
ENode 1.0 - Staged Event-Driven Architecture思想的运用
Posted on 2013-07-09 01:04 netfocus 阅读(4897) 评论(26) 收藏 举报开源地址:https://github.com/tangxuehua/enode
上一篇文章,简单介绍了enode框架的command service api设计思路。本文介绍一下enode框架对Staged Event-driven architecture思想的运用。通过前一篇文章我们知道command service是会被高并发的访问,我们除了可以用异步的方式执行command以及集群的方式来提高系统响应性能外。最根本上要解决的问题是尽量快的处理单个command。这样才能在单位时间内处理更多的command。
先贴一下enode框架的内部实现架构图,这样对大家理解后面的分析有帮助。
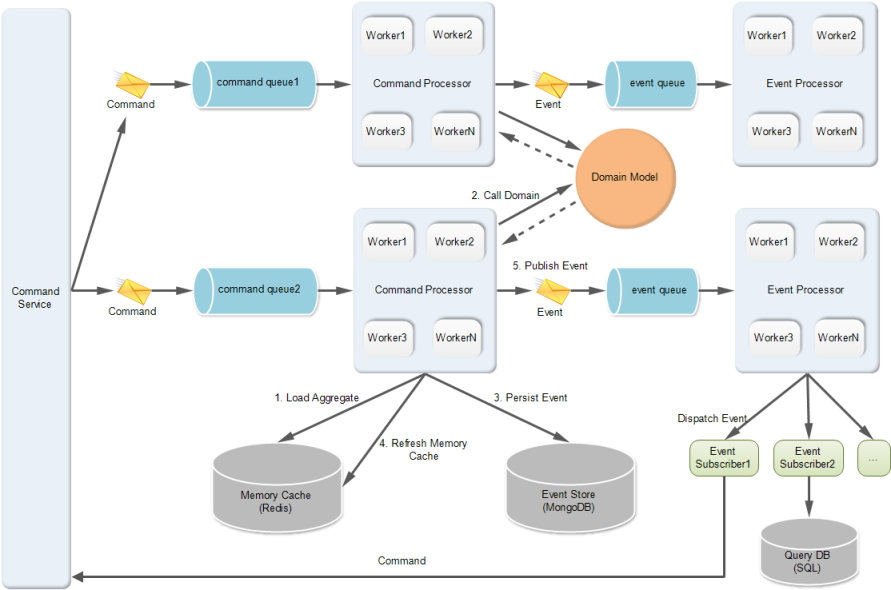
我觉得要尽量快的处理command,主要思路有两点:
能并行处理的尽量并行
- command service接收到command后,会把command发送到某个可用的command队列。然后该command队列的出口端,如果只有单个线程在处理command,而且这个线程如果有IO操作,那肯定快不到哪里去;因为只要处理单个command的速度跟不上command进入队列的速度,那command队列里的command就会不断增多,导致command执行的延迟增加。所以,思路就是,设计多个线程(就是上图中的Command Processor中的worker)来同时从command队列拿command,然后处理。这样就能实现多个线程在同时处理不同的command。
- 但是光这样还不够,实际上我们还可以做的更好,那就是command queue也可以设计为多个。也就是说command service接收到command后,会通过一个command router,将当前command路由到某个可用的command队列,然后将该command发送到该队列。这样做的好处是,我们的command service背后有多个command队列(上图画了两个command queue)支撑着,每个command队列的出口端又有多个线程在同时处理。这样的话,我们就能最大化的压榨我们的服务器CPU和内存等资源了。当然,框架要支持允许用户配置多少个command队列,以及每个队列多少个线程处理。这样框架使用者就能根据当前服务器的CPU个数来决定该如何配置了。
- 同理,domain model产生的事件(domain event)的处理也应该要并行处理;那具体是什么处理呢?就是上图中的Event Processor所做的事情。Event Processor会包含多个worker,每个worker就是一个线程。每个worker会从event queue中拿出事件,然后将事件进一步分发(dispatch)给所有的事件订阅者。
那么上面这些并行执行的逻辑是如何访问共享资源的呢?
对于command processor中的每个work线程,从上面的架构图可以清晰的看到,共享资源是event store和memory cache。event store,我们会并发的写入事件;memory cache,我们会并发的更新聚合根。所以,这两种存储都必须很好的支持高并发的写入,且要高效;经过我的一些调研,个人觉得mongodb比较适合作为eventstore。原因是:1)支持集群和sharding;2)支持唯一索引;3)支持关系型查询;4)高性能,默认是先保存到内存,每100ms将内存数据写入日志,每1分钟将内存数据正式写入磁盘;基于这4点,我们能利用mongodb实现一个比较理想的eventstore。而内存缓存(memory cache),我觉得memcached或者redis都还不错,都是比较成熟的分布式缓存。利用分布式缓存,我们不必担心数据放不下的问题,因为我们可以对数据按特征进行分区存放。这个思路就像数据库的分库分表类似。需要注意的是,eventstore必须支持严格控制并发冲突,mongodb的唯一索引可以确保这一点;而memory cache,不用支持并发冲突检测,只要能保障快速的根据key读写即可。因为我们总是先持久化完事件后再将最新状态的聚合根更新到memory cache,而持久化事件到eventstore已经做了并发冲突检测,所以更新到memory cache就一定也是按照事件持久化的顺序被更新到memory cache的。另外,实际上event store和memory cache是被整个web服务器集群所共享的。不过幸好mongodb,redis等产品足够强大,都支持横向扩展,所以我们完全有信心在web服务器不断增加的情况下,也对mongodb,redis做相应的横向扩展,从而不会让这两个地方产生瓶颈。
能允许延迟处理的尽量延迟
处理每个command时,会调用domain model执行业务逻辑,然后domain model会产生事件(domain event)。然后框架会在command处理完毕后自动对事件进行后续的处理。主要做的事情是:1)持久化事件到eventstore;2)更新memory cache;3)将事件publish出去。这三步分别对应上图中的3、4、5三个箭头。大家可以看到,对于publish事件这一步,我们不是马上将事件dispatch给事件订阅者的,而是先发送到event queue,然后异步的方式dispatch事件。
这里可以这样做的原因是,当领域事件被持久化到eventstore,本质上就已经表示业务逻辑处理完成了。事件是一件已发生的事情,事件被保存了就表示这件已发生的事情被记载了,也就是说,成为了历史。当我们下次要获取最新的聚合根时,如果从内存缓存里获取到的聚合根的状态是旧的,那从eventstore中通过event sourcing得到的聚合根一定是最新的,因为eventstore中存放了所有最新的历史。所以,我们可以知道,只要事件被持久化完成了,那后续的所有步骤都可以异步的方式来做。但是为什么更新memory cache没有异步的做呢?因为command handler在处理业务逻辑时,获取聚合根是从memory cache获取的,所以越早更新memory cache,我们拿到的聚合根的数据就越可能是最新的,拿到的数据越新,就意味着产生并发冲突的可能性就越低。实际上,因为像memcached, redis这样的分布式缓存,性能是非常高的,每秒1万次的读写操作问题应该不大。所以,我们可以认为内存缓存中的数据总是与eventstore实时保持一致的,因为延迟在0.1毫秒以内。因此,我们会在事件被保存到eventstore后,马上将最新状态的聚合根写入到memory cache。
但是,将事件dispatch给所有的事件订阅者这个操作是非常耗时的,因为我们无法知道每个事件订阅者具体做的事情,比如有些是更新CQRS查询端的读库的表,有些是调用外部系统的接口,等等。所以,dispatch这个逻辑必须异步,实际上,这也是CQRS架构的核心思路。另外,我们为了尽量快的dispatch事件,如上面提到,我们会开多个线程去并行的dispatch事件给事件订阅者。
有一个需要好好考虑的问题是:我们如何保证事件的持久化顺序与publish出去的顺序相同?这个问题,下次专门写一篇文章好好讨论吧。有兴趣的也可以想想为什么要解决这个问题,也非常欢迎和我讨论解决方案。
关于来自ebay的经验学习
可伸缩性最佳实践:来自eBay的经验,这篇文章中提到,提高可伸缩性的一项关键措施是积极地采取异步策略。
如果组件A同步调用组件B,那么A和B就是紧密耦合的,而紧耦合的系统其可伸缩性特征是各部分 必须共同进退——要伸缩A必须同时伸缩B。同步调用的组件在可用性方面也面临着同样的问题。我们回到最基本的逻辑:如果A推出B,那么非B推出非A。也就 是说,若B不可用,则A也不可用。如果反过来A和B的联系是异步的,不管是通过队列、多播消息、批处理还是什么其他手段,它们就可以分别地伸缩。而且,此 时A和B的可用性特征是相互独立的——即使B受困或者死掉,A仍然能够继续前进。
整个基础设施从上到下都应该贯彻这项原则。即使在单个组件内部也可通过SEDA(分阶段的事件驱动架构,Staged Event-Driven Architecture)等技术实现异步性,同时保持一个易于理解的编程模型。组件之间也遵守同样的原则——尽可能避免同步带来的耦合。在多数情况下, 两个组件在任何事件中都不会有直接的业务联系。在所有的层次,把过程分解为阶段(stages or phases),然后将它们异步地连接起来,这是伸缩的关键。
用异步的原则解耦程序,尽可能将过程变为异步的。对于要求快速响应的系统,这样做可以从根本上减少请求者所经历的响应延迟。对于网站或者交易系统, 牺牲数据或执行的延迟时间(完成全部工作的实践)来换取用户的延迟时间(用户得到响应的时间)是值得的。活动跟踪、单据开付、决算和报表等处理过程显然都 应该属于后台活动。主要用例过程中常常有很多步骤可以进一部分解成异步运行。任何可以晚点再做的事情都应该晚点再做。
还有一个同等重要的方面认识到的人不多:异步性可以从根本上降低基础设施的成本。同步地执行操作迫使你必须按照负载的峰值来配备基础设施——即使在任务最重的那一天里任务最重的那一秒,设施也必须有能力立即完成处理。而将昂贵的处理过程转变为异步的流,基础设施就不需要按照峰值来配备,只需要满足平 均负载。而且也不需要立即处理所有的请求,异步队列可以将处理任务分摊到较长的时间里,因而起到削峰的作用。系统的负载变化越大,曲线越多尖峰,就越能从异步处理中得益。
enode框架内部的实现思路,正是学习了这种SEDA的思想,将一个command的处理过程分为两个阶段(command执行,event分发),每个阶段尽量调用多的资源去并行处理,两个阶段之间通过队列连接,实现这两个阶段之间相互不受影响,比如事件分发失败不会影响command的执行;并且,因为两个阶段之间没有直接联系,所以事件分发虽然相对较慢,但也不会影响command的执行效率;这就是SEDA的好处,将过程分阶段,分阶段的依据是找出这个过程中哪些地方可以延迟执行,即可以允许异步执行。然后用队列衔接每个阶段,对每个阶段优化处理。
总结
通过上面的分析,我们知道了,enode框架内部实现的主要设计思路是:
- 每个系统依赖于enode框架都可以支持web服务器集群;
- 每台web服务器上面部署了一个enode框架实例;
- 每个enode框架实例有一个唯一的command service;
- 每个command service内部有多个command queue,通过command router来路由command;
- 每个command queue的出口端都有一个command processor在消费command;
- 每个command processor内部实际是通过多个worker线程在并行的消费command;
- 每个worker线程都访问共享的event store和memory cache资源;
- 每个worker线程在消费完一个command后,产生的事件先发送到一个可用的event queue,同样也会通过一个event queue router来路由;
- 每个event queue的出口端都有一个event processor在消费event;
- 每个event processor内部实际也是通过多个worker线程在并行的分发event给事件订阅者;
就写这些吧,希望本文能对大家理解enode有所帮助。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号