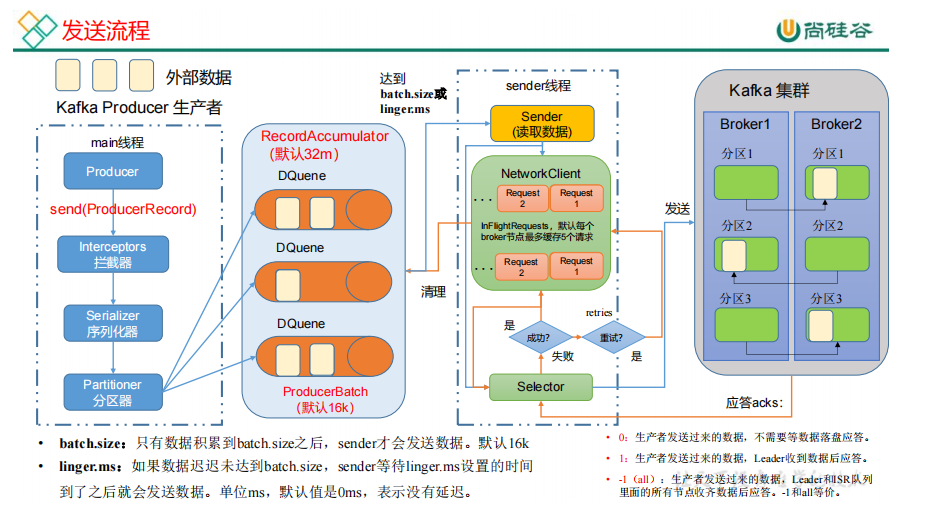
1.生产者发送流程
![]()
外部数据发送到kafka集群,创建一个main线程,创建一个kafka producer对象发送,首先调用一个send方法,
把这批数据用send方法发送。数据到拦截器,可以对数据进行加工操作,拦截器是可选项。数据到序列化器,
java的序列化太重,kafka有自己的。数据到分区器,判断数据应该到哪一个分区,一个分区创建一个缓冲队列,是一个
双端队列RecordAccumulator,包含队列和内存池,队列里新增批次数据时,从内存池取出内存,发送到kafka集群时,把内存释放给内存池
都是在内存里完成的,总大小是32M,一批次大小是16k。达成条件被拉取,Sender线程把缓冲队列的数据读出来后发往kafka集群。
Sender线程怎么发送。他以(每个节点为key,后面跟上请求),如果给一个节点发送了5个请求都没有应答,就不发送了,
最多缓存5个请求。生产者发送过去数据,kafka集群有3种应答级别。如果返回成功,首先把该请求清空,然后把每个分区的
缓冲数据清理掉。如果返回失败,进行重试,重试次数默认int最大值,可以自定义,重试方法是重发请求
2.生产者发送消息的分区策略
2.1默认的分区器 DefaultPartitioner
1)指明partition的情况下,直接将指明的值作为partition值;例如partition=0,所有数据写入分区0
2)没有指明partition值但有key的情况下,将key的hash值与topic的partition数进行取余得到partition值;
例如:key1的hash值=5, key2的hash值=6 ,topic的partition数=2,那么key1 对应的value1写入1号分区,
key2对应的value2写入0号分区。
3)既没有partition值又没有key值的情况下,Kafka采用Sticky Partition(黏性分区器),会随机选择一个分区,并尽可能一直
使用该分区,待该分区的batch已满或者已完成,Kafka再随机一个分区进行使用(和上一次的分区不同)。
例如:第一次随机选择0号分区,等0号分区当前批次满了(默认16k)或者linger.ms设置的时间到, Kafka再随机一个分区进
行使用(如果还是0会继续随机)。
2.2自定义分区器
3.生产者如何提高吞吐量
修改如下参数:
• batch.size:批次大小,默认16k
• linger.ms:等待时间,修改为5-100ms
• compression.type:压缩snappy
• RecordAccumulator:缓冲区大小,修改为64m
4.ack 应答级别
可靠性总结:
acks=0,生产者发送过来数据就不管了,可靠性差,效率高;
acks=1,生产者发送过来数据Leader应答,可靠性中等,效率中等;
acks=-1,生产者发送过来数据Leader和ISR队列里面所有Follwer应答,可靠性高,效率低;
在生产环境中,acks=0很少使用;acks=1,一般用于传输普通日志,允许丢个别数据;acks=-1,一般用于传输和钱相关的数据,
对可靠性要求比较高的场景。
数据完全可靠条件 = ACK级别设置为-1 + 分区副本大于等于2 + ISR里应答的最小副本数量大于等于2
幂等性就是指Producer不论向Broker发送多少次重复数据,Broker端都只会持久化一条,保证了不重复。
精确一次(Exactly Once) = 幂等性 + 至少一次( ack=-1 + 分区副本数>=2 + ISR最小副本数量>=2) 。
重复数据的判断标准:具有<PID, Partition, SeqNumber>相同主键的消息提交时,Broker只会持久化一条。其
中PID是Kafka每次重启都会分配一个新的;Partition 表示分区号;Sequence Number是单调自增的。
所以幂等性只能保证的是在单分区单会话内不重复。
2)如何使用幂等性
开启参数 enable.idempotence 默认为 true,false 关闭。
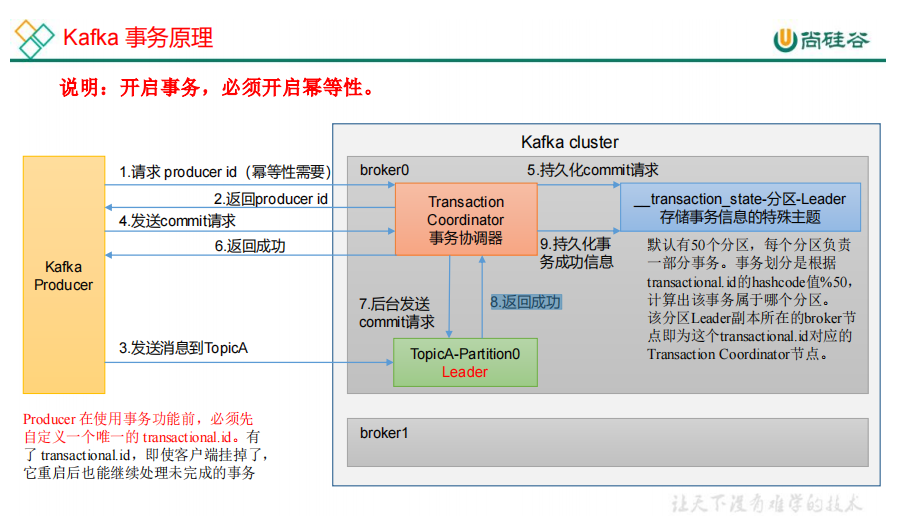
6.生产者事务
![]()
7.生产经验——数据乱序
![]()
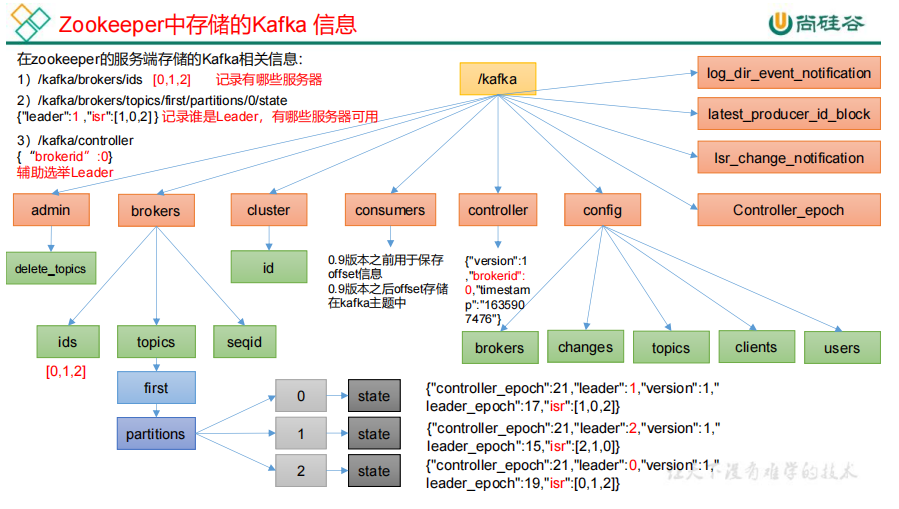
8.Zookeeper 存储的 Kafka 信息
![]()
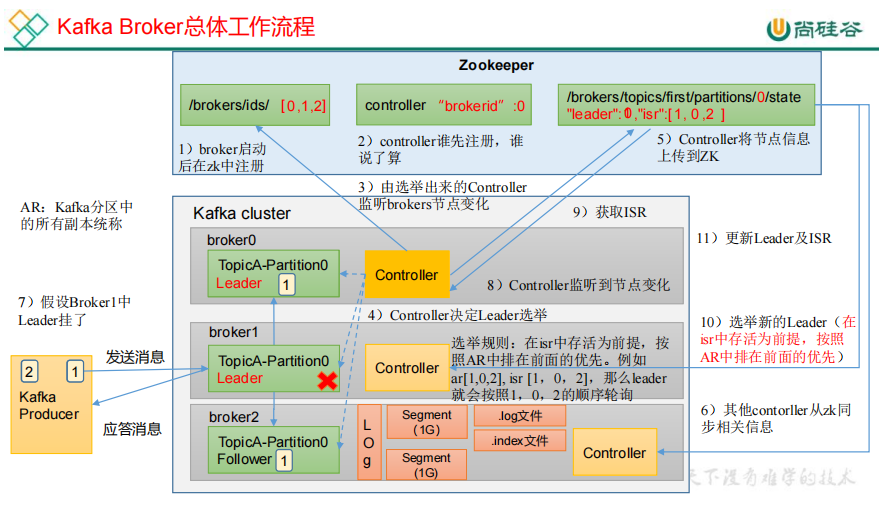
9.Kafka Broker 总体工作流程
![]()
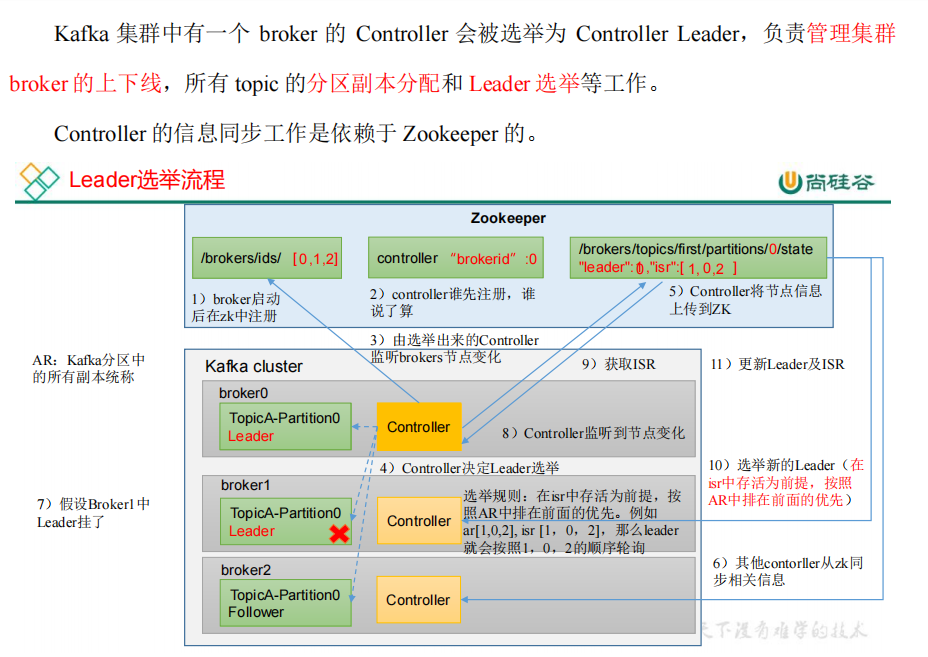
每个节点都有Controller,谁先注册,谁是Controller Leader。
10.Leader 选举流程
![]()
11.Follower故障处理细节
![]()
12.Leader故障处理细节
![]()
13.生产经验——手动调整分区副本存储
14.生产经验——Leader Partition 负载平衡
![]()
![]()
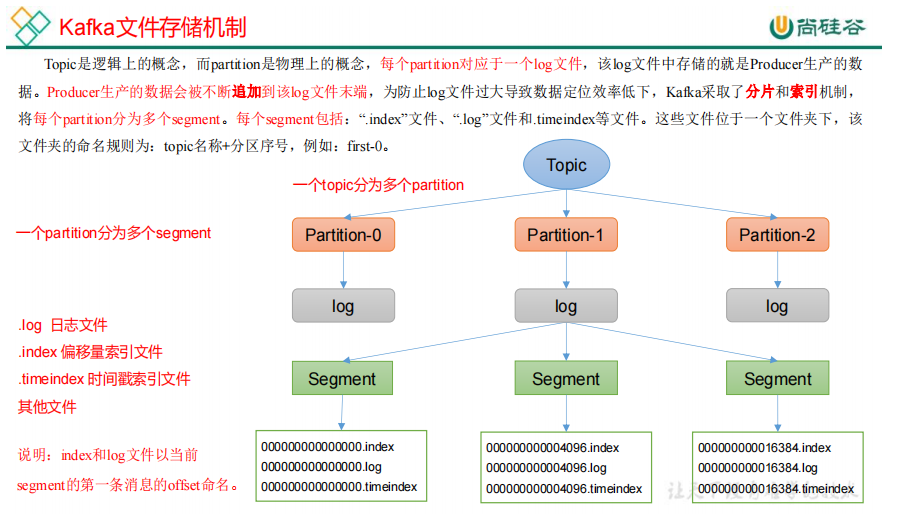
17.文件清理策略
![]()
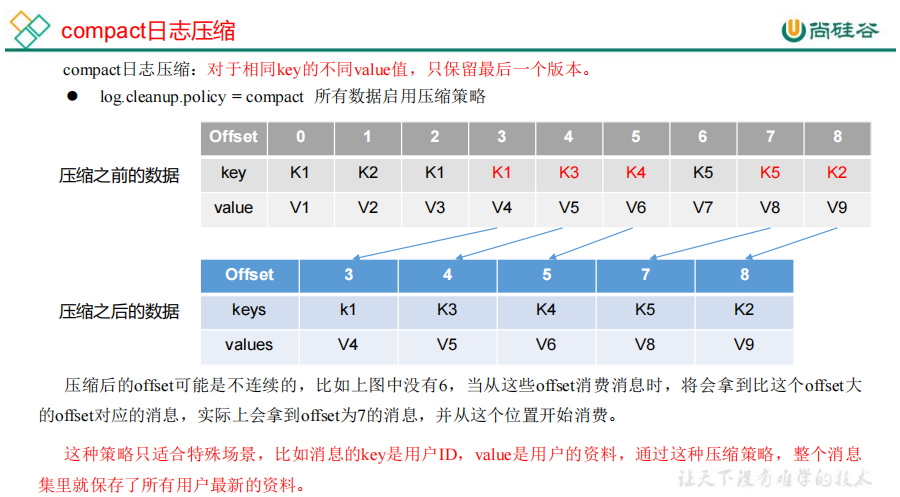
2)compact 日志压缩
![]()
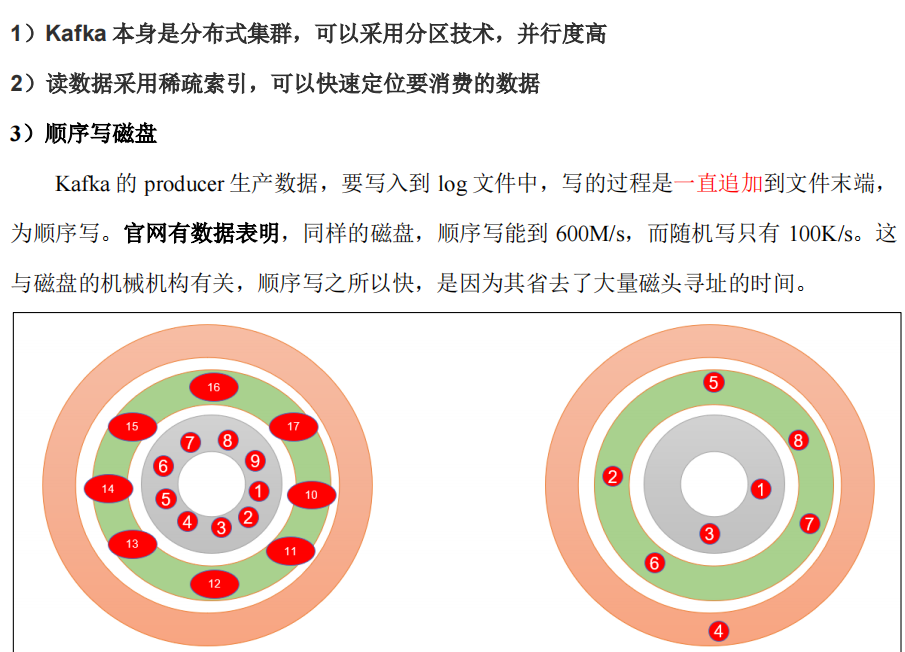
18.高效读写数据
![]()
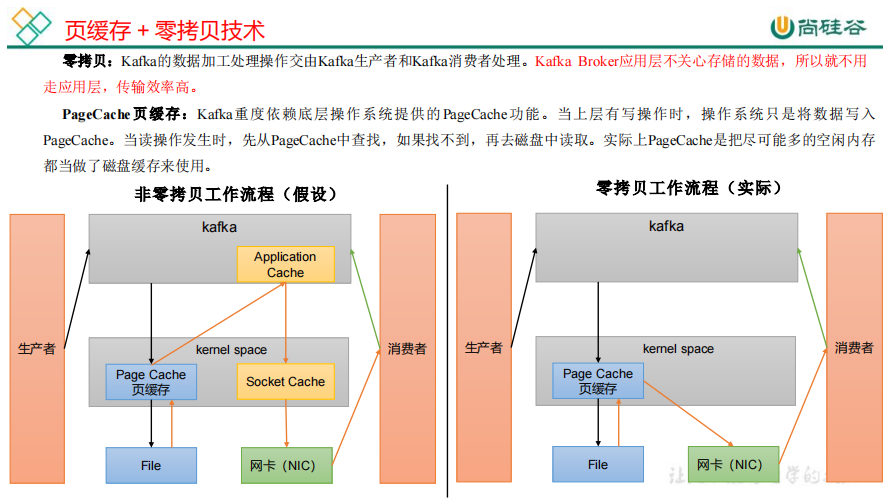
4)页缓存 + 零拷贝技术
![]()
![]()
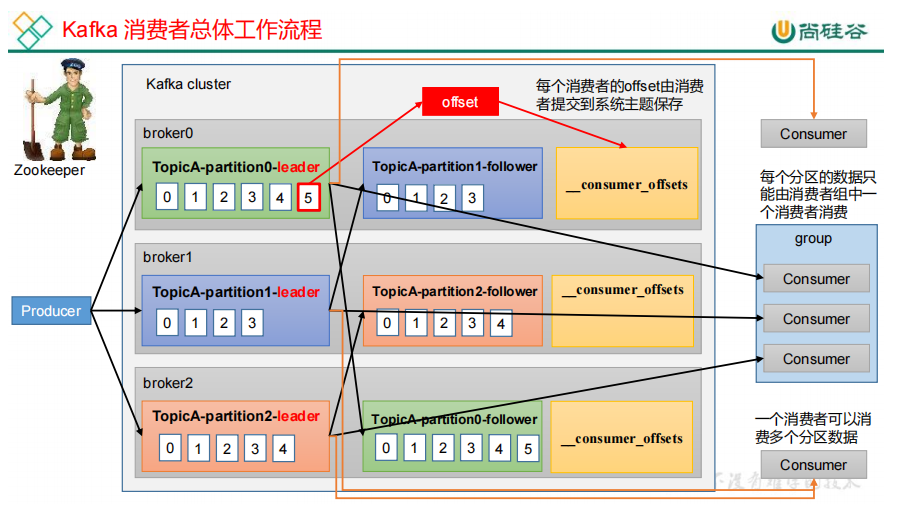
19.Kafka 消费者工作流程
![]()
消费者消费到什么地方由offset保存,offset保存在系统主题中
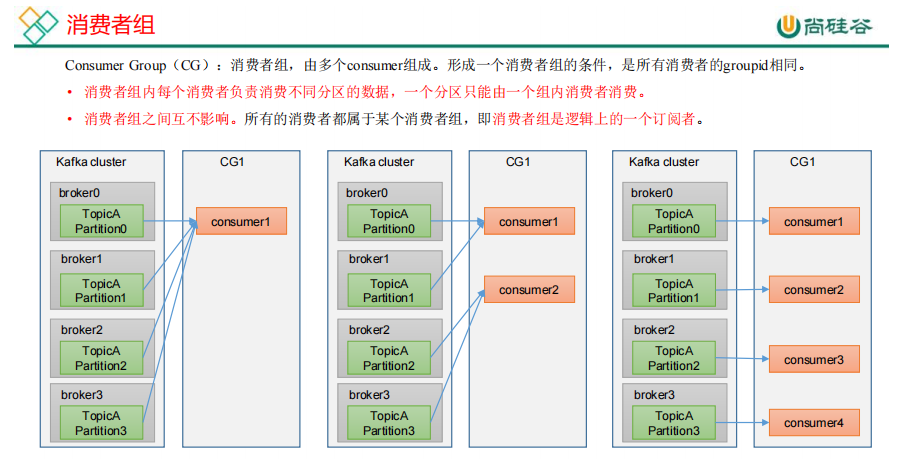
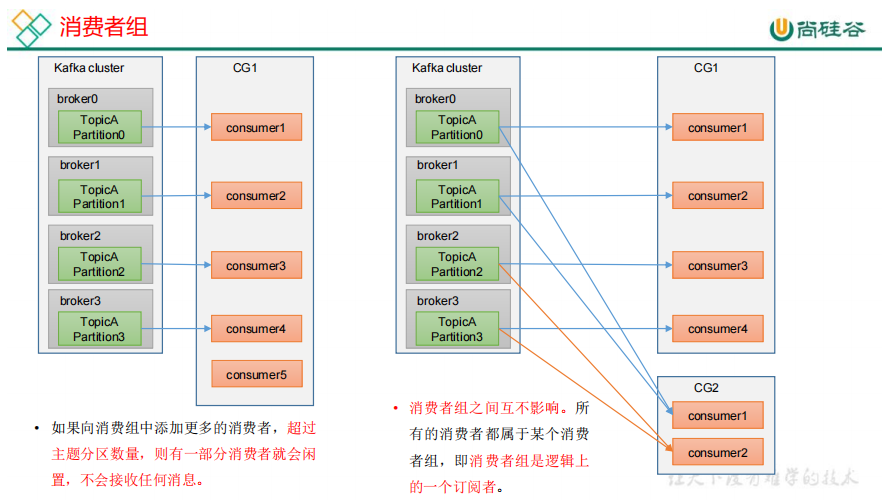
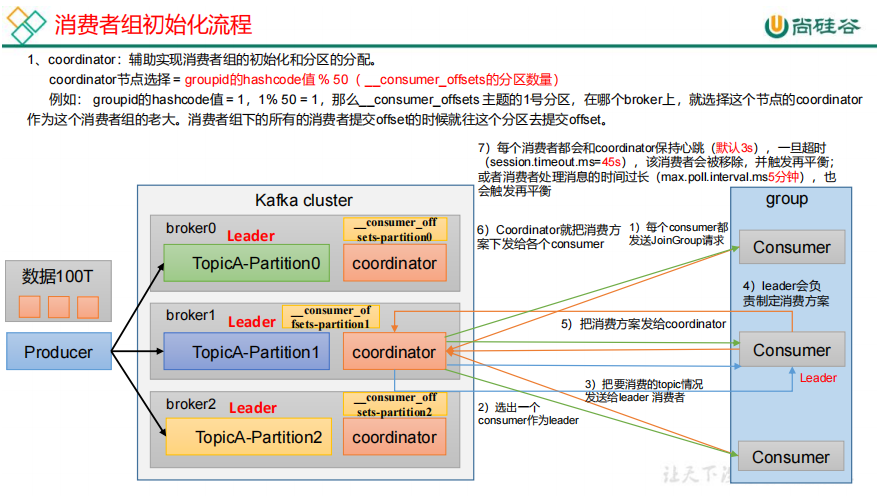
20.消费者组原理
![]()
![]()
![]()
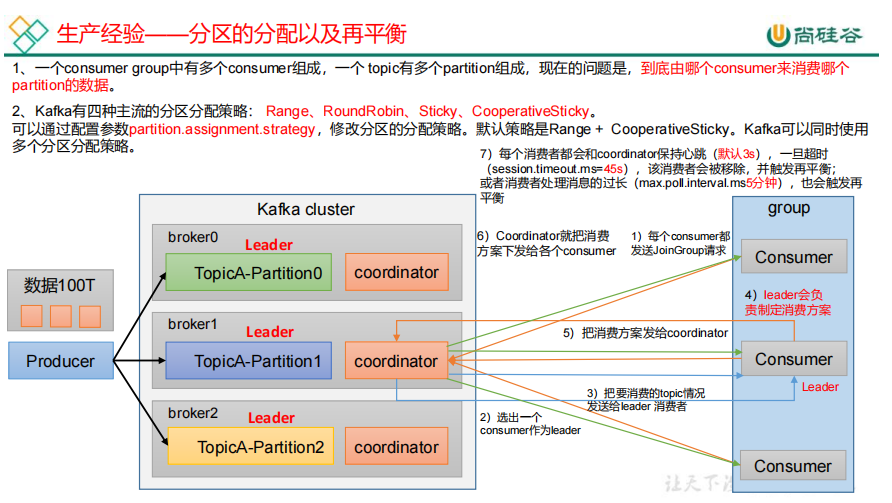
每个broker都有coordinator,offset保存在consumer—offset主题上,它默认有50个分区。每个consumer向coordinator发送joinGroup请求,
coordinator随机选择一个consumer作为leader
![]()
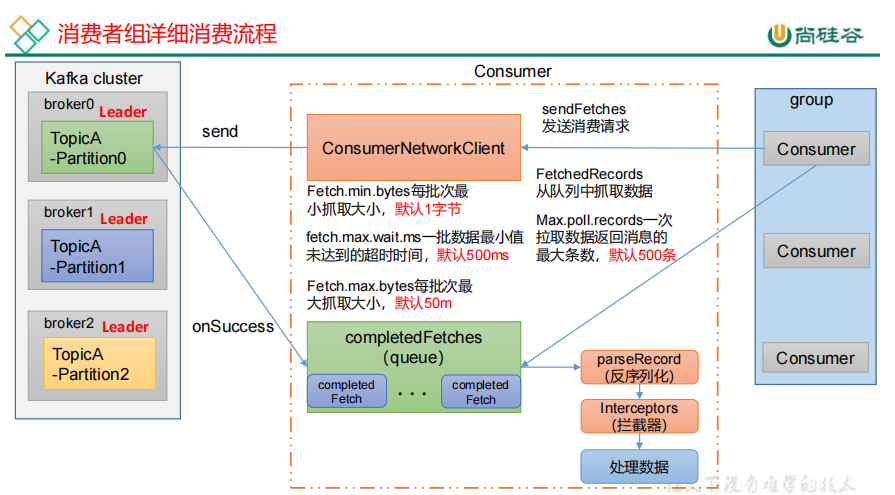
消费者首先创建一个网络连接客户端ConsumerNetworkClient,consumer首先调用一个sendFetches方法,用来抓取数据的初始化,
准备完之后通过send方法发送请求,之后通过回调函数onSuccess把数据拉取回来放到消息队列,然后consumer从队列拉取数据,一次
拉取500条,这些数据首先进行反序列化,经过拦截器(可以处理数据,监控数据),之后处理数据。
21.生产经验——分区的分配以及再平衡
![]()
![]()
![]()
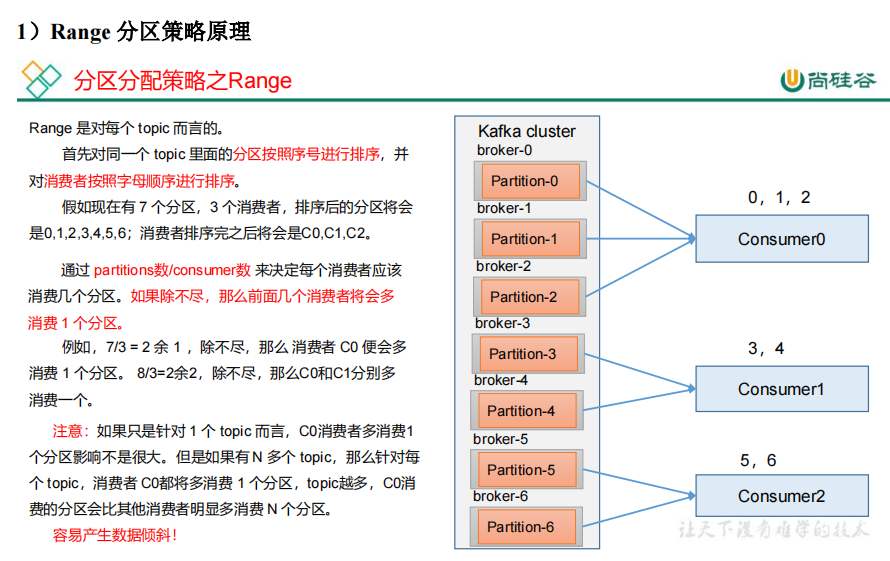
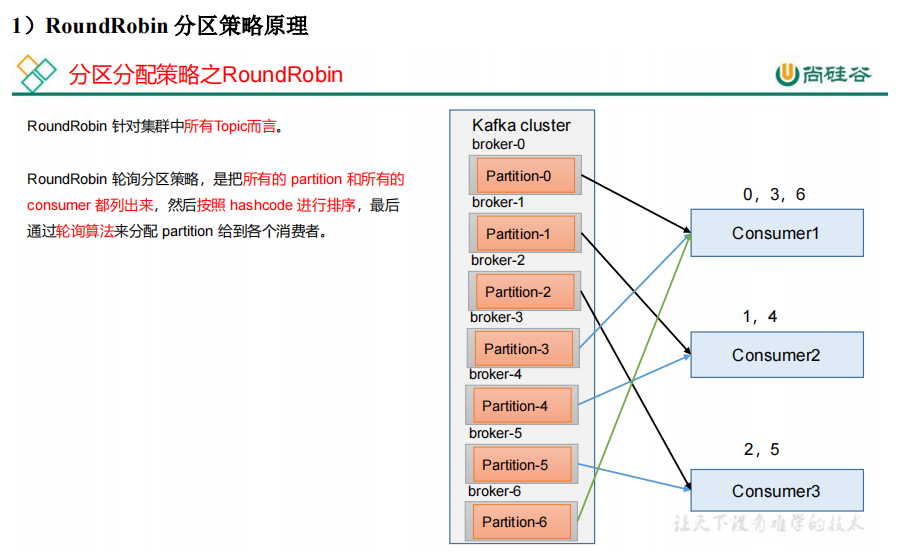
所有topic的分区列出来,hashcode排序后轮询分配
![]()
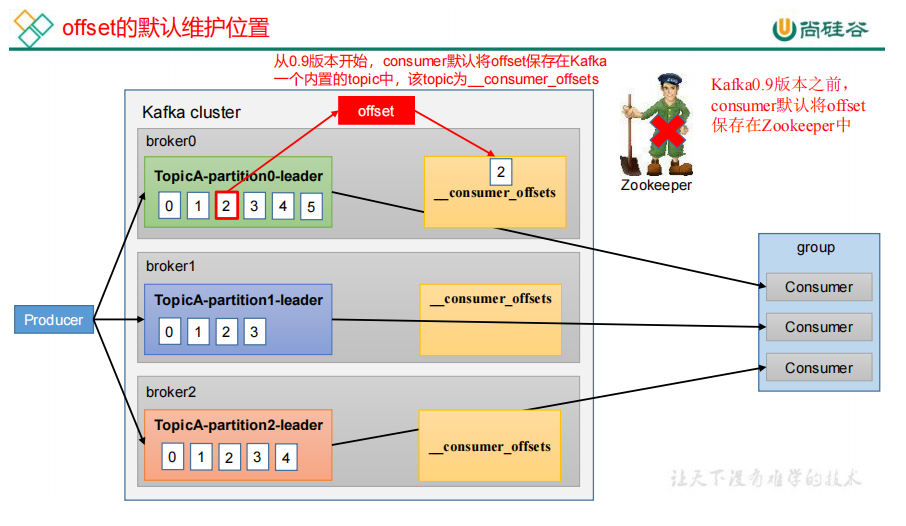
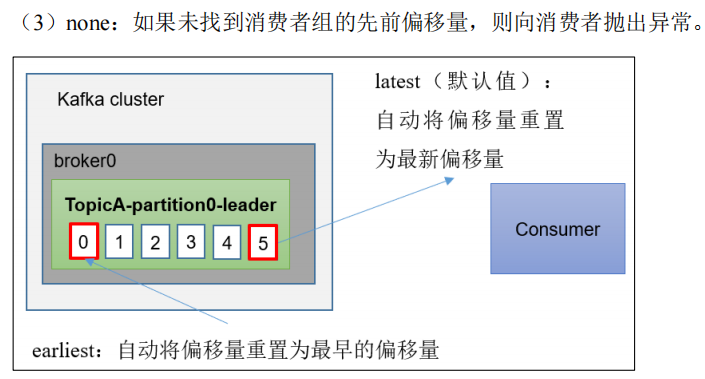
22.offset 的默认维护位置
![]()
offset就是记录消费者消费到哪了
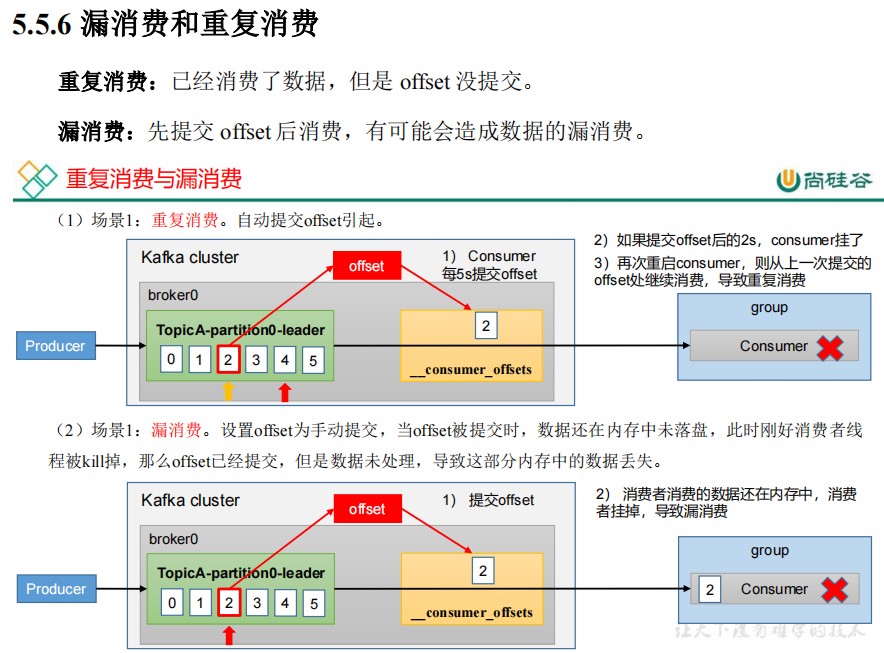
![]()
![]()
![]()
![]()
![]()
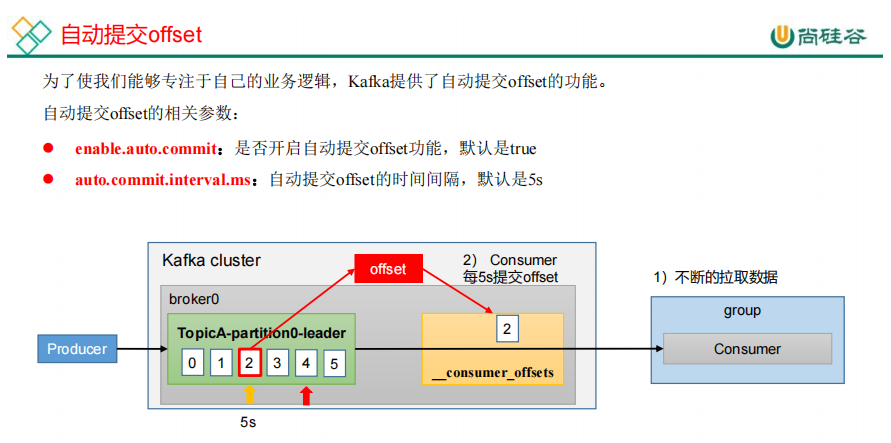
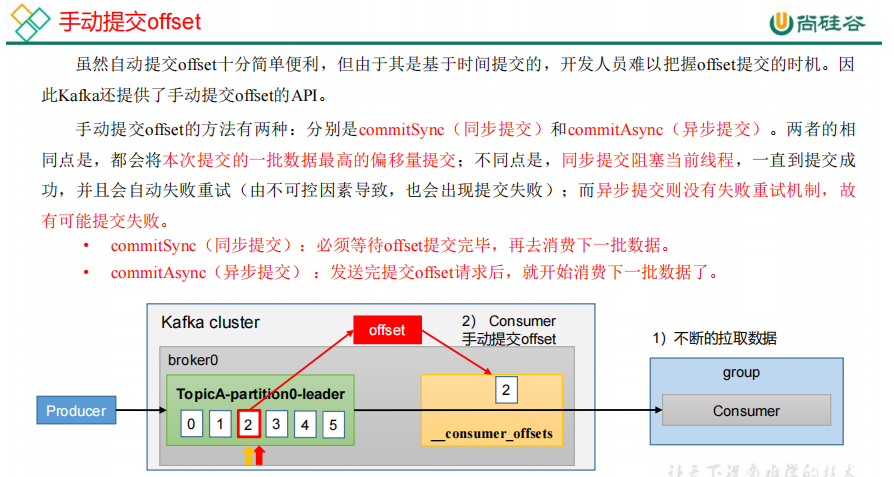
23.生产经验——数据积压(消费者如何提高吞吐量)










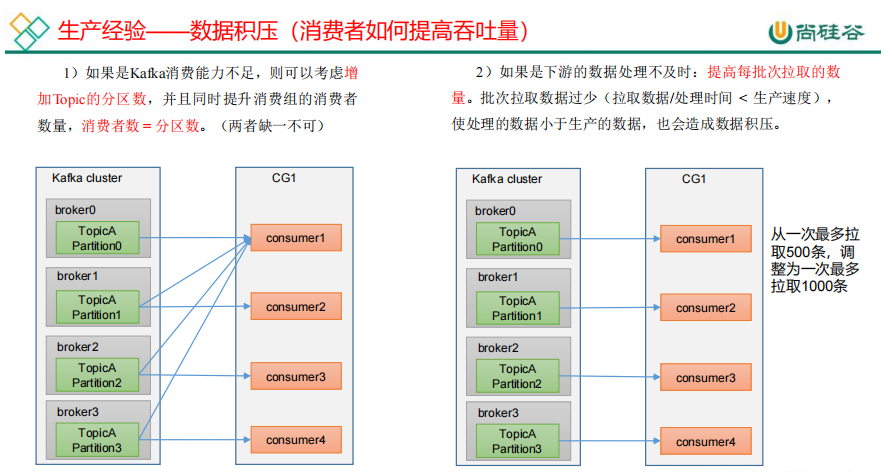

 浙公网安备 33010602011771号
浙公网安备 33010602011771号