[深度学习大讲堂]文化、进化与局部最小值
本文为微信公众号[深度学习大讲堂]特约稿,转载请注明出处
Reference:Culture vs Local Minima [Bengio.2012]
关于作者
首次看到Bengio教授这篇论文是在[对话机器学习大神Yoshua Bengio(下)]
这篇论文是提问时候偶然提到的,按照Question中说法:
您(Bengio)是机器学习领域唯一公开的以深度学习来研究社会学的科学家。
所以相对于Hinton教授给我们带来生物神经方面的New Idea和Surprise(Hinton有剑桥认知心理学学士学位)
从社会、文化角度扩展Deep Learning是非常有必要的,Bengio教授把重点放在了这个方向,其实和他的研究经历有关。
他是神经网络(Forward-NN、Recurrent-NN)在自然语言处理(NLP)方向上推广的重要贡献人之一。[Bengio03]
如果你曾经品读过他的100页大论文 [Learning Deep Architectures for AI] ,就会不得不佩服Bengio教授的思想。
如果说Hinton创立了Deep Learning,那么Bengio就是Deep Learning最好的布道师和奠基人。
作为一位坚持不加入任何商业公司的纯粹学者、Quora最受欢迎的机器学习专家,他对Deep Learning和AI的贡献非常大。

学习情结
1.1 学习的两大动机
我们为何而学习?消磨人生?显然不是。
人类的学习情结大致由两方面构成:
(I) Predictive Criterion(预测):
我们会不自觉的受到[时间访问局部性]的浸染,即当前遭遇的知识(Context)很有可能在近期再次相遇(Encounter)。
显然,如果不对当前的Context进行剖析,那么意味着未来多次相遇时,无法做出预测(Prediction),得不偿失。
贪心机制会诱导我们尽早地对不确定的Context学习,用成语来讲就是“ 亡羊补牢,未为迟也”。
(II) Reward Criterion(激励):
一些与生存有关的问题会被独立诱导学习。
比如吃货在获取[如何满足口福]方面,显然有很强的积极性。
又比如,为了满足生理需求,人类在[性知识]方面的探索可谓是五花八门。
其中(I)广泛见于“监督学习”、“非监督学习”,(II)的相关工作由“强化学习”完成。
1.2 预测学习算法
“预测”显然在学习进程中处于主体地位,也是神经网络拟合模型的起源。
预测的相对确定性建立在,以当前参数$\theta$对不确定性样本评估的[误差]的[期望]:
$Criterion(\theta)=\int P(y)L(\theta,y)dy=E[L(\theta,y)]$
期望积分形式不是很直观,它有更亲切的表达形式:
$Criterion(\theta)=\frac{1}{N}\sum_{i=1}^{N}L(\theta,y)$
我们熟知的大部分监督学习算法,其优化目标基本都是$\min \limits_{\theta} \, Criterion(\theta)$
显然,当$\theta_{Optimization}\approx \theta_{Real}$,我们认为Optimization过程引导Agent完成了学习任务。
1.3 假设:优化
你觉得(II)是否很功利?显然是,我们人类只会贪婪地朝满足自己的目标发展,这是骨子里的[目标性]。
你觉得(I)是否很功利?显然也是,数学式不会给我们反驳的机会,这也是骨子里的[目标性]。
综合(I)(II),Bengio提出了第一个假设:
|
Optimization Hypothesis:When the brain of a single biological agent learns, it performs an approximate optimization with respect to some endogenous objective. |
推理、然后误入歧途
2.1 瞬时速度与平均速度
考虑一个高一物理题:
|
2330米的赛跑,跑道为圈,某人以匀速跑完一圈用了10s。求平均速度、恰达终点时的瞬时速度? |
解:
平均速度=0/10=0m/s
瞬时速度=2330/10=233m/s
这是一个有趣的问题,因为从微观上来讲,这个人很努力地跑,大家心知肚明。
但是,从宏观上来讲,他其实在原地踏步,浪费时间。
这样的问题在自然界是普遍存在的,贯穿[人类文明]的发展。
2.2 微观视点:推理
推理(Inference)过程是相当微观、细致的,起码它是神经元级别的变化。
非线性分类模型的拓扑结构,基本都有隐变量(Latent variables)。
隐变量经过非线性的激活(重视or不重视),变成隐元(Hidden Units),(注:SVM的隐元即支持向量)。
隐元介于输入和输出之间,包含着对输入的[编码信息],解释(explain)着当前的观测样本。
在Forward-NN里,隐元只和上一层隐元(或输入)连接[前向连接],在Recurrent-NN里,隐元还和当前层隐元连接[递归连接]。
推理是迭代的(iterative),时间尺度为[秒级],不停地修改[Configurations],尽可能认同更多的(agree more)观测样本。
每次瞬时的变化(change),意味着心智状态(state of mind)的瞬变。
变化的跳跃范围可能很大,因为神经元数量众多,且很敏感,容易牵一发而动全身。不像学习,是一个徐徐渐进的过程。
2.3 宏观视点:学习
学习是一个渐进、积累的过程,时间尺度为[分钟级]。
推理算是学习的子过程,个人用一个有趣数学式来表达:
$Learning(t)=\int Inference(t)dt$
即对推理过程函数中的[时间]进行积分,得到学习过程函数。
回到瞬时速度和平均速度问题,众多推理过程可能是雄心勃勃的,但是构成的学习过程却可能是毫无意义的。
正如积分最倒霉的是积成了[零],只要积分曲线(面)具有对称性。推理过程显然也可以呈现对称性,而且是大量地对称性。
网络上的一个著名励志段子:
当你的所拥有的知识撑不起你的野心时,你只能 静下心去努力学习 原地打转。
闭门造车的推理,即便花了时间,得到的其实还是[零]。
2.4 局部最小值:上帝也无法逃离?
[局部最小值]算是神经网络的经典宿敌了,自上个世纪90年代始,以Vapnik为首的统计机器学习数学家就不断对此炮轰猛击。
在今天看来,[局部最小值]或许并不是神经网络的过错,大量证据表明,人类在自然学习过程中本身就会出现局部最小值。
至于SVM为什么能绕开了[局部最小值],和Vapnik这位大数学家有关,他用求解最优分隔平面巧妙地变换了神经网络的目标函数。
从网络拓扑结构来看,SVM仅算是单隐层神经网络的特例。
凸优化、自适应隐元(支持向量)、完备的数学体系,真的让SVM从本质上脱离了神经网络吗?
在[论文2.7节]中,Bengio对此发出的疑问:
|
Different learning algorithms for neural networks differ in the specifics of the criterion and how they optimize it, often approximately because no analytic and exact solution is possible. |
2.5 假设:局部下降
既然人类自然学习本身就存在局部最小值,那么是如何掉进去的,又如何从中逃逸?
来看Bengio的第二个假设:
|
Local Descent Hypothesis:When the brain of a single biological agent learns, it relies on approximate local descent in order to gradually improve itself. |
即是说,学习过程依赖于对[误差]的不断局部下降,这是一个徐徐渐进的过程。
[论文2.7节]最后有一个观点很突兀:
|
One should not confuse local minima in synaptic weights with local minima (or the appearance of being stuck) in inference. |
即是说,神经推理过程不会陷入[局部最小值],神经元可以随时大幅度变化自己,根本没有机会结识[局部最小值]。
那么问题就肯定出在学习过程了,个人总结出四个关键点:
(I) 首先,根据Bengio的假设,学习过程显然是间断的,少有学习任务能够一气呵成。
(II) 一旦间断,就肯定需要[断点续传],每次选择一个局部的方向继续工作。
(III) 在学习后期,学习速率通常会变得很慢(比如厌学了),导致学习几乎停滞不前了。
(IV) 知识是有限的,尤其是在解决世界难题上(如NP完全问题),一部分人仍然会固执地坚持似乎不正确的解(N=NP)。
————————————————————————————————————————————————————
(II)显然不能保证,当前由贪心原则选择的[最速下降路径]一定是[通往全局最小值路径]的子路径。
因为函数曲面必然存在大量[局部最小值],所以搜索必然不会恰好选择[通往全局最小值路径],而是在中间就落入局部最小值。
这是为什么[局部最小值]不可避免的自然原因。
当然,Bengio还指出的更坏的情况,当前[最速下降路径],甚至不能保证会到达[局部最小值]。
依据是[随机梯度下降]与[批梯度下降]。
我们知道,[随机梯度下降]没有选择全部样本来学习,而是逐部分学习,最后会下降到离[批梯度下降]稍远的偏移位置。
这是[断点续传]策略造成的不可避免型[精度误差],Bengio称该偏移位置为[Effective Local Minima]。
————————————————————————————————————————————————————
(III)的解释可从二阶下降的牛顿法角度观察,学习速率由二阶Hessian矩阵控制:
$\Delta x_{t}=H_{t}^{-1} \cdot g_{t}$
随着[误差]的不断减小,$H_{t}^{-1}$近似也在减小,学习速率的下降似乎是无法挽回的。
以至于最后,学习进程几乎处于停滞状态,此时很大可能在某个局部最小值附近,于是就出不来了。
从社会角度来看,出自[对话机器学习大神Yoshua Bengio(下)]中的Q&A:
|
Q: 您觉得文化趋势是否会影响个体并且导致它们赖在局部优化情况?比如各种宗教机构和启蒙哲学之间的争端,家长式社会和妇女参政之间的冲突。这种现象是有益还是有害的? A: 我的看法是,非常多的个体固守自己的信念,因为这些信念已经变成了他们身份的一部分,代表了他们是怎么样的一个群体。改变信念是困难而且可怕的。 |
————————————————————————————————————————————————————
对于(IV),我们都知道: “失败乃成功之母”。失败是必然有的,说明你掌握的知识有限。
物理学巨匠牛顿说过:“如果说我看得比别人更远些,那是因为我站在巨人的肩膀上。”
随着越来越多的先辈在[局部最小值]中摸爬滚打,我相信,在未来,我们的子孙肯定会到达[全局最小值]。
2.6 逃逸策略
尽管在自然学习过程中,陷入局部最小值不可避免,但人类目前至少存在两个途径来逃逸。
★策略一:绞尽脑汁,豁然开朗
当我们被一个问题所困时,[绞尽脑汁]往往会从其他方向找到突破点。
该策略是有实验依据的,由Bengio组在2014年(本论文写成2年后)发现:
当参数(神经元)的维度很高时,局部最小值会蜕变成鞍点:

参数高维,即每层中神经元个数很多,VC维超级大,会出现和直觉相悖的现象:几乎不存在局部最小值。
Bengio对此的解释: [2015蒙特利尔深度学习暑期学校之自然语言处理篇.哈工大SCIR]
|
假设在某个维度上,一个点是局部极小点的概率为p。 那么这个点在1000维的空间下是局部极小点的概率则为 p^1000,是一个典型的小概率事件。 而该点在少数几个维度上局部极小的概率则相对较高。 在参数优化过程中,当到达这些点的时候训练速度会明显变慢,直到找到正确的方向。 |
Hinton教授的Dropout方法,实际上把已经神经网络变成了一个动态平均结构,这与生物神经网络是类似的。
尽管这时候模型总VC维已经庞大的无法直视,但是只要擅加稀疏和屏蔽,瞬时的结构风险是并不大的。
生物神经网络的Dropout稀疏率达95%以上,也就说,同时有95%的神经元被屏蔽,仅有5%是在工作的。
|
[绞尽脑汁] 似乎能够强行降低稀疏率,立刻提高维度,寻求鞍点来突破。(仅个人假设) |
当从局部最小值逃逸后,人会放松下来,又把稀疏率提高,服从结构风险最小化原则。
这时候,只要保持一个愉悦的心情,学习就会有效得多。如果继续保持重压,那么过拟合显然不可避免的。
正所谓:打骂(神经元数量使用特别多)出来的清华北大,不是残就是废(过拟合)。
—————————————————————————————————————————————————
★策略二:知识扩充
这大概是最普遍的方法了,大量的局部最小值由于“知识有限,智商不足以解答”而产生。
“知识有限”不仅直接体现在观测样本上(如Cifar10相对于ImageNet),还间接体现在“归纳的中间结果”上。
比如在数学证明时,缺乏对前置定理的了解,你几乎是无法进行下一步推导的。
这也是本篇论文讨论的重点,[文化浸染是如何协助从局部最小值中逃逸的?]
深度结构与层次抽象表达
3.1 莫名其妙的功臣——Hubel&Wiesel
几乎大部分关于Deep Learning资料,开篇必引1981年诺贝尔生理学或医学奖获得者,Hubel&Wiesel。
他们在1974年经典之作[Visual-field representation in layer IV of monkey striate cortex],可以说是万恶之源。
至于深度神经网络的最初构想是否真的与Hubel&Wiesel的工作有关,并没有确切证据。但拿诺奖来贴金,这是非常划算的买卖。
3.2 抽象观点
对RBM的可视化是简单的,但是对DBN的可视化确实艰难的。因为第二层以上参数学习的是经过non-linearity变换后的特征。
Bengio弟子之一Dumitru Erhan在2009年提出了对深度网络可视化的方法,用实验验证了深度结构的逐层抽象能力。[Erhan10]
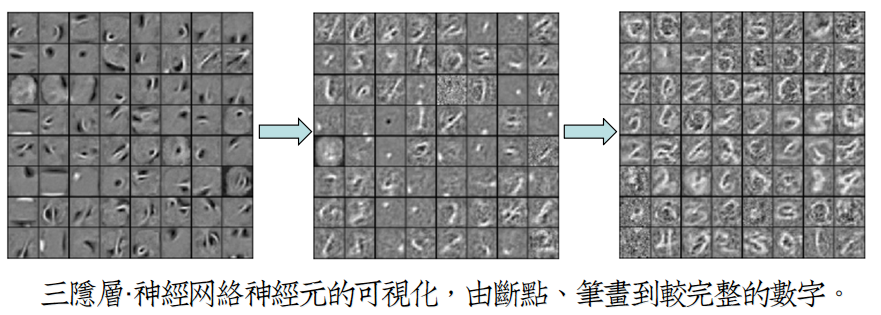
3.3 函数观点
神经元在每层时,都有一个对应的表达函数,深度越大,函数积链越长,后一层的函数链,其实是由前一层的函数链递推得到。
这像极了现代程序设计方法——按功能设计子函数、增大代码重用率。
尽管单隐层神经网络被证明可将任何函数拟合至精度为$\frac{1}{n}$ [Barron 1993],但是正如我们不会写出单函数代码一样,这并没有意义。
单隐层结构本身就不是科学的,起码它缺少神经元[复用](re-use)机制,效果不会很好。
Bengio组的另一个研究热点即使探索深度的[等效性],当前呼声较高的是这个假设:
|
Theorems on advantage of depth: (Hastad et al 86&91, Bengio et al 2007,Bengio&Delalleau 2011, Braverman 2011,Pascanu et al 2014, Montufar et al 2014) |
以SVM为例,当搜索空间无限庞大时,K层神经网络的搜索范围与$2^{n}$个支持向量等效,这时候选择SVM是不妥的。
反之,要是研究如何拟合$sinx$,SVM和K层神经网络几乎是难分伯仲。
这显然又回到了NFL(No Free Lunch)上,既不可盲目支持深度神经网络,更不可盲目排斥深度神经网络。
—————————————————————————————————————————————————
[复用]机制让神经网络结构变得很灵活,副作用也很明显,它服从于乘法原理。
从图论观点来看,假设每个结点连出两条路径,那么到达深度$n$的结点就有$2^{n}$条路径,复杂度呈指数级增长。
大量的可选择路径,让模型在搜索过程中,不停陷入形形色色的局部最小值当中,这似乎是无法避免的。
3.4 层次抽象与层次理解
回忆一下,当你初逢《高等数学》,你是如何理解积分这样高级概念的:
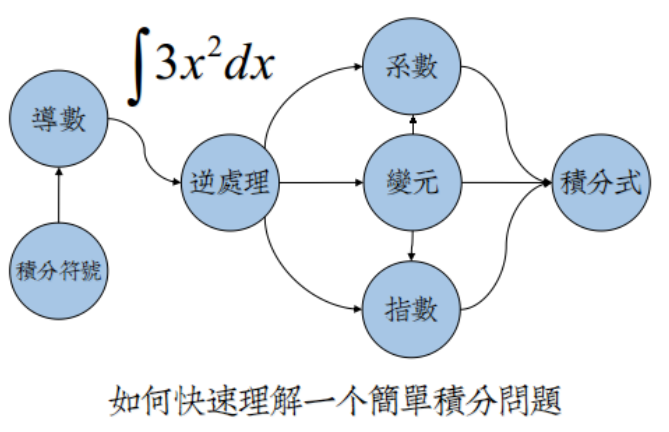
关于这个“世界”的表达,不同的人会产生不同的抽象,让自身去更好地理解。
虽然抽象内容各不相同,但这种行为是共性的——层次结构、分布联系、深度计算。
鉴于此,Bengio提出第三个假设:
|
Deep Abstractions Hypothesis:Higherlevel abstractions in brains are represented |
在计算模型中捕风捉影
4.1 非监督学习、监督学习
数据挖掘最常见的思路:先聚类,定模式。后分析,精结果。这种主动意识的行为,真的没有潜意识在诱导嘛?
考虑一个小学低年级的奥数题:
|
找规律,并填空。 0、1、1、2、3、5、8、13、21、34、__、__、__。 |
尽管我们对斐波那契数列耳熟能详,但世界上似乎还没有任何一种聚类算法能够发现这种规律。
那些年,愚昧无知的我们又是如何解决这个问题的呢?
答案无非就是:
|
在数次失败、偶然恰好尝试[斐波那契公式]时,假设这是这种[概念]是对的,用给定数据计算多个实例$\widetilde{x}$,用$\widetilde{x}$去验证$x$,只要$\sum (\widetilde{x}-x)^2= 0$,即我们的[概念]发现的模式没有任何错误,则认为,解答正确,并且记忆这种解法。 |
很不凑巧,这恰是RBM/AutoEncoder的思路,而我们的潜意识似乎正好在使用它。
对斐波那契数列规律的五花八门探索,不仅基本不是最优的,更多还是错的(与学习任务南辕北辙)。
如果碰巧有个模式是对的,那么对后续的学习就轻松许多,或是不用学习、或是作为一种暗示和引导。
据此两点,Bengio提出第一、第二观测现象:
|
Observation O1: training deep architectures is easier if hints are provided about the function that intermediate levels should compute. |
|
Observation O2: from
the work on artificial neural networks: it is much easier to teach a
network with supervised learning (where we provide it examples of when a
concept is present and when it is not present in a variety of examples)
than to expect unsupervised learning to discover the concept (which may
also happen but usually leads to poorer renditions of the concept). |
4.2 搜索之殇
神经网络并没有什么奇妙的内涵,它本质仍然是一个[启发式穷举搜索模型]。
类似于A*,它的启发式方向是[贪心策略:最速下降]。
但这个穷举,是一个连续实数型的无尽穷举,是一个曲面复杂的连续函数的生成。
类比于[深度优先搜索],我们都知道,随着深度的增加,会出现越来越恶劣的情况。
而神经网络同样有这样的厄运,这在上个世纪90年代,是被各界广为批判的,相关实验在[Erhan09]中。
据此,Bengio提出第三观测现象:
|
Observation O3: directly
training all the layers together would not only make it difficult to
exploit all the extra modeling power of a deeper architecture but would
actually get worse results as the number of layers is increased. |
O3仍然有一些其它的佐证,最形象的要属[Erhan09]中对同结构,随机初始化的各个神经网络,追踪多个训练阶段,
剥离输出层,将最后的隐层输出降维,且2D可视化,得到轨迹线图:
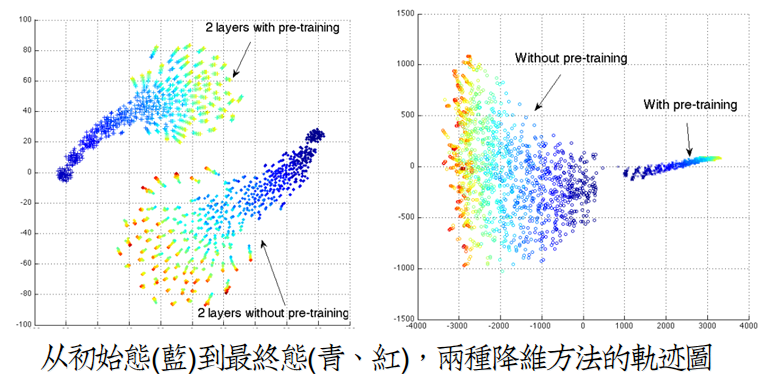
这个轨迹线隐含着两点有趣的现象:
(I) 不同初始化的神经网络,选择了独立的搜索方向,陷入了独自的局部最小值中,彼此不会重合。
(II) 没有预训练的神经网络,杂乱无章地在乱跑。
据此,Bengio提出第四、第五观测现象:
|
Observation O4: No
two trajectories end up in the same local minimum. This suggests that
the number of functional local minima (i.e. corresponding to different
functions, each of which possibly corresponding to many instantiations
in parameter space) must be huge. |
|
Observation O5: A training trick (unsupervised pre-training) which changes the initial |
4.3 假设:从模型走向人类
Bengio根据以上的Observation作了三个伟大的假设,他认为:
人类和现在的神经网络模型一样愚蠢,饱受[局部最小值]与[难以驾驭深度结构]的折磨。
前提条件:[One Single Human Learner],当然这个条件是不存在的,除非世界上除你以外的人都死光了
根据 Local Descent Hypothesis、O4、O5,Bengio提出局部最小值假设:
|
Local Minima Hypothesis:Learning of a single human learner is limited by effective local minima. |
结合O3,有对于训练深度结构的艰难假设:
|
Deeper Harder Hypothesis:The detrimental effect of local minima tends to |
最后,是一个关于徒有深度结构、却几乎不能利用之来逐层抽象的假设:
|
Abstractions Harder Hypothesis:A single human learner is unlikely to discover high-level abstractions by chance because these are represented by a deep |
这些看起来有些天方夜谭,人类怎么可能像机器学习模型那样愚蠢?
但如果从史前时代开始,世界上就你一个人,你保持不死状态直到今天,没准今天真和模型一样愚蠢。
而之所以没有出现这种情况,是因为[社会文化浸染]与[有性繁殖],让我们的进化地如此强大。
社会:神经网络们的互联网E时代
5.1 双脑聊天
考虑这样一个场景:
|
那年,牛顿还没见过苹果长什么样子,也不知道什么为红色。 他偶然来到果园,指着树上的红苹果,问山德士上校:“我听说果园里有苹果,这是苹果嘛?” 上校回答道:“你看,这种颜色叫红色,而红色的球状的物体是就是苹果。” 牛顿继续问:“味道怎么样?” 上校冷笑道:“你来KFC品尝一下我们的苹果鸡腿堡不就行了。” |
将这个场景用神经网络模型表示:
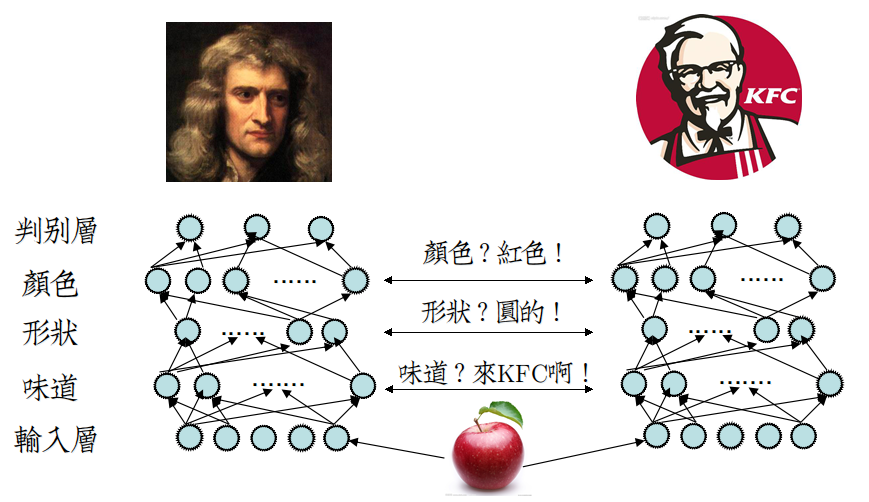
牛顿在未经过任何学习的情况下,直接从上校口中获取关于苹果的[颜色][形状],这是一件非常不可思议的事。
因为从目前的模型来看,要让神经网络监督训练[颜色][形状],仍然需要大费周章。
然而,此时牛顿还不知道苹果的[味道],所以当他看见一个[红色的皮球],会认为这是苹果,上前咬一口,咸咸的,
所以牛顿可能得出了这样一个真理,[苹果是红色的、圆的、咸咸的],而[红色的、圆的、甜甜的]的物体肯定不是苹果。
——————————————————————————————————————————————————
看完上面的笑话,我们一般会觉得,牛顿其实也很蠢。
如果没人告诉他[苹果是甜甜的],那么他可能一辈子会把[红色的皮球]错认为是[红色的苹果],掉进一个局部最小值中。
其实事情不比那么糟,牛顿起码有一个方法,让[红色的、圆的、甜甜的]的物体也被他认为是苹果:
只要他不知道[苹果是可以吃的],即,牛顿的神经网络中,扔掉关于[味道]的隐层,让网络深度变浅。
这不禁让我们想起了 O3 , 错误地直接训练多层网络,会让结果变糟,此时浅层结构胜于深度结构。
但,如果牛顿使用了正确的方法,比如真的去KFC吃了苹果鸡腿堡,那么就会认为[红色的、圆的、咸咸的]肯定不是苹果,
这比直接舍弃[苹果是可以吃的]有效地多,此时深度结构远胜于浅层结构,符合O1。
5.2 信息交流,让世界更美好
牛顿认知苹果,归功于山德士上校苦口婆心的教导,以口头语言形式。
从信息论观点来看,我们认为汉语的信息量比英语大,大部分语言的信息量要比行为动作要大。
即上校用四书五经而不是美式英语向牛顿解释,牛顿收获可能更大。
上校用美式英语而不是肢体动作向牛顿解释,牛顿收获可能更大。
但无论如何,只要[交流](Communication)能够传递到另一方的神经网络当中,成功消除神经元混沌,就足够了。
当然,我们还是希望能够实现信息量更丰富(Richer)的[交流],也许偶然之中,就能突破自己的其它[局部最小值]。
[交流]不仅仅局限于人类,动物之间那些[危险警示],也可视为[交流],这样,愚蠢的动物才能有效学习如何保护自己。
据此,Bengio提出引导学习假设:
| Guided Learning Hypothesis. A human brain can learn high-level abstractions if guided by the signals produced by other humans, which act as hints or indirect supervision for these high-level abstractions. |
5.3 交流背后的那些事
在牛顿的识别苹果神经网络中,关于[颜色][形状]的隐层,被山德士上校给替换了。
这不过只是瞬时行为,然而仅仅就结束了嘛?显然不是。
牛顿回去之后,将今天的收获见闻回想了一遍,对苹果有了更深的认识。
在神经网络中,我们假设:
[回想]过程发出了一个训练信号(Train Signal),牛顿的神经元立刻开始飞舞起来,
经过多轮的推理(Inference),将[颜色][形状][味道]三个隐层的值给[Fine-Tune]下,降低了识别错误率。
显然,因为牛顿爱思考的性格,[交流]触发了牛顿的学习机制。
这倒是能解释,为什么同样的老师上了同样的课,学生有的考上了清华,有的成了家里蹲。
5.4 交流引发强大的心智活动
[交流]在神经系统中产生最频繁的效应就是[虚拟环境],通俗点就是“不在场却能身临其境”。
经[交流]直接修改的神经网络,上下协调性不佳,需要[Fine-Tuning],可能还需要一些新样本来强化记忆理解。
Hinton教授认为生物神经元普遍包含两种方向的计算。
这是一个证明RBM和AutoEncoder合理性的突破点,因为大多数情况下,需要在“判别模型”和“生成模型”间快速切换。
[虚拟环境]的产生可以用“生成模型”来解释,只要将前向传播的方向逆置,从[颜色]到[形状]、[味道],生成“苹果”,
就能在没有看见苹果的情况下,脑中浮现出苹果。
——————————————————————————————————————————————————————
[交流]将关于世界的[概念](Concept)传播,传播通道的带宽是有限的,这意味着将产生[竞争]。
比如,我们在接受[地球是圆的]同时,会排斥[地球是方的]、[地球是三角形的]。
[竞争]是自然界的标准法则,所谓优胜劣汰,适者生存.
最后留下的[概念]在族群(Population)神经网络的[局域网]中,成为霸主,此时[概念]进化为[信仰]。
[信仰]同[深度结构]类似,是一把双刃剑。
正确的[信仰],如哥白尼的[日心说],有助于我们走出关于天体运动的[局部最小值]。
错误的[信仰],如亚里士多德的[力是维持物体运动的原因],则会长期把我们囚禁在[局部最小值]中。
5.5 外传:合理的课程学习
该部分是Bengio个人的一个小研究,基于 Guided Learning Hypothesis. , 即学习过程是可以被引导的。
课程顺序学习制度是人类在学习任务上的经验总结,一个实例如下:
|
CTSC(国际信息学奥林匹克竞赛中国队选拔赛)1997 [选课],背景描述: 在选修课程中,有些课程可以直接选修,有些课程需要一定的基础知识,必须在选了其它的一些课程的基础上才能选修。例如《Frontpage》必须在选修了《Windows操作基础》之后才能选修。我们称《Windows操作基础》是《Frontpage》的先修课。 |
从感觉上来看,先修课制度划定了学习进程的任务次序,具有[由浅入深性]、[无后效性],保证学习进程循序渐进。
同时,让学习任务也具有深度结构,这是一个合理的层次抽象策略( 从简单抽象(子抽象)到复杂抽象(组合抽象) ) 。
据此,Bengio假设,如果在机器学习任务中,能够将样本的学习难度划分,重新安排学习顺序,那么就会有更好的效果。
因为学习是局部渐进的,所以低难度的学习样本,目标函数曲面较为简单,能够较为接近[全局最小值]。
再次,使用中、高难度的样本,函数曲面逐渐复杂,最后仍然会落入[局部最小值]中,不过位置更接近[局部最小值]。
进化论 与 迷因论
6 .1 理查德·道金斯的迷因论
理查德·道金斯(Richard Dawkins)大概是世界上最野心勃勃、最不为人知的生物进化学家了。
在他的研究中,最令人难忘的工作就是提出“迷因论”,[果壳网]有一篇很好的翻译介绍。
6.2 搜索观点
几乎世界万物的生命进程都可以看作是一个搜索进程。
基因的进化是在搜索—— 不断舍弃劣等基因,探索高等基因。(历程:几十万年)
迷因的进化是在搜索—— 在数量爆炸性的文化中,寻找传承不息的迷因子。(历程:几十年、几百年、几千年)
学习的进化是在搜索—— 个体为将所掌握的知识统一,琢磨一个支点去平衡它们。(历程:几分钟、几小时、几天)
推理的进化是在搜索—— 神经元为了协调神经关系,不断变化自己。(历程:几毫秒,几秒)
这些搜索策略,因为大自然的馈赠,获得了足以并行搜索的条件。
基因的并行在于[有性繁殖],一个家族生生不息的繁衍,一起推动着这个家族基因的并行搜索进程。
迷因的并行在于[宿主传播],显然,知乎的一条回答,能够在短时间内进入数以千计人的脑中,加深“MH”印象。
学习的并行在于[个体交流],一个经典案例就是 “牛顿是如何认知苹果是红色的、圆圆的、甜甜的?”
推理的并行在于[神经网络],神经元彼此连接着,构成神经网络,而神经冲动无时无刻不在产生,瞬息万变。
自然界的四大并行搜索是可怕的,它们之间层层叠加,协助人类以最快的速度从[局部最小值]中逃逸,无限逼近[全局最小值]。

6.3 先有鸡,还是先有蛋
尽管迷因子看起来无所不能,但仔细分析,道金斯仅给出迷因的两种特性:[自由脑入侵]与[噪声复制] (noisy copy)
这两种特性只能描述迷因子发展的中间状态,一个很严肃的问题必须被考虑:最早的迷因子无从复制,又如何而来?
该问题一定程度上等效于哲学上的“鸡生蛋,还是蛋生鸡?”
显然,要解决这个疑问,就必须从迷因论中跳出来,在其他领域寻找论据。
最先、也是最容易产生的一种假设,就是迷因起源于它的栖息地——脑,由神经网络而生。
如果这种假设是正确的,那么迷因就获得第三种特性 [迷因重组]。
[迷因重组]的想法显然效仿于[基因重组],[基因重组]是[有性繁殖]生物体内在的一种可怕技术。
人类的基因数量只有5万,且[基因突变]的频率太低,但是一旦这些基因排列组合,产生的基因型数量是庞大到无法计算的。
[迷因重组]更加可怕,人的一生接触的迷因子显然不止5万,所以[迷因重组]可以产生大量的崭新迷因子。
这似乎能解释迷因子的起源问题。
6.4 迷因计算模型
[噪声复制]尽管看起来是像是一条毒瘤链,实际上它的速度是可怜的。
Bengio用了这样一个例子:
| 一种迷因,在某轮传播中连接N个人,产生N个复制体。如果现在有M个人,且M>N,那么按照并行计算的概念,产生的M个复制体,会让下轮的迷因传播速度提升M/N倍。 |
这看起来很有道理,画成图应该是这样:
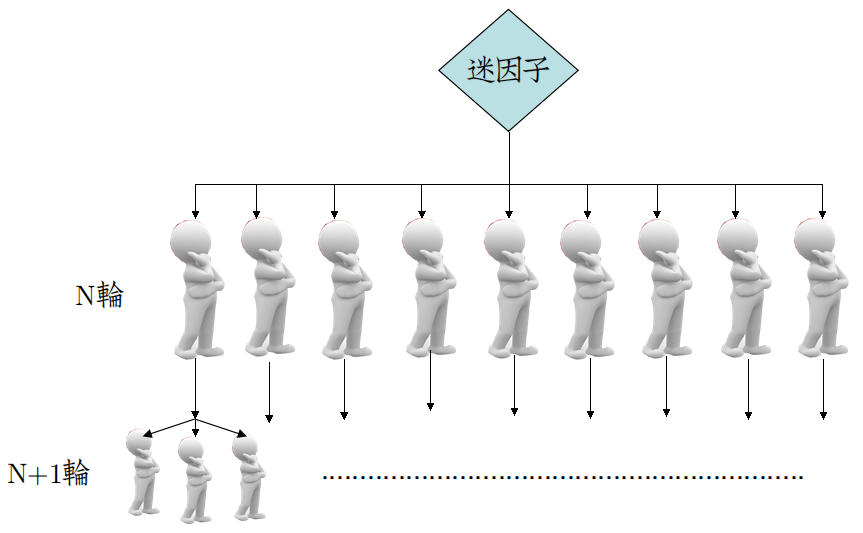
从图上来看,显然是不符合上文关于人类“交流”的假设的,所以应该是这样:

对于其中的某个人,他可能在短时间内,[连续]与[同轮]的人交换信息,这部分可以用一个子图描述:
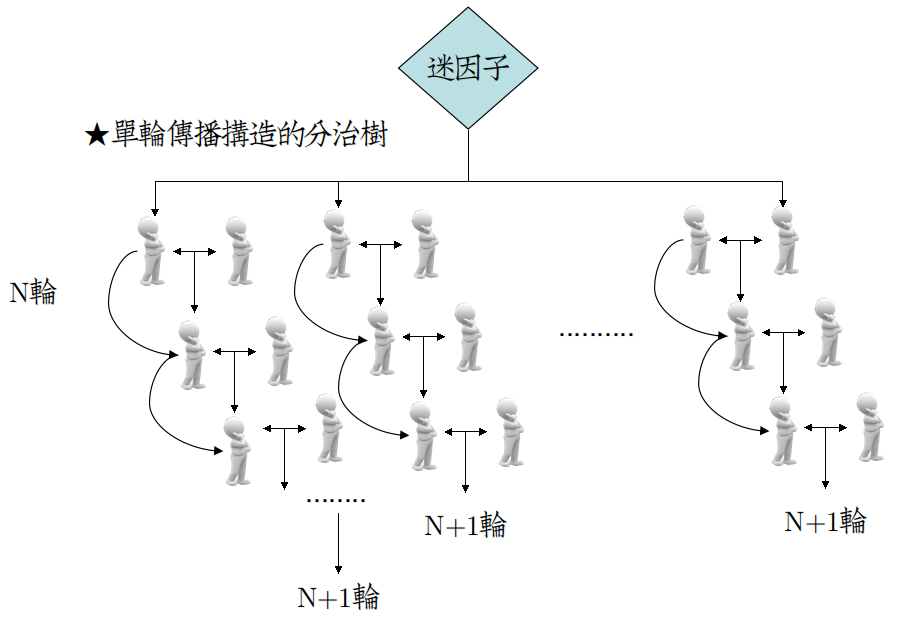
现在,让我们考虑一个更疯狂的想法,假如某人在每次交流时,对迷因的看法都不同,
那么在这颗分治树上,叶子结点(最终的想法)与非叶结点(曾经的想法)对迷因都是有贡献的。
考虑对于深度为$n$的二叉树,总结点数的计算公式: $N=2^{n}-1$,这样,迷因子的传播速度,就可以呈指数级增长。
这只是理论上的最好传播效果,Bengio指出,实际交流跨度不会很大,所以这棵分治树的规模是有限的。
据此,Bengio提出迷因分治传播假设:
| Memes Divide-and-Conquer Hypothesis. Language, individual learning, and the recombination of memes constitute an efficient evolutionary recombination operator, and this gives rise to rapid search in the space of memes, that helps humans build up better high-level internal representations of their world. |
个人对于人工智能的奇思妙想
上述基本就是Bengio教授目前对人工智能的大部分研究和假设了,整体总结起来真的是非常有趣。
将人工智能同进化观点联系起来,其实还有一些有趣的假设:
| 机器毁灭人类假设(个人观点). 当机器的进化速度超越人类时,人类就会被毁灭。 |
| 机器天择假设(个人观点). 机器会在恰当时机加入天择队列,与人开始竞争。竞争遵循进化论观点,优胜劣汰,不合格的人类会被淘汰,从而加速人类进化速度,以确保不会被机器超越。 |
其中,第二个假设最近有了一个强大的支持,来自于反对人工智能的霍金,他指出[比起机器人,我们更应该警惕资本主义]
大致内容如下:
|
从本质上讲,拥有机器的人将自成一个新的阶级,而他们不会为普通工人提供工作机会。正因为这样,富可敌国的人们和其它人的鸿沟越来越大。富人的财富比其工资增长得更快,而工人阶级甚至永远无法赶超。 听起来这样的预言似乎比机器人统治世界还要悲伤一些。毕竟大家都是人,怎么差距这么大呢? |

Cnbeta当时的即时评论是这样的:

但无论怎么讲,我们的机器仍然是太蠢了,进化只能由每年的论文和产品推进,这样的速度离征服人类还早着呢。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号