Redis集群配置
参考文档:
- redis官网:https://redis.io/
- redis集群教程:http://www.redis.cn/topics/cluster-tutorial.html
- 单机安装参考:http://www.runoob.com/redis/redis-install.html
- 集群部署参考:http://zyxjohn.blog.51cto.com/5313197/1932714
- 配置文件参考:http://www.cnblogs.com/zhoujinyi/p/6430116.html
- 集群管理,测试参考:http://www.cnblogs.com/zhoujinyi/p/6477133.html
本文简单介绍redis及其集群的配置操作。
一.环境
1. OS
Server:CentOS-7-x86_64-1511
Node1:10.11.4.201
Node2:10.11.4.202
Node3:10.11.4.203
2. redis版本
redis-4.0.0:https://redis.io/download
rubygemredis-3.3.3.gem:https://rubygems.org/gems/redis
二.安装redis服务器
以node1为例,node2/node3配置根据环境微调。
1. 安装redis
[root@node1 ~]# cd /usr/local/src/ [root@node1 src]# wget http://download.redis.io/releases/redis-4.0.0.tar.gz [root@node1 src]# tar -zxvf redis-4.0.0.tar.gz [root@node1 src]# cd redis-4.0.0 #没有“configure”,直接“make”; #在安装的时候指定“PREFIX”,注意不带“--”,不指定时默认安装到“/usr/local/bin”下; #解压目录下的“src/“下的二进制文件可直接运行 [root@node1 redis-4.0.0]# make [root@node1 redis-4.0.0]# make PREFIX=/usr/local/redis install
2. 设置环境变量
#如果是单节点,至此就已安装完成,可直接启动; #启动指令:”/usr/local/redis/redis-server“,采用默认配置; #也可在启动指令后带”redis.conf”文件指定conf文件; #”redis.conf”默认文件在解压目录下有范本,可直接使用 [root@node1 src]# cd /usr/local/redis/ [root@node1 redis]# ln -s /usr/local/redis/bin/* /usr/local/bin/
3. 配置redis.conf文件
#预设redis运行的pid,log文件,数据等的目录等 [root@node1 ~]# cd /usr/local/redis/ [root@node1 redis]# mkdir -p /usr/local/redis/etc [root@node1 redis]# mkdir -pv /usr/local/redis/var/{run,log} [root@node1 redis]# mkdir -pv /usr/local/redis/var/lib/{redis_6379,redis_6380} #redis以进程为实例,可以根据每台宿主机的性能与redis的负载运行若干实例,只要区分每个实例的监听端口即可; #本实验每台宿主机运行两个实例以验证主从的自动分配; #以监听端口重新命名redis.conf文件 [root@node1 redis]# cp /usr/local/src/redis-4.0.0/redis.conf /usr/local/redis/etc/redis_6379.conf #对于集群配置,以下配置文件中,配置深蓝粗体字部分即可,其余可采用默认配置; #redis.conf文件的详细配置请参考:http://www.cnblogs.com/zhoujinyi/p/6430116.html; #本宿主机的另一个实例conf文件请参考以上配置修改,可以复制已配置完成的redis_6379.conf为redis_6380.conf后,vim采用“:1,$s/6379/6380/gc”修改。 [root@node1 redis]# vim /usr/local/redis/etc/redis_6379.conf #监听地址,这里设置全地址监控; #开启/关闭实例的脚本中,关闭实例时调用的是127.0.0.1地址。 bind 0.0.0.0 #监听端口 port 6379 # 默认没有在后台执行 daemonize yes # 定义pid与log路径,根据上文预设配置 pidfile /usr/local/redis/var/run/redis_6379.pid logfile "/usr/local/redis/var/log/redis_6379.log" # 集群模式默认是关闭的 cluster-enabled yes # 集群配置文件的名称,每个节点都有一个集群相关的配置文件,持久化保存集群的信息; # 此文件不需要手动配置,由Redis生成并更新; # 每个Redis集群节点/实例需要一个单独的配置文件,同一宿主机系统中不同实例的配置文件名称不能冲突 cluster-config-file nodes-6379.conf # 集群节点超时时间,单位毫秒,集群内部多种通信时间限制以此超时时间倍数为准 cluster-node-timeout 15000 #由redis服务器自动生成,默认情况下,redis服务器程序会定期自动对数据库做一次遍历,把内存快照写在一个叫做“dump.rdb”的文件里,这个持久化机制叫做SNAPSHOT; #有了SNAPSHOT后,如果服务器宕机,重新启动redis服务器程序时,redis会自动加载dump.rdb,将数据库状态恢复到上一次做SNAPSHOT时的状态 dbfilename "dump.rdb" #数据目录,数据库写入此目录,redis 存储分为内存储存、磁盘存储和log文件三部分; #rdb、aof文件也写在此目录; #rdb持久化可以在指定的时间间隔内生成数据集的时间点快照(point-in-time snapshot);即全量数据(rdb):把内存中的数据写入磁盘,便于下次读取文件进行加载; #aof持久化可以记录服务器执行的所有写操作命令,并在服务器启动时,通过重新执行这些命令来还原数据集;aof文件中的命令全部以redis协议的格式来保存,新命令会被追加到文件的末尾;redis 还可以在后台对aof文件进行重写(rewrite),使得aof文件的体积不会超出保存数据集状态所需的实际大小;即增量请求(aof):是把内存中的数据序列化为操作请求,用于读取文件进行replay得到数据; #redis还可以同时使用aof持久化与rdb持久化,此时,当redis重启时,它会优先使用aof 文件还原数据集,因为aof文件保存的数据集通常比rdb文件所保存的数据集更完整。 dir "/usr/local/redis/var/lib/redis_6379"
4. 配置开机启动
1)配置启动脚本
#配置启动脚本,根据前文的配置文件修改相关参数,可对每个实例分别配置; #配置启动脚本主要是方便启动/关闭服务,不必每次指定redis.conf文件; #也可通过”redisl-server &”或者”redis-server xxx/redis.conf”等方式启动服务; #以下启动脚本的蓝色粗体字体基于默认配置的修改或新增 [root@node1 ~]# cp /usr/local/src/redis-4.0.0/utils/redis_init_script /etc/init.d/redis_6379 [root@node1 ~]# vim /etc/init.d/redis_6379 #!/bin/sh # chkconfig: 35 10 90 #重要!否则chkconfig不能识别开机启动服务项; #”35”为运行级别,”10”为启动优先级,”90”为关闭优先级 # # Simple Redis init.d script conceived to work on Linux systems # as it does use of the /proc filesystem. REDISPORT=6379 # EXEC=/usr/local/bin/redis-server EXEC=/usr/local/redis/bin/redis-server # CLIEXEC=/usr/local/bin/redis-cli CLIEXEC=/usr/local/redis/bin/redis-cli # PIDFILE=/var/run/redis_${REDISPORT}.pid PIDFILE=/usr/local/redis/var/run/redis_${REDISPORT}.pid # CONF="/etc/redis/${REDISPORT}.conf" CONF="/usr/local/redis/etc/redis_${REDISPORT}.conf" USER=redis #添加执行用户变量 case "$1" in start) if [ -f $PIDFILE ] then echo "$PIDFILE exists, process is already running or crashed" else echo "Starting Redis server..." # $EXEC $CONF su - $USER -c "$EXEC $CONF" #非root账号启动服务 fi ;; stop) if [ ! -f $PIDFILE ] then echo "$PIDFILE does not exist, process is not running" else PID=$(cat $PIDFILE) echo "Stopping ..." # $CLIEXEC -p $REDISPORT shutdown su - $USER -c "$CLIEXEC -p $REDISPORT shutdown" #非root账号关闭服务 while [ -x /proc/${PID} ] do echo "Waiting for Redis to shutdown ..." sleep 1 done echo "Redis stopped" fi ;; restart|force-reload) ${0} stop ${0} start ;; *) echo "Usage: /etc/init.d/redis {start|stop|restart|force-reload}" >&2 exit 1 Esac [root@node1 ~]# cp /etc/init.d/redis_6379 /etc/init.d/redis_6380 [root@node1 ~]# vim /etc/init.d/redis_6380 #修改“REDISPORT”变量值 REDISPORT=6380
2)设置开机启动
[root@node1 ~]# chkconfig --add redis_6379 [root@node1 ~]# chkconfig --level 35 redis_6379 on #默认runlevel 35已打开 [root@node1 ~]# chkconfig --add redis_6380 [root@node1 ~]# chkconfig --level 35 redis_6380 on
5. 创建账号并赋权
#因为redis很容易对服务器进行root账号提取,建议使用非root账户启动redis服务; #使用创建的账号执行脚本文件,对服务启动/关闭,账号需要有执行shell的权限。 [root@node1 ~]# groupadd redis [root@node1 ~]# useradd -g redis -s /bin/bash redis [root@node1 ~]# chown -R redis:redis /usr/local/redis [root@node1 ~]# chown redis:redis /etc/init.d/redis_6379 [root@node1 ~]# chown redis:redis /etc/init.d/redis_6380 [root@node1 ~]# chmod +x /etc/init.d/redis_6379 #默认有执行权限,可不设置 [root@node1 ~]# chmod +x /etc/init.d/redis_6380
6. 设置iptables
[root@node1 ~]# vim /etc/sysconfig/iptables -A INPUT -p tcp -m state --state NEW -m tcp --dport 6379 -j ACCEPT -A INPUT -p tcp -m state --state NEW -m tcp --dport 6380 -j ACCEPT [root@node1 ~]# service iptables restart
7. 启动
#可通过启动脚本启动/关闭服务;或采用”service”指令 [root@node1 ~]# su - redis -c "/etc/init.d/redis_6379 start" [root@node1 ~]# su - redis -c "/etc/init.d/redis_6380 start"

8. 验证
[root@node1 ~]# ps aux | grep redis #注意启动账户 [root@node1 ~]# netstat -tunlp | grep redis

三.配置redis cluster
Redis 3.0之后,官方版本支持了Cluster,与之前的第三方cluster相比(如Twenproxy、Codis),Redis Cluster没有使用Porxy的模式来连接集群节点,而是使用无中心节点的模式来组建集群。
在Cluster出现之前,只有Sentinel保证了Redis的高可用性。
Redis Cluster在多个节点之间进行数据共享,即使部分节点失效或无法进行通讯时,Cluster仍然可以继续处理请求。
如果每个主节点都有一个从节点支持,在主节点下线或无法与集群的大多数节点进行通讯的情况下,从节点提升为主节点,并提供服务,保证Cluster正常运行。
Redis Cluster的节点分片是通过哈希槽(hash slot)实现的,每个键都属于这 16384(0~16383) 个哈希槽的其中一个,每个节点负责处理一部分哈希槽。
1. 配置集群管理工具
#redis作者基于ruby写了集群管理工具,首先安装ruby相关依赖。 [root@node1 ~]# yum install ruby rubygems -y [root@node1 ~]# cd /usr/local/src/ [root@node1 src]# wget https://rubygems.org/downloads/redis-3.3.3.gem [root@node1 src]# gem install redis-3.3.3.gem
#集群管理工具redis-trib.rb在解压包中已包含; #redis-trib.rb是基于ruby的集群管理工具,如果不使用此工具,也可以手工创建集群,具体操作请见:http://www.cnblogs.com/zhoujinyi/p/6477133.html [root@node1 src]# cp /usr/local/src/redis-4.0.0/src/redis-trib.rb /usr/local/redis/bin/ [root@node1 src]# ln -s /usr/local/redis/bin/redis-trib.rb /usr/local/bin/ redis-trib.rb具有以下功能: 1) create:创建集群 2) check:检查集群 3) info:查看集群/节点信息 4) fix:修复集群 5) reshard:在线迁移slot 6) rebalance:平衡集群节点slot数量 7) add-node:将新节点加入集群 8) del-node:从集群中删除节点 9) set-timeout:设置集群节点间心跳连接的超时时间 10) call:在集群全部节点上执行命令 11) import:将外部redis数据导入集群
2. 创建集群
1)创建集群
[root@node1 ~]# redis-trib.rb create --replicas 1 10.11.4.201:6379 10.11.4.201:6380 10.11.4.202:6379 10.11.4.202:6380 10.11.4.203:6379 10.11.4.203:6380
- 节点已自动分配主从关系,且主节点分布在不同的宿主机上,10.11.4.201与10.11.4.202节点上的实例互为主从,但10.11.4.203上的两个实例互为主从有一定的风险;
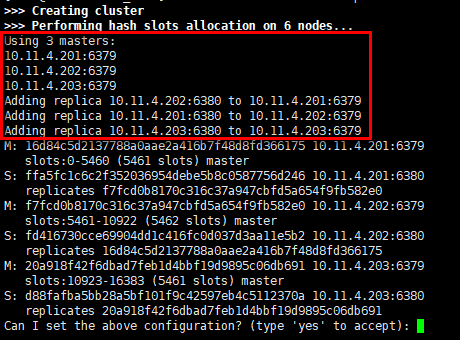
- 同意分配计划,输入"yes"后,各节点开始通讯,并协商哈希槽的分配,最后输出报告指出各主节点分配的哈希槽,16384个哈希槽全部分配完毕,集群创建成功。

2)注意事项
- (1) "--replicas 1"参数,指定每个主节点配置的从节点数量,如果这里设置为1,最少3个主节点的情况下,总节点数不能低于6,否则集群不能成功创建;
-
(2) 加入集群的节点必须是空节点,不包含槽/数据信息,否则不能加入集群,报错如下:
[ERR] Node 10.11.4.201:6379 is not empty. Either the node already knows other nodes (check with CLUSTER NODES) or contains some key in database 0.
解决方案如下:
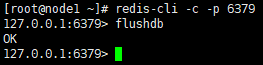
- 停止redis服务;
- 删除相关或全部节点的appendonly.aof,dump.rdb,nodes.conf文件;
- 一般执行上面两步即可,如果还不行可执行清库操作
-
[root@node1 ~]# redis-cli -c -p 6379 127.0.0.1:6379> flushdb
-
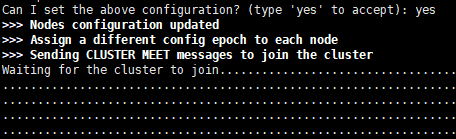
(3) 在同意集群分配方案,输入"yes"后,进行到"Waiting for the cluster to join"阶段,但一直处于等待状态,无报错,现象如下:
![]()
原因:redis集群除提供给客户端连接的端口外,还有集群通讯的"集群总线端口",此端口为客户端连接端口+10000,这里即为:16379/16380
解决方案如下:
- iptables放行相关端口或关闭iptables服务。
3)集群创建流程
-
(1) 为每个节点创建ClusterNode对象,包括连接每个节点,检查每个节点是否为独立且db为空的节点,执行load_info方法导入节点信息。
-
(2) 检查传入的master节点数量是否大于等于3个,只有大于3个节点才能组成集群。
-
(3) 计算每个master需要分配的slot数量,同时为master分配slave,分配的算法大致如下:
- (a) 将节点按host分类,这样保证master节点能分配到更多的主机中。
- (b) 不停遍历host列表,从每个host列表中弹出一个节点,放入interleaved数组,直到所有的节点都弹出为止;master节点列表就是interleaved前面的master数量的节点列表,保存为masters数组。
- (c) 计算每个master节点负责的slot数量,保存在slots_per_node对象,用slot总数除以master数量取整即可。
- (d) 遍历masters数组,每个master分配slots_per_node个slot,最后一个master,分配到16384个slot为止。
-
(e) 为master分配slave,分配算法会尽量保证master和slave节点不在同一台主机上;对于分配完指定slave数量的节点,如果还有多余的节点,也会为这些节点寻找master。
分配算法会遍历两次masters数组:第一次遍历masters数组,在余下的节点列表找到replicas数量个slave,每个slave为第一个和master节点host不一样的节点,如果没有不一样的节点,则直接取出余下列表的第一个节点;第二次遍历是在对于节点数除以replicas不为整数,则会多余一部分节点,遍历的方式跟第一次一样,只是第一次会一次性给master分配replicas数量个slave,而第二次遍历只分配一个,直到余下的节点被全部分配出去。
-
(4) 打印出分配信息,确认是否按照给出分配方式创建集群。
-
(5) 输入"yes"同意后,执行flush_nodes_config操作,该操作执行前面的分配结果,给master分配slot,让slave复制master;对于还没有握手(cluster meet)的节点,slave复制操作无法完成,但flush_nodes_config操作出现异常会很快返回,后续握手后会再次执行flush_nodes_config。
-
(6) 为每个节点分配epoch,遍历节点,每个节点分配的epoch比之前节点大1。
-
(7) 节点间开始相互握手,握手的方式为节点列表的其他节点与第一个节点握手。
-
(8) 然后每隔1秒检查一次各节点是否已经消息同步完成,使用ClusterNode的get_config_signature方法,检查的算法为获取每个节点cluster nodes信息,排序每个节点,组装成node_id1:slots|node_id2:slot2|...的字符串,如果每节点获得字符串都相同,即认为握手成功。
-
(9) 再执行一次flush_nodes_config,这次主要是为了完成slave复制操作。
-
(10) 最后再执行check_cluster,全面检查一次集群状态;包括和前面握手时检查一样的方式再检查一遍,确认没有迁移的节点,确认所有的slot都被分配出去了。
-
(11) 至此完成了整个创建流程,返回"[OK] All 16384 slots covered."。
四.验证
1. 集群检查
1)redus-trib.rb
#首先列出检查点的状态信息,节点10.11.4.203:6379是主节点,分配的哈希槽是10923~16383,有1个从节点运行; #其他节点的信息也会列出,最后检查哈希槽的分配状态; #“redis-trib.rb info 10.11.4.201:6379”可以查看单节点信息 [root@node1 ~]# redis-trib.rb check 10.11.4.203:6379
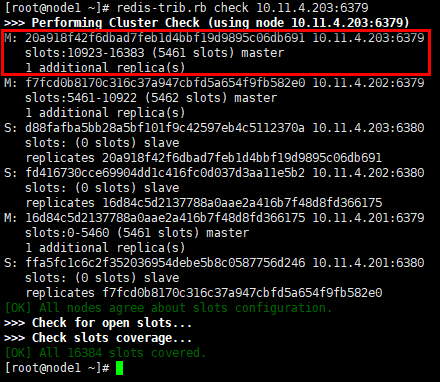
2)CLUSTER命令
#”cluster info”,列出集群状态,16384个哈希槽已全部分配等; #”cluster nodes”,分别列出每个节点的集群id,状态等。 [root@node1 ~]# redis-cli -c -h 10.11.4.202 -p 6379 10.11.4.202:6379> cluster info 10.11.4.202:6379> cluster nodes
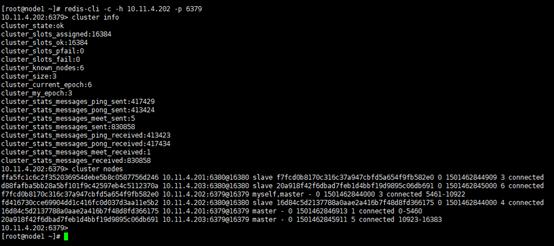
#”cluster slots”可以查看槽位与对应节点的信息 [root@node1 ~]# redis-cli -c -h 10.11.4.202 -p 6379 10.11.4.202:6379> cluster slots

2. 数据测试
具体数据测试,failover可参考:http://www.cnblogs.com/zhoujinyi/p/6477133.html
1)Key-Value建立与查询
[root@node1 ~]# redis-cli -c -h 10.11.4.202 -p 6379 10.11.4.202:6379> set test world 10.11.4.202:6379> get test 10.11.4.202:6379> exit

#在节点10.11.4.203:6379上获取key值”test”,会有一个重定向动作,将”test”的value指向6918哈希槽,在10.11.4.202:6379节点上 [root@node1 ~]# redis-cli -c -h 10.11.4.203 -p 6379 10.11.4.203:6379> get test
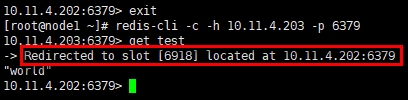
#”cluster countkeysinslot XXX”可以获取指定哈希槽的key的数量 [root@node1 ~]# redis-cli -c -h 10.11.4.202 -p 6379 10.11.4.202:6379> cluster countkeysinslot 6918

2)在线迁移
#在线迁移可用于将集群中的一些slot从源节点迁移到目的节点,如完成集群的在线横向扩容或缩容。 [root@node1 ~]# redis-trib.rb reshard 10.11.4.202:6379 #迁移槽位数量 How many slots do you want to move (from 1 to 16384)? 1 #迁移目的节点 What is the receiving node ID? 20a918f42f6dbad7feb1d4bbf19d9895c06db691 #迁移源节点 Source node #1:f7fcd0b8170c316c37a947cbfd5a654f9fb582e0 Source node #2:done #迁移计划执行与否 Do you want to proceed with the proposed reshard plan (yes/no)? yes
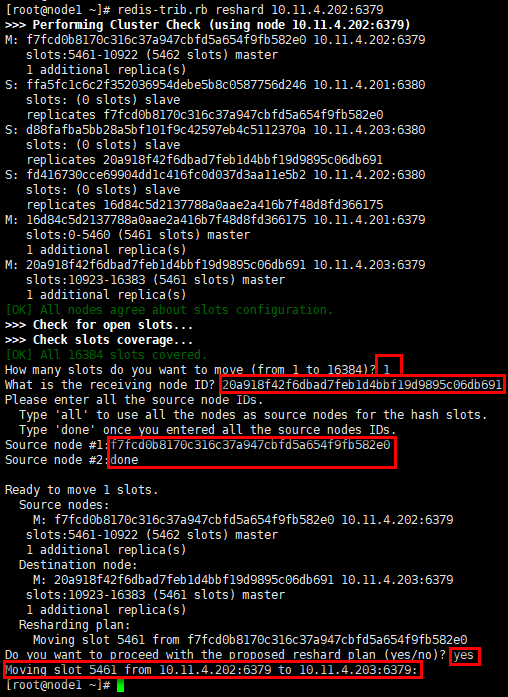
#哈希槽5461已从10.11.4.202节点迁移到10.11.4.203节点; #迁移后,哈希槽分布不均,可采用redis-trib.rb的“rebalance”进行平衡 [root@node1 ~]# redis-cli -c -h 10.11.4.203 -p 6379 10.11.4.203:6379> cluster nodes


 浙公网安备 33010602011771号
浙公网安备 33010602011771号