Java volatile 关键字详解【图 & 源码】
前言
核心目标: volatile 关键字的核心目标是解决**可见性(Visibility)和有序性(Ordering)**问题。它告诉编译器和 JVM,这个变量是“易变的”,对它的访问(读/写)需要遵循特定的内存语义规则,不能进行过度的优化。
一、问题背景:为什么需要 volatile?
在理解 volatile 之前,必须理解现代计算机架构和 JMM(Java Memory Model)带来的挑战:
-
多级缓存与可见性问题:
- 现代 CPU 有多个核心,每个核心通常有自己的高速缓存(L1, L2)。
- 变量最初存储在主内存中。
- 当一个线程读取变量时,它可能将变量从主内存加载到自己的工作内存(通常是 CPU 寄存器或核心的缓存)。
- 当一个线程修改变量时,它首先修改自己工作内存中的副本,之后某个时间点才会写回主内存。
- 问题: 如果线程 A 修改了变量但尚未写回主内存,线程 B 读取到的可能还是主内存中的旧值。这就是可见性问题——线程 A 的修改对线程 B 不可见。
-
指令重排序与有序性问题:
- 为了提高性能,编译器(Java 编译器或 JIT 编译器)和 CPU 处理器可能会对指令的执行顺序进行优化重排(Instruction Reordering)。
- 重排序遵循
as-if-serial语义:单线程执行结果不能被改变。 - 问题: 在多线程环境下,这种重排序可能导致程序的行为与代码的书写顺序不一致。例如:
// 线程 A resource = new Resource(); // (1) 分配内存空间 (2) 初始化对象 (3) 将引用赋值给 resource initialized = true; // (4)- 编译器/CPU 可能将 (3) 和 (4) 重排序。如果线程 B 看到
initialized为true后立即使用resource,它可能访问到一个尚未完全初始化的对象(此时 (2) 可能还没执行完)。这就是有序性问题。
- 编译器/CPU 可能将 (3) 和 (4) 重排序。如果线程 B 看到
JMM(Java Memory Model): JMM 定义了 Java 程序中各种变量(实例字段、静态字段、数组元素)的访问规则,以及在 JVM 中将变量存储到内存和从内存中读取变量的底层细节。它规定了:
- 线程如何、何时能看到其他线程写入共享变量的值。
- 在必要时,如何同步对共享变量的访问。
JMM 的核心概念是happens-before关系,它定义了操作之间的可见性保证。
二、volatile 的语义(JMM 层面)
当一个字段被声明为 volatile 时,JMM 对其读写操作施加了严格的内存语义:
-
可见性保证:
- 写操作(Write): 对一个
volatile变量的写操作完成后,该变量的新值会立即被强制刷新到主内存中。 - 读操作(Read): 对一个
volatile变量的读操作发生时,JVM 会强制使该线程的工作内存中该变量的缓存失效,从而必须从主内存中重新读取该变量的最新值。 - 效果: 一个线程对
volatile变量的写操作,对后续所有其他线程对该变量的读操作总是可见的。这解决了缓存不一致性问题。
- 写操作(Write): 对一个
-
有序性保证(禁止指令重排序):
- 编译器重排序限制: 编译器在生成字节码或 JIT 编译生成机器码时,会遵守特定的规则,禁止对
volatile变量的访问操作与其他内存操作进行某些可能破坏语义的重排序。 - 处理器重排序限制: JVM 通过在生成的指令序列中插入特定的内存屏障(Memory Barrier / Memory Fence) 指令,来禁止 CPU 对
volatile变量的访问操作与其他内存操作进行某些类型的重排序。 - 具体规则(基于 happens-before):
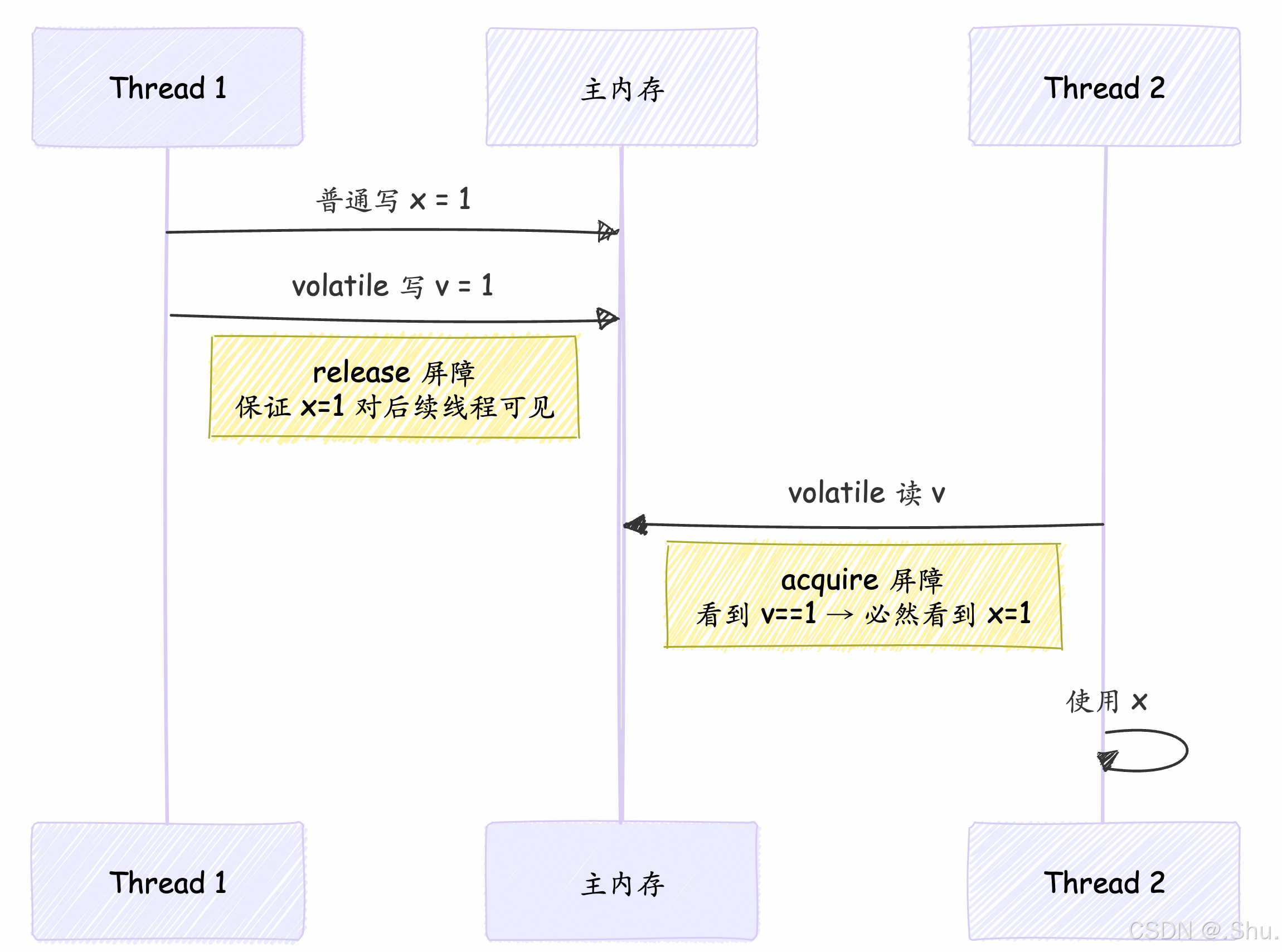
- volatile 写 happens-before 于后续(任何线程)对这个 volatile 变量的读。 这是
volatile语义的核心。 - volatile 写之前的任何读写操作,不能被重排序到 volatile 写之后。 (StoreStore + StoreLoad 屏障效果)
- volatile 读之后的任何读写操作,不能被重排序到 volatile 读之前。 (LoadLoad + LoadStore 屏障效果)
- volatile 写 happens-before 于后续(任何线程)对这个 volatile 变量的读。 这是
- 编译器重排序限制: 编译器在生成字节码或 JIT 编译生成机器码时,会遵守特定的规则,禁止对
Happens-Before 链路(volatile 传播可见性)
三、底层机制:内存屏障(Memory Barriers)
volatile 语义的实现核心在于内存屏障。内存屏障是一种 CPU 指令,它告诉 CPU 和编译器:
- 在屏障之前的所有特定类型的操作(读/写)必须在该屏障之后的所有特定类型的操作开始之前完成。
- 它强制刷新缓存/使缓存失效,确保内存可见性。
- 它限制指令重排序。
JVM 主要使用以下四种类型的内存屏障(对应不同的重排序限制):
- LoadLoad Barrier: 确保该屏障之前的读操作(Load)先于之后的读操作完成。
- StoreStore Barrier: 确保该屏障之前的写操作(Store)先于之后的写操作完成,并且之前的写操作结果对其他处理器可见(刷新到主存)。
- LoadStore Barrier: 确保该屏障之前的读操作(Load)先于之后的写操作(Store)完成。
- StoreLoad Barrier: 这是一个“全能型”屏障,它确保:
- 该屏障之前的所有写操作(Store)都完成并刷新到主存。
- 该屏障之后的所有读操作(Load)都能看到这些最新写入的值(或更晚的值)。
- 它通常具有其他三种屏障的效果,但开销也最大。
volatile 写操作的内存屏障插入策略
在 JVM 生成的机器码中,对一个 volatile 变量的写操作之后,会插入一个 StoreLoad Barrier(或者等效的组合屏障,具体取决于平台)。
- 作用:
- StoreStore Barrier (隐含): 确保
volatile写之前的所有普通写操作的结果在该volatile写刷新到主存之前,都已经对其他处理器可见(即普通写也要刷新)。 - StoreLoad Barrier: 确保
volatile写的结果立即刷新到主存,并且使其他处理器中该volatile变量的缓存行失效。这保证了volatile写对后续读的可见性,并且防止volatile写与后续的读/写操作重排序。
- StoreStore Barrier (隐含): 确保
volatile 读操作的内存屏障插入策略
在一个 volatile 变量的读操作之前,会插入一个 LoadLoad Barrier + LoadStore Barrier(或者等效的组合屏障)。
- 作用:
- LoadLoad Barrier: 确保
volatile读操作之前的所有读操作(包括其他普通读)都已完成。防止volatile读与之前的读操作重排序。 - LoadStore Barrier: 确保
volatile读操作完成之后,才执行之后的写操作。防止volatile读与之后的写操作重排序。 - 更重要的是:
volatile读操作本身会强制从主内存加载最新值(相当于使本地缓存失效)。LoadLoad和LoadStore屏障确保了在后续操作使用这个新值之前,所有必要的约束(禁止重排序)已经满足。
- LoadLoad Barrier: 确保
四、源码窥探(OpenJDK HotSpot)
理解 JVM 如何实现 volatile 需要查看多个层面的代码:
-
字节码层面:
- 声明为
volatile的字段在 Class 文件的字段表(field_info)结构中,其访问标志(access_flags)会包含ACC_VOLATILE(值为0x0040)。这是 JVM 识别volatile字段的源头。 - 文件:
src/hotspot/share/classfile/classFileParser.cpp(解析 class 文件时设置标志) - 文件:
src/hotspot/share/oops/fieldInfo.hpp(存储字段信息,包含访问标志)
- 声明为
-
解释器执行(Template Interpreter):
- JVM 为不同类型的字段访问(
getfield,putfield)生成了一系列的模板(汇编代码片段)。 - 当解释器执行到访问一个带有
ACC_VOLATILE标志的字段的字节码(如getfield,putfield)时,它会选择对应的、插入了内存屏障的模板来执行。 - 关键文件:
src/hotspot/cpu/<arch>/templateTable_<arch>.cpp(例如x86/templateTable_x86.cpp) - 关键函数:
TemplateTable::putfield_or_static,TemplateTable::getfield_or_static - 关键代码片段(概念性伪代码):
// putfield (写 volatile 字段) void TemplateTable::putfield_or_static(...) { ... if (field->is_volatile()) { if (support_IRIW_for_not_multiple_copy_atomic_cpu) { // 某些特殊 CPU 可能需要额外屏障 } // 在写操作之后插入 StoreLoad 屏障 // 对于 x86, 通常使用 lock addl [rsp], 0 作为 StoreLoad 屏障 (一个空操作锁指令) __membar(Assembler::StoreLoad); } ... } // getfield (读 volatile 字段) void TemplateTable::getfield_or_static(...) { ... if (field->is_volatile()) { // 在读操作之前插入 LoadLoad 和 LoadStore 屏障 // 对于 x86, LoadLoad 屏障通常不需要显式指令 (x86 内存模型较强) // LoadStore 屏障通常也不需要显式指令 (x86) // 但 volatile 读本身在 x86 上会生成有 lock 前缀的指令 (如 cmpxchg) 或依赖缓存一致性协议 (MESI) 保证可见性 // 对于弱内存模型平台 (如 ARM, PowerPC), 需要显式屏障指令 (dmb, isync 等) __membar(Assembler::LoadLoad | Assembler::LoadStore); } ... } - 注意: 具体的屏障插入策略和使用的指令高度依赖目标 CPU 架构。x86 的内存模型相对较强(TSO - Total Store Order),很多屏障是隐式的,
volatile写通常只需要一个StoreLoad屏障(常用lock addl $0x0, (%rsp)实现)。而 ARM/PowerPC 等弱内存模型平台需要更多显式的屏障指令(如dmb)。
- JVM 为不同类型的字段访问(
-
JIT 编译器(C1/C2):
- 当方法被 JIT 编译时,编译器(如 C2)会在中间表示(IR)层处理
volatile访问。 - 编译器会识别
volatile访问点,并在生成的机器码中插入相应的内存屏障指令,遵循与解释器模板相同的语义规则。 - 关键文件:
src/hotspot/share/opto/memnode.hpp/.cpp(内存操作节点) - 关键类:
LoadXNode,StoreXNode(及其 volatile 版本LoadVolatile,StoreVolatile) - 关键文件:
src/hotspot/share/opto/output.cpp(机器码生成) - 关键文件:
src/hotspot/cpu/<arch>/macroAssembler_<arch>.cpp(架构相关的屏障实现) - 关键代码片段(概念性):
// 在生成 volatile 写操作的机器码时 (例如 x86) void MacroAssembler::store_volatile(...) { ... // 生成实际的存储指令 (如 mov) lock(); // 或者更具体的屏障指令 addl(Address(rsp, 0), 0); // x86 上常用的 StoreLoad 屏障实现 (lock addl) } // 在生成 volatile 读操作的机器码时 (例如 ARM) void MacroAssembler::load_acquire(...) { // volatile 读通常具有 acquire 语义 ... // 生成加载指令 (如 ldr) dmb(Assembler::LD); // ARM 上的 LoadLoad + LoadStore 屏障 }
- 当方法被 JIT 编译时,编译器(如 C2)会在中间表示(IR)层处理
-
OrderAccess 模块:
- HotSpot 定义了一个
OrderAccess模块 (src/hotspot/share/runtime/orderAccess.hpp),它提供了跨平台的内存屏障抽象。 - 它定义了
loadload(),storestore(),loadstore(),storeload(),acquire(),release(),fence()等屏障函数。 - 在具体的平台实现中 (如
src/hotspot/os_cpu/<os>_<arch>/orderAccess_<os>_<arch>.hpp),这些函数会被映射到该平台/CPU 架构上最合适的屏障指令(或无操作,如果该屏障在该平台是隐式的)。 - 解释器和 JIT 编译器最终会调用
OrderAccess提供的函数来插入屏障。
- HotSpot 定义了一个
五、volatile 的典型用法
- 状态标志: 最简单且最常用的场景。一个线程设置
volatile boolean flag = true;,另一个线程循环检查while (!flag) { ... }。volatile确保设置标志的线程一修改flag,检查线程就能立即看到。 - 一次性安全发布(One-time Safe Publication): 结合
volatile和不可变对象或正确构造的对象(所有字段都是final的)。public class Singleton { private static volatile Singleton instance; public static Singleton getInstance() { if (instance == null) { // 第一次检查 (无锁,性能好) synchronized (Singleton.class) { if (instance == null) { // 第二次检查 (避免多次初始化) instance = new Singleton(); // volatile 写 } } } return instance; // volatile 读 } // ... private constructor etc. }volatile在这里防止了对象初始化过程中的重排序问题。如果没有volatile,线程 A 可能在构造器未执行完时就先将引用赋值给instance(重排序),此时线程 B 在第一次检查instance != null后直接返回了一个未完全初始化的对象。volatile写禁止了这种重排序,确保引用赋值发生在对象完全构造之后。
- 独立观察(Independent Observations): 定期发布观察结果供其他线程使用。例如,一个传感器程序将当前读数写入一个
volatile变量,其他线程可以随时读取最新值。 - 开销较低的读-写锁策略: 当读远多于写时,可以结合
volatile和synchronized实现一种轻量级的读写锁。public class CheesyCounter { private volatile int value; public int getValue() { return value; } // volatile 读,低成本 public synchronized int increment() { // 写操作需要同步 return value++; } }- 读操作 (
getValue) 是volatile读,开销低且保证看到最新值。 - 写操作 (
increment) 需要synchronized保证原子性(因为value++不是原子操作)。synchronized块退出时的释放锁操作也包含一个StoreLoad屏障,确保了修改对后续volatile读的可见性。
- 读操作 (
六、重要注意事项与限制
-
不保证原子性(Atomicity): 这是最常见的误解!
volatile不能替代synchronized或java.util.concurrent.atomic包中的类来保证复合操作的原子性。- 反例:
volatile int count = 0; count++; count++实际上是read-modify-write三步操作(读取当前值 -> 加1 -> 写回新值)。volatile保证了读到的值是最新的,也保证了写回的值能被其他线程看到,但不能阻止两个线程同时读到相同的值,各自加1,然后写回,导致最终结果只增加了一次。这种情况下需要使用synchronized或AtomicInteger。
- 反例:
-
性能考量:
volatile读操作通常开销很低(接近普通读,尤其是在 x86 上)。volatile写操作的开销相对较高,因为它需要插入StoreLoad屏障(在 x86 上是一个相对昂贵的lock前缀指令)。这会导致写操作后的指令流水线刷新。- 过度或不必要地使用
volatile会影响性能。只在确实需要解决可见性和有序性问题时才使用。
-
替代方案:
synchronized: 提供更强的保证(原子性、可见性、有序性),但开销更大(锁获取/释放)。java.util.concurrent.atomic(e.g.,AtomicInteger,AtomicReference): 使用 CAS (Compare-And-Swap) 操作提供特定变量的原子操作和volatile语义。对于count++这类操作,AtomicInteger.incrementAndGet()是更好的选择。java.util.concurrent.locks.Lock: 提供更灵活的锁机制。- JDK9+:
VarHandle提供了更细粒度的内存顺序控制(如acquire,release,relaxed),是volatile和Atomic类的底层基础,允许更精确地控制屏障类型。
七、配方级用法与正确姿势
- “停止标志 / 配置开关”
class Worker implements Runnable {
private volatile boolean running = true;
public void stop() { running = false; }
public void run() {
while (running) { /* do work */ }
}
}
- running 用 volatile:主线程对其写对工作线程立即可见;工作线程对它的读不会被搬到循环外(acquire+release 规约)。
- 安全发布(Safe Publication)
class Holder { final int x; Holder(int x){ this.x=x; } }
class Repo {
private volatile Holder h; // 用它来做“发布”
public void init() { h = new Holder(42); } // volatile 写(release + StoreLoad)
public int read() { Holder t = h; if (t!=null) return t.x; return -1; } // volatile 读(acquire)
}
- 通过 volatile 引用发布对象:读到非空就能看到构造前的所有写(包括 final 字段的冻结语义),避免“半初始化”可见。
- 双重检查锁(DCL)必须配 volatile
class Singleton {
private static volatile Singleton INSTANCE;
private Singleton(){ /*...*/ }
static Singleton get() {
if (INSTANCE == null) { // 第一次检查(无锁)
synchronized (Singleton.class) {
if (INSTANCE == null) { // 第二次检查(有锁)
INSTANCE = new Singleton(); // 必须 volatile, 防止构造重排导致“先发布后初始化”
}
}
}
return INSTANCE;
}
}
- 没有 volatile,new 可能被重排为:分配→赋值引用→执行构造,导致另一个线程读到非空引用但对象未完全初始化。
DCL 中 volatile 的作用

- 计数器:为什么 volatile 不够
volatile int c = 0;
void wrong() { c++; } // 读-改-写:非原子
- 用 AtomicInteger.incrementAndGet() 或 LongAdder(高并发热点;分段减少伪共享)。
- 数组与 volatile
volatile int[] arr; // 仅“引用”是 volatile,元素不是
- 若要元素级可见且原子,使用 AtomicIntegerArray / AtomicReferenceArray 或 VarHandle 针对元素做 getVolatile/setVolatile。
八、总结
volatile是解决多线程可见性和防止特定指令重排序(有序性)问题的轻量级同步机制。- 其核心原理是通过 JMM 规定的
happens-before关系,并在底层(字节码解释/JIT编译)通过插入内存屏障指令来实现。 - 内存屏障强制刷新缓存/使缓存失效(保证可见性),并限制编译器和 CPU 的重排序(保证有序性)。
volatile写 相当于插入StoreStore+StoreLoad屏障(效果),确保写操作前的修改可见且写操作本身的结果立即全局可见。volatile读 相当于插入LoadLoad+LoadStore屏障(效果),确保读到最新值并防止后续操作重排序到读之前。- 主要应用场景:状态标志、安全发布、独立观察、读多写少的计数器(需配合锁保证写原子性)。
- 关键限制:不保证原子性。 复合操作仍需其他同步机制。
- 使用时应权衡其性能开销(尤其是写操作),并优先考虑更高级别的并发工具(如
java.util.concurrent)或Atomic类。
理解 volatile 需要深入到 JMM 和 CPU 内存模型的层面。通过分析 HotSpot 源码中解释器模板、JIT 编译器和 OrderAccess 的实现,可以清晰地看到 volatile 语义是如何通过内存屏障在具体硬件架构上落地的。
本文来自博客园,作者:NeoLshu,转载请注明原文链接:https://www.cnblogs.com/neolshu/p/19120779

 浙公网安备 33010602011771号
浙公网安备 33010602011771号