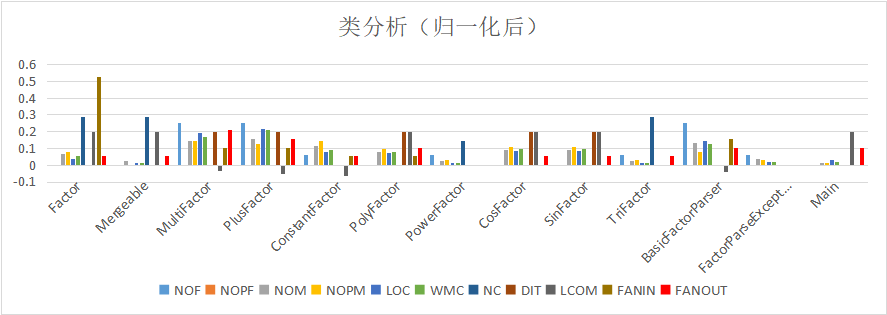
可见Factor类的FANIN值很高,说明其复用性极佳,而事实上也确实如此。LCOM值值得注意,Mergeable、PolyFactor、CosFactor和SinFactor的LCOM值偏高,说明其类内的聚合度较低。FANOUT值中MultiFactor和PlusFactor的值较高,因为其中都包括合并优化的算法导致复杂度较高。
methodMetrics 类的方法分析
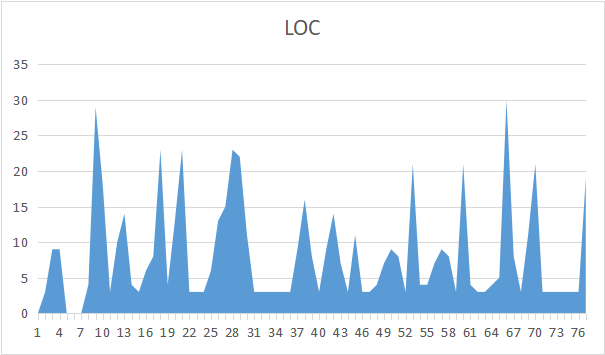
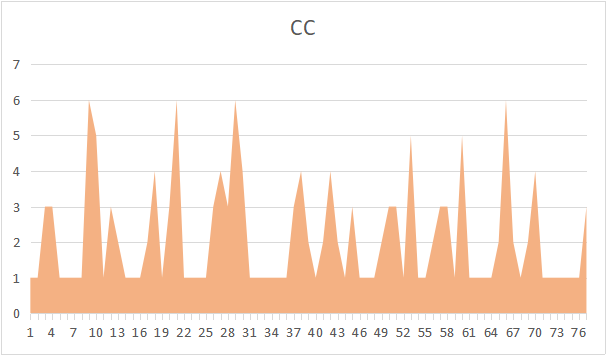
可以看到,第二&三次的代码中,LOC和PC存在着基本一致的分布性。这说明了圈复杂度同代码行数具有一定程度上的关系。
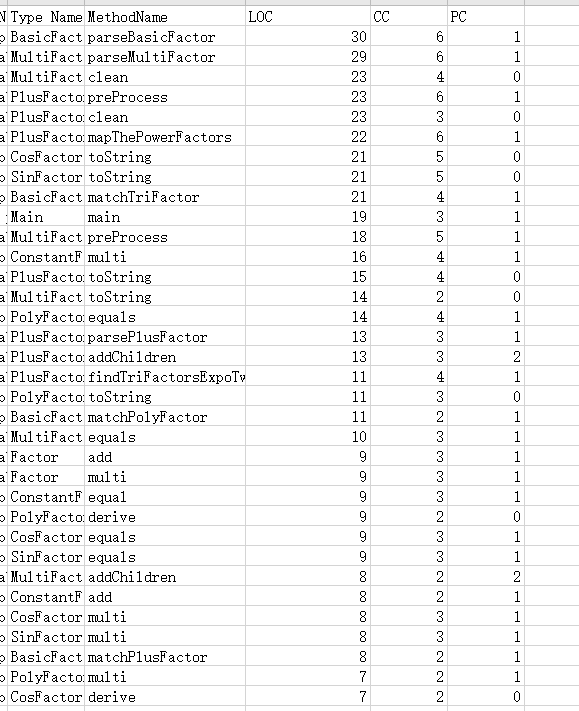
上图中可见,各种因子解析函数的复杂度较高,其次是字符串相关处理和输出函数和优化相关函数。令我奇怪的是字符串相关函数的复杂度会比优化函数的复杂度,个人思考认为这与字符串输出函数中涉及大量的条件判断(以输出符合要求和性能分更好的字符串)有关。
喜闻乐见的异味环节(Smell)
个人认为这些异味(Smell)具有很强的指示性(即使他们看起来更像代码规范要求)。其能够指出代码中存在的可能问题,实打实地表现了可能妨碍维护和迭代的点,比如Magic Number等。
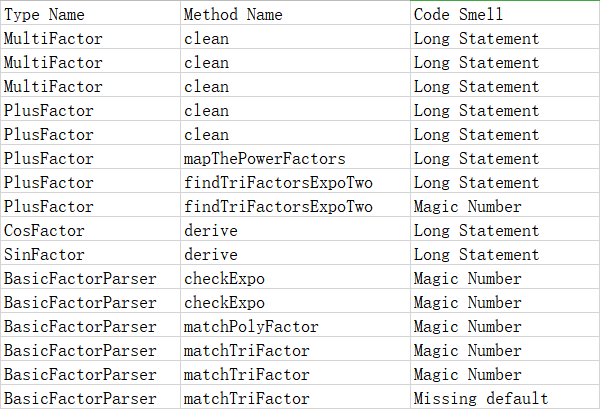
首先,我们看方法中的Smell。上图中可以发现,Magic Number是较多的,原因之一是因为设计书要求(比如幂数不高于50等),其二是字符串解析和输出的需要(比如幂数为1时需要特殊处理等)。其次是statement过长,这其实指出了设计中较容易出问题的地方(事实上,这些statement过长的部分恰恰是debug过程中的硬骨头)。然后Smell也有助于指出一些代码编写上的错误,比如Missing Default这种可能导致崩溃的设计。
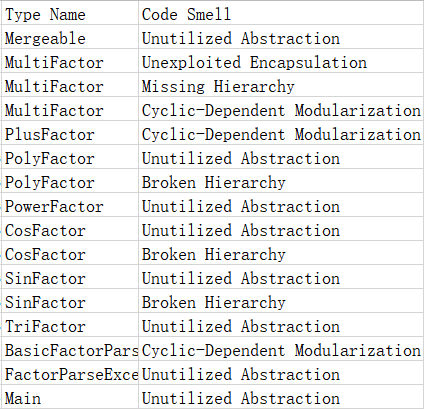
其次,我们看上图中可以发现,最频繁的问题是Unutilized Abstraction,这意味着有的抽象没有使用,个人研究后发现这是迭代过程中旧的函数没有删干净而导致的,多是一些私有方法。其次,在PowerFactor的子类中出现了Broken Hierarchy问题,研究发现其是由于其子类有同样功能的函数但是没有在PowerFactor中统一声明而是分开声明并实现了(属于类设计的缺陷)。最后,在MultiFactor、PlusFactor两个复合类和BasicFactorParser这个统一解析类中产生了Cyclic-Dependent Modularization,这是因为前两者中的合并优化函数是通过调用表达式树的子节点(而这个子节点有可能和父节点是同一个类),后者是因为解析过程中包括解析表达式因子,会调用PlusFactor的解析函数,而PlusFactor的解析函数又会调用这个统一解析类。
重构前后的度量对比
在由于圈复杂度和代码行数的正比性,以及迭代时的要求存在差异性,因此代码量上的差异是显而易见的,在此按下不表。
因此我在重构的度量下更加重视类的设计差异。我们来看两次架构下的typeMetrics:
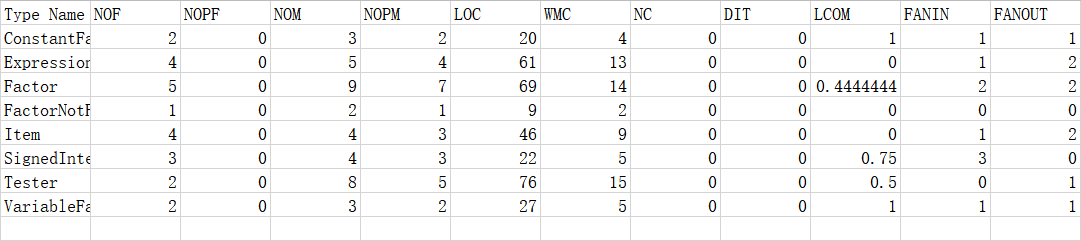
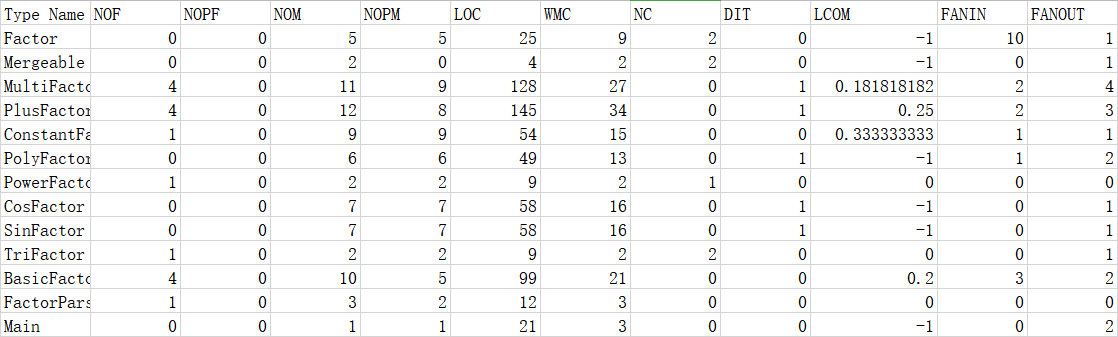
可以看出,第一次作业中的FANIN值较低、LCOM较高,明显比第二次作业的复用性更低、聚合度更低。这些特点尤其体现在SignedIntergerWithZeroAhead类(万恶之源,现在看起来,都想直接删了它)。而由于两次作业在架构上完全不同,对具体实现的方法的设计基本无法对比,但是根据度量的结果我们仍然能够看出架构的优劣性。这也是我这次第一次使用OO度量时被惊艳到的一点。
BUG反思——粗心大意、悔不当初
在第二次和第三次作业中,我都没能通过强测,使得每强测得分都丢了10分左右(正确样例下性能分基本在99.9级)。这也使得我非常沮丧,这基本宣告了我第一单元作业的彻底失败。但是也没有办法,事已至此,希望自己能从失败中多得到点新的经验吧……
这两次作业中我基本没有在BUG修复阶段花费时间,因为BUG都在我进行互测的过程中就自我发掘了出来……而且更加坑的点在于都是一些较为愚蠢的错误:
-
第二次作业:SinFactor在进行相乘操作时将自身的this作为返回值返回了回去,导致在构建完成后的再优化过程中会造成bug。
-
第三次作业:PolyFactor的toString()方法中特判了expo==2的情况,而输出为x*x,系第二次作业所做优化与第三次作业要求不符导致错误。
总结一下这两次失误。实际上bug位置都是很容易就能发现出来了的,debug时间不会超过10min,但是在提交前的程序测试过程中没能发现问题而提交了。原因有三:
-
没有仔细分析两次作业之间要求的差异性,过于注重题目的增量,而对要求的变更不敏感。
-
没有测评机(实际上第三次作业时有,但是是第二次作业后构建的,然后由于原因一,所以测评机也没考虑到题目要求的变更)。
-
最主要的,对语言的理解程度不够,编程的手感没有练好,犯的都是低级错误,实在不应该。
在这里我也想吐槽一下自己的运气……每次都是22点前构造的数据一点问题都测不出来,互测阶段随便丢几个新造的数据就发现自己的问题了(悲),还有的问题(比如x*x的那个bug)其实水群里已经讨论过,但是我没有看到(水群有益论)。
以下为这两个bug出处的函数行和圈复杂度:

参照上文中的度量分析图,可以发现其实这两个BUG位置的圈复杂度和代码行数并不高,果然还是粗心大意惹的祸……
互测——用力过猛……但是用错了方向
我在第二次作业互测阶段才意识到评测机的重要性,结果用力过猛了……
设计的评测机原本只是一个样例生成机,后来利用Python的subprocess.Popen函数实现了自动评测。后来发现,既然都使用了subprocess,为什么我们不再来个多线程呢?加了多线程后,发现同质BUG重复性较高,有的同学每测两个样例就会WA,而如何判断BUG的同质性呢?我采用了一种取巧的方法,即对bug较多的程序分模块进行测试(谢天谢地,这些同学的模块划分做的还不错),如果多个bug定位在一个功能模块内,就认为其是一个同质bug,那我只丢两三个相关攻击样例。然后发现人工进行多个模块划分的话,我太累了。于是模块划分就变成了划分为通用性的解析+输出、求导+输出、输出三个部分,这样的话只需要前期较小的人工划分操作即可。
做完这些事情后,我试着跑了一下我的程序,它特别吃性能,跑评测过程中基本没法做其他事情。于是我想起了我在TencentCloud上还买过一个小服务器……emm,just do it。然后我在云服务器上配置了anaconda后把评测机上了云,然后还设想用邮件每半小时更新一次战况发送给我。但是天有不测风云,第三次作业互测过程就限制了互测攻击者的攻击能力,因此这个邮件功能就没加了。我也能理解课程设计者的想法,不能提倡这种卷的风气,这门课的目标不是培养优秀的自动化测试人员,而是优秀的面向对象编程的程序员。
总结互测过程,我认为最大的困难在于跳出自己的思维去理解他人的代码。由于具有一定先入为主的理念,导致我阅读其他代码时会代入自己的设计想法,导致我会想当然地认为其同名函数的实现的方式和我的一致(但是实际上可能是完全不同的)。我只能对其程序进行简单的划分并进行随机样例测试,却很难针对其代码上的特定位置的bug进行攻击,这也是我需要思考和改进的点。事后反思,OO互测的要求压缩样例长度等限制,目的就是在于希望我们有的放矢而不是依靠大量数据去乱打一气,我的想法过于依赖数据量和构建规则了……

 浙公网安备 33010602011771号
浙公网安备 33010602011771号